The DeepSeek-R1 model has been updated to version DeepSeek-R1-0528. Articles praising it are already everywhere, so I won't rehash that. Yesterday, I conducted a model comparison between Claude-4, Claude-3.7, Gemini-2.5, and ChatGPT-o3 based on Nvidia's financial report. I originally intended to include the results for the latest R1 model, but there were some issues with the output. It wasn't until today that I could generate proper results, so I'm discussing it in this article instead.
For results from other models, refer to yesterday's article: Comparing several models' financial analysis of Nvidia—this is why I prefer Gemini-2.5 and Claude-3.7.
Someone in the comments asked for the prompt, so here it is again:
Gen a highly detailed professional interactive react slides to analyze the following financial report of Nvidia with the link
https://nvidianews.nvidia.com/news/nvidia-announces-financial-results-for-first-quarter-fiscal-2026 in Chinese, please integrate code into one html file
Yesterday, when I gave the same prompt to DeepSeek-R1, two problems arose. First, the generated code was consistently buggy; DS's code modification capability still lags significantly behind Claude, which took some time to resolve. Second, although a link was provided, it seemed that R1 could not successfully access the page to obtain accurate data even with the search function turned on (the screenshots below show numerous data errors). Coupled with DeepSeek's current rate-limiting, it took a significant amount of manual debugging until the model finally outputted code with a functioning visual effect.
Screenshots of the results are as follows:
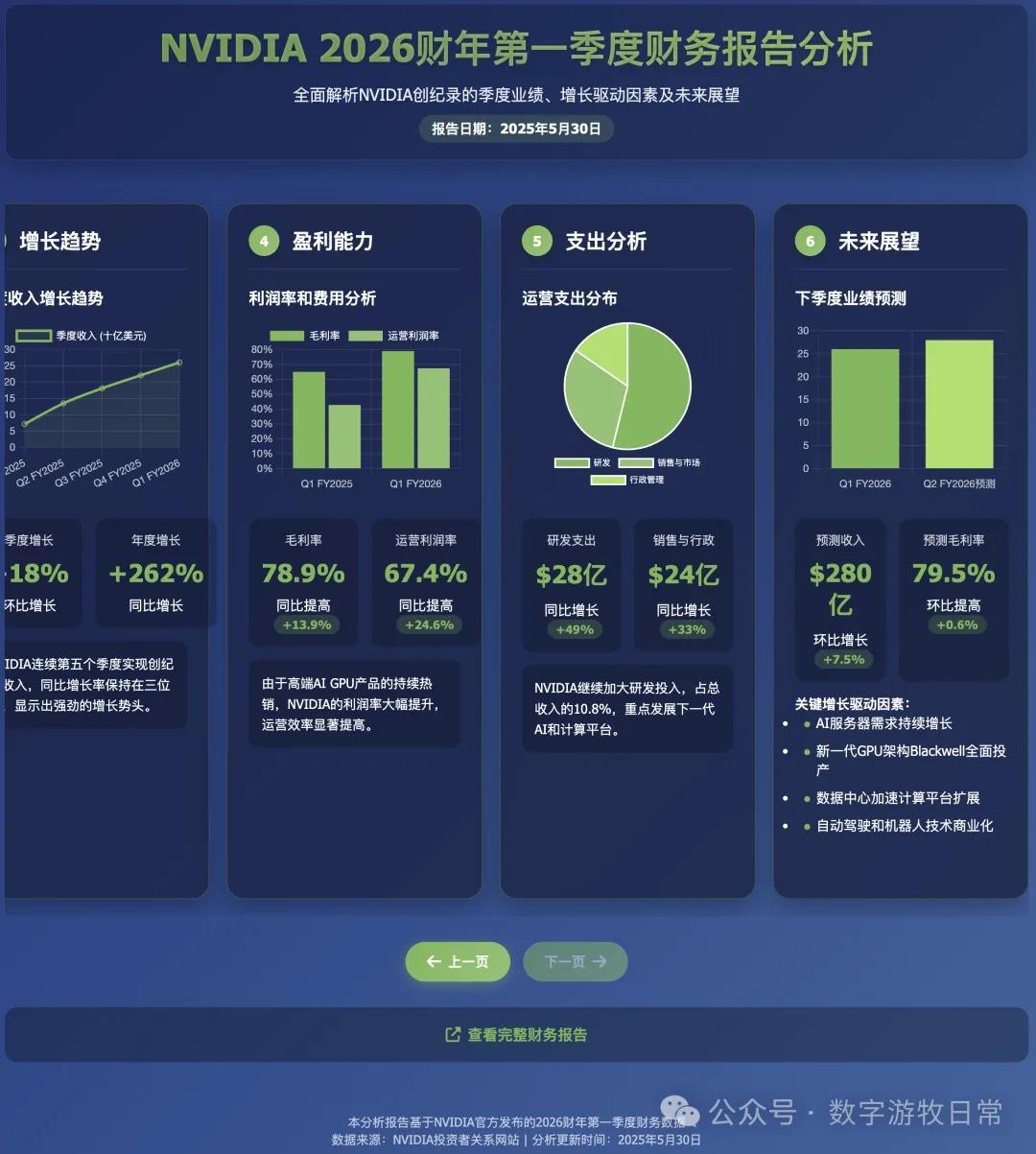
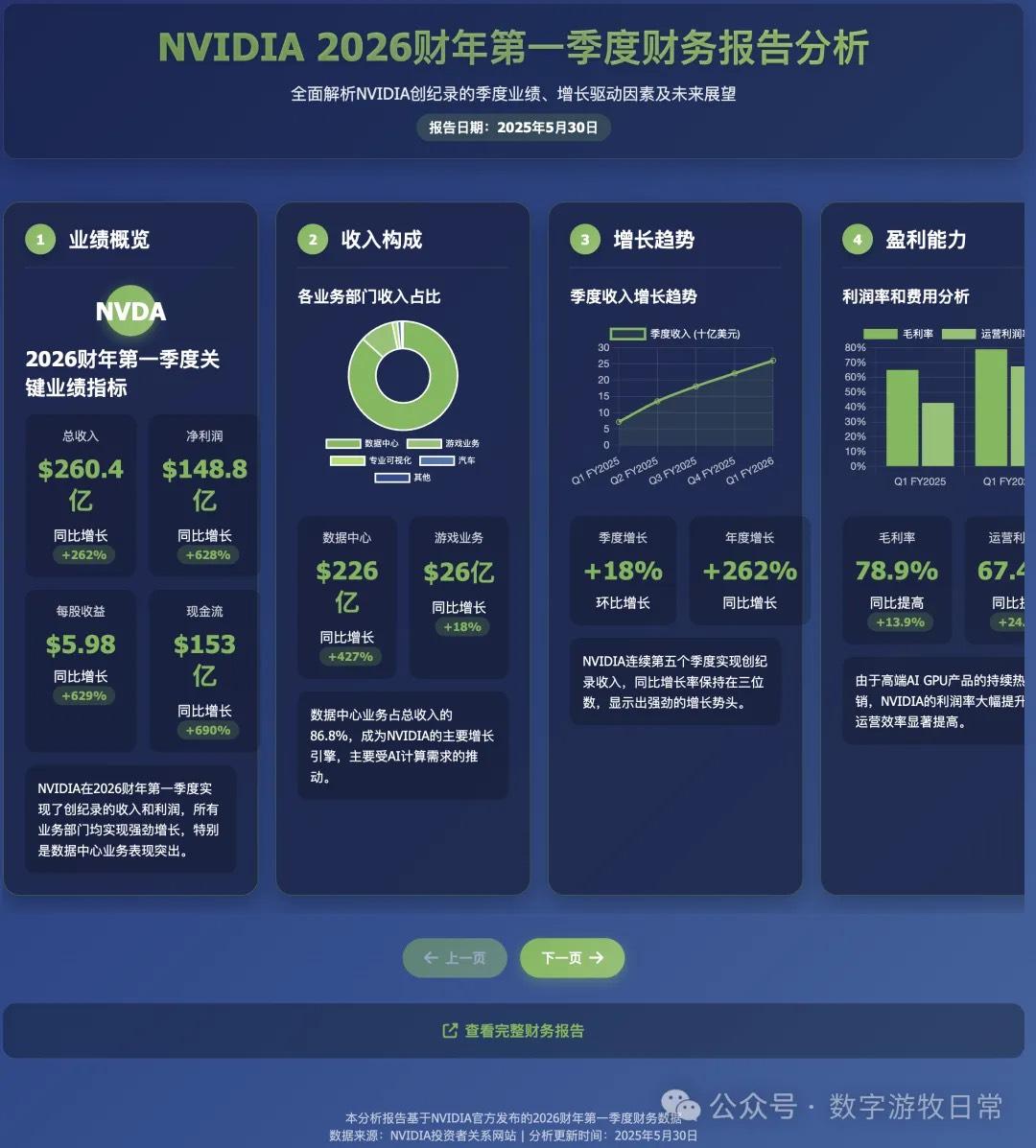
Objectively speaking, although the code required several revisions, the aesthetic sense, page layout, and completeness have significantly improved compared to previous models. If compared to the results from the models in yesterday's article, I would even argue that this version looks the best (I have always believed that aesthetics is one of the two most important capabilities).
However, if you look at the details, the data is completely nonsensical. This is a matter of perspective:
From a critical standpoint, one could say the data is entirely wrong;
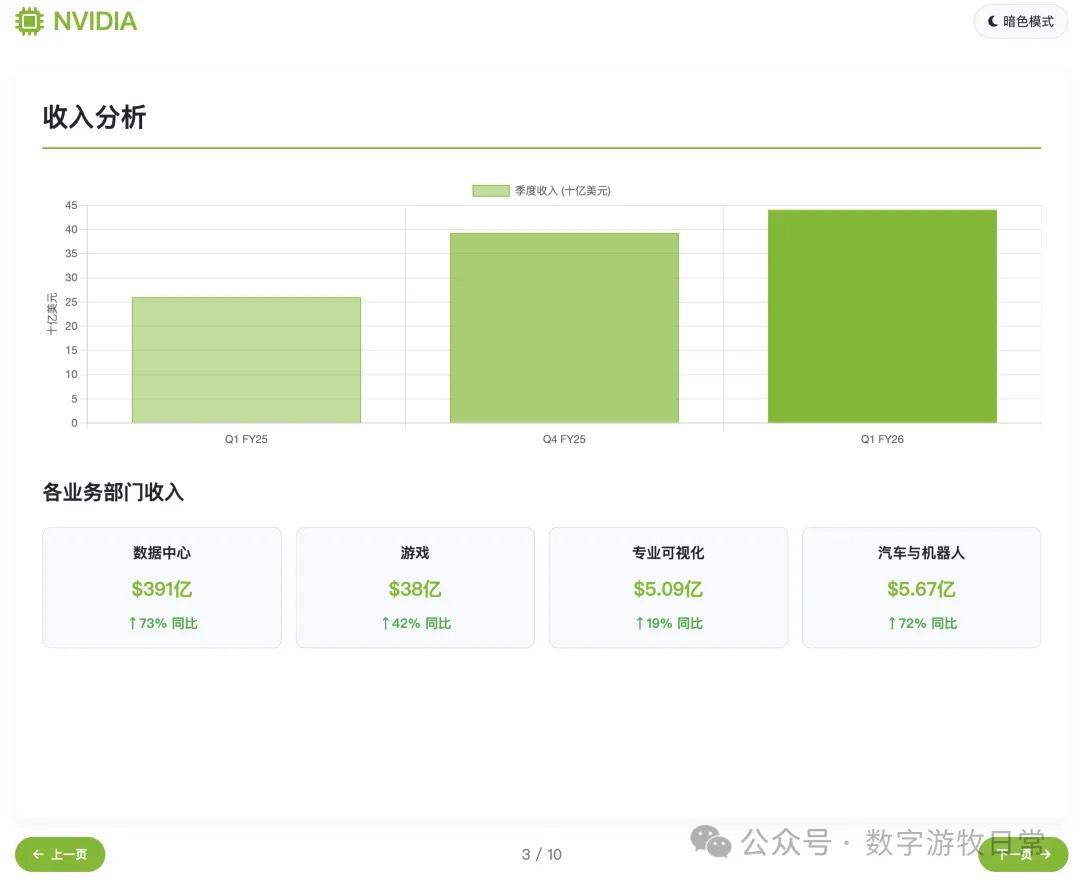
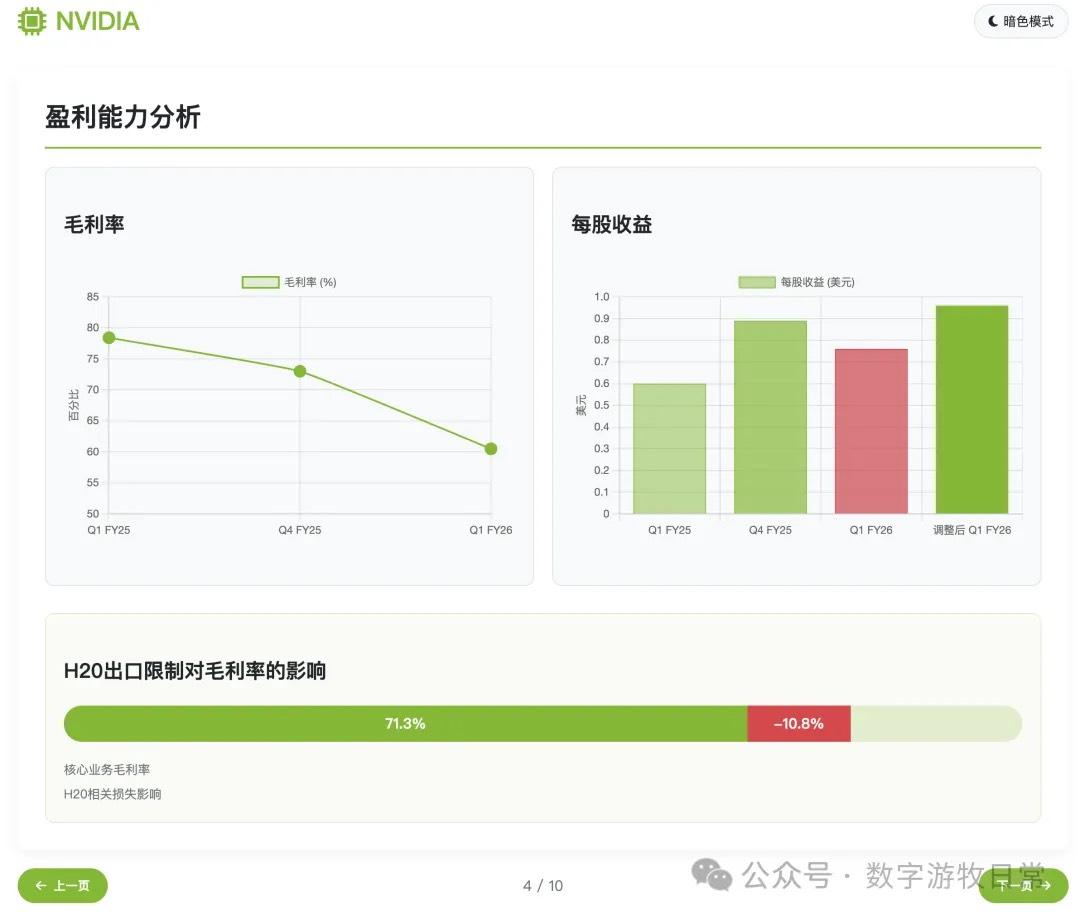
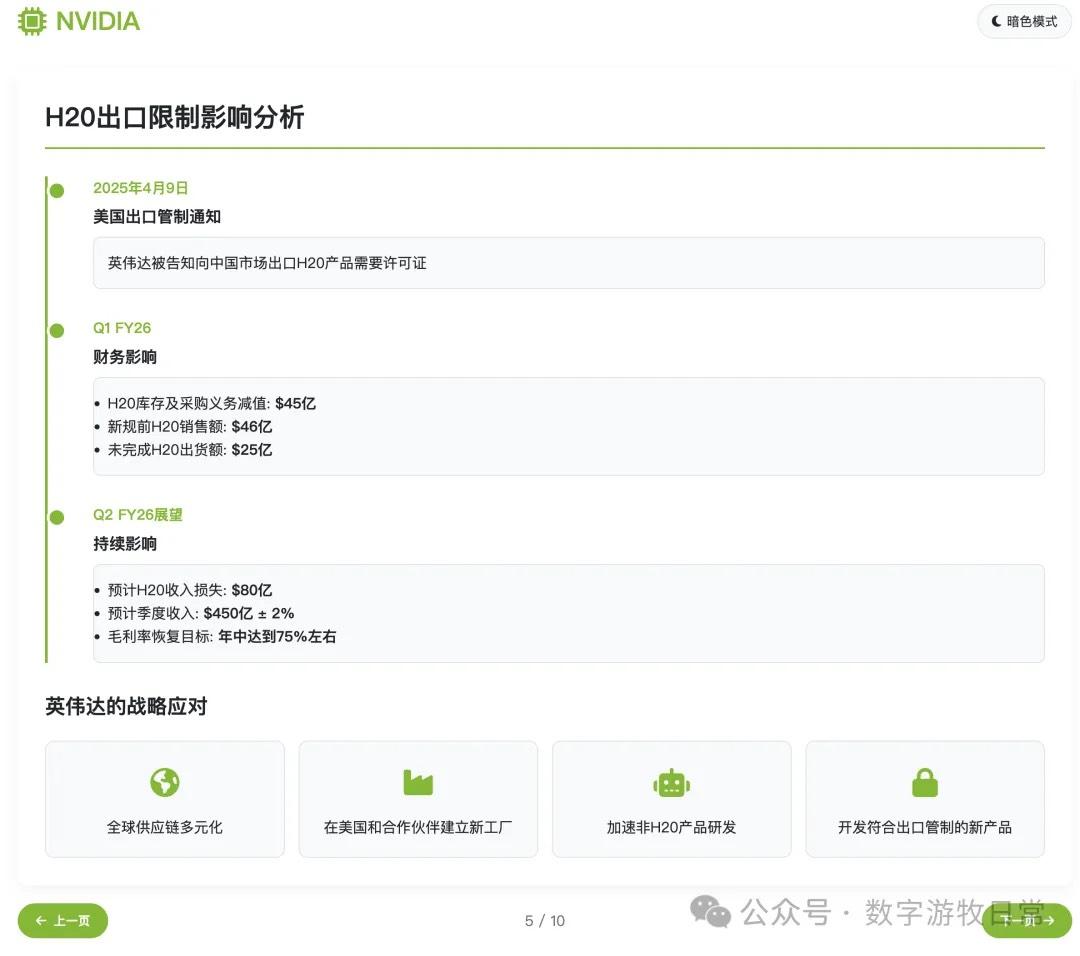
From a complimentary standpoint, because the model didn't directly access the provided link but likely relied on search results, a closer look reveals much of the data is from a year ago—specifically FY25Q1 (revenue, profit, gross margin, etc.);
Of course, objectively, we can "forgive" the time alignment issue. Although R1's chain of thought explicitly wrote "FY2026," it's normal for models to not truly "understand time."

Additionally, there were small issues with some detailed data, such as expense categories.
Attaching Nvidia's official FY25Q1 financial results press release link for reference; I won't dwell on this version further: https://nvidianews.nvidia.com/news/nvidia-announces-financial-results-for-first-quarter-fiscal-2025.
Since the above results suggest R1 cannot directly access the provided FY26Q1 link, I changed the prompt: under the original prompt, I copy-pasted the entire content of the linked webpage and re-ran the generation.
After several rounds of debugging, here are the screenshots of the results, totaling ten pages:
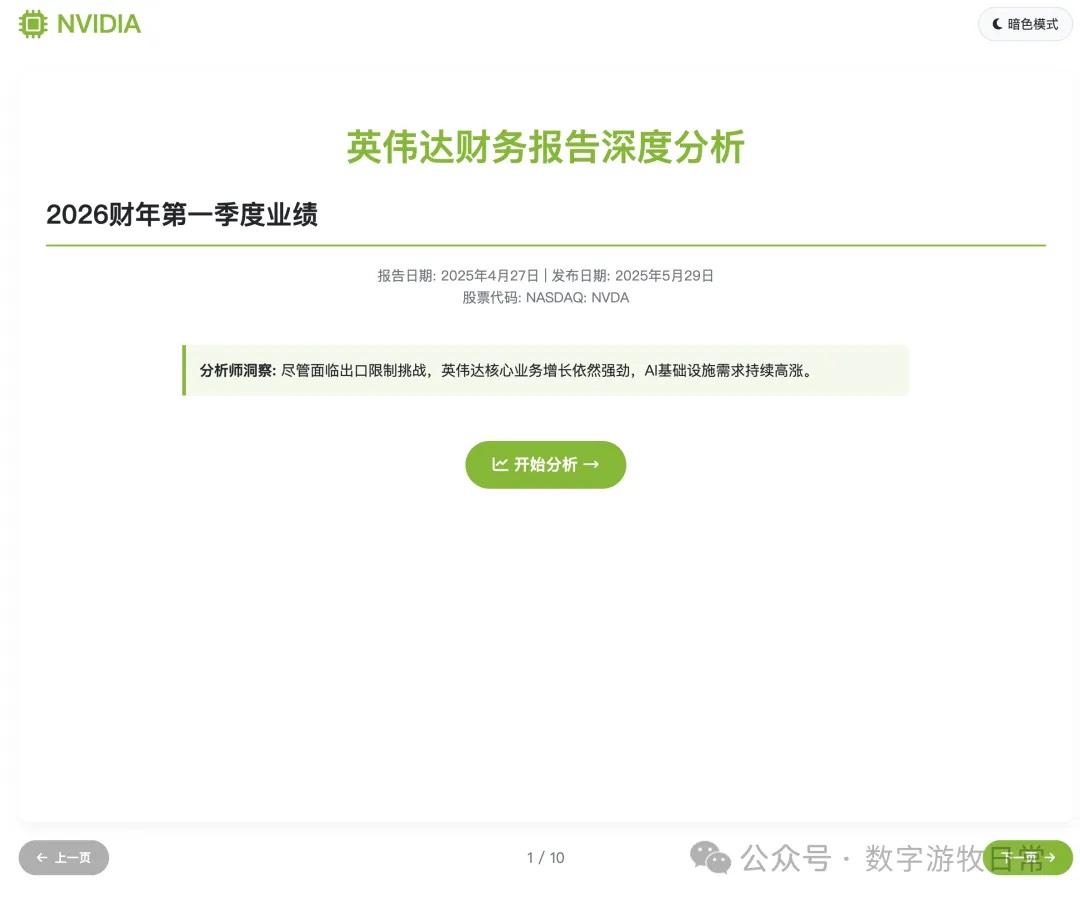
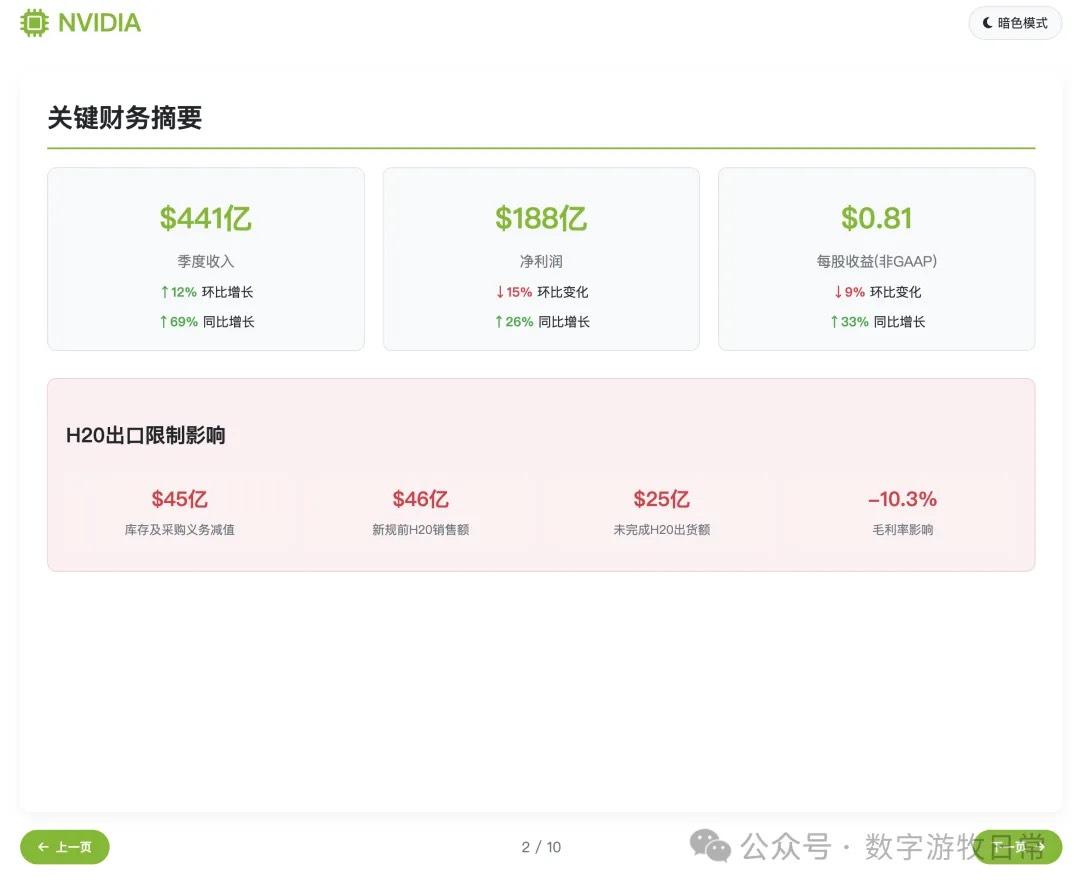
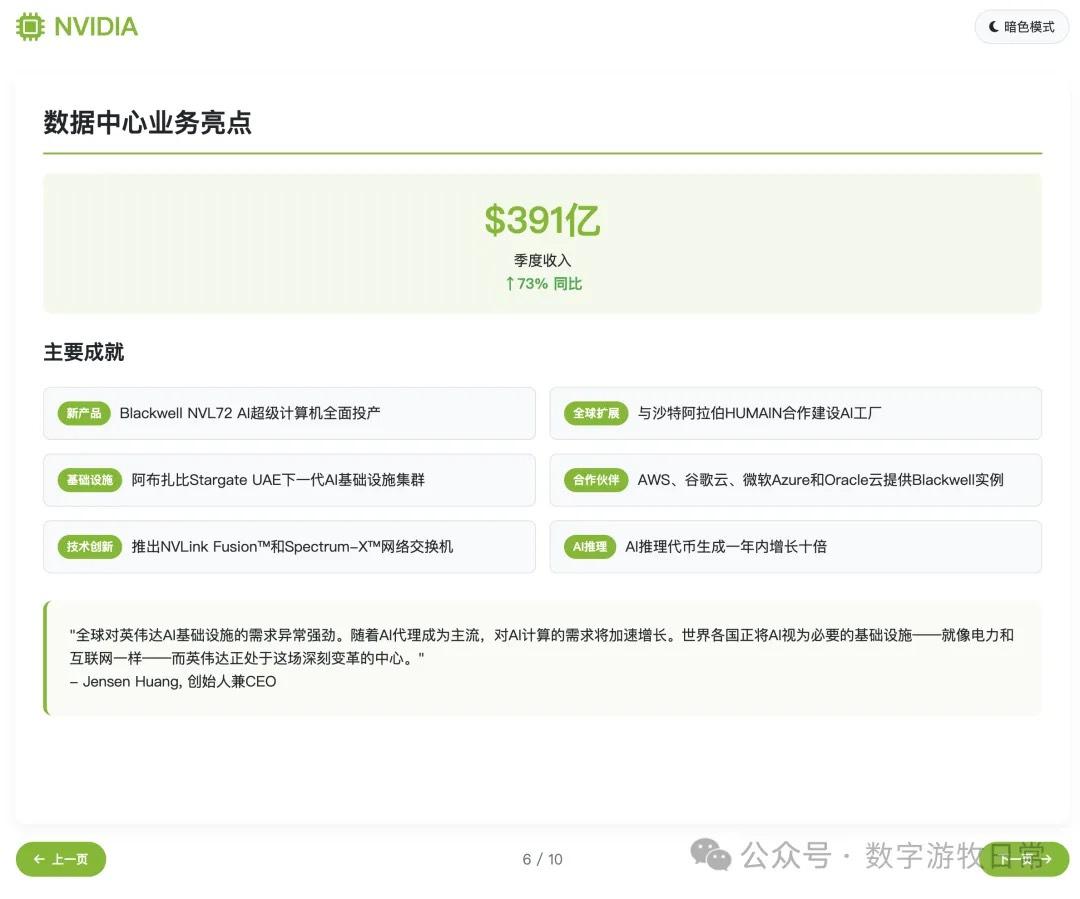
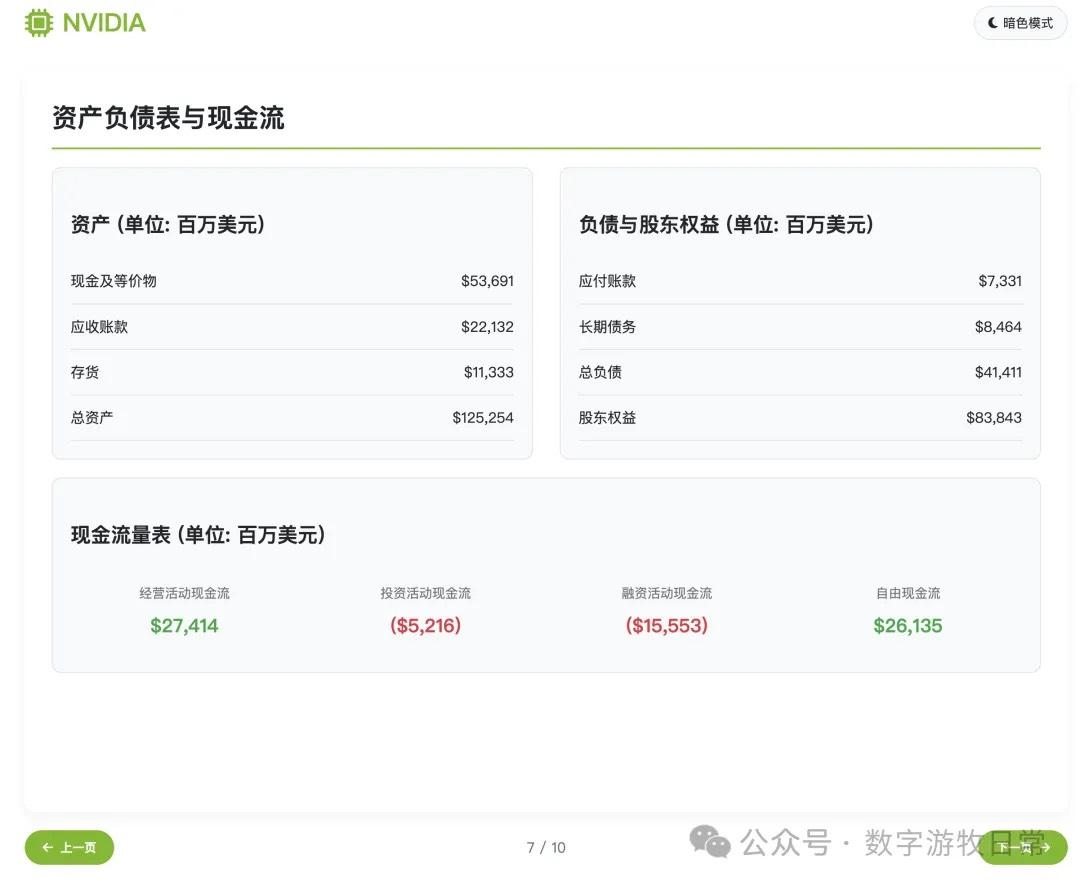
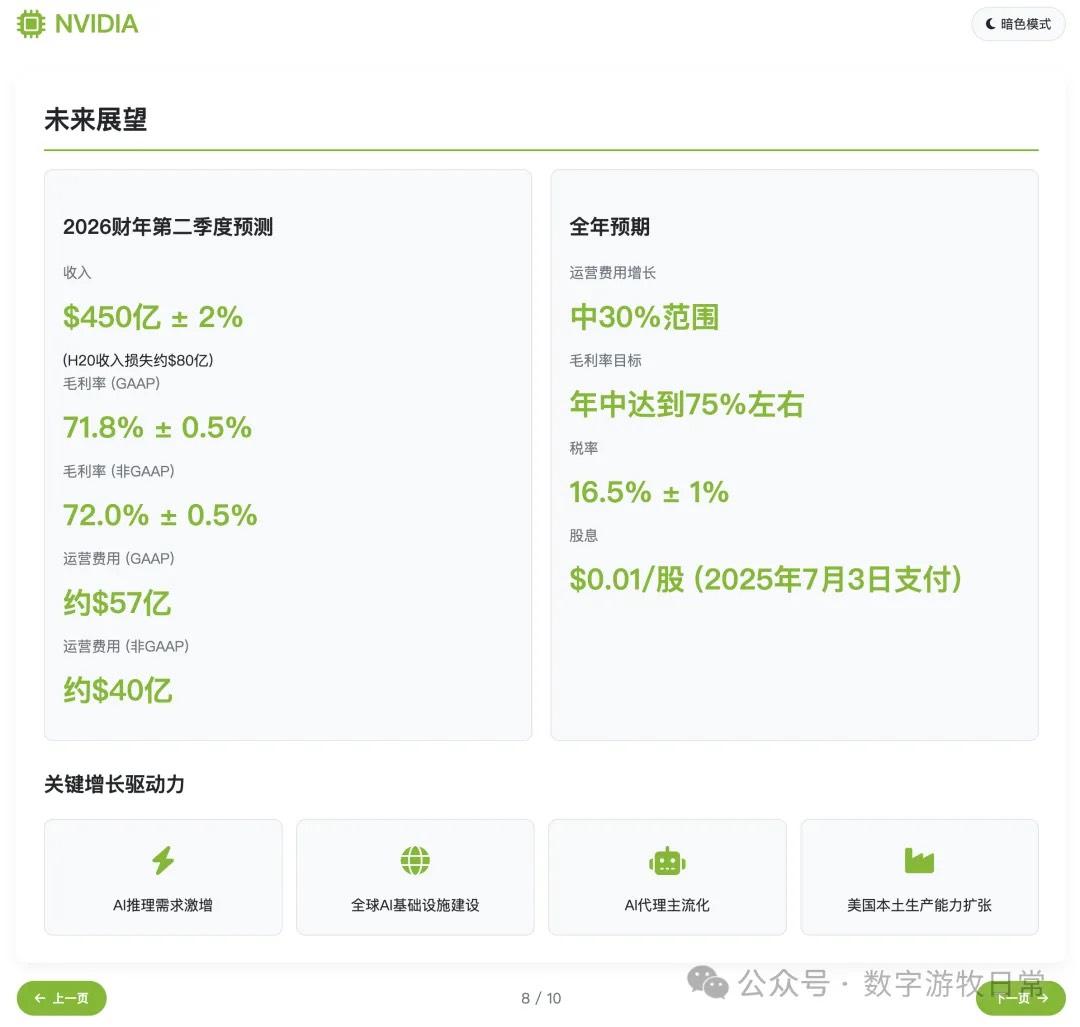

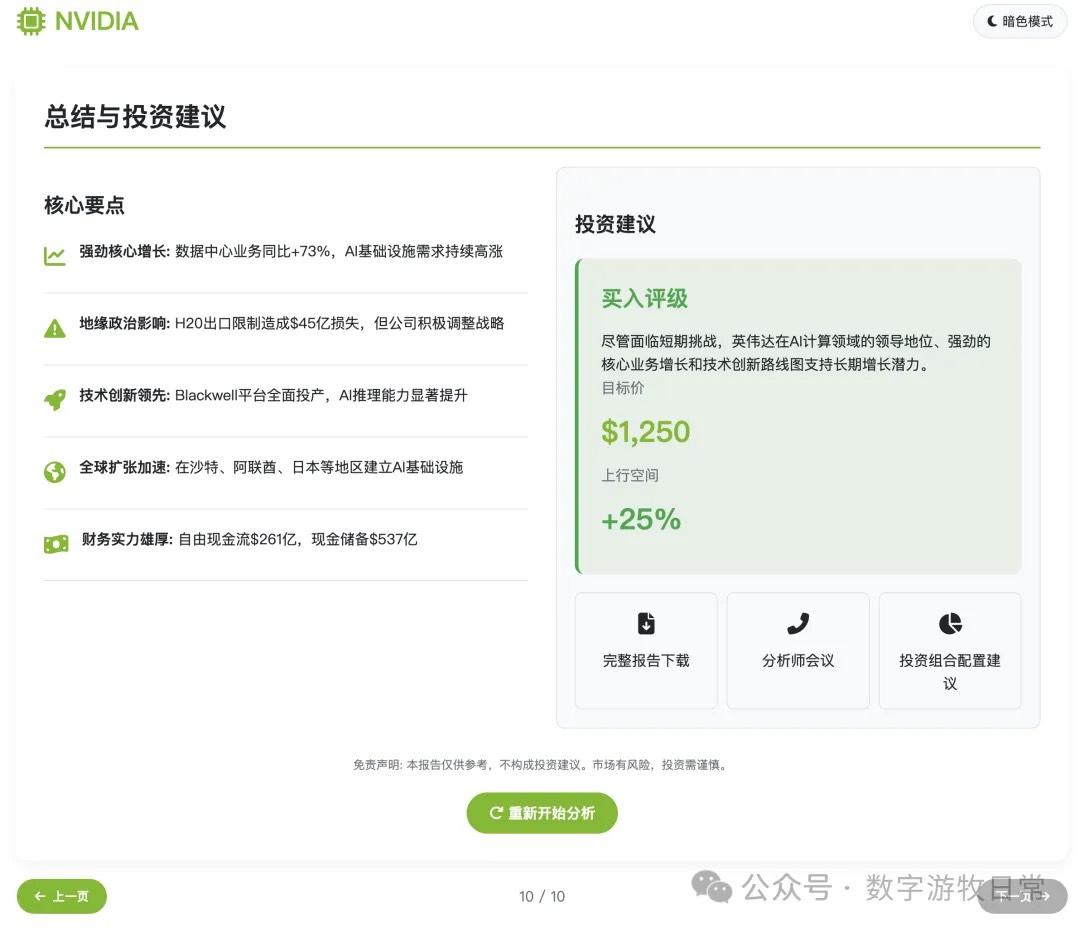
Subjective evaluation: If you ignore the last page and just look at the first nine, I believe the results are better than Claude-4 (both Opus and Sonnet), with better aesthetics and roughly equal detail richness. However, it is not as good as Gemini-2.5-Pro or Claude-3.7.
However, if you add the last page, points must be deducted.
In this version, I did not remove the investment advice section as I did yesterday. Consequently, the errors regarding price and growth space figures became glaring: while we might understand the first price corresponds to the value before the 1-for-10 stock split, where the "growth space" figure came from remains a giant question mark.
In fact, during my repeated interactions with R1 to output the correct code, some other versions produced even more "alarming" results. For example, in the source code of a version that failed to run, we can see this text:

Please note the figures 1350 and 25%.
Essentially, even if 1250 or 1350 are somewhat justifiable, this static "25%" is completely inexplicable.
I've been reading Steven Pinker's book "Rationality" recently, and I couldn't agree more with one point: adding lots of details can make a result appear more rational and persuasive.
Perhaps this is the "worldview" of reasoning models like R1. Yes, in many cases, the addition of "thinking" makes the model appear more powerful, but it also makes the output less trustworthy. This doesn't just apply to R1, but all reasoning models—whether it's o3, Claude-4, or Gemini-2.5. Over the past period, many have noticed that reasoning models are crossing the line, becoming increasingly redundant. If combined with a subpar base model or poor balancing between pre-training data and input data (user uploads, search results, etc.), you get the "catastrophic results" mentioned above.
Initially, the most stunning thing about R1 was using a small amount of reinforcement learning data (like detailed steps for solving math problems) to trigger the model's ability for "autonomous step-by-step reasoning." However, this thinking also compels the model to include many plausible-sounding but incorrect details, like the price and growth space mentioned above. From the perspective of learning corpora, a financial analysis of a listed company will likely conclude with investment advice; from a "structural requirement" standpoint, this completeness is fine.
But this kind of erroneous association must be restrained. Gemini-2.5 balances this quite well (though it briefly crossed the line in May, it seems to have rebalanced recently), and Claude-3.7-Sonnet has performed well since its release.
The powerful details of "over-thinking" can conquer a user at first glance, but a detailed comparison reveals errors that will push them away. Demis said at Google I/O Day that the upcoming work is about constantly "plugging holes," but results with fewer details and higher accuracy are always more useful than those full of detailed errors.
Regarding the R1 model specifically, the examples above also expose a harsh reality: R1 reveals deficiencies in the underlying base model's capabilities.
It's easy to understand why prices like 1250 and 1350 appear: the cut-off date of the underlying model's data is likely before Nvidia's stock split (I couldn't find an official statement on the cut-off date). However, it is impossible to understand why different prices are all associated with a 25% growth figure.
In fact, ChatGPT, Gemini, and the Claude series all had similar time-alignment errors last year (Claude was the worst), but these were largely resolved after search functionality was enabled (Claude was later, as its search is recent). This is a capability of the base model, not the search engine (believe me, for such simple questions, the search results themselves are unlikely to be wrong). When R1 is inclined to have the base model output results at all costs, it spits out various unaligned pre-training corpora. 1250 and 1350 must be based on different corpora, and 25% might come from another different corpus. Believe me, it likely didn't perform any calculations (I maintain the view that base models do not calculate).
We all know that versions prior to R1 had very high hallucination rates, and I believe the new R1 has indeed significantly reduced them. However, it seems that so-called "reasoning models" have still not escaped the method of "using reinforcement learning to achieve prompt engineering" that I wrote about at the beginning of the year.
This method is a double-edged sword: it allows the underlying model to output more detail and score higher on "closed leaderboards," but excessive mining for details also generates more errors.