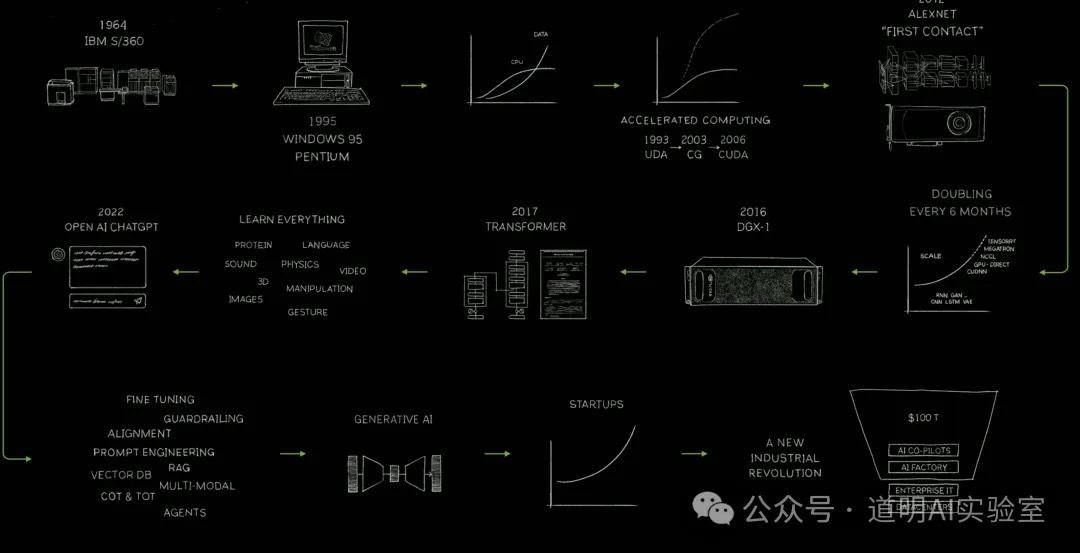
全市场瞩目的英伟达GTC 2024随着黄仁勋穿着标志性黑色皮衣登场演讲而宣告正式开始了。
1. 数字孪生:计算正在改变百万亿美金的行业
百万亿美金的行业正在因为计算而快速变革,这是老黄第一张PPT要表达的。是的,当我以为他在回顾英伟达的成功史时,其实,他只是在点出一个正在快速发生的事实:计算正在改变着百万亿美金的行业。
这个事实并不是去年才发生的,但是这个事实,还在不断加速。
所以,演讲的第一部分内容,虽然篇幅远小于自家Blackwell GPU的新品介绍,但是却基础又重要:数字孪生,Digital Twin。
之前我反复讲过,最重要的变化是物理世界与数字世界的联结,而这个联结就是数字孪生,这个联结背后则是靠越来越高速的计算驱动的仿真。
2. 从GPU到GPU系统:Blackwell不仅仅是算力的提升,更是功耗的大幅下降
当然,计算的背后,是英伟达的基础设施,所以,Blackwell架构登场了,最大的改变是,我们可能要重新定义“GPU”了。
首先,我们正常的理解下,GPU应该长下面这个样子。依然是4nm制程。

但是,到了Blackwell时代,上面的芯片不能再叫做GPU,两个连在一起才是(类似于苹果的M2 Max到M2 Ultra)。这个也许叫“B200”=“B100”+“B100”(直到发布会看完,我还在疑惑,也许这个还是该叫B100?不过,不重要)。

事实上,并没有明确的“B100”,“B200”产品名称,只有“Blackwell GPU”。
如果再把两个“Blackwell GPU”连在一起呢?如果再把更多的GPU连在一起呢?
- **GB200:**两个“Blackwell GPU”+一个Grace CPU(GH200是一个GPU+一个Grace CPU)。
- **单台机器:**两个GB200(4个Blackwell GPU)联结在一台机器里,叫一个Tray,或者一个节点。
- **GB200 NVL72:**把18个tray连在一个机柜,背后用NVLink链接,就是36个GB200,72个GPU,所以叫做“GB200 NVL72”。这是最大的“GPU”。
英伟达也正式从GPU走向GPU系统。
那么,性能如何?

一个“Blackwell GPU”,在FP8下,算力是Hopper架构的2.5倍。
如果用来训练类似于GPT-MoE-1.8T(猜测的GPT-4)模型,大概需要8000块Hooper架构GPU(H100),训练90天。

使用GB200 NVL72系统,需要2000个GPU(每个GPU有两个Blackwell,所以实际上是4000个基础计算架构),同样90天,但是,能耗只有使用目前Hooper架构系统的四分之一。

如果放到推理,英伟达这次引入了新的FP8和FP4两种精度。特别是如果使用FP4精度推理,性能提升30倍。
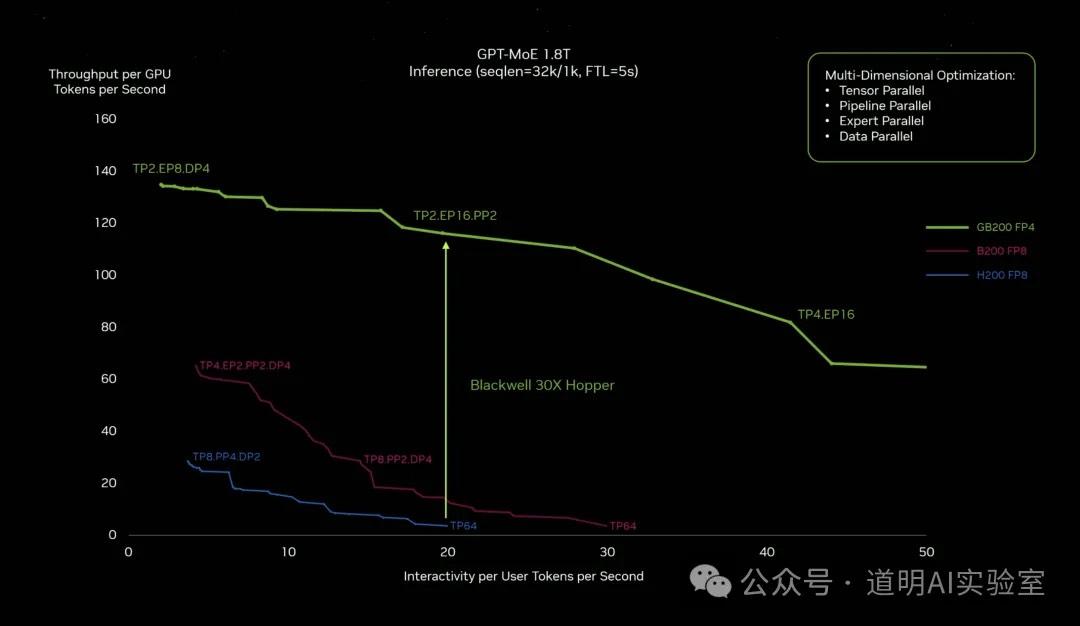
所以,新产品的潜在客户是谁?最大的那些,至少要构建几千甚至上万块GPU集群的那些。
AI又逐渐回到“巨头时代”了,不是吗?
老黄在最后一张PPT做了个总结,新的Blackwell系统:新的GPU,新的NVLink,新的GB200超级芯片,新的X800交换机,新的Blackwell平台。

3. 其他:
英伟达软件开发平台(统称),包括支持CUDA加速计算的一系列名称,不一一罗列了。
自动驾驶,机器人,数字孪生……
面向自动驾驶和机器人的下一代芯片Thor,将于今年年底明年年初发货。
最大的变化其实是:大模型驱动。
其实,正如我在前瞻里提到的,市场经过了一年的“充分学习”后,这些变化,都只是量变,而不是质变了。
总结:
- 虽然Blackwell架构之前传出的信息已经比较充分了:一个GPU包含两个计算单元等产业链也早就明确了。但是“GB200 NVL72”这种连接方式还是略超预期的,只不过这些产品针对的客户群开始变得越来越集中了;如果能够快速出货,对AMD的打击不小;
- FP4表现抢眼。英伟达已经充分认识到了,推理市场才是下一个重要战场;
- 黄仁勋两小时的演讲或者说show,是在很自信的告诉大家一个明确信号:英伟达就是AI的基础设施,没有之一。
- 正如开场白讲的一样:这是一个正在快速改变百万亿美金行业的市场,计算。
- 这其中,最大的机会是:数字孪生。
最后,一个小“彩蛋”:机器人登场。
