
OpenAI's 12-day-long launch event finally reached its climax on the final day with the announcement of the "o3 futures." Since, aside from a few viral benchmarks, the amount of additional information was actually quite limited, I hadn't quite figured out how to evaluate this model and chose not to comment immediately.
However, over the past 24 hours, friends have been constantly asking me for my take. I gave them my "second impression": 1. The model's results look great; 2. It is definitely not AGI; 3. Its audience is very narrow.
After a day of sorting through my thoughts, I'm ready to write down my "third impression." It isn't vastly different from the second, but the distinction is that the "second impression" was primarily formed using System 1 (intuition, so-called fast thinking) as defined in Thinking, Fast and Slow. The following "third impression" relies more on System 2 (logic, complex calculation, so-called slow thinking).
Note: I strongly buy into the ideas in Thinking, Fast and Slow, but I have some internal resistance to over-linking this theory with the o1 model. However, since many people are used to discussing it this way, I will use this framework to state my views.
Let's start with OpenAI's somewhat confusing naming system for its models: Why is it called o3 instead of the "GPT-4.5" that was talked about with such certainty last week?
To answer this, we first need to explain GPT: Generative Pre-trained Transformer (according to ChatGPT's own answer).

So, the GPT system refers to pre-trained models. Of course, there's a small question here: If pre-training stops using the Transformer architecture in the future, will it still be called GPT? In my understanding, yes, because I have always viewed GPT as "Generative Pre-Training," a term originating from the title of the first paper in OpenAI's GPT series. Although it used the Transformer architecture, it didn't strictly bind pre-training to the Transformer itself.

While writing the first draft of this section, I happened to discuss it with my daughter. We debated for nearly half an hour because she understood the "T" in GPT to mean Transformer. Finally, we reached a consensus based on ChatGPT's answer: "T" stands for Transformer. Well, it looks like she was right.
Of course, whether "T" stands for Training or Transformer isn't crucial here. Under either explanation, GPT refers to models focused on pre-training.
So, what is the o1 model OpenAI released in September? It's generally believed that "o" stands for "Orion," a code name. This doesn't have much practical significance. Simply put, the "o" series models represent "thinking" models built on top of the GPT series models. They are reinforcement learning models, designed to complete specific tasks after the pre-training phase.
The GPT model is like an encyclopedia, storing compressed knowledge (refer to my previous article: LLM is a Compressor, written before the OpenAI live demo event). The goal of the "o" series models is to achieve good results in "open-book exams" given the existence of GPT. Therefore, we see OpenAI showcasing the "high scores" o3 achieved in AIME 2024.
At least for now, OpenAI's naming convention for GPT and the "o" series is relatively clear: pre-training versus task execution.
This leaves one question: Where is GPT-5?
In my view, by the time we reached GPT-4o, the "historical mission" of "knowledge compression" as a pre-training goal had already been completed for text and general images. Of course, there will be "GPT-5, 6, 7, 8," but for each generation to be meaningful, it will require more modalities and significantly larger datasets (possibly ten times more for each generation). Currently, these conditions are clearly not met (refer to my previous piece on 2025: Time to write the 2025 AI Outlook: Two keywords, several predictions, and one potential risk).
So, the name is not actually that important.
However, it is very necessary to distinguish between these two model systems:
The "Large Models" most people discuss are primarily at the pre-training or GPT level. The simple meaning of the Scaling Law, which the market cares about most, is that if pre-training can still pursue larger scales, then investment in computing power can continue.
Pre-training has always been just one of the foundations for reaching so-called AGI (Artificial General Intelligence). The model functions we discuss now, such as search, code generation, and "thinking models," are all vertical domain task models that utilize the "compressed knowledge" from pre-training to complete specific tasks.
Take chess as an example: one side memorizes and summarizes a massive number of games, while the other side focuses on how to "win the match." Of course, the relationship between DeepMind's AlphaGo and AlphaZero isn't exactly like this, which I will discuss in detail later.
At one level, both the GPT series and the "o" series have "memory," since they have compressed so much knowledge and so-called "thinking methods." But from the perspective of human understanding, these models have no "memory": they do not update or change themselves through their interactions with us.
The discussion on the naming system is basically complete. The above roughly demonstrates a System 2 "slow thinking" process (though not perfectly mapped):
Searching, whether through its own "knowledge base" (or memory) or external information.
Comparison, such as the process of verifying the meaning of "GPT."
Induction and summary to reach a conclusion—though I skipped many steps.
Interestingly, I don't believe the above process represents so-called "human intelligence": thinking conducted according to a "standard procedure" likely isn't seen as a manifestation of "IQ" in most people's eyes.
This leads to the second part of this piece, or my core viewpoint: o3 is definitely not AGI, and the "o" series models cannot even lead us to what we consider AGI.
The concept of fast and slow thinking appears in Daniel Kahneman's Thinking, Fast and Slow mentioned at the start (System 1 and System 2 were not Kahneman's originals, just frequently used by him). Since the release of o1 in September, various self-media outlets have been "trumpeting" slow thinking. With the release of o3, there is a unanimous cry of "AGI is here."
Yes, the o1 model is strong, and o3 has significantly boosted "complex thinking capability." I once mentioned in a review of the o1 model: "The road to AGI is becoming clearer."
Yes, that thinking o1 model is here:
In one sentence, for the first time, we have the "commander," "planner," and "thinker" of large models; in another sentence, the road to AGI is becoming clearer.
From: Daoming AI Lab
"Strawberry" is here, the long-awaited "Commander"
Now, with o3, the road to AGI is certainly clearer, but in my view, this is because o3 likely points to a wrong path that will not reach AGI: slow thinking cannot "lead to human intelligence."
Kahneman emphasized more than once in his book that his theory wasn't meant to highlight the "slow thinking" of System 2, but rather how to use System 2 to overcome the shortcomings of the "fast thinking" System 1 to enhance decision-making capacity. The fundamental reason is that human System 1 cannot be turned off; it influences our decisions anytime and anywhere.
My understanding is: human intellect or intelligence level is perhaps more reflected in "System 1."
To elaborate, the so-called logic or "thinking" ability of "System 2" can mostly be acquired through post-hoc learning and training. Yes, o3's operational mode is indeed very similar to "System 2," and the results are "mind-blowing."
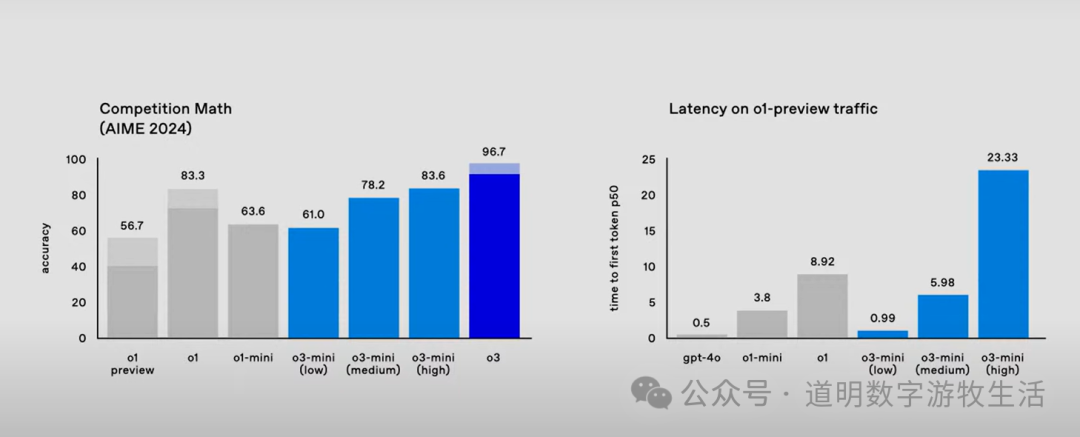
But if we look closely again at the AIME performance mentioned above, the problem arises: o3 improved by about 13 points over o1-mini (96.7 vs 83.3), but the latency increased nearly twofold (23.33 seconds vs 8.92 seconds). Assuming the o3 model scale is similar to o1 (it is actually likely much larger, as OpenAI claims the test-time training scaling law still holds), it means o3 improved the score from an "A" to an "A++" at nearly three times the cost.
Perhaps, to many people including myself, this cost is worth paying—after all, we have obtained an "AI model" that performs at the top level in mathematics competitions.
However, if we discuss this from a human perspective: it's similar to the same math competition where a ten-year-old child scores 83.6 while an eighteen-year-old high school graduate scores 96.7. Which one would you think is smarter? Who has a higher "IQ"?
This is, of course, a matter of opinion, but I believe that a significant portion of people, myself included, would consider the ten-year-old to have a higher "IQ."
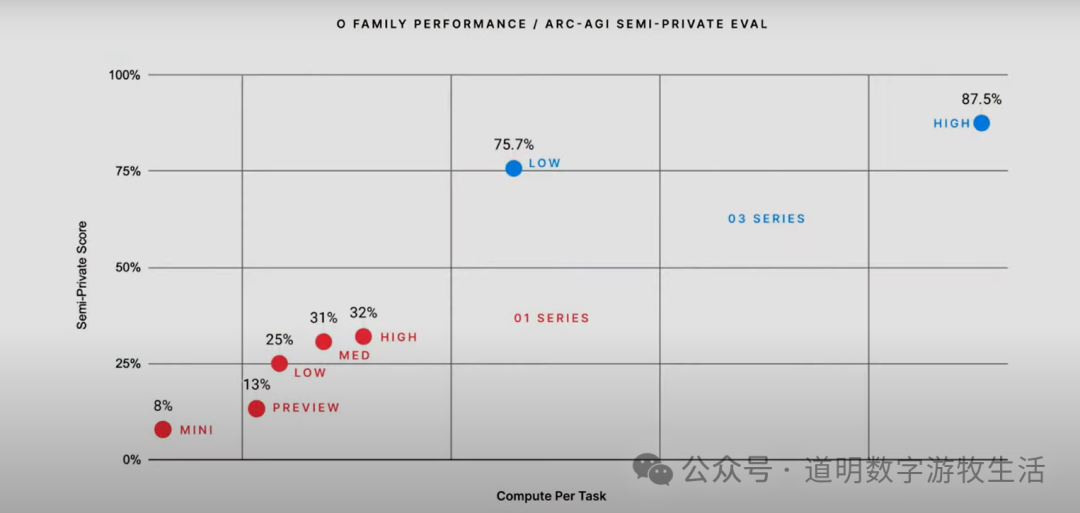
Returning to model performance, a fairer statement might be: if cost is not a factor (OpenAI itself claims the cost to solve a low-compute task with 75.7% accuracy is $20, while a high-compute task requires $1,000–$6,000, though accuracy improves to 87.5%), o3 might outperform most humans on specific tasks. However, this excellent performance on specific tasks is not in the same dimension as what humans understand as "intelligence."
In short: the o3 model can be a very good problem-solving Agent, but it is not the AGI we want.
So, where is the problem?
First is the issue of definition. We don't seem to have a particularly unified standard for "human intelligence." Regarding the most common so-called IQ tests, it's generally believed that the younger the subject, the more representative the test results. It seems we acknowledge that "learning and training" affect the objectivity of an "IQ test." Does this mean more of us are willing to admit that "acquired" "problem-solving ability" is not a sign of "high IQ"?
Of course, in a general sense, we have some criteria for judging someone as "high IQ": fast reactions, strong memory, the ability to find solutions to problems never encountered before, and so on.
This leads to the second aspect: the problem of evaluation standards for model capabilities. The ARC-AGI evaluation system we see only reflects a single dimension: problem-solving ability. While this can reflect intelligence levels to some extent, its correlation with what we understand as "IQ" is likely low.
Actually, this is not a problem at all. As long as the cost is right (and it will continue to drop as hardware upgrades), having a model that is better at solving problems than most people but doesn't exhibit the same "IQ" as a human—isn't that what many people hope for?
Third, technical issues deserve more in-depth discussion.
Let's return to the framework of System 1 and System 2.
On one hand, some of the human criteria for "high IQ" mentioned above seem more applicable to the scope of System 1: making quick reactions and decisions based on intuition and experience. We likely won't heartfully praise a normal person who takes over three minutes to calculate "17 x 48 = 816" as "smart," but we would likely marvel at someone who blurts out the answer in ten or even five seconds.
To some extent, the capacity of System 1 has a higher correlation with "IQ."
Secondly, human "associative" ability may be the source of much creativity. We've all had the experience where moving from a few words to others, or from one concept to another, is almost subconscious and instantaneous. Kahneman's book has no shortage of such examples. While System 2 may be involved in this process, System 1 is clearly more important in such decisions.
Furthermore, even within System 1 and System 2, the capacity or boundaries of these systems differ for different people. For instance, answering "2+2=4" is listed by Kahneman as being within the scope of System 1 intuitive decision-making. However, this boundary varies; some people can react instantly by "intuition" to two-digit or even three- or four-digit addition and subtraction, while others may need to focus and call upon System 2 "slow thinking" to answer.
While "talent" plays a role in these differences, more often they are acquired through massive "training," like a pianist's muscle memory or a soccer goalkeeper's excellent reaction speed.
Perhaps a large amount of training within the System 2 domain can at least enhance the capacity of System 1.
If we apply this back to models, it can be summarized as follows: if AGI truly exists, it is more likely to be dominated by System 1 with System 2 as an assistant, and training within the System 2 scope is more about enhancing System 1's capabilities.
This leads to my conclusion: I do not believe the o3 model, which emphasizes "slow thinking," is AGI, nor do I agree that the "o" series models following this path can lead to AGI. Under the current model system, I see no way for "slow thinking" "o" series models to enhance the System 1 capabilities of any models OpenAI has released. Perhaps there will be in the future, but not now.
So, why can't the "o" series models following the "slow thinking" path enhance System 1 capabilities?
Let's further discuss using DeepMind's AlphaGo and AlphaZero models as examples.
Granted, Go is a relatively closed task domain, but the two generations of AlphaGo and AlphaZero roughly present a R&D path and methodology for super AI. Although not perfectly analogous, AlphaGo can basically be understood as a pre-trained model that "learned" a massive number of games, while AlphaZero is a deep reinforcement learning model that learned through constant self-play.
During actual play, AlphaGo searched through possible options at every step, calculated potential win rates, and then made the choice with the highest probability. The number of future steps the model could "see" basically represented its capability, but the more steps it could "see," the "slower" it thought. Naturally, this process was almost entirely System 2, and many people questioned whether probability calculations that beat top human players truly meant the model was smarter than a human.
By the AlphaZero era, such questions were rarely heard. Although System 2 certainly still played a huge role in the model's operation, through the reinforcement learning process of "learning play through play," AlphaZero gradually turned "Go capability" into an intuition or instinct. Today, AlphaZero has long since become a friend and sparring partner for players, and even the best players can improve their skills by playing against it. This is naturally credited to the introduction of System 1 (this phrasing is not perfectly accurate, but that is the general idea).
This AlphaZero model provides a very ideal path to AGI. In fact, major frontier model developers—whether OpenAI, Google, Anthropic, or others—likely have this as their primary roadmap. However, there are two very important points: 1. Do we have enough labeled data to enter the reinforcement learning (supervised learning) phase? 2. The problems AGI faces are primarily open-ended, but in open domains, many problems have no standard answer and are highly personalized. A model that cannot generate "memory" and adapt itself based on interaction with users or the world, and cannot constantly improve its System 1 capability through interaction, will naturally struggle to fit the definition of "AGI."
Sufficient data, "memory capability," and constant training to produce System 1 "intuition-like" ability.
Yes, this is roughly why I have always been more optimistic about Google DeepMind: 1. Google has plenty of user data, which is labeled. While this data cannot be used directly for training, generating high-quality labeled data based on it is a unique advantage for Google. 2. DeepMind has always been a pioneer in reinforcement learning with sufficient reserves, and they have been trying to reach AGI through memory-based reinforcement learning (Refer to: World Models: Scientists play games, engineers do art). 3. Google's ecosystem gives models more opportunities to interact with users and specific tasks, and even offers the chance to achieve "personalized" models leading to AGI.
The above is not necessarily to recommend Google, but if we list these advantages of Google DeepMind and compare them apple-to-apple with OpenAI, we might reach a fairer conclusion: to some extent, the "o" series slow-thinking models are necessary, but betting on "slow thinking" might also be a forced, passive choice for OpenAI.
After all, OpenAI was previously a pure model company with no exclusive data or scenarios, even if ChatGPT is already a top-eight daily active app. But how many users provide feedback to the model to offer "priceless" labeled data? And how many strong scenarios provide opportunities for the model to interact with users and offer "personalized models"?
OpenAI is not unaware of this problem, which is why functions are constantly added to ChatGPT. But how can two years of data accumulation in very niche fields compare with companies like Google, Meta, or Apple?
As I write this, I have basically completed the System 2 slow-thinking evaluation of the "o3" model. The arguments might not be correct, the logic might not be complete, and the conclusion might naturally be wrong. But isn't the issue of AI or AGI an opportunity for us humans to constantly study ourselves, reflect on ourselves, and discover ourselves?
Finally, some friends might be concerned about whether "o3" will drive demand for computing power:
The massive inference cost of "o3" in its highest accuracy mode (thousands of dollars per task) does not mean that training "o3" requires higher computing power expenditure.
In the current landscape, the compute expenditure for model training over the next three to five years is basically a relatively fixed value (determined by factors like the progress of cluster compute, chip factory capacity, data center energy supply, and data volume). As for inference, the demand is certainly huge, but it is also more compatible with different types of compute.
The most suitable application areas for "o3" are at the absolute frontier with very small audiences, such as scientific research and biomedicine. While a single project could be an "astronomical" cost, the total sum is still a small number compared to the current capital expenditures of tech giants.
Conclusion: Ignoring the cost of use, "o3" is undoubtedly a major step forward. In fields like research and biomedicine, "o3," with its emphasis on System 2 "slow thinking," has excellent use cases. However, "slow thinking" is unlikely to lead to "AGI." As model development reaches its current stage, OpenAI, lacking scenarios and data, is entering a "bottleneck period" that is difficult to break through.