Snap推出了Snap-Video,又一个基于spatial(空间)和temporal(时间)的transformer文生视频模型。这是半个月时间里像模像样的第四个了,OpenAI的Sora自不必提,还有DeepMind的Genie,StabilityAI的Stable Diffusion 3,以及这一个Snap-Video。至于Morph Studio的AIGC电影工具,是基于Stable Diffusion 3的,LTX Studio的类似工具,还不太好判断。
Attention is all your need。Transformer没有让人失望,在图形领域,也通过各家巨头的疯狂“内卷”,几乎把卷积神经网络彻底“卷”进bin了。
2023年,ChatGPT开始的是“大模型”时代,2024年,Sora开启的是“世界模型”时代。当然,相比大模型,世界模型的叫法,还是要有美感的多。虽然,世界模型不是指全世界都可以用的模型,而是指“理解”人类世界,并且能够“预测”或者“生成”物理世界的模型。使用“或者”,不是指两者皆可,而是在很多人看来,是泾渭分明的两条路,Meta的首席科学家Yann Lecun就觉得至少不是“生成”。
当然,抛开这种争议,之所以叫世界模型,隐含的意思是模型并非给人类用的,而是给机器用的,是给可能的AGI(通用人工智能)准备的。
在“生成派”的路径下,为了训练AGI,我们先创造一个机器能够“看懂”的物理世界。所以,Sora这类模型可能在很长时间里都难以生成非常自然的人类走路的视频,可是,谁又能确定机器是否建立了“这个人在走路”这样的概念了呢?
在“预测派”的路径下,我们让机器看真实的物理世界,也许是许多不同的人走路的不同视频,然后让机器自己说出“人在走路”这样的概念。这是非常Old-School甚至可以说几乎就是最早“深度学习”想要追求的目标。因为这样的坚持,在Sora发布的同一天,Meta拿出了V-JEPA模型,纯预测,不生成。V-JEPA提出了很好的概念,很多巧思在其中,从研究意义上讲,结果也足够令人欣喜,但是它还很初步,虽然概率很大,但事实上还没证明具备scaling的能力,离产品化还很远。但,这就是科学家拿出的东西。
我一直觉得,Yann Lecun是固执的极少数。可是在我认真比较了OpenAI的sora和Google DeepMind的Genie后,我发现自己可能错了,因为Google DeepMind可能反而跟Yann Lecun更接近,他们很“骄傲”,很“炫技”,以科学家自诩,相形之下,OpenAI的团队却更像极了比996还“卷”的工程师。
Google提出了transformer,OpenAI把它用在了GPT里;
DeepMind主导下与OpenAI合作提出了RHLF(人类反馈增强学习),OpenAI把它用在ChatGPT里;
Google提出了ViT(Vision Transformer),Runway提出了Latent Diffusion Model,Meta的团队结合后提出了DiT(Diffusion Transformer),OpenAI把DiT用在了Sora里;
……
这些桥段,讨论的人已经很多了,我重提旧事,不是因为我主观上更偏好Google,而是,其实,三个桥段描述中,我认为最难的都是“用在”这两字。
AI不是写论文,而是系统性的无数次实验。也正是如此,今天的暂时领先者,是OpenAI,2:0的那种。
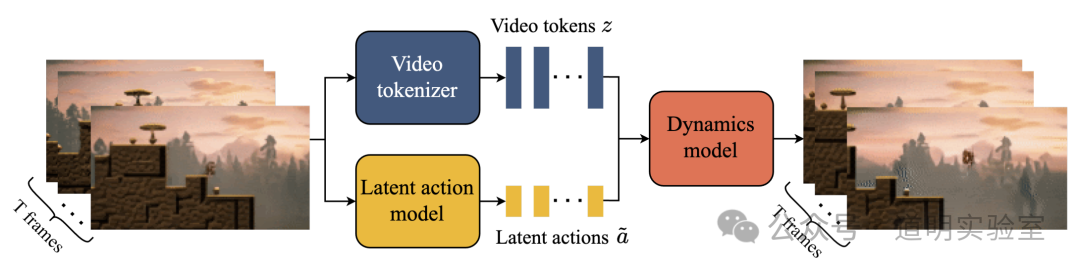
主观上,我特别喜欢Genie的完美架构:ST-Transformer(时间与空间Transformer)与MaskGIT(训练时对图像的部分进行遮盖,增强预测能力)的融合,完全无监督的Latent Action Model,用于视频中下一帧的预测。
这些结合,构造了一个非常完美的“世界”:上传一张图,里面的物体就可以按照promt动起来,甚至,可以像打游戏一样,可以控制物体的运动。
大家立刻为Genie找到了一个马上落地的应用场景,游戏开发。OpenAI刚成立的时候,一个主要方向就是基于游戏场景训练人工智能,在那个时间点上,他们和DeepMind都深信游戏世界是通向AGI的高确定性之路。只是,现在看起来,OpenAI已经基本放弃了游戏世界,而DeepMind用来训练Genie的数据,游戏视频依然占了绝对多数(还有一些开源的数据集)。
DeepMind的科学家还在“打游戏”。
相比之下,OpenAI对于Sora的技术介绍就吝啬了很多。
模型架构就上面一张图,大家所有的解读几乎都是基于DiT的那篇论文。
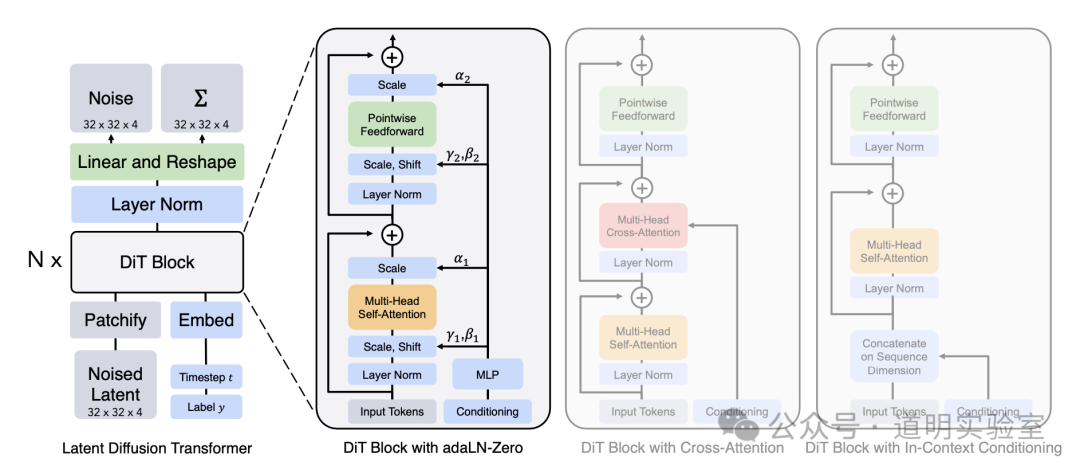
虽然,我相信OpenAI一定是在DiT上做了很多改进,但是,大概率核心模块的改动不会太大。
以OpenAI现在越来越“Close”的做派,架构上的创新这种“炫技”部分,都会大书特书,边边角角的工程优化和反复尝试后得到的“超参数”经验值,都会能遮掩多少就遮掩多少。
因为,工程上的经验,获取成本极高,说出来后却又不值钱了。
可是,这很好,工程师才能做出更接近完美的产品,更何况,这个工程师更倾向于召集优秀的“艺术创作者”加入内部测试的“红队”。
所以,工程师在搞艺术,至少,审美在线的文生视频模型,或许比ChatGPT更挣钱。
关于“科学家”与“工程师”的比喻,我没有任何高低评判,只是,在重新把Diffusion和Vision Transformer相关的几十篇重要论文集中比对学习的过程中,“团队文化”差异成为说服我Sora与Genie根本不同的底层原因。
这种文化影响了选择,选择决定了面临的约束条件,约束条件又制约了选择。
相比AGI这种多少有些虚幻的追求,OpenAI选择做产品,相比用户叫好的产品,DeepMind选择“完美的模型”。
于是乎,Sora的强点,正是Genie的弱项,Genie的优势,又正是Sora努力的方向。

Sora与OpenAI强的地方:1、数据质量,成立以来,OpenAI做过很多尝试,但是唯有对最高质量数据的追求从未减弱,资金与人力投入几乎是天文数字,在ChatGPT推出之前,OpenAI没有任何独家数据,但它却有质量远高于任何人的基础训练数据;2、工程优化与产品调教,即使到现在,OpenAI可能依然还是唯一一家系统性研究及开发AI模型的公司,集群搭建,数据Pipeline,模型训练,精调,产品管理,甚至宣传,这是一个极其庞大的系统性工程,更不是从OpenAI挖几个人就可以带走的;3、疯狂的内卷,从Greg Brockman在社交媒体上发言的时间和内容,就可以清晰的感受到OpenAI远胜996的内卷程度,而且是自发的,也只有这种自发才可以支撑“工程师”们为了一个想法,反复实验,优化。
Genie与Google DeepMind强的地方:1、研究文化,所以无论是老的Google Research与DeepMind,还是合并后的Google DeepMind,这种文化带来了最大量的创新和储备;2、强大的资源,显而易见;
虽然比较两家各自强点的篇幅对比有些反差过大,但是,“研究文化”的内涵太丰富了,所以,会有Genie更完美的模型架构,理论上更大的潜力,会有Gemini这种原生多模态在图像视频理解上更好的表现……
其实,模型发展到了今天,除了少数几个耳熟能详的名字外,可能即使OpenAI和Google内部的研发人员都不能完整的解释一个模型的全部,哪怕粗略一点。
对我们这些外部人员而言,更可怕的是,如果当初8张A100还能训练一下 GPT-2,现在,我们连哪怕小规模验证一下不同模型技术路线的可行性的资格都没有。
我们只能凭着各种论文和技术报告里细枝末节的信息的对比和推理,去揣测,或者自嗨。例如,可以很自嗨的假设下面这些问题与回答:
1、如果DeepMind有OpenAI的数据,他们还会坚持游戏世界的数据质量更好更接近AGI吗?大概率不会。科学家当然懂数据的重要性,却往往不愿意去干数据这种“脏活”。
2、为什么Genie的图像分辨率只有160X90?很多游戏视频的分辨率就是这么高,为了训练方便,孰低原则。DeepMind不屑于搞那些工程师才会做的适应不同训练图像大小,不同生成大小的“吃力不讨好”的活。AGI不应该被分辨率影响的。
3、Sora的参数规模真的是大家猜测的30B左右吗?Sora有不同算力的模型,即使按照技术报告里披露的,都有4X Computer,32X Computer模型,而32X应该还不是最大的。如果简单按照谢赛宁的计算,DiT-XL/2模型是DiT-B/2的五倍规模,那么16X模型的Sora大概三倍于DiT-XL/2,30B参数规模就是这么来的。但是如果是128X呢?就还要提升四倍到30B。另外,参数规模是一回事,训练数据大小又是另一个概念,DiT训练的数据集分辨率是512X512的,latent大小是64X64X4,Sora的训练数据一定有不小的比例分辨率是超过1024X1024的,latent大小很可能到128X128X4,在patch大小都是2的情况下,实际训练数据大小再增加4倍。加上,Sora训练用的视频数据量本身就远大于ImageNet,Sora很可能是训练算力开销上百倍于DiT-XL的模型。然而,这些答案,我们都很难知道准确的数字,因为,工程师反复试验得到的经验值,怎么可能轻易泄露?
4、其实最好的模式或许应该是这样的:科学家继续疯狂发“完美模型”论文,工程师继续落地产品。可惜,他们隶属于两家公司。