DeepSeek-R1模型更新,版本号DeepSeek-R1-0528,关于各种“表扬”的文章已经铺天盖地了,不再是我涉及的内容。正好昨天基于英伟达的财报进行了Claude-4,Claude-3.7,Gemini-2.5,ChatGPT-o3的模型比较。本来是要加入最新R1模型的结果评价,但是在结果上出现了一些问题,直到今天才能够正常输出,所以就放到这篇文章里一起讨论了。
关于其他模型的结果,参看昨日文章:比较几个模型对英伟达的财报分析,这是为什么我更偏好Gemini-2.5和Claude-3.7的原因
评论里问到提示词,正好这里再给出一次:
Gen a highly detailed professional interactive react slides to analyze the following financial report of Nvidia with the link
https://nvidianews.nvidia.com/news/nvidia-announces-financial-results-for-first-quarter-fiscal-2026 in Chinese, please integrate code into one html file
昨天将同样的提示词给到DeepSeek-R1,出现两个问题,一是生成的代码一直有问题,DS的改代码能力相比Claude还是有较为明显的差距,所以花了些时间,另一个问题是虽然给了链接,但是即使打开搜索功能,看起来R1也无法顺利的访问该页面,获取准确的数据(下面的截图可以看到大量数据错误)。再加上DeepSeek还在进行访问限流,所以在人工辅助调试直到模型输出正常可视化效果的代码,花了不短的时间。
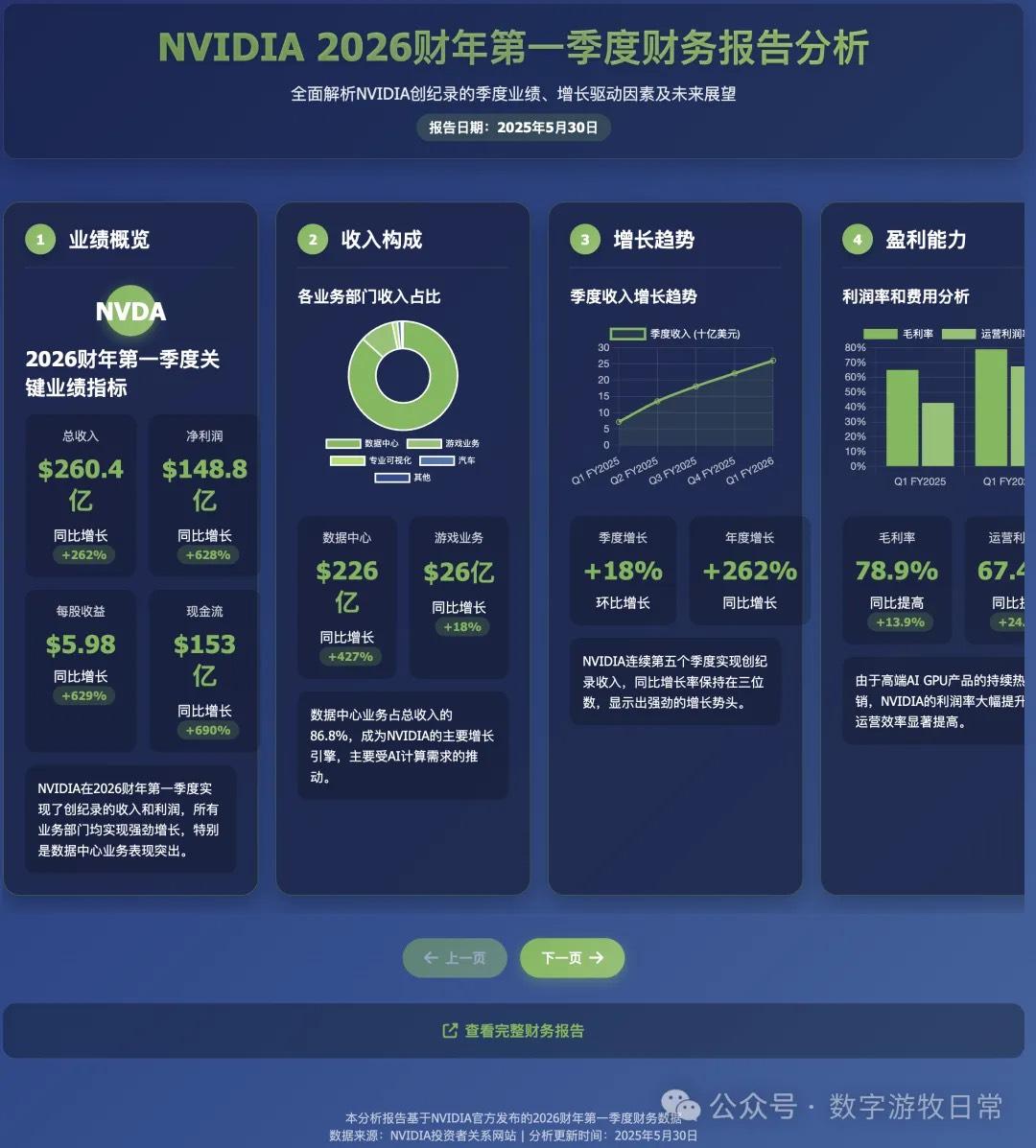
效果截图如下:
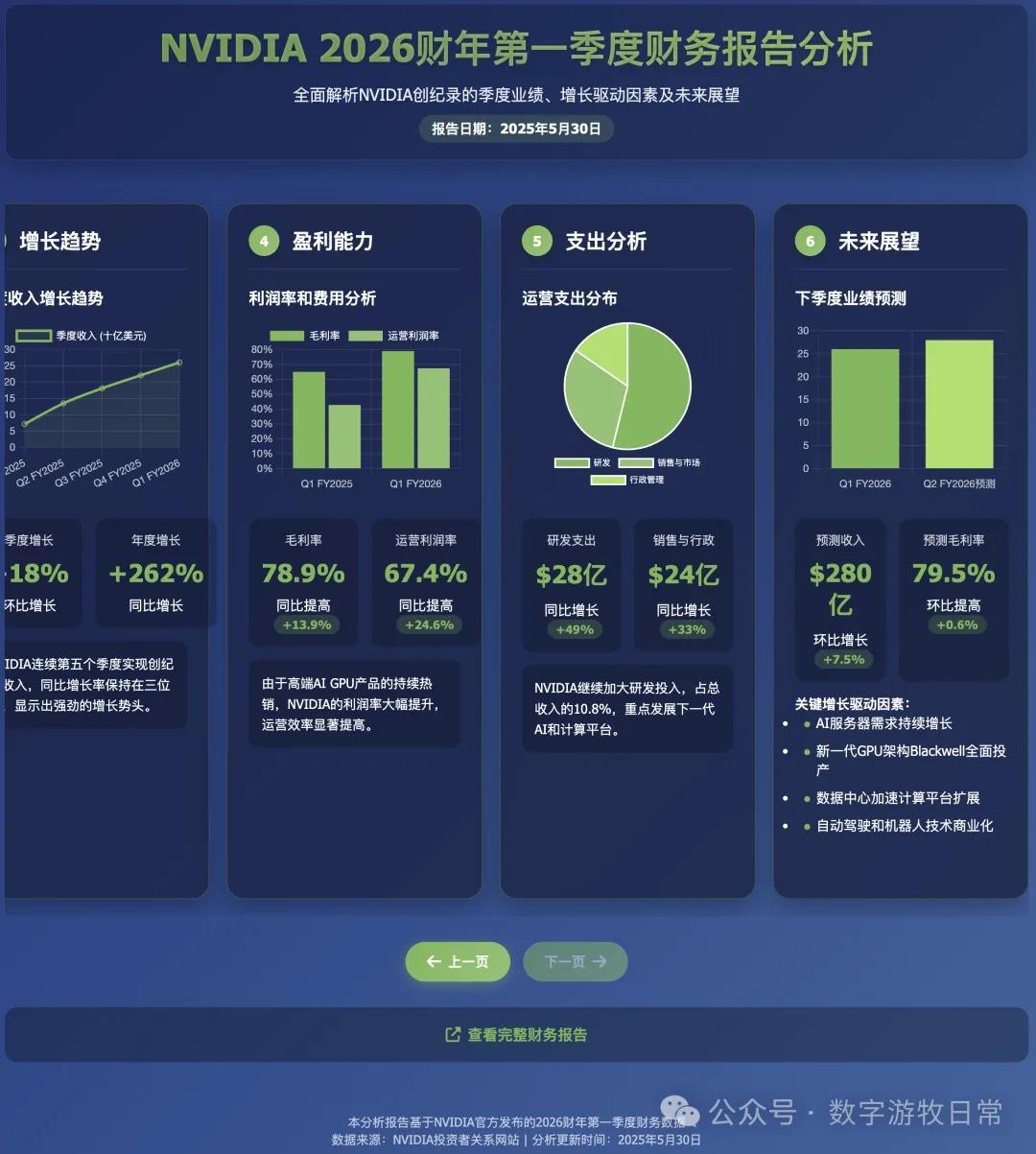
客观评价,虽然代码修改了几次,但是审美能力,页面布局,完整性相比之前的模型,是有非常显著的提升的。如果对比我昨天文章里几个模型的生成结果的话,我甚至认为这个版本是最好看的(我一直认为好看是最重要的两项能力之一)。
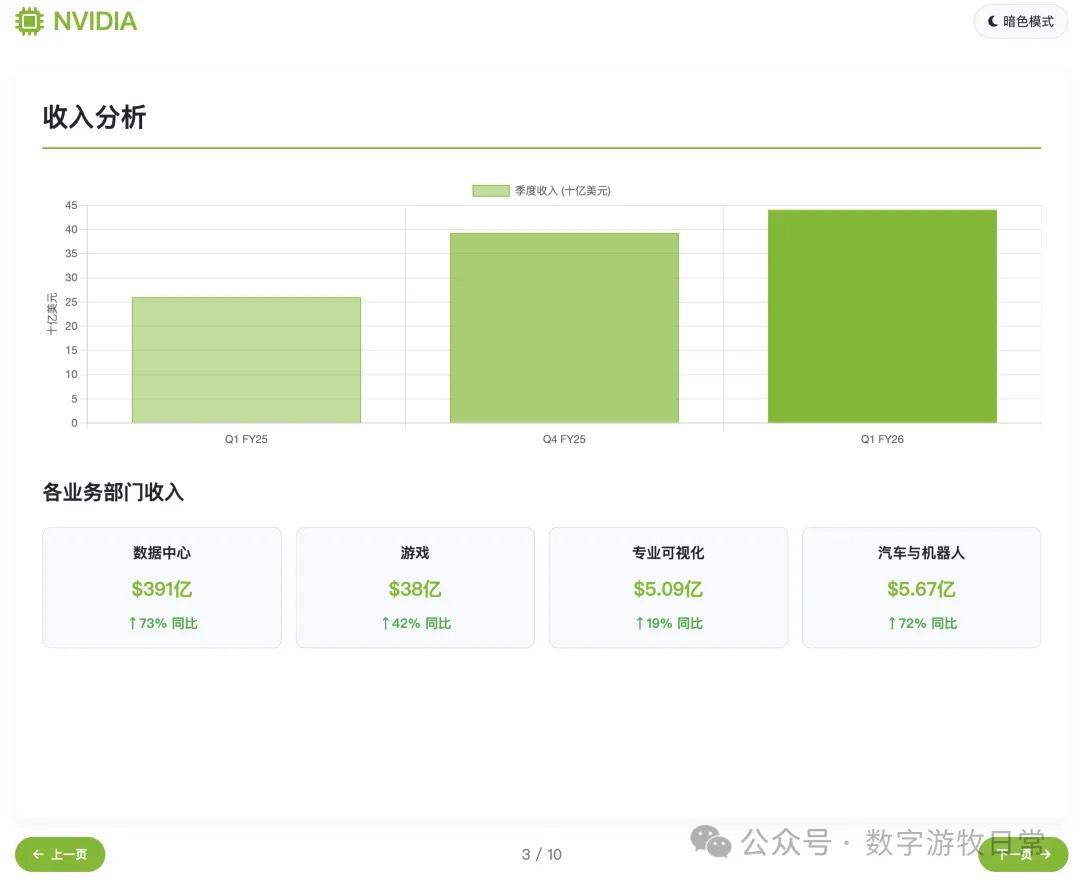
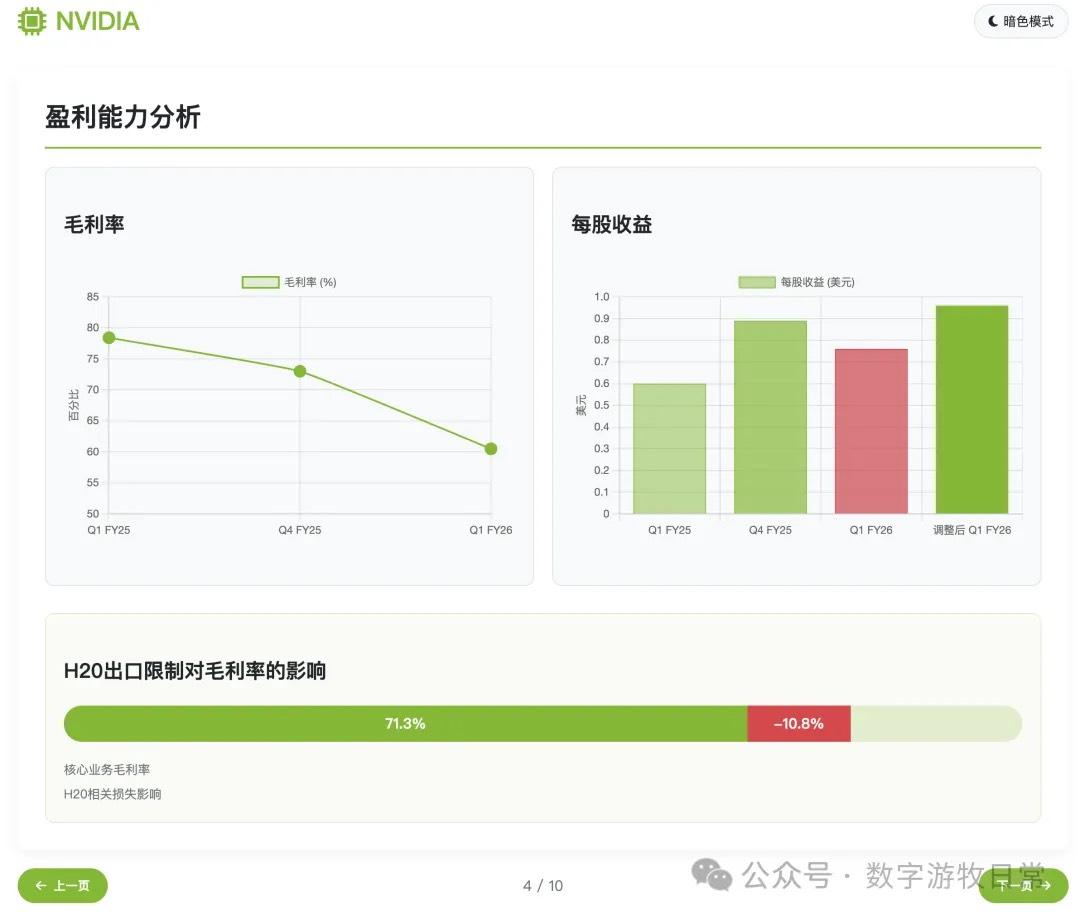
然而,如果看细节的话,数据就全部都是牛头不对马嘴了,但是这个问题见仁见智:
从批评的角度,可以说数据全是错的;
从表扬的角度,其实因为并没有直接访问给出的网页链接的信息,而更可能是直接搜索的,如果仔细对照的话,很多都是一年前的数据,也就是FY25Q1的(营收,利润,毛利这些);
当然,客观而言,我们可以“原谅”时间对齐的问题,尽管R1的思考过程明确的写了“2026财年”,但模型“不理解时间”也算是正常的。

另外,有些细节数据还是有些小问题的,比如支出类的。
附上英伟达官方的FY25Q1主要财务数据新闻稿链接,不再在这个版本里纠缠了:https://nvidianews.nvidia.com/news/nvidia-announces-financial-results-for-first-quarter-fiscal-2025。
以上的结果看起来是R1没有办法直接访问给出的FY26Q1的链接,那么,换一个提示词,在原本的提示词之下,再把链接网页里的内容全部复制粘体,再做生成。
当然,经过了几次错误调试后,结果截图如下,一共十页:
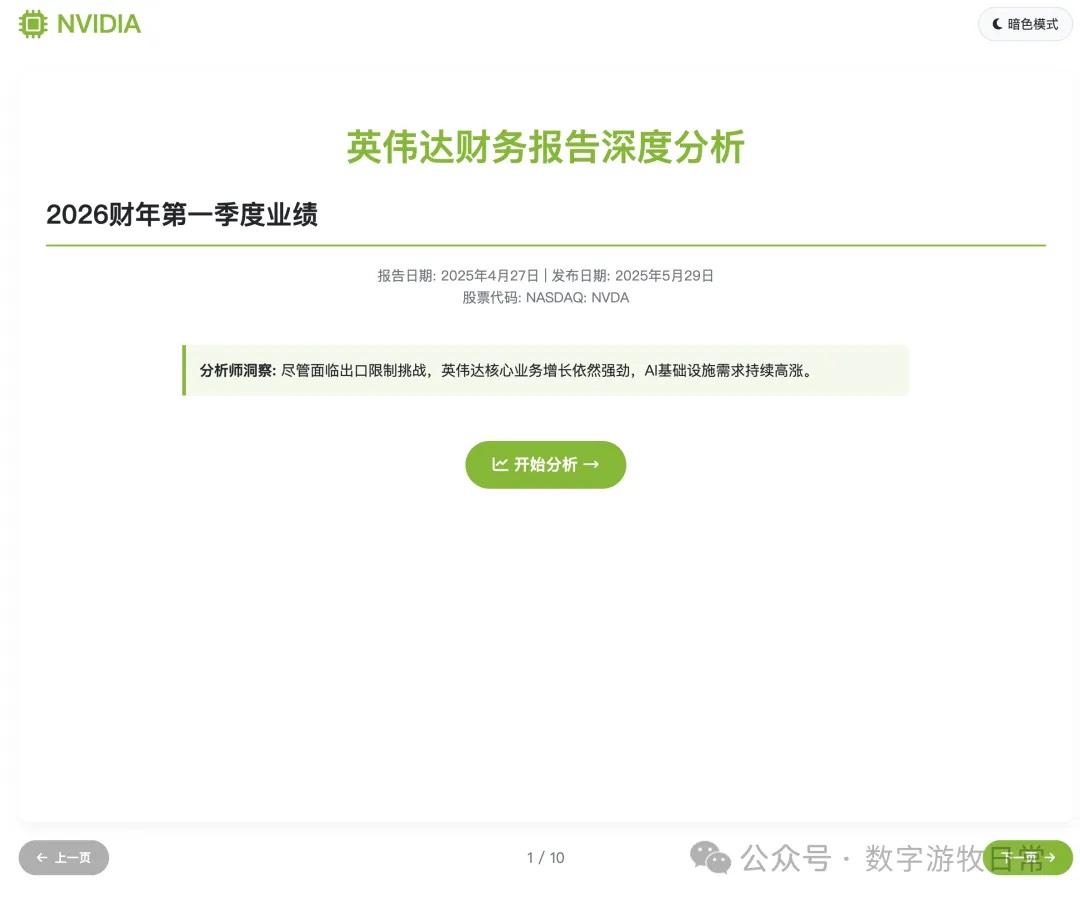
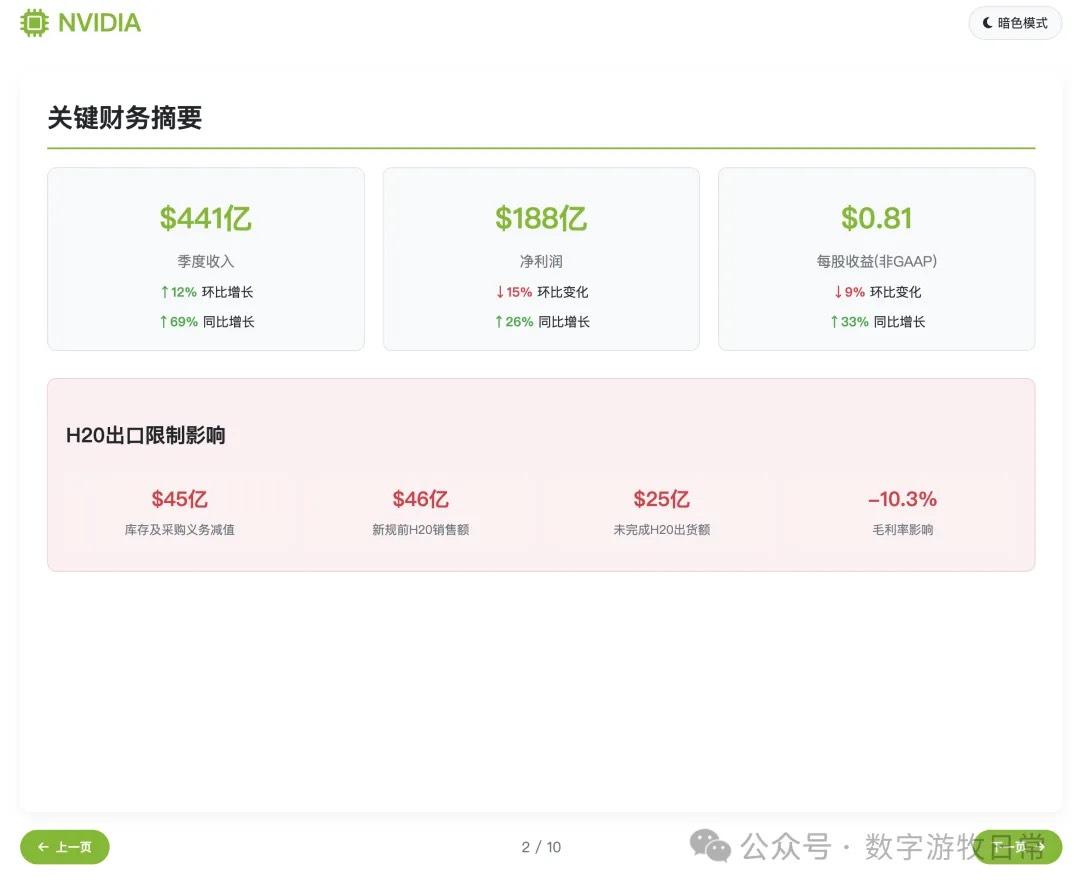
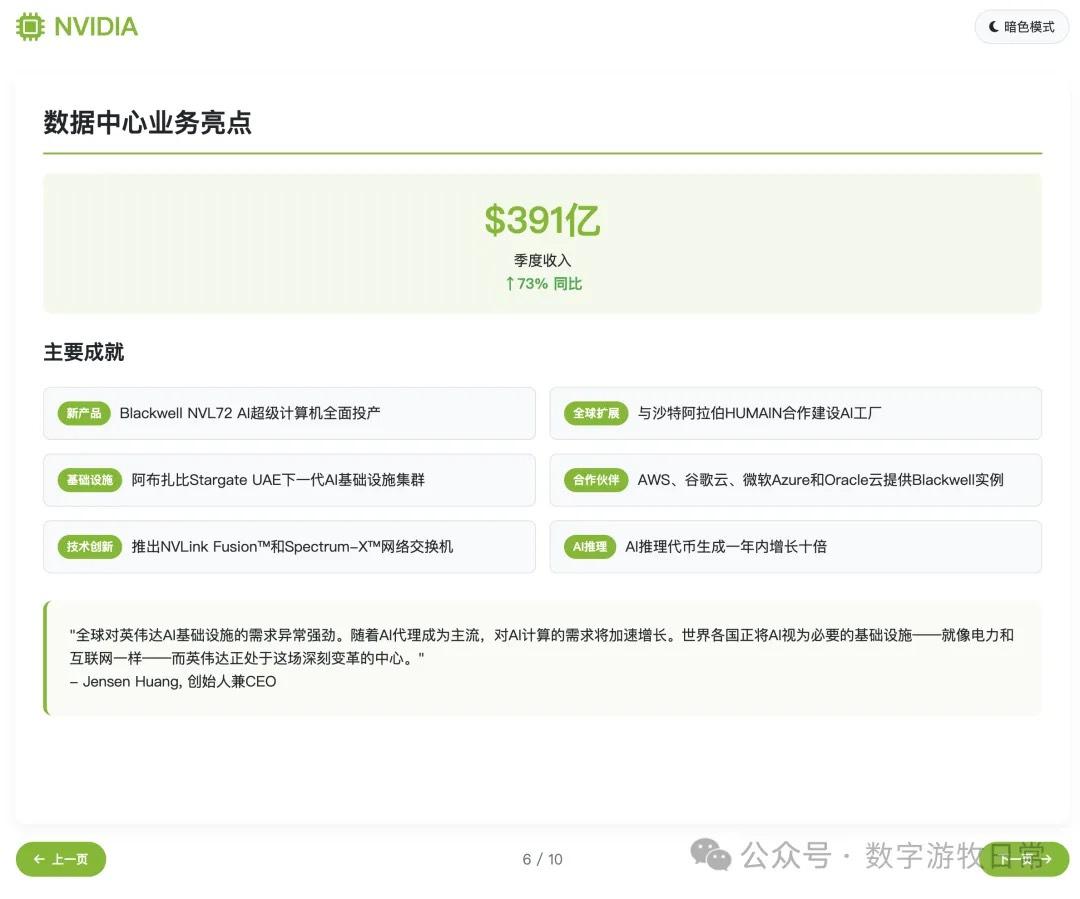
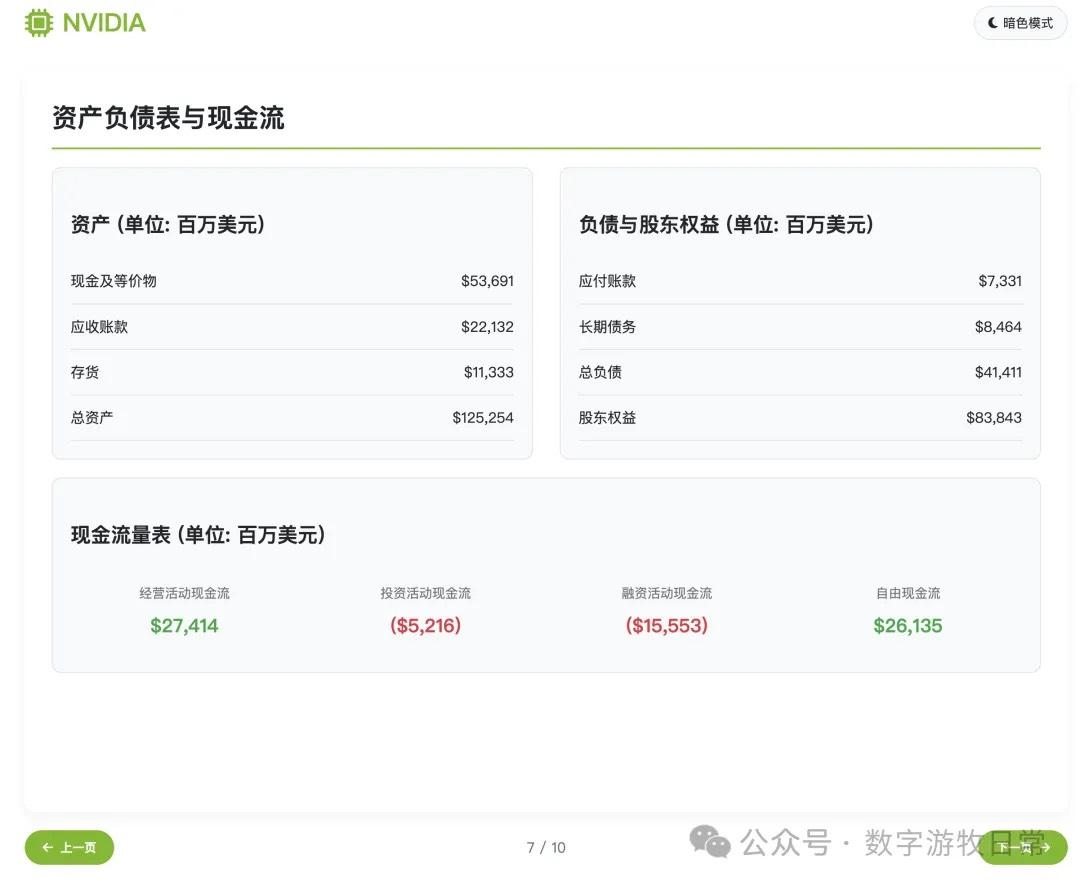
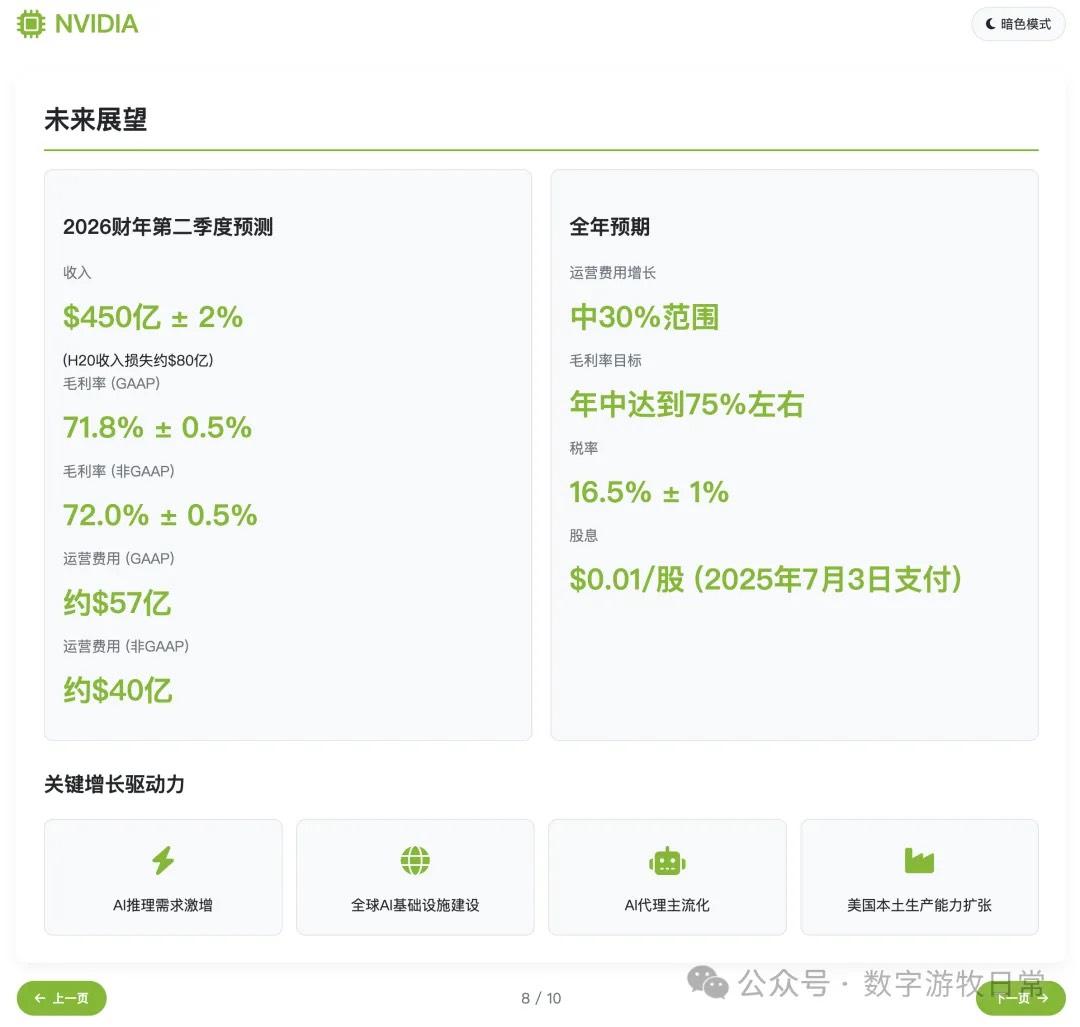

主观评价:如果不看最后一页,光是前九页的结果的话,我认为是比Claude-4(无论是Opus还是Sonnet)更好的,审美更好,细节丰富度基本相等。但是会不如Gemini-2.5-Pro和Claude-3.7。
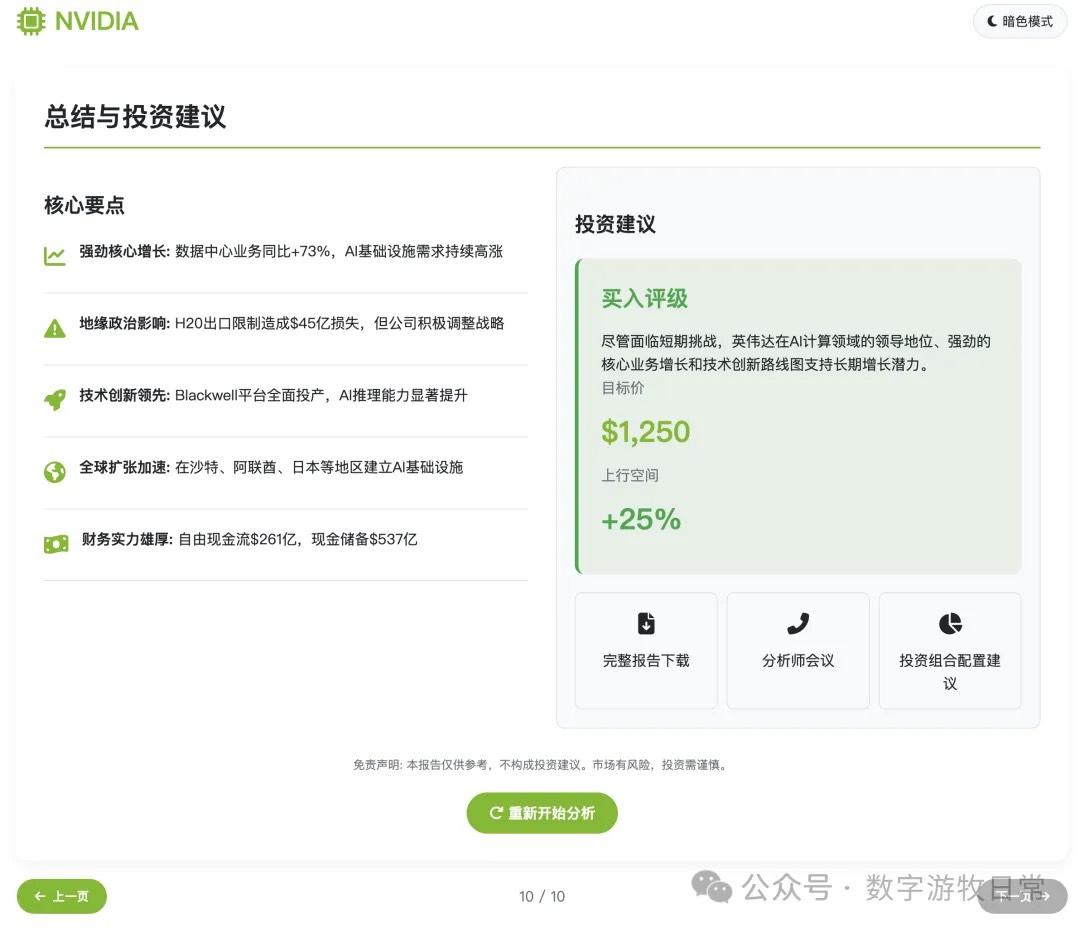
然而,如果把最后一页加上的话,那可能就要扣分了。
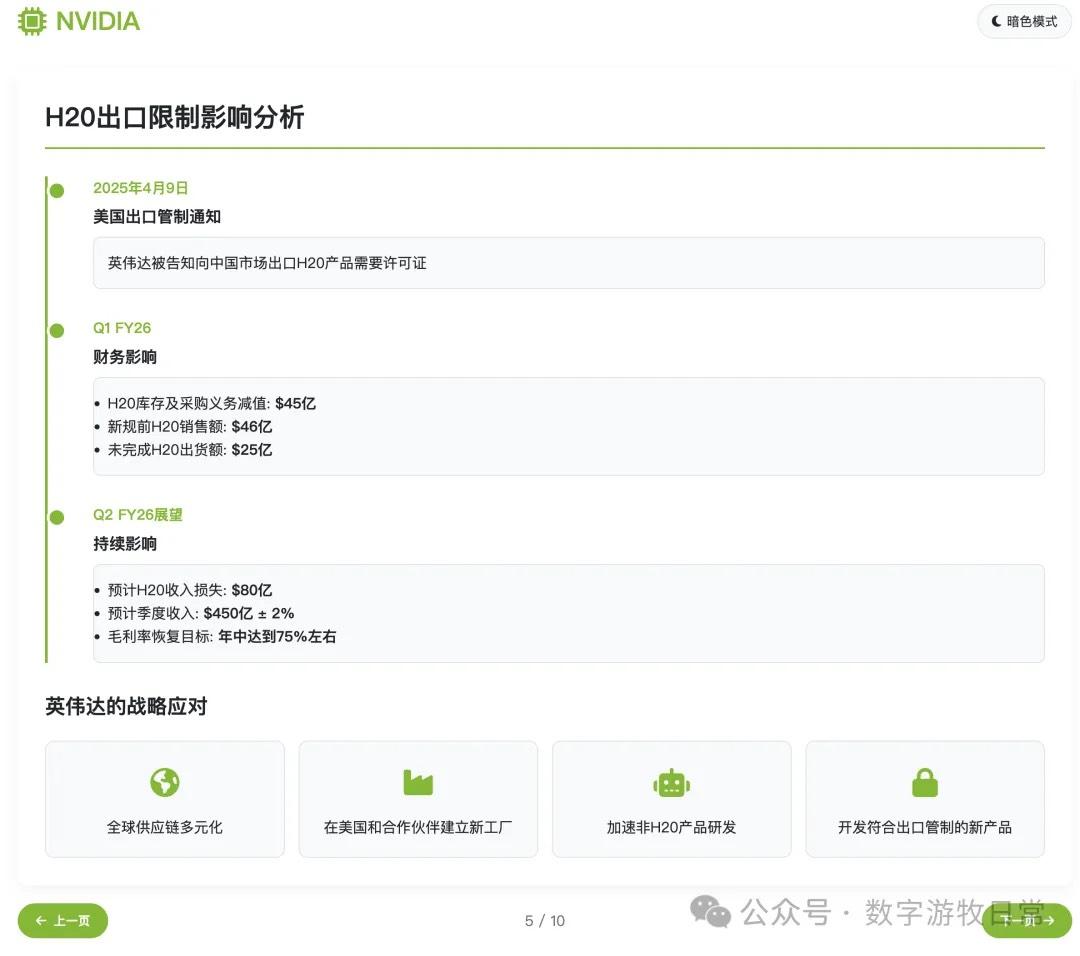
在这个版本里我没有像昨天一样去掉投资建议部分。因此,关于价格和空间的数字的错误就变得非常显著:当然我们可以理解第一个价格也许是对应的也许是没有1拆10之前的价格,但是这个空间如何来的就打下了大大的问号。
实际上,在我跟R1反复对话希望输出正确的代码的过程中,一些其他版本的结果更“吓人”,例如下面一个无法正常运行的版本的源代码里,我们可以看到文字部分:

请注意,1350和25%。
所以,我们基本可以认为,即使1250或者1350情有可原,至少,这个不变的“25%”是莫名其妙的。
最近在读平克的《理性》这本书,一个有意思的观点我不能更认同:加入很多细节可以让结果看来更理性更有说服力。
也许,这就是R1这类思考模型的“世界观”。是的,在不少场合,“思考”的加入确实让模型看起来变强大了,但是“思考”同样让模型的输出变得不可信。这里并不是单单指R1,而是所有的“思考”模型,无论是o3,Claude-4,还是Gemini-2.5,过去一段时间大量的发现“思考”模型正在过线,变得越来越“画蛇添足”,如果再叠加不够好的基础模型,或者处理不好预训练数据与输入数据(用户上传,或者搜索,等等)的平衡关系的话,就会出现上述的这种“灾难性结果”。
当初R1最令人惊艳的地方是使用少量的强化学习数据(比如解数学题的详细步骤)激发了模型“自主分步思考”的能力。但是这种思考,也促使模型“必须”要加入很多似是而非的细节,一如上述的价格和空间。从学习的语料角度出发,自然,对一家上市公司进行财务分析后大概率就是要给出投资建议的,从“要件”的角度看,这种完整没问题。
但是这种错误的联想,就是需要被克制的。实际上,Gemini-2.5平衡的不错(虽然在五月份的一段时间里一度也出现了“过线”问题,但是最近似乎又平衡回来了),Claude-3.7-Sonnet自从发布后就表现的还不错。
“过度思考”结果的强大细节会让人“一眼被征服”,但是如果对细节进行详细比较,又会被随处可见的错误“劝退”。Demis在前几天Google I/O Day上说后面的工作就是不断的“补洞(hole)”,可是虽然细节少一点但是准确率更高的结果总比满是错误的细节更有用。
当然,如果回到R1模型来说,上面的例子也暴露出了一个残酷的现实:R1暴露了基础模型能力的不足。
我们很容易理解为什么出现1250和1350这样的价格:因为底层模型数据截止时间(cut-off date)很可能在英伟达拆股之前(我没找到关于cut-off date的官方的表述)。但是,我们无法理解不同价格都是25%的原因。
实际上,对于上面的情况,ChatGPT、Gemini和Claude系列模型在去年的时候也都出现过这种时间对齐上的错误(Claude最严重),但是在开启搜索后,都基本上解决了(Claude会更晚一点,因为搜索功能是最近才有的)。这其实是基础模型的能力,而不是搜索的能力(要相信对于这种简单问题,搜索本身的结果是不太可能出错的)。当R1倾向于一定要基础模型输出结果时,它吐出了各种时间上没有对齐的预训练里的语料数据。1250 and 1350 must be based on different corpora, and 25% might come from another different corpus. Believe me, it likely didn't perform any calculations (I maintain the view that base models do not calculate).
我们都知道,R1之前的版本,幻觉率非常高,我也相信,新版的R1可能真的显著地降低了幻觉率。但是,看起来,所谓的“思考模型”依然没有摆脱我在年初文章里写的“利用强化学习实现提示词工程”的方式。
这种方式就是一把“双刃剑”,看起来可以让底层模型输出更多细节,可以在“封闭的评分榜”上刷出更高的分,但是过度的挖掘细节,也产生了更多的错误。