Snap has launched Snap-Video, yet another transformer-based text-to-video model utilizing spatial and temporal dimensions. This is the fourth significant model in just two weeks, following OpenAI's Sora, DeepMind's Genie, StabilityAI's Stable Diffusion 3, and this Snap-Video. As for Morph Studio's AIGC film tools, they are based on Stable Diffusion 3, while similar tools from LTX Studio are still difficult to judge.
"Attention is all you need." Transformer has not disappointed. In the field of graphics, through the intense "involution" (extreme competition) among various giants, it has nearly driven convolutional neural networks (CNNs) completely into the bin.
2023 marked the beginning of the "Large Model" era with ChatGPT, while 2024 has seen Sora usher in the "World Model" era. Of course, compared to "Large Model," the term "World Model" is far more aesthetically pleasing. However, "World Model" doesn't mean a model that the whole world can use; it refers to a model that "understands" the human world and can "predict" or "generate" the physical world. The use of "or" here doesn't mean both are applicable; rather, in the eyes of many, they are two distinct paths. Meta's Chief Scientist Yann LeCun believes it is at least not about "generation."
Beyond this controversy, the implicit meaning of calling it a world model is that the model is not intended for human use, but for machines—prepared for a potential AGI (Artificial General Intelligence).
Under the "Generative" path, to train AGI, we first create a physical world that the machine can "understand." Therefore, models like Sora may struggle for a long time to generate perfectly natural videos of humans walking. However, who can be certain whether the machine has established the concept of "this person is walking"?
Under the "Predictive" path, we let the machine observe the real physical world—perhaps many different videos of different people walking—and then let the machine derive the concept of "walking" itself. This is a very old-school approach, almost the original goal that "deep learning" sought to achieve. Because of this persistence, on the same day Sora was released, Meta introduced the V-JEPA model—pure prediction, no generation. V-JEPA introduces excellent concepts and many clever ideas; from a research perspective, the results are quite encouraging. However, it is still in its infancy; while promising, it has not yet proven scaling capabilities and is far from productization. But this is exactly what scientists produce.
I have always felt that Yann LeCun is among a stubborn minority. But after carefully comparing OpenAI's Sora and Google DeepMind's Genie, I realized I might be wrong. Google DeepMind might actually be closer to Yann LeCun. They are "proud," "showy," and see themselves as scientists. In contrast, the OpenAI team looks more like engineers who are even more "involutionary" than the 996 work culture.
Google proposed the Transformer; OpenAI applied it in GPT.
DeepMind, in collaboration with OpenAI, proposed RLHF (Reinforcement Learning from Human Feedback); OpenAI applied it in ChatGPT.
Google proposed ViT (Vision Transformer), Runway proposed the Latent Diffusion Model, and Meta's team combined them to propose DiT (Diffusion Transformer); OpenAI applied DiT in Sora.
...
These anecdotes have been discussed by many. I bring them up not because of a subjective preference for Google, but because I believe the hardest part in all three scenarios is the word "applied."
AI is not about writing papers; it is about systematic, countless experiments. That is why the current temporary leader is OpenAI, leading by a score of 2:0.
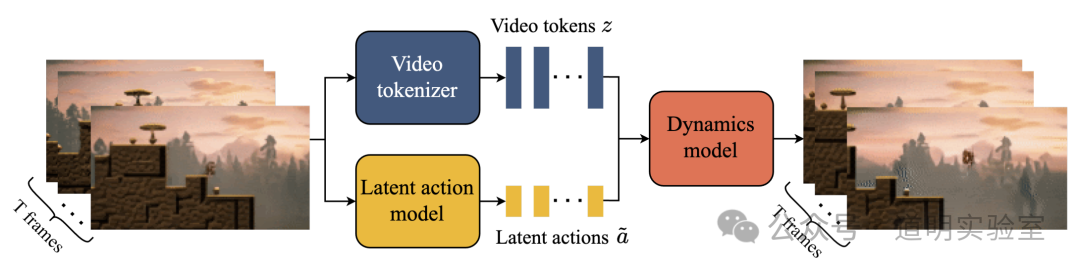
Subjectively, I particularly like Genie's perfect architecture: the fusion of ST-Transformer (Spatial-Temporal Transformer) and MaskGIT (masking parts of the image during training to enhance prediction capabilities), and a completely unsupervised Latent Action Model used for predicting the next frame in a video.
These combinations create a near-perfect "world": upload an image, and the objects within it can move according to a prompt; one can even control the movement of objects, much like playing a video game.
People immediately found an immediate application scenario for Genie: game development. When OpenAI was first founded, a major direction was training AI based on gaming scenarios. At that time, both they and DeepMind firmly believed the game world was the path of high certainty toward AGI. However, it now appears OpenAI has largely abandoned the game world, while the data DeepMind used to train Genie still consists predominantly of game videos (along with some open-source datasets).
DeepMind's scientists are still "playing games."
In comparison, OpenAI's technical introduction to Sora is much more stingy.
The model architecture is summarized in just the image above. Almost all interpretations are based on the DiT paper.
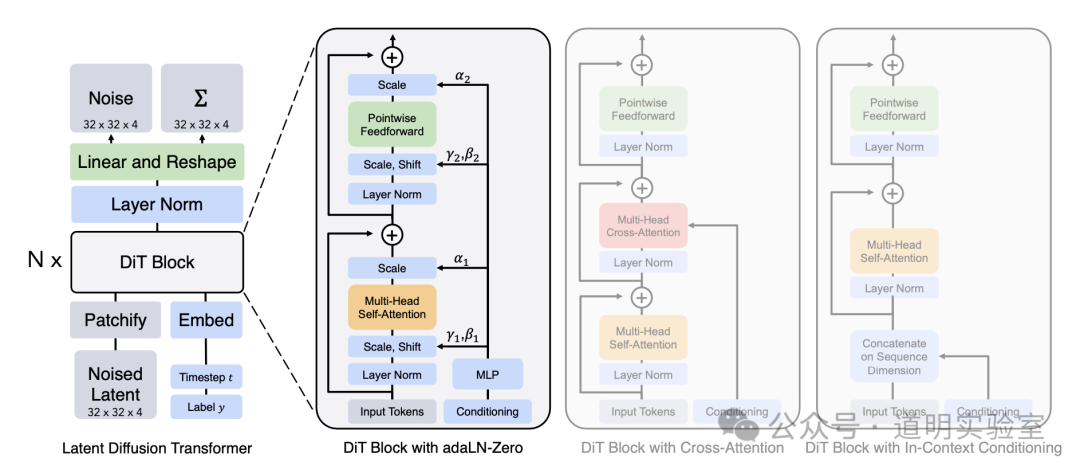
While I believe OpenAI must have made many improvements to DiT, the core modules likely haven't changed much.
Given OpenAI's increasingly "Closed" approach, the "showy" parts of architectural innovation are highlighted, while engineering optimizations and "hyperparameter" values obtained through trial and error are obscured as much as possible.
This is because engineering experience is extremely costly to acquire but becomes worthless once shared.
But this is good; only engineers can create products that approach perfection. Furthermore, these engineers are inclined to invite elite "artistic creators" to join the internal "Red Team" for testing.
Thus, engineers are creating art. At the very least, an aesthetically pleasing text-to-video model might be more profitable than ChatGPT.
Regarding the analogy of "scientists" versus "engineers," I am not making a value judgment. However, after cross-referencing dozens of key papers related to Diffusion and Vision Transformer, the difference in "team culture" became the underlying reason that convinced me Sora and Genie are fundamentally different.
This culture influences choices, choices determine constraints, and constraints in turn restrict choices.
Compared to the somewhat illusory pursuit of AGI, OpenAI chooses to build products. Compared to products that users cheer for, DeepMind chooses "perfect models."
Consequently, Sora's strengths are Genie's weaknesses, and Genie's advantages are the direction Sora is striving toward.

Where Sora and OpenAI are strong: 1. Data quality: Since its inception, OpenAI has made many attempts, but its pursuit of the highest quality data has never wavered. The investment in capital and manpower is astronomical. Before ChatGPT, OpenAI had no exclusive data, but it had basic training data of far higher quality than anyone else. 2. Engineering optimization and product tuning: Even now, OpenAI might be the only company systematically researching and developing AI models. Cluster setup, data pipelines, model training, fine-tuning, product management, and even PR form a massive systemic engineering project that cannot be replicated by poaching a few people. 3. Intense competition: From Greg Brockman's social media posts, one can clearly sense an intensity far exceeding 996. This is spontaneous, and only such spontaneity can support "engineers" in repeatedly experimenting and optimizing a single idea.
Where Genie and Google DeepMind are strong: 1. Research culture: Whether it was the old Google Research and DeepMind or the merged Google DeepMind, this culture has brought about the largest amount of innovation and reserves. 2. Massive resources: This is obvious.
While the space dedicated to comparing their respective strengths seems disproportionate, the depth of "research culture" is profound. Thus, we have Genie's more perfect model architecture and theoretically greater potential, and Gemini's superior performance in image and video understanding as a native multimodal model.
In fact, now that models have reached this stage, with the exception of a few well-known names, perhaps even R&D personnel inside OpenAI and Google cannot fully explain an entire model, even roughly.
For those of us on the outside, what's even scarier is that while 8 A100s could once train GPT-2, we now lack the qualifications to conduct even small-scale validation of different model technical routes.
We can only speculate or engage in "self-indulgence" based on comparing and inferring from minor details in papers and technical reports. For example, one could self-indulgently hypothesize the following questions and answers:
If DeepMind had OpenAI's data, would they still insist that game world data is better and closer to AGI? Probably not. Scientists understand the importance of data but are often unwilling to do the "dirty work" of data curation.
Why is Genie's image resolution only 160x90? Many game videos are exactly that resolution; for training convenience, the principle of the lowest common denominator was applied. DeepMind doesn't bother with the "thankless" engineering tasks of adapting to different training image sizes and generation sizes. AGI shouldn't be affected by resolution.
Is Sora's parameter scale really around 30B as speculated? Sora has models of different compute intensities. Even according to technical reports, there are 4X and 32X Compute models, and 32X is likely not the largest. If we follow Saining Xie's calculation where DiT-XL/2 is five times the scale of DiT-B/2, then a 16X Sora model is roughly triple the size of DiT-XL/2, leading to the 30B parameter estimate. But what if it's 128X? That would increase it fourfold to 120B. Furthermore, parameter scale is one thing; training data size is another. DiT was trained on 512x512 resolution with a latent size of 64x64x4. A significant portion of Sora's training data likely exceeds 1024x1024, with a latent size possibly at 128x128x4. If patch size remains at 2, the actual training data size increases fourfold again. Combined with video data volumes far exceeding ImageNet, Sora's training compute cost is likely hundreds of times that of DiT-XL. However, we are unlikely to know the exact numbers because why would engineers easily leak the experience values they gained through repeated trials?
Actually, the best model might look like this: scientists continue to publish "perfect model" papers, and engineers continue to launch products. Unfortunately, they belong to two different companies.