
NVIDIA has announced yet another piece of "paperware": the Rubin CPX chip, specifically targeted at massive context (million tokens) inference, and the Rubin NVL144 CPX which incorporates it.
TL;DR: I am not optimistic about this product for the following reasons:
- This configuration is somewhat of a "white elephant." User scenarios are diverse. Even if it targets long-context scenarios like AI search, code generation, and video processing, it's easy to conclude that even if the ratio of Rubin to Rubin CPX is 4:8 and compute power is 1:1, the HBM will spend a significant amount of time idle. Why wouldn't inference providers just use non-HBM compute? It's cheaper, uses less power, handles heat better, and is easier to maintain.
- If user scenarios remain mixed, the absolute volume of chat requests is still high. The relatively low bandwidth of GDDR7 could slow down the entire system's response time.
- While this system might have some rationale in space-constrained data centers due to its high compute density—and providers could perform complex scheduling—the issues return to heat and CPU bottlenecks. Furthermore, the more optimizations inference providers (model companies) do, the less irreplaceable NVIDIA's hardware becomes.
Here is the full article.
The image below shows the Rubin CPX chip, which uses 128GB of GDDR7 memory.
The image below shows the Rubin NVL144 CPX: a rack with 18 trays, each containing four Rubin GPUs and eight Rubin CPX chips.

This leads to a new set of ceiling metrics: 8 exaflops (NVFP4), 100TB memory (HBM+GDDR7), claiming performance 7.5x that of the GB300 NVL72.
NVIDIA wins again, apparently: "For every $100M investment, there's a $5B return."

This statement appears blatantly in their press release without qualifying footnotes. I've screenshotted it, wondering if it will lead to a class-action lawsuit one day. I never doubt NVIDIA's capabilities or status, but I'm increasingly repulsed by this borderline irresponsible "false advertising." According to data NVIDIA just released in MLPerf 5.1 and on its website, even with the GB300 NVL72 inferencing DeepSeek R1, the single-GPU performance increase over the Hopper architecture is only 5.2x. Please, show us the 30x performance boost claimed at launch.
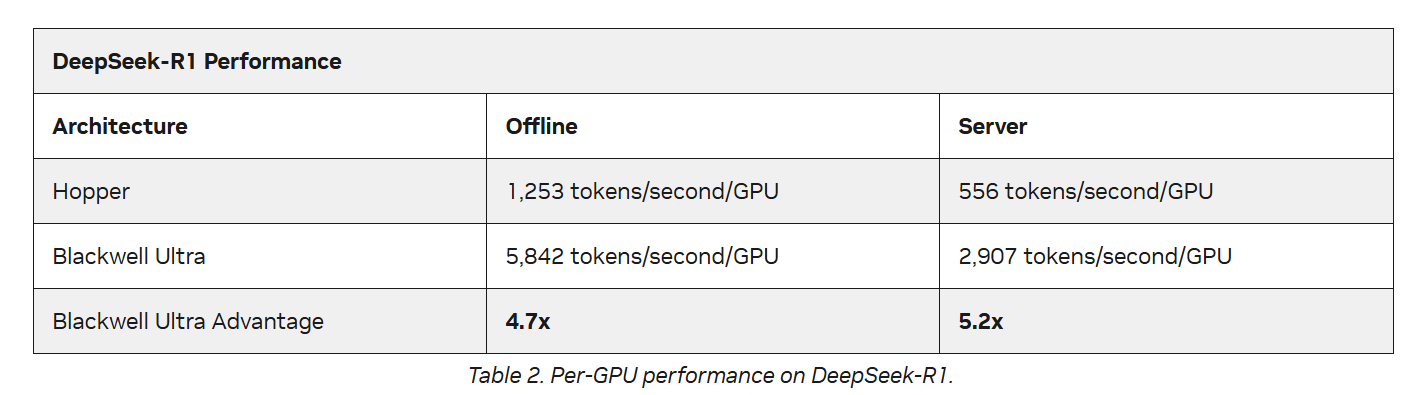
https://developer.nvidia.com/blog/nvidia-blackwell-ultra-sets-new-inference-records-in-mlperf-debut/
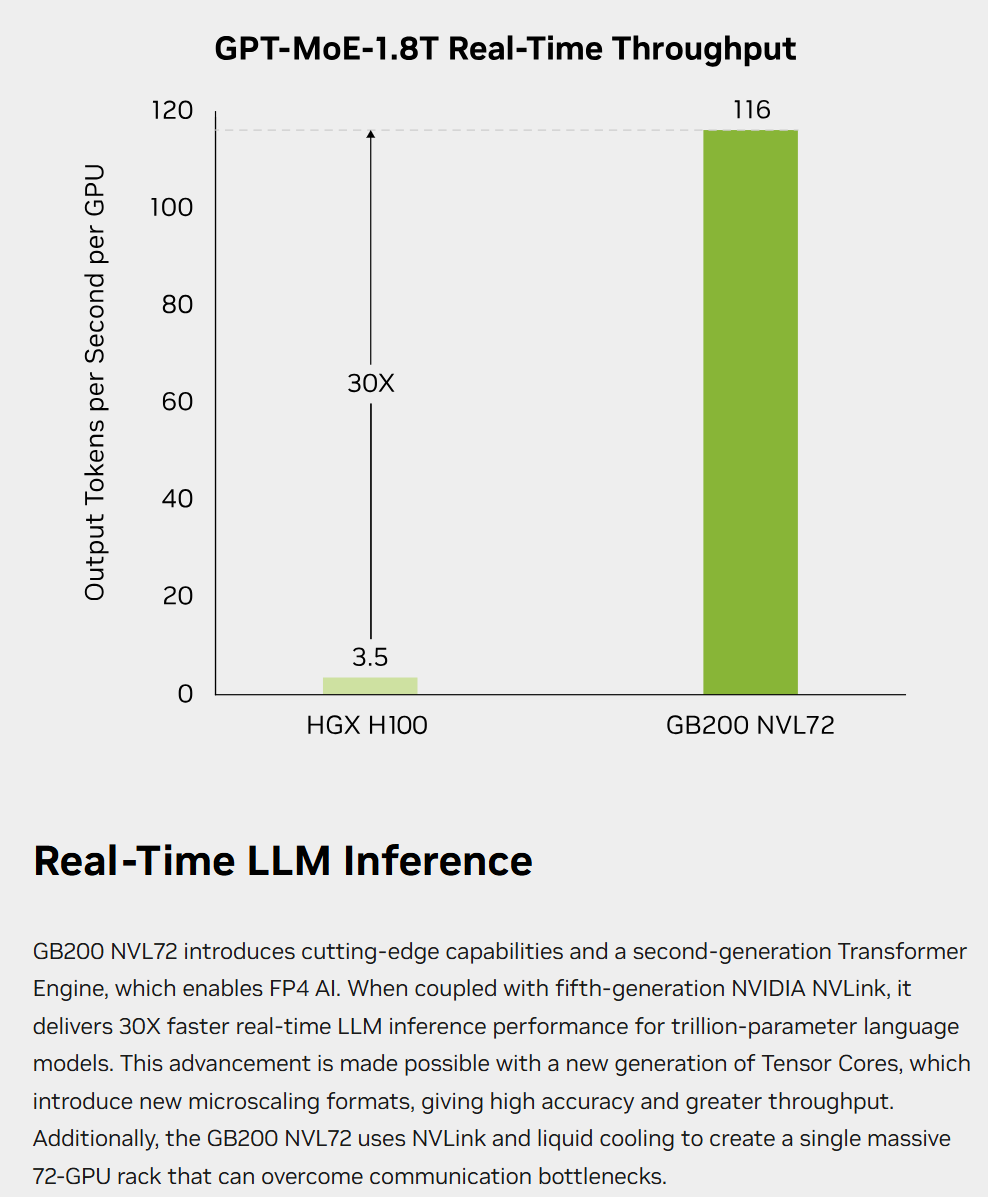
https://www.nvidia.com/en-sg/data-center/gb200-nvl72/
Moreover, this is still "paperware" with an expected delivery in late 2026—which likely means another six months on top of that.
The above was purely emotional skepticism. Let's discuss the technical side: why push this product?
The main reason is to counter potential competitive pressure. AMD has released a competitor to NVL, the Helios rack based on MI400, which features stronger CPUs and better inference cost-performance. While AMD's cadence is at least half a generation behind NVIDIA, the community is quite optimistic about this product, and the ROCm ecosystem (targeting CUDA) has matured significantly. There is also the XPU trend popularized by Google's TPU.

Beyond competition, long-context inference scenarios are growing rapidly. The surge in token usage since last year is largely driven by search, code generation, and upcoming video generation. These differ significantly from traditional AI chat.
Inference has two stages: prefill and decode. In a dynamic demo, prefill (blue) is loading user input/context, and decode (green) is "guessing the next word."
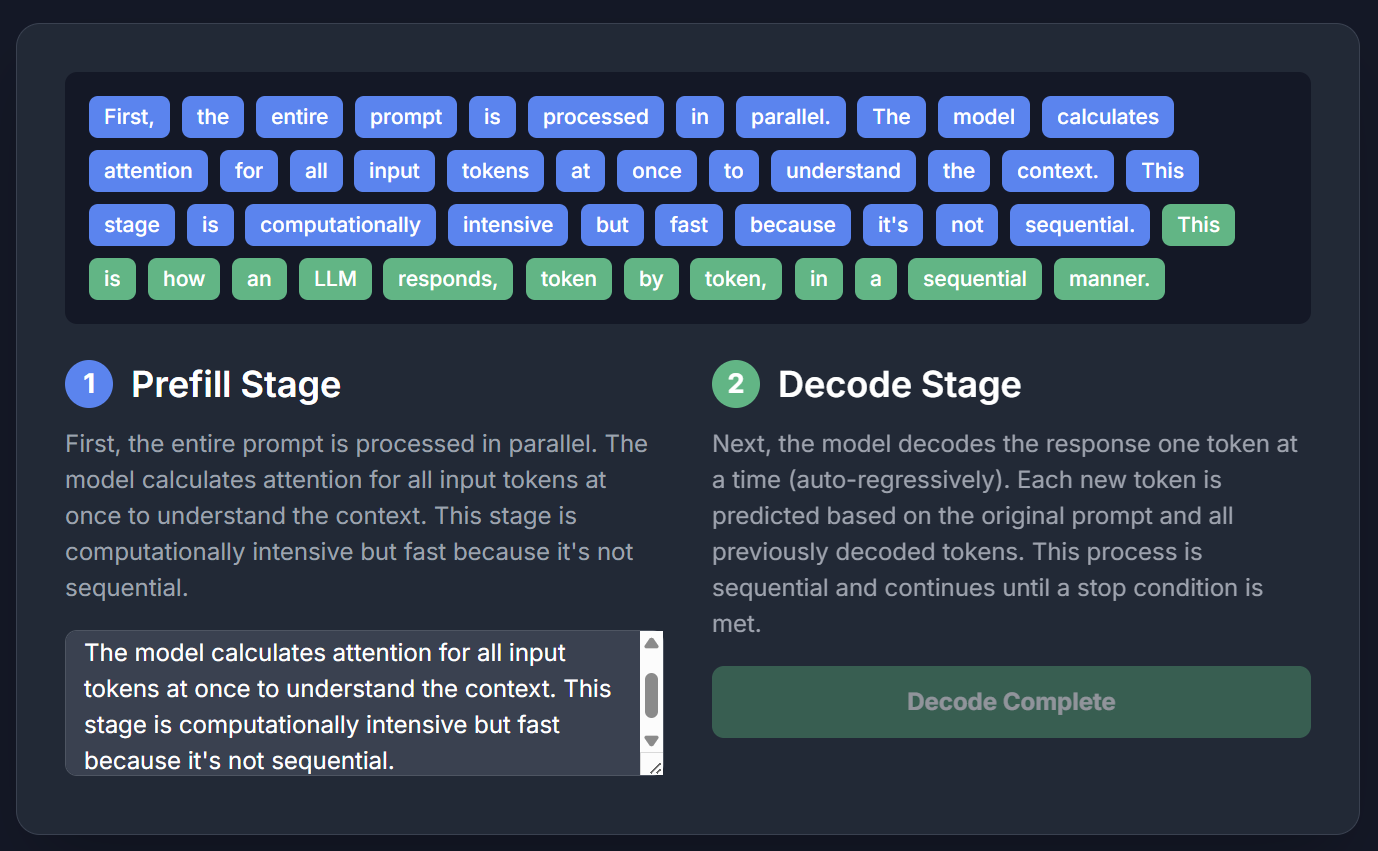
The hardware requirements differ: prefill needs more compute, while decode needs more memory bandwidth and KV-Cache capacity.

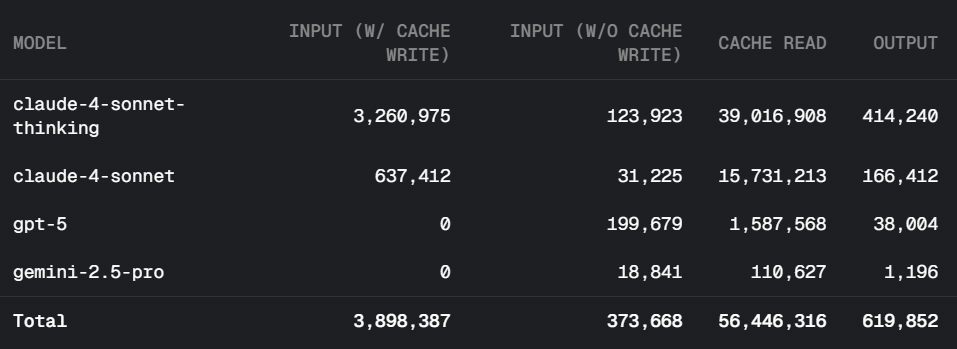
When context is long, prefill demand spikes (needing more compute), but bandwidth requirements remain relatively low. In standard AI chat, the difference is less stark (e.g., DeepSeek R1 data shows a roughly 3-4:1 input-to-output ratio).
However, in search and code generation with Agents, the ratio changes drastically.
As shown below, in search tasks, input tokens can be hundreds of times the output tokens.
In code generation, the ratio can reach 100:1.
Since long context requires long prefill times, HBM bandwidth effectively sits idle or underloaded during this phase. From a depreciation perspective, having expensive HBM bandwidth idle for more than half the time is uneconomical in long-context scenarios.
This is where NVIDIA's market sensitivity shows: pairing the same compute with much cheaper memory (GDDR7) to specialize in prefill.
This is the value of this architecture, as illustrated by the diagram from NVIDIA's website below.
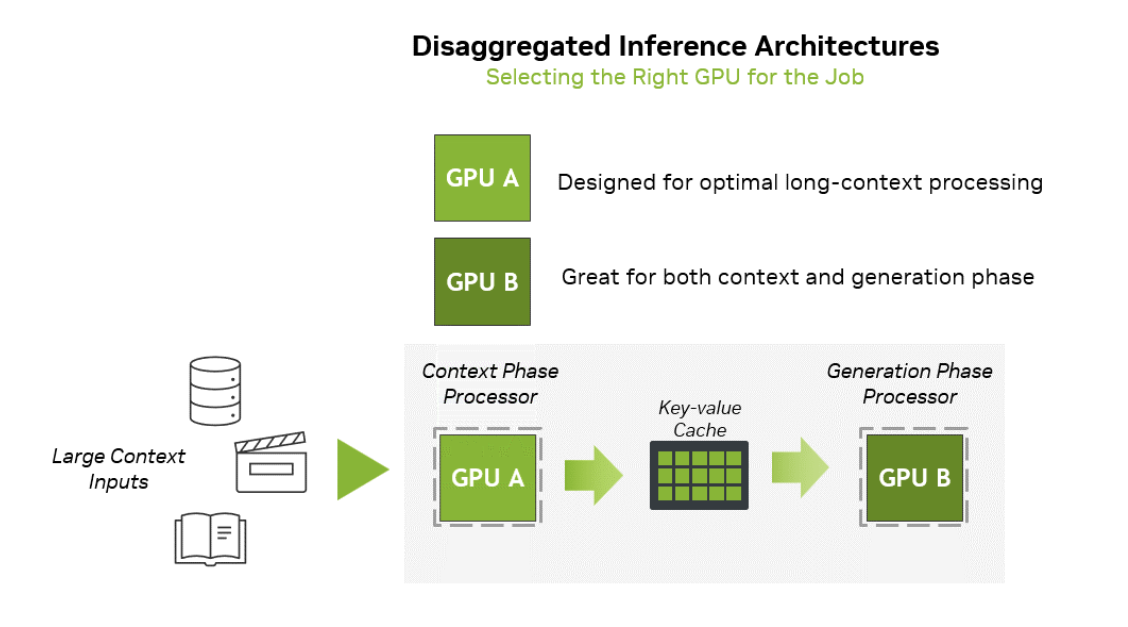
Despite this, I remain skeptical. The configuration is awkward for diverse scenarios, and as model companies optimize software, NVIDIA's hardware moat may shrink. NVIDIA's core strength is its aggressive pace, but for now, physical limits remain a reality.