写下这个标题的时候,我依然深度依赖Deep Research,但是在过去的几个月里,只要有可能,我都在尝试完全依靠IDE工具(我只使用Cursor,但是我相信Windsurf,Trae等也一样),完成我的目标。
在一些中级难度和产出要求的场景下,我已经实现了这个目标。例如批量信息的搜索与知识图谱的生成,例如内部培训材料的准备,比如摄影相关一般内容性网站的建设……
在这个过程中,我已经完全摆脱了MCP,90%以上可用的MCP都高度依赖原生API,那么直接生成代码使用就好了,不必要在MCP环节增加不确定性。
当然,在可见的很长一段时间里,我依然摆脱不了对Deep Research的依赖,因为无论OpenAI还是Google,都把这个产品优化的很好(当然在Gemini-2.5的5月6号的版本更新后,Gemini's Deep Research可见的变差了)。可是它依然存在难以在目前架构下解决的问题:
- 最突出的,就是无法进行增量更新。尽管我们可以在一个对话session里完成几次深度研究,用户也可以很认真的告诉模型“对XX部分进行扩充和更新”,但是结果往往不如我们所愿;
- 无法进行批量的标准化输出。例如,我们要对一个话题的十个子话题分别进行深度研究,并且希望每个子话题间用同样的研究方法,同样的输出格式。是的,当我们对模型提出上述要求时,模型会“告诉我们它理解了”,但是结果依然会让我们失望;
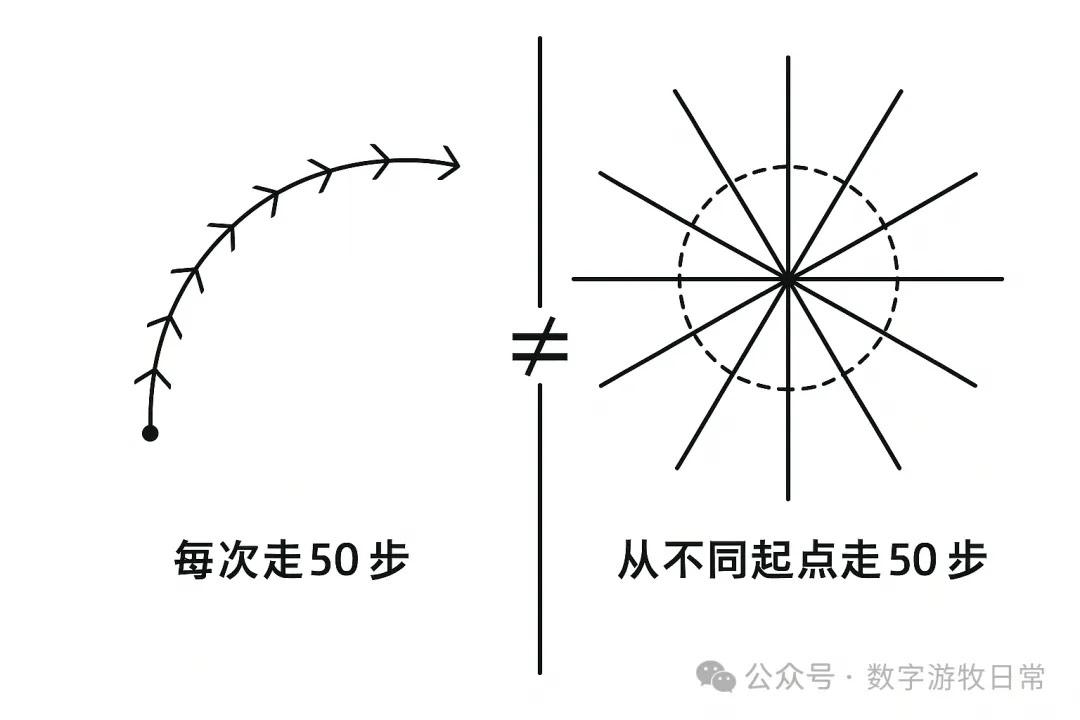
简而言之,尽管目前的Deep Research是一个工程化的实现,但它无法在一个工程化的架构下进行持续迭代式的产出:我们需要按照一个节奏走出1000步,但是这个目标无法通过每次从不同的起点走50步,然后进行20次的方式获得。它不会让我们得到一条清晰路径的曲线,更可能的是从一个圆环上不同点向外发散的类似于星芒的形状。
上面的插图也是一个很好的例子:当我把前面一段描述给到GPT-4o并让她生成一张图时,在两轮对话后,它返回了上面这张。
是的,大体上,这张图呈现了我要表达的意思,却总有些出入。然而,我基本上无法再通过“对话”的形式修正其输出,以达到100%或者95%准确的意图表达。
这不能完全说是模型的问题,还有很大部分我的问题:即使我脑子里有一个画面,我也可能无法很准确的以模型能够理解的方式用语言表达出来。
写到这里,我跳出了目前的“书写进程”,尝试手绘了一个存在于大脑里的概念草图:既然文字的理解有偏差,那么多模态下图形的理解应该会有帮助。
是的,下面三张图呈现了再输入图形后,又通过文字指令进行局部修正的输出过程。
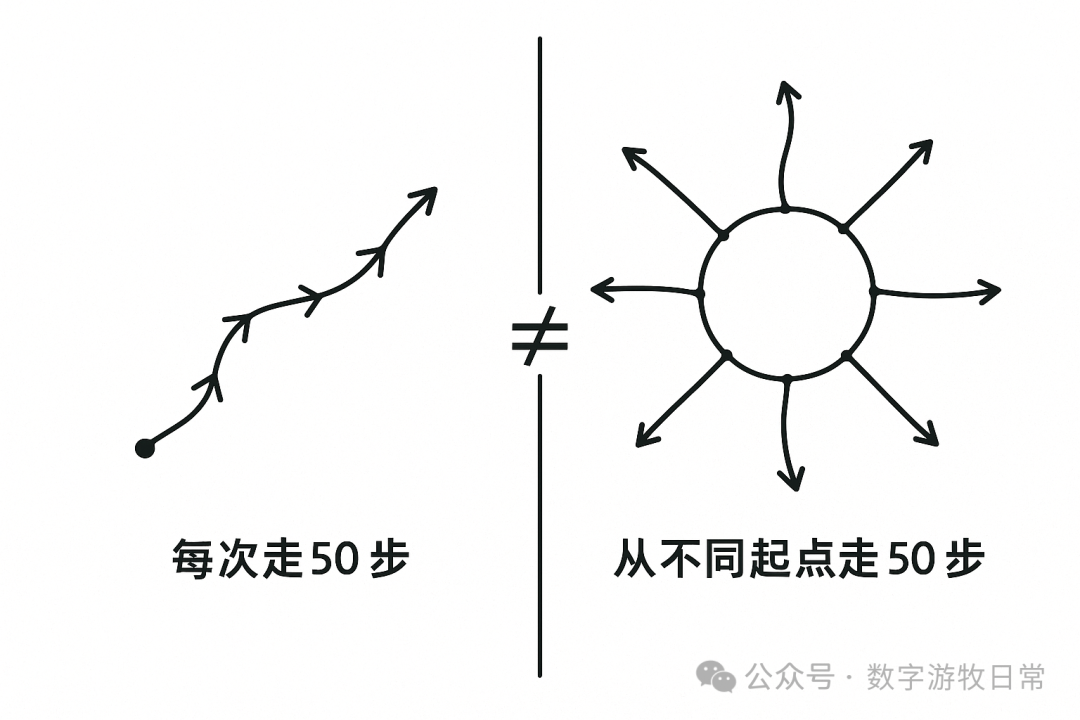
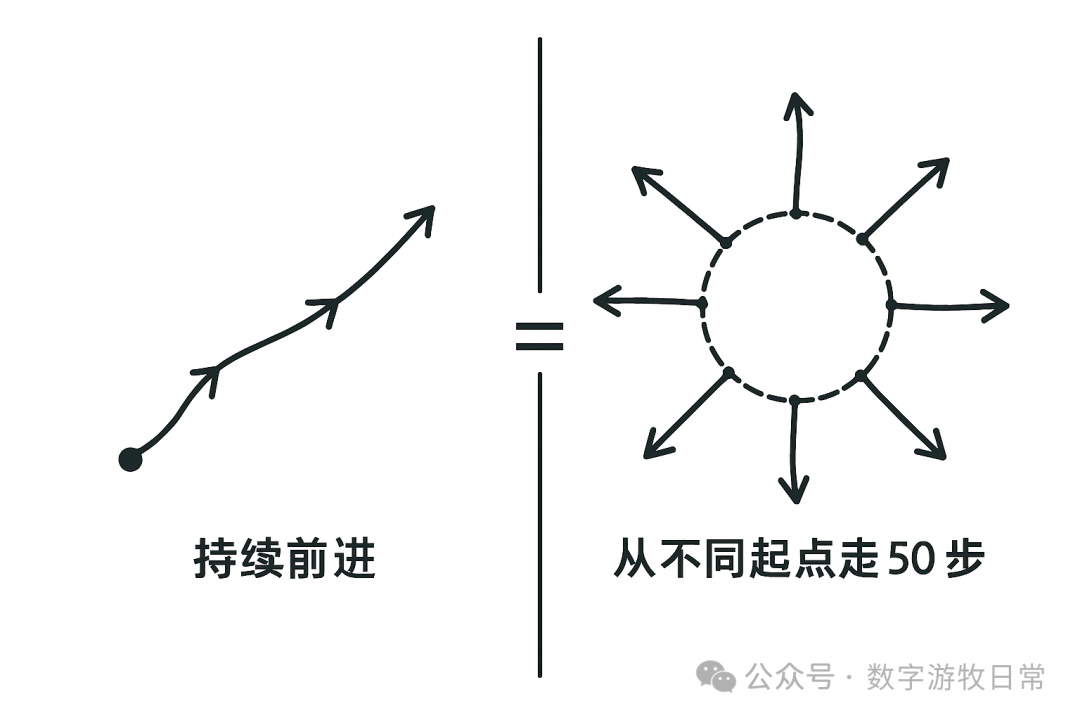
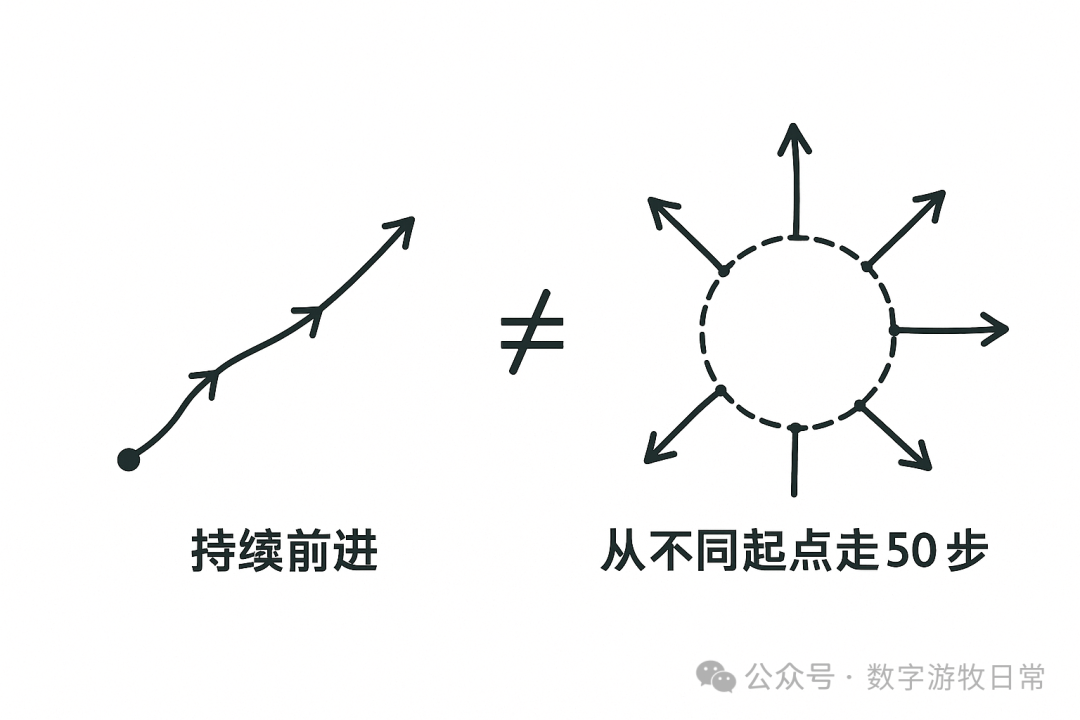
我们可以很明显看到其中的差别,也可以很明显看出,模型在修改我们希望变化的部分的同时,也改动了我们不希望变化的部分。
我们当然可以认为这是模型本身的随机性设定造成的,但深层次的原因还是在于当前生成式AI本身:每一次的输出其实都是全新的。
当然,这个问题不是新出现的,所以我们看到了workflow工具,看到了agent,看到了human-in-the-loop。
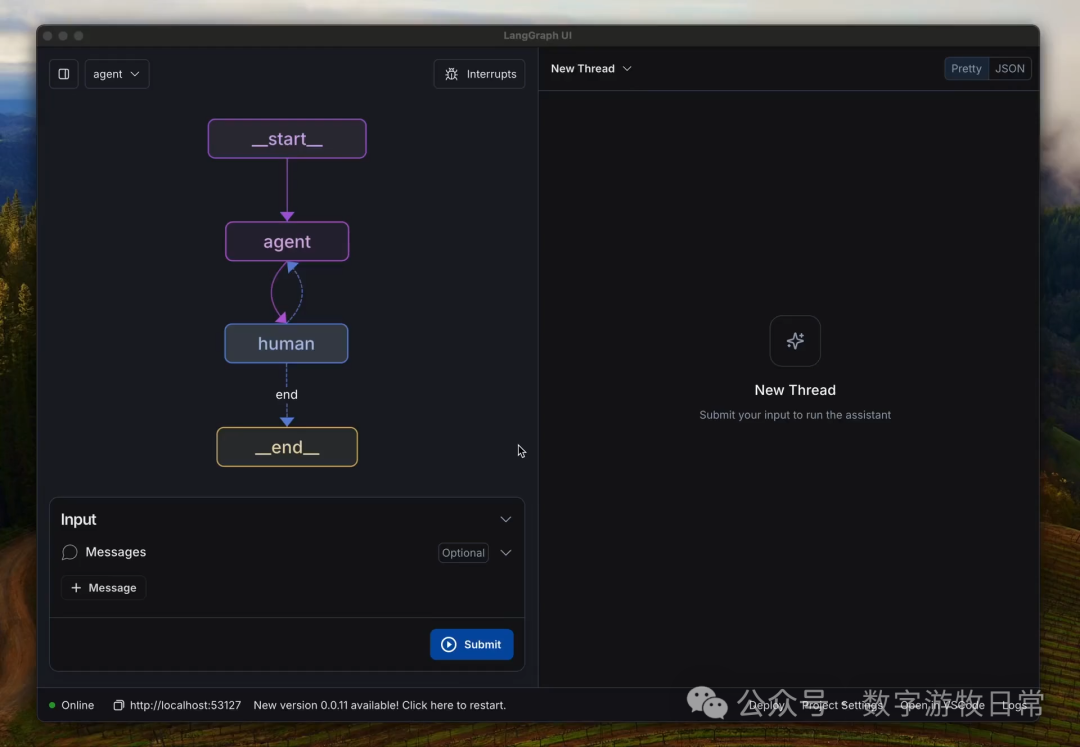
过去半年,我们看到了大量的demo,包括我自己分享的,更包括类似于Manus这样的卖家秀,我们产出了大量的类似于“缝合怪”的结果,却鲜有生产环境里大批量落地的实例。当然,也包括我本职工作范围内的“生产环境”。
在快速demo与实际落地之间,我们遭遇了一系列的矛盾:
我们希望有一些模型可以专注于“代码生成”,可是大概没有任何一段“不结合具体业务场景”的代码是有用的,“专注的模型”如果没有足够业务背景知识理解的基础,也生成不了“好代码”;然而,当我们引入更大知识面更丰富的模型时,代码与业务的结合度显著提升了,问题也出现了,模型开始频繁的受到自身“知识”的影响从而逐渐脱离我们的本意;
在一个工程里,我们希望模型聚焦于某一个具体任务,不必自由发挥,可是,如果不给模型输入足够多的背景信息,任务执行的效果会大打折扣,给足输入后,“自由发挥”却开始让我们哭笑不得;
更多的灾难来自于引入“思考”……
在当前的模型架构下,这几乎是无解的:尽管模型的架构尽可能复现大脑的神经网络,尽管attention和预测下一token很像我们的语言方式……
然而以我们目前的算力,是无法清晰的知道为什么模型在面对选择题时,为什么会选“C”?模型也无法通过我们的输入,准确无误地得到我们的真实意图。如果我们把自己大脑的输出过程也类比为一个生成器的话,我们的这个生成器与模型的生成器,是完全两个世界。我们此刻正互相看不起,互相嘲笑着对方“智商为零”……
另一方面,大脑似乎具备一种独特的“专注能力”,虽然我们经常进行跨学科跨领域的关联和比较,但是当我们执行一项具体工作时,我们会倾向于专注在一个较窄的领域,而“自动隔断”其他领域的输入,这帮助我们将“创造力”和“执行力”在一定时间范围内进行分离。
对模型而言,所有训练的知识都被压缩到一个高维空间中,所有的attention之间其实都是有关联关系的(只不过强弱不同),我们无法或者其实也不可以在这个空间里人为设定一堵又一堵的墙,进行类似于人脑的“自动隔绝”。
以上,大概从更技术化的层面解释了为什么那么多“不如人愿”的结果,或者被我们简单称为“幻觉”的输出。
这是两个世界,我们不可能放弃对自己世界的绝对控制权,但我们其实也无法控制那个事实上我们并不理解的世界。
当然,或许这不会成为太大的困扰,我们需要尽可能的相信黑盒的输出,也需要学会如何自己对结果负责。
所以,如果我们需要Deep Research或者Agent的全面与高效,我们就需要认真的从中学习足够的经验,帮助我们自身如何更好的在提效的同时对产出结果负责。
这个过程本身可能就会付出很多的时间和失败教训,正如我最新一个教训:我逐步认识到human-in-the-loop可能是错误的,模型的输出能力已经早就超越了人可以承受的生理极限,过多的人为干预只是在开时代的倒车。
我们也无法在当下,完全信赖于模型或者应用的产出,不一定是它“错”,只是它还不能被我们完全理解、处理和接受。
模型也不是Copilot,因为没有主次之分。
这就是一种symbiosis,共生关系。在这样的关系下,能让两个世界和谐共处的,就是程序代码:在互联网的世界里,我们所有的意图,其实都可以通过模型生成代码来实现。
我们需要的只是这个共生关系下的生产环境,一个IDE:它既可以让在我们一个工程化的框架下逐步迭代,也可以让两个世界各自发挥最大的优势。