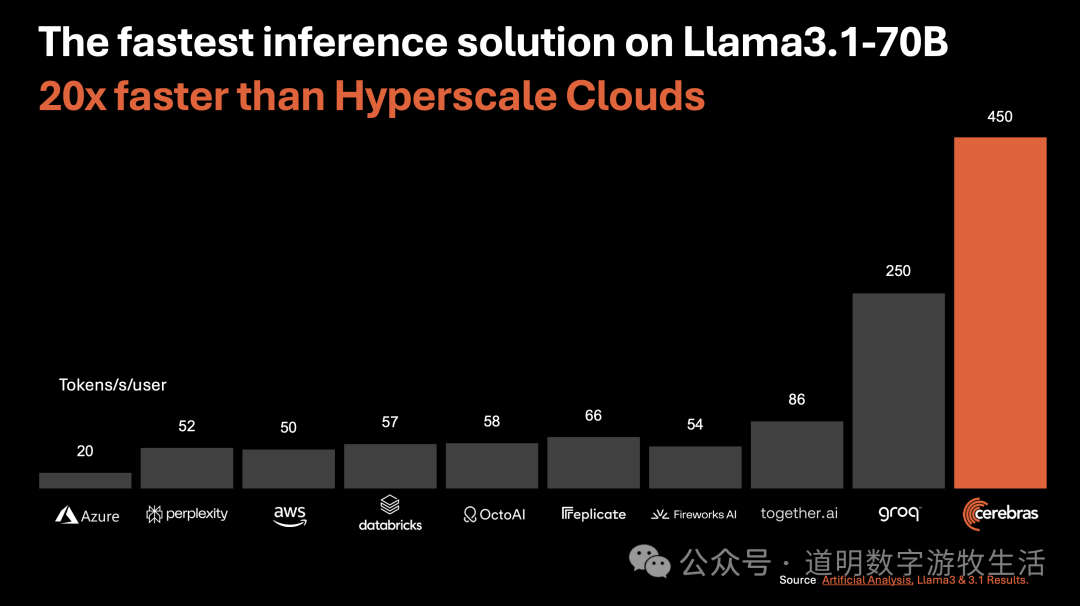
八月底,Cerebras公布了又一个创纪录的模型推理速度纪录:LlaMa-3.1-70B达到450tokens/s,远超各个云平台的速度,也超过了之前的第一Groq。
来源:cerebras.ai
这几天,Cerebras官网再次公布了更惊人的纪录:2100tokens/s,一个多月时间又提高了约4倍。

来源:cerebras.ai
当然,最近一个多月的这一次4倍多提升,更大可能性是并联带来的,而并没有对基础的软硬件做太多改动。
这种推理性能的大幅提升当然来自于软硬件的共同优化。不过,抛开复杂的技术细节(芯片方面的知识很多我而言也是盲区),核心是两点:1、使用带宽更高的SRAM(大概是Blackwell使用的HBM的8TB/S的十倍);2、“不惜成本”地将单wafer的SRAM容量做到44GB。
前一点,是Groq首创,之前还引起过巨大的轰动。因为虽然SRAM相比DRAM可以做到高得多的带宽,但是带来的是更高的成本上升。粗略计算,同样的内存容量,十倍带宽提升,成本提高甚至可能接近一百倍,综合而言,性价比更低。
同时,Groq令人诟病的另一点,就是单Chip的SRAM内存容量有限,难以支持较大规模模型。当然,本质上这也是成本考量。
如今看来,Cerebras丧心病狂的“大力出奇迹”,似乎又增加了这条路未来的胜率:单wafer容量做到44GB,用四个wafer并联再去推一个完全精度(16比特)的模型。
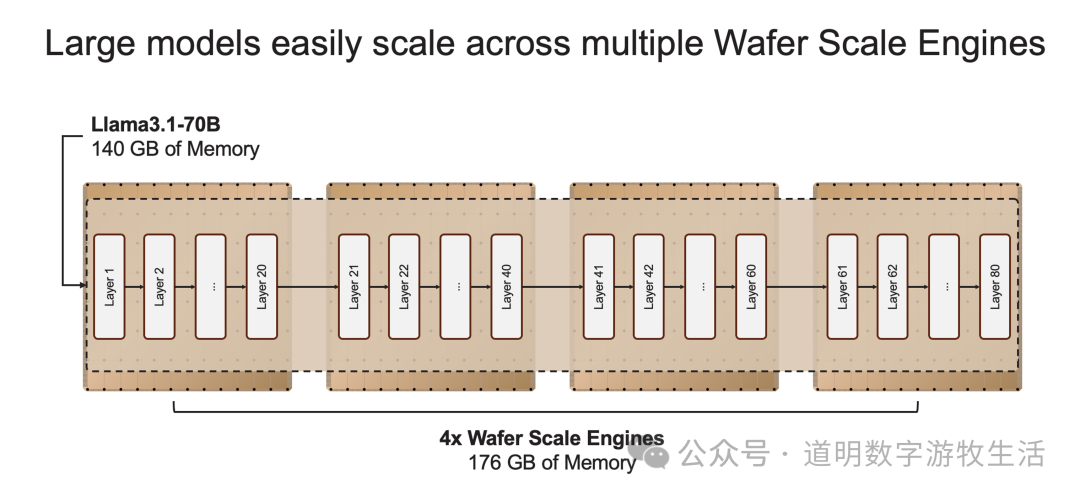
来源:cerebras.ai
所以我们可以见证巨大的速度差距。
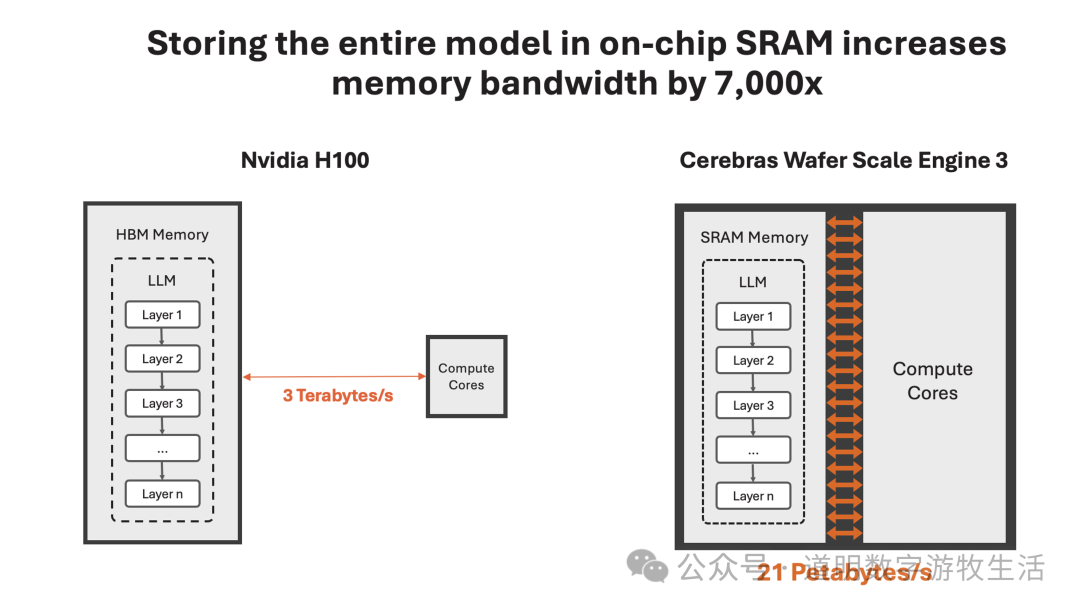

来源:cerebras.ai
随着并联数的增加,当然可以推更大的模型,比如LlaMA的405B。
显然,虽然利用on-chip的SRAM这条赛道还很窄,但确实从现在起出现了两家直接竞争的对手,Groq和Cerebras。
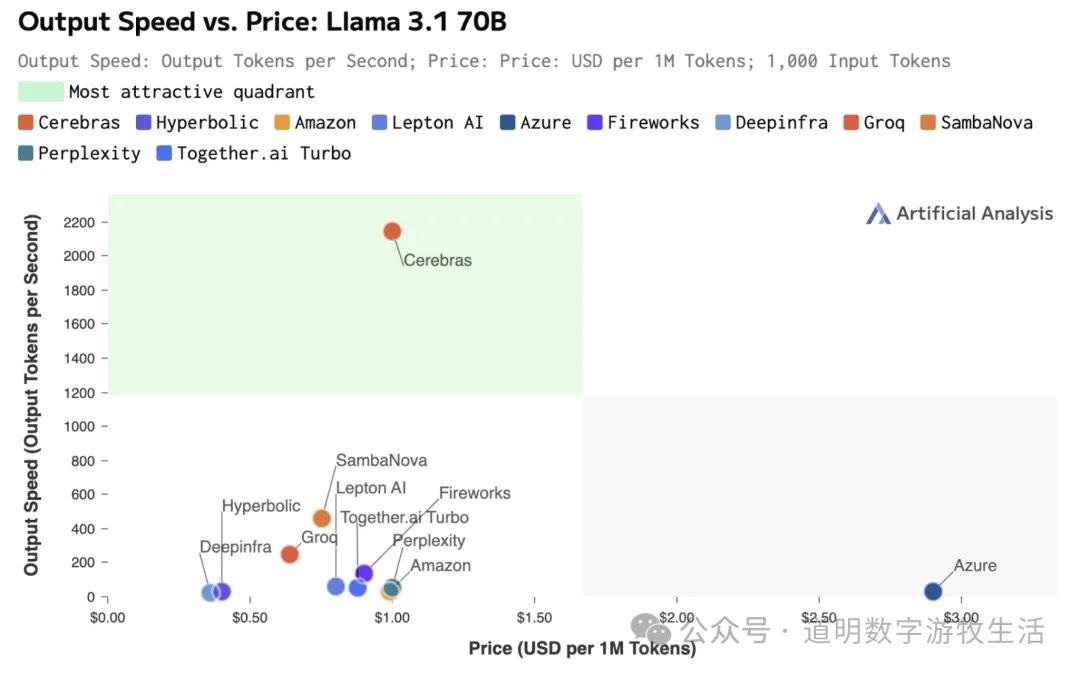
上图是Cerebras在Groq贴出的性能评测结果上加入了自己的最新纪录。有价值的信息量是两条:1、推理成本已经实质性地降到1美金/百万tokens以下了;2、Groq的评测页面做得很好,很完整。
推理性能评测结果: https://artificialanalysis.ai/providers/groq
虽然我并不会成为Groq或者Cerebras的用户,我的关注点更多在本地推理方案而不是云端推理上。但是在推理需求越来越成为市场最关注点的当下和未来,类似于Cerebras和Groq的解决方案的不断问世,一些可能的影响依然非常值得探讨:
- Cerebras和Groq推理方案在当下最大的问题是SRAM成本过高、性价比过低而无法本地化的推广。但是如果综合考虑推理性能、能源消耗,作为云端推理的解决方案依然竞争力十足;
- 即使英伟达Blackwell架构的NVL-72大规模推广,主流推理性能可以提高数十倍(GB200推理性能的三十倍提升如何得来?),综合下来,可能成本还是会高于Cerebras的方案;
- 其实,在摩尔定律逐渐失效的当下,单芯片性能代际提升幅度已经非常有限了,英伟达方案的竞争力在:集群互联;CUDA提供的部署便捷性和稳定性;庞大的用户群;
- Cerebras的方案一定存在很多软硬件的bug没有披露,短期内对英伟达不会造成任何威胁。但是,如果几大主流云商逐渐将SRAM的方案作为可选项之一,情况可能就会发生巨大的变化;
- 过去一年多,即使不考虑Cerebras和Groq这种SRAM的方案,利用H100 GPU推理的性能也至少提升了数十倍,这是软件层面的贡献;
综上,两句话:1、在GPU技术架构下,软件层面的性能优化最重要;2、几大云巨头能够利用各种硬件创新加上软件优化,逐渐过渡到基于“自研硬件”的推理时代。
这个趋势不会在一两年里完成,却是未来五到十年AI应用落地里最重要的趋势之一。