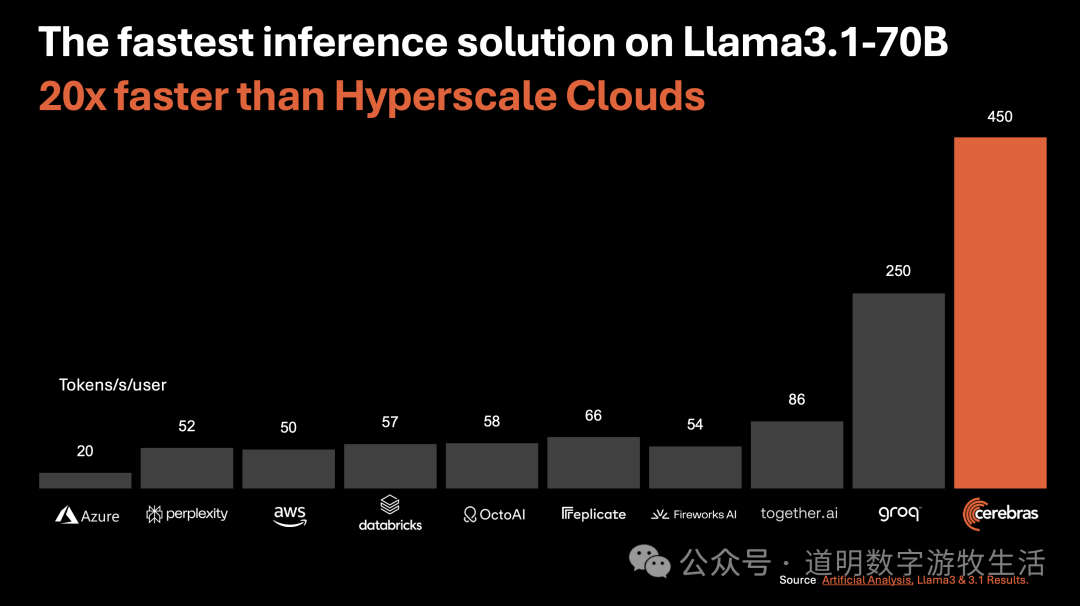
At the end of August, Cerebras announced yet another record-breaking model inference speed: Llama-3.1-70B reached 450 tokens/s, far exceeding the speeds of various cloud platforms and surpassing the former leader, Groq.
Source: cerebras.ai
Recently, the Cerebras official website announced an even more staggering record: 2100 tokens/s, a nearly fourfold increase in just over a month.

Source: cerebras.ai
Of course, this recent 4x jump in performance is most likely due to parallelism, rather than significant changes to the underlying hardware or software.
Such massive improvements in inference performance naturally come from the joint optimization of hardware and software. However, setting aside complex technical details (many chip-level details are outside my expertise), the core comes down to two points: 1. Using higher bandwidth SRAM (roughly ten times the 8TB/s HBM bandwidth used by Blackwell); 2. Achieving a single-wafer SRAM capacity of 44GB regardless of cost.
The first point was pioneered by Groq, which caused a huge sensation earlier. While SRAM can achieve much higher bandwidth than DRAM, it comes with significantly higher costs. Roughly speaking, for the same memory capacity, a ten-fold bandwidth increase can lead to a nearly hundred-fold increase in cost, making it less cost-effective overall.
Additionally, another criticism of Groq is the limited SRAM capacity per chip, which makes it difficult to support larger models. This, fundamentally, is also a cost consideration.
Now, Cerebras's "brute force" approach seems to have increased the odds for this path in the future: achieving 44GB per wafer and using four wafers in parallel to run a full-precision (16-bit) model.
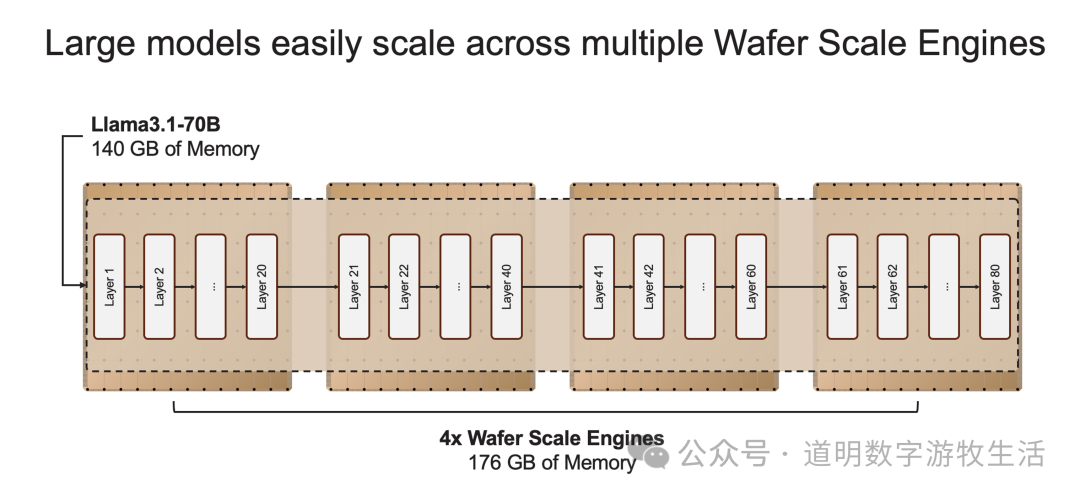
Source: cerebras.ai
Thus, we can witness a massive speed gap.
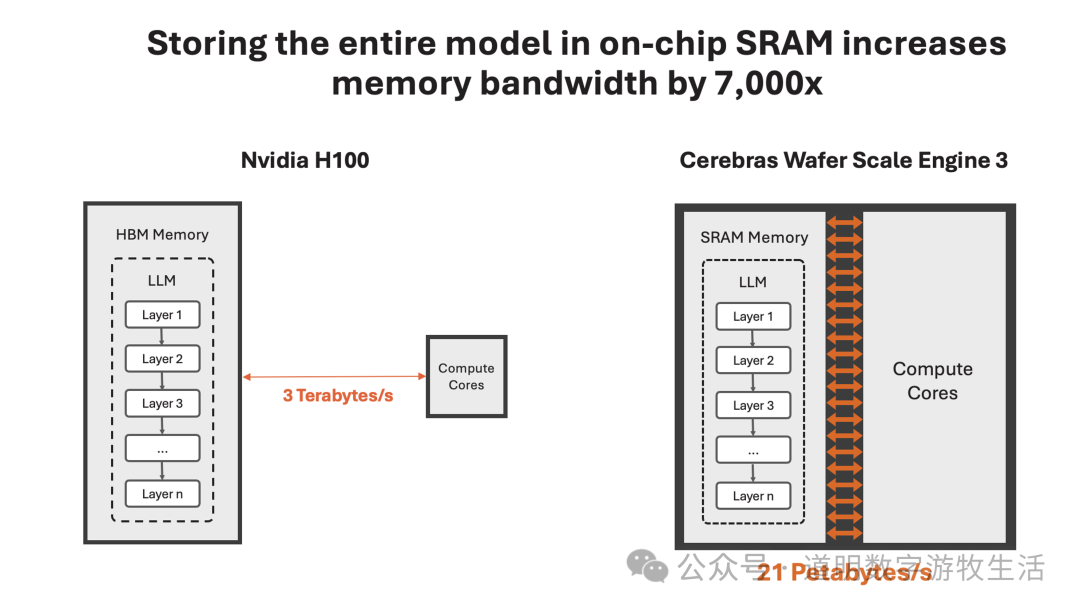

Source: cerebras.ai
With increased parallelism, they can naturally run larger models, such as Llama 405B.
Clearly, although the on-chip SRAM track remains niche, two direct competitors have emerged: Groq and Cerebras.
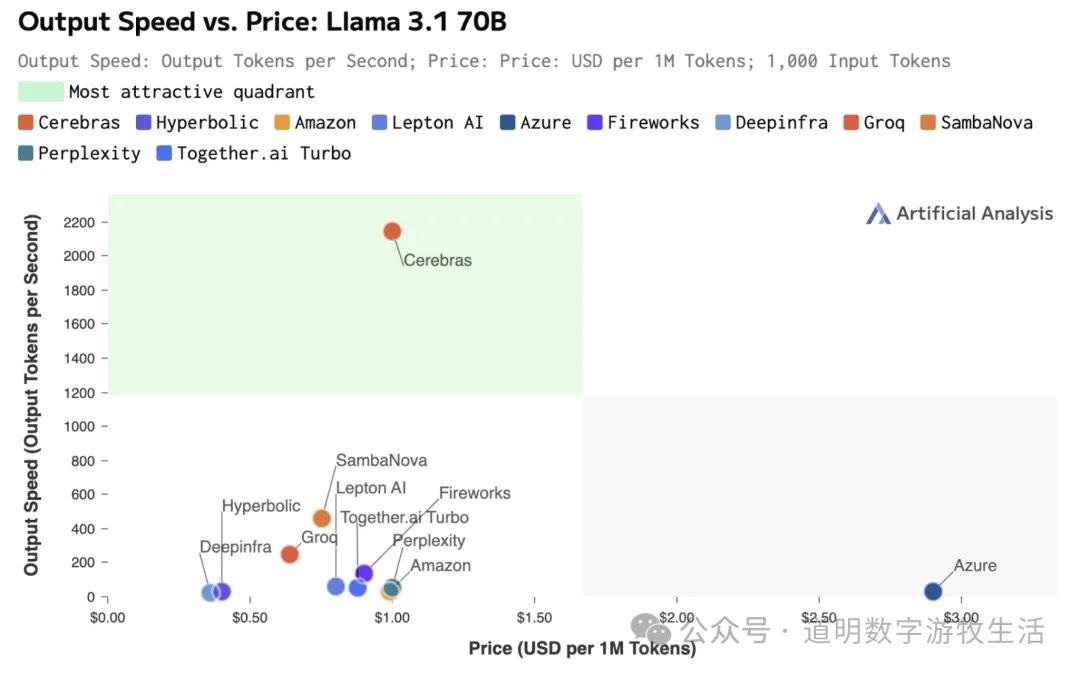
The image above shows Cerebras adding its latest record to the performance benchmarks posted by Groq. There are two key takeaways: 1. Inference costs have substantially dropped below $1 per million tokens; 2. Groq's benchmarking page is very well-executed and comprehensive.
Inference Performance Benchmarks: https://artificialanalysis.ai/providers/groq
While I may not personally become a user of Groq or Cerebras—as my focus is more on local inference rather than cloud-based solutions—the emergence of solutions like these is worth discussing as inference demand becomes the market's primary focus:
- The biggest issue with Cerebras and Groq's current solutions is the high cost of SRAM, which makes them hard to promote for local use. However, when considering inference performance and energy consumption, they remain highly competitive as cloud inference solutions.
- Even if NVIDIA's Blackwell-based NVL-72 scales broadly and boosts mainstream inference performance by dozens of times (how the 30x GB200 performance gain is calculated remains to be seen), the combined costs may still be higher than Cerebras's approach.
- As Moore's Law slows down, generational performance leaps in single chips have become limited. NVIDIA's competitiveness lies in cluster interconnects, the ease and stability of deployment provided by CUDA, and its massive user base.
- Cerebras’s solution undoubtedly has many undisclosed hardware and software bugs and won't threaten NVIDIA in the short term. However, if major cloud providers start offering SRAM-based solutions as an option, the situation could change drastically.
- Over the past year, even without considering SRAM solutions like Cerebras or Groq, inference performance on H100 GPUs has improved dozens of times over—this is a contribution from the software layer.
In summary: 1. Under current GPU architectures, software-level performance optimization is paramount; 2. Cloud giants can leverage hardware innovation and software optimization to transition toward an era of inference based on "self-developed hardware."
This trend won't be completed in a year or two, but it is one of the most significant trends in AI application deployment over the next five to ten years.