As I write this title, I still rely heavily on Deep Research. However, over the past few months, whenever possible, I have been trying to achieve my goals by relying entirely on IDE tools (I only use Cursor, but I believe Windsurf, Trae, etc., are the same).
In some scenarios with medium difficulty and specific output requirements, I have already achieved this goal. Examples include bulk information searching and knowledge graph generation, preparation of internal training materials, and the construction of general content-based websites related to photography...
In this process, I have completely moved away from MCP. Since more than 90% of available MCPs rely heavily on native APIs, it's simpler to just generate code directly, avoiding the uncertainty added in the MCP stage.
Of course, for a foreseeable future, I still cannot shake off my reliance on Deep Research because both OpenAI and Google have optimized this product very well (though after the May 6th update of Gemini-2.5, Gemini's Deep Research has visibly worsened). However, it still has problems that are difficult to solve under the current architecture:
- The most prominent is the inability to perform incremental updates. Although we can complete several deep research tasks in one dialogue session, and users can explicitly tell the model to "expand and update XX part," the results often fall short of expectations;
- The inability to produce standardized batch outputs. For example, if we want to conduct deep research on ten sub-topics of a subject and hope that each sub-topic uses the same research method and output format. Yes, when we make such requests, the model will "tell us it understands," but the results will still disappoint us;
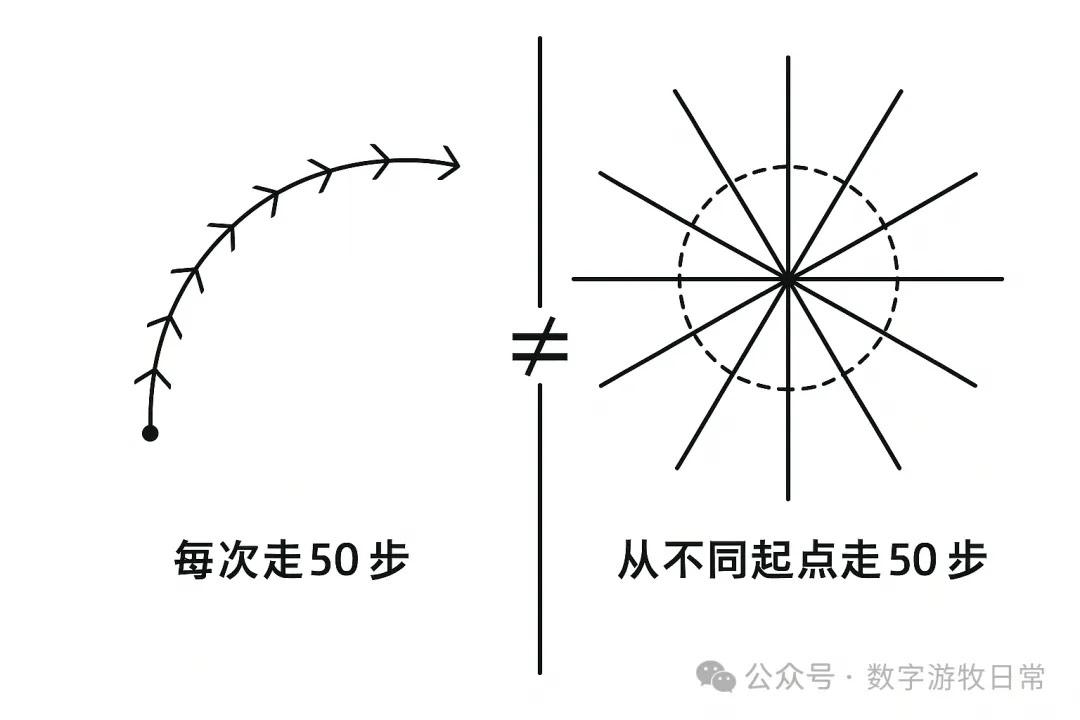
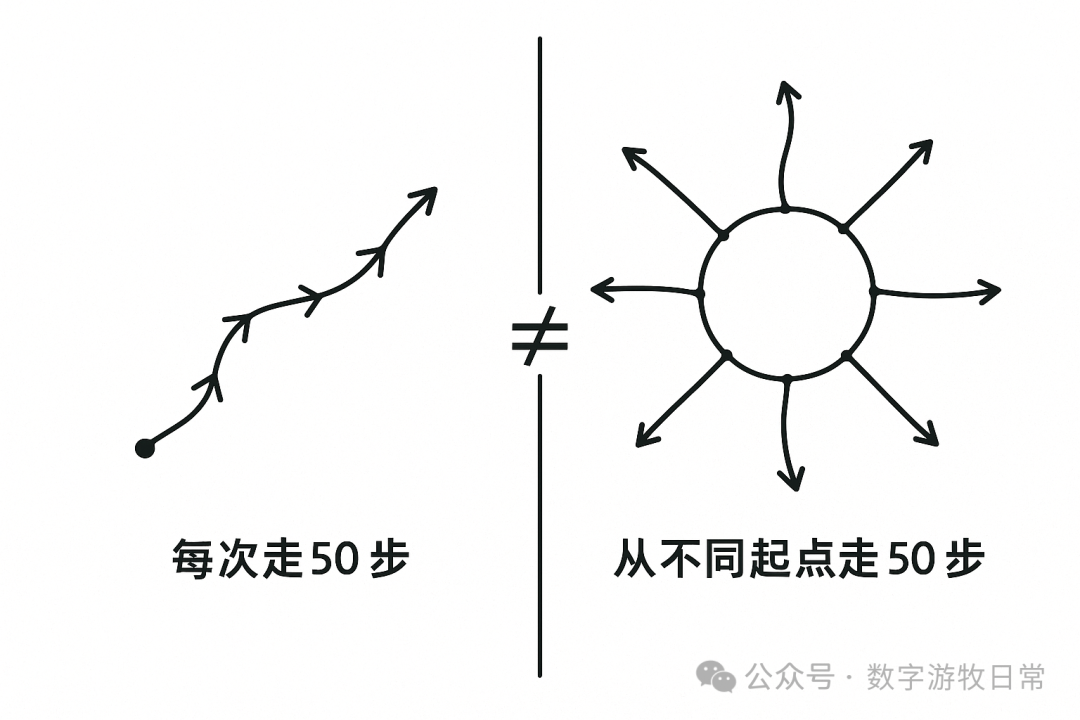
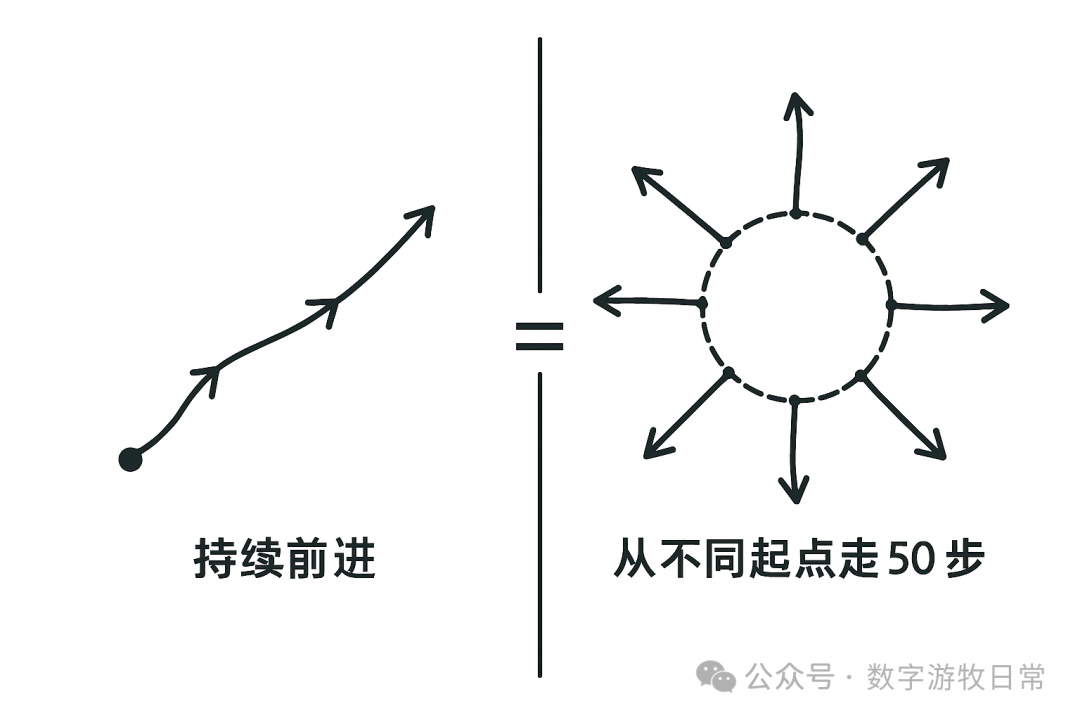
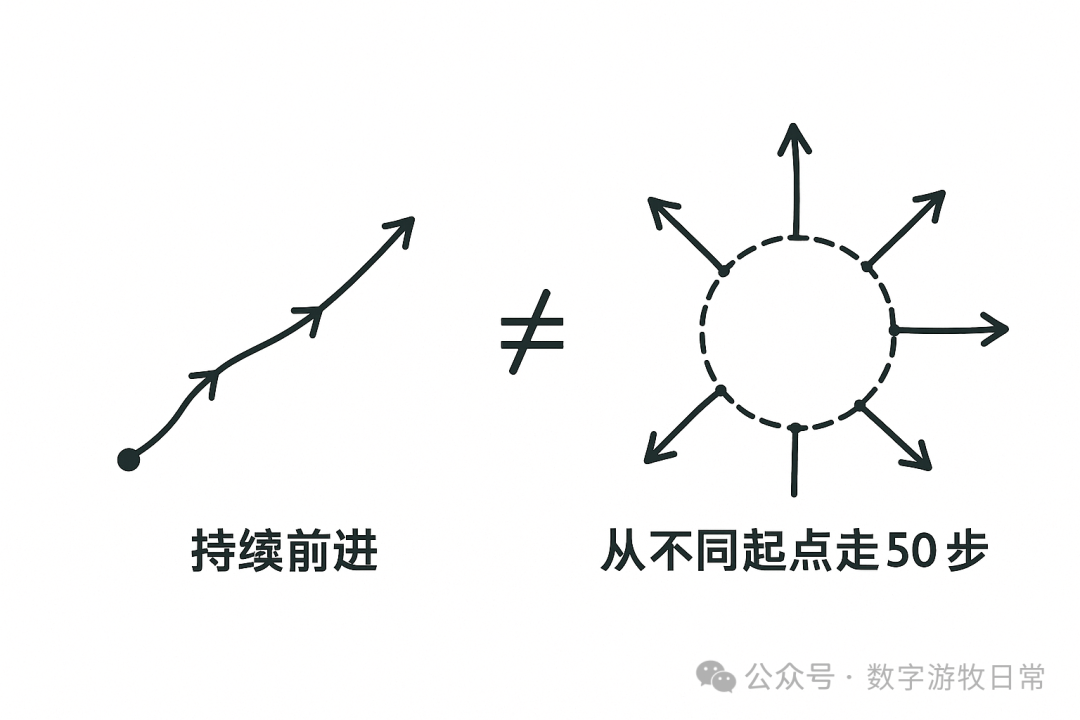
In short, although current Deep Research is an engineered implementation, it cannot produce outputs in a continuous iterative manner under an engineered architecture. We need to walk 1000 steps at a certain rhythm, but this goal cannot be achieved by walking 50 steps from a different starting point each time and repeating it 20 times. It won't give us a curve with a clear path; instead, it is more likely to create a starburst shape radiating outward from different points on a circle.
The illustration above is also a good example: when I gave the preceding description to GPT-4o and asked it to generate an image, it returned the one above after two rounds of dialogue.
Yes, generally speaking, this image presents what I want to express, but there are always discrepancies. However, I can basically no longer correct its output through "dialogue" to achieve a 100% or 95% accurate expression of intent.
This isn't entirely the model's problem; a large part of it is mine. Even if I have a picture in my mind, I may not be able to accurately express it in words in a way the model can understand.
At this point, I broke out of the current "writing process" and tried to hand-draw a conceptual sketch existing in my brain. Since text understanding is biased, multimodal understanding of graphics should help.
Indeed, the three images below show the output process of performing local corrections via text instructions after inputting the graphic.
We can clearly see the differences and also clearly see that while the model modifies the parts we want to change, it also alters parts we don't want changed.
We could attribute this to the model's inherent randomness, but the deeper reason lies in current generative AI itself: every output is essentially brand new.
Of course, this problem isn't new, which is why we've seen workflow tools, agents, and human-in-the-loop.
Over the past six months, we have seen a massive amount of demos, including those I shared, and especially "seller shows" like Manus. We have produced many "Frankenstein-style" results, yet there are few instances of large-scale deployment in production environments. This includes the "production environment" within my own professional scope.
Between rapid demos and actual landing, we encounter a series of contradictions:
We hope for models that focus on "code generation," yet almost no code is useful without being combined with a specific business scenario. A "focused model" cannot generate "good code" without a foundation of sufficient business background knowledge. However, when we introduce larger models with richer knowledge, the integration between code and business improves significantly, but a new problem arises: the model starts being frequently influenced by its own "knowledge," gradually drifting away from our original intent;
In a project, we want the model to focus on a specific task without free-styling. But if we don't provide enough background information, the task execution suffers. Once given enough input, the "free-styling" begins to make us both laugh and cry;
More disasters come from introducing "reasoning"...
Under current model architectures, this is almost unsolvable. Although the model architecture tries to replicate the brain's neural networks, and although attention and predicting the next token are similar to our language patterns...
However, with our current computing power, it's impossible to clearly know why a model chooses "C" in a multiple-choice question. The model also cannot accurately grasp our true intentions through our input. If we liken our brain's output process to a generator, our generator and the model's generator are in completely different worlds. At this moment, we are looking down on each other, mocking each other's "zero IQ"...
On the other hand, the brain seems to possess a unique "focus capability." Although we frequently make interdisciplinary comparisons, when we perform a specific task, we tend to focus on a narrow field and "automatically isolate" inputs from other domains. This helps us separate "creativity" and "execution" within a certain timeframe.
For the model, all trained knowledge is compressed into a high-dimensional space, and all attention links are essentially related (just with varying strengths). We cannot, and perhaps should not, manually build walls in this space to perform "automatic isolation" like the human brain.
The above explains from a more technical level why there are so many "unsatisfactory" results, or outputs we simply call "hallucinations."
These are two different worlds; we cannot give up absolute control over our own world, yet we cannot truly control a world we do not actually understand.
Of course, perhaps this won't be too much of a bother. We need to believe in the black box's output as much as possible, while also learning how to take responsibility for the results ourselves.
Therefore, if we need the comprehensiveness and efficiency of Deep Research or Agents, we need to seriously learn enough experience from them to help ourselves better take responsibility for outputs while improving efficiency.
This process itself may cost a lot of time and involve lessons from failure. My latest lesson is that I've gradually realized "human-in-the-loop" might be a mistake. The model's output capability has already far exceeded the physiological limits humans can handle; too much human intervention is just turning back the clock on progress.
We also cannot fully trust the output of models or applications at this stage. It's not necessarily that it's "wrong," but rather it cannot yet be fully understood, processed, and accepted by us.
The model is not a Copilot either, because there is no primary or secondary distinction.
This is a symbiosis. In such a relationship, what allows the two worlds to coexist harmoniously is computer code: in the world of the internet, all our intentions can be realized through code generated by the model.
What we need is a production environment under this symbiosis, an IDE: it can allow us to iterate gradually within an engineered framework, while letting both worlds exert their greatest strengths.