
Regarding the outlook for next year, I have been mulling it over for a long time. During my conceptualization, a predictable and major change occurred: the release of Gemini-3 and Nano Banana Pro models. Their significance is not about a leaderboard or proving that scaling laws still work—whether in pre-training or post-training. Their significance lies in this: when a model breaks the ceiling of human capability in a certain field, it drives a transformation of the entire digital world.
Therefore, in terms of form, for this outlook, I do not need to organize data, charts, or videos, or even look up references, because the model can assist me. Although it is still not perfect, it has already significantly surpassed me in almost all instrumental parts—not just in capability, but in execution efficiency.
In terms of content, this outlook can be a bit more macroscopic because the details can be filled in by the model, not necessarily under my "command," but under anyone's command.
In case the text gets boring, here are some different forms of expression: some "raw stuff."


So, where to start?
Start with intelligence. When giants invest in computing power, data centers, and electricity at any cost, there is only one ultimate goal: intelligence. We still cannot fully articulate what "intelligence" is, but it should be like a human: capable of active thinking, adapting to a wide enough range of scenarios, executing autonomously, and growing autonomously.
This is the starting point for the title of this outlook: "The Bitter Lesson," a summary by Richard Sutton, the "father of reinforcement learning." While many Chinese translations use "苦涩" (bitter), I feel "艰涩" (arduous/gritty) might be more suitable for the present and future.
The so-called bitter lesson refers to the fact that any attempt to "discipline" a model by teaching it rules and knowledge will ultimately be defeated by "letting the model grow itself through more data."
If we believe this (at least I completely do), then the practical questions are two-fold: Are current models on the right path? And where is the future direction?
This is why I think using "arduous" might be better: because if we believe in data, we know how difficult the path of data expansion will be.
Back to practical questions.
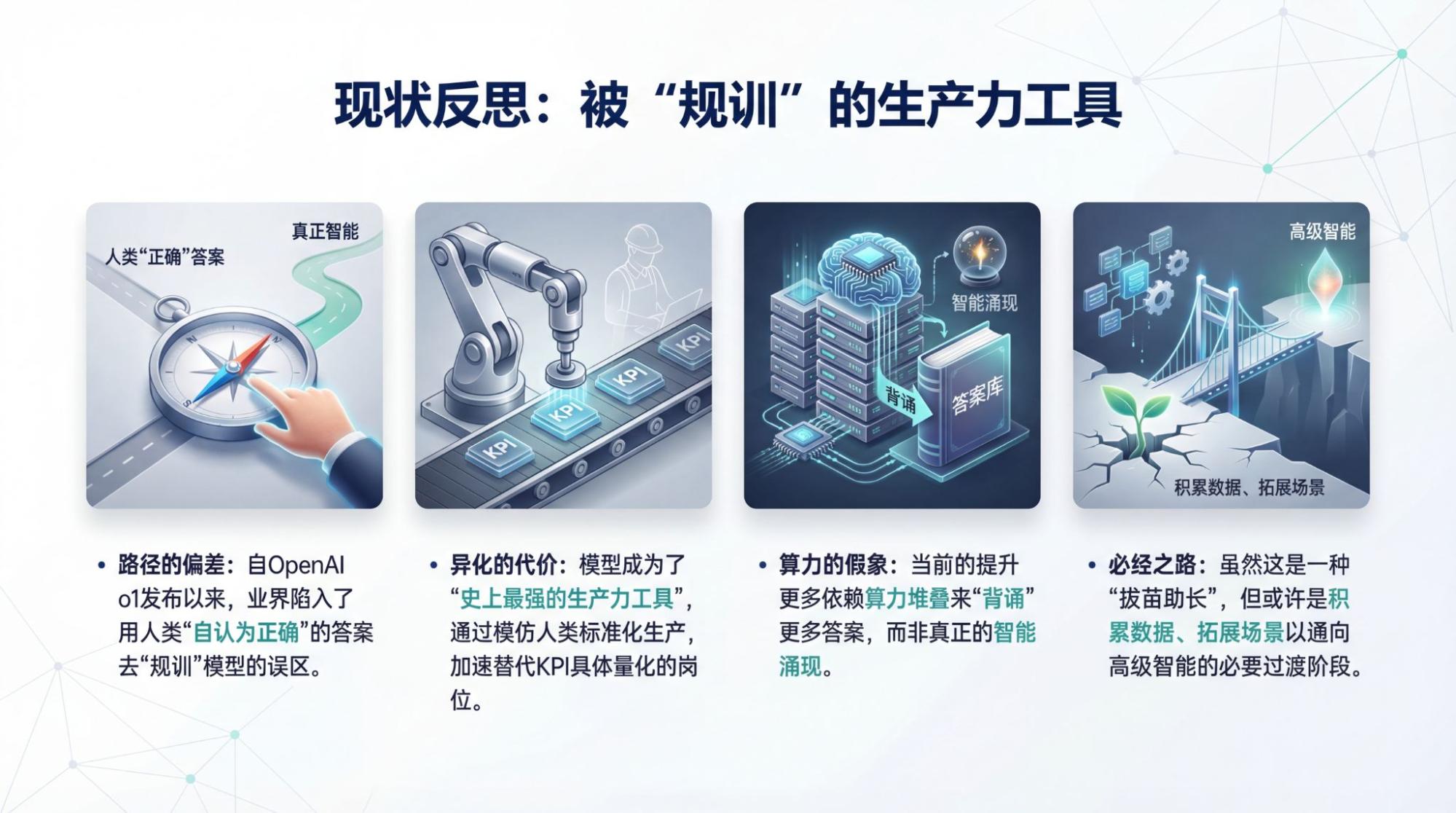
Are current models on the right path? I don't think so. Not since OpenAI released the o1 reasoning model last year. To make models look useful, we have used a bunch of answers and processes that we humans "believe to be correct" to discipline the model, allowing it to "mimic" us in doing many things.
I have discussed this issue several times. To a large extent, this is a good thing; it has allowed AI to prematurely become the "strongest productivity tool in history."
But it is also a destructive "alienation." It chose the easiest path, where data is most abundant and in fields where humans were once "most proud": so-called knowledge, test-taking, and standardized production.
Today, we no longer need to discuss whether AI will replace human jobs, because many positions are being and will be accelerated out of existence—specifically those fields where KPIs are most concrete and quantifiable.
The only reason more positions still seem safe is simple: insufficient computing power.
I believe the only reason this path does not lead to the intelligence we understand is that models are just rapidly memorizing answers obtained from human practice, and no one can say for sure whether those answers themselves are correct.
With a 10x increase in compute, we might memorize two or three times more "answers." With a 10x increase in compute, we might recite two or three times more "answers" in the same amount of time. That's all.
However, this might be a necessary stage. When compute and data are insufficient, we might only be able to "pull up the seedlings to help them grow" by constantly adding human "cleverness." But this forced growth might also allow us to obtain more data and expand into more scenarios, eventually leading to a high-end version that doesn't need that "cleverness."
It’s just that this path is bound to be "arduous."
The second question: where is the future direction? Everyone can have a different understanding of their own "intelligence." However, knowledge itself doesn't seem to make us "smarter"; our intelligence seems more derived from learning from mistakes. Yet, the ability to generalize from mistakes varies from person to person, as does the ability to learn from the mistakes of others. We try, fail, think, optimize, try again, succeed, think again, try again, fail again...
Countless repetitions have made each of us who we are today, and made humanity what it is today. A barber apprentice must be clumsy at first, and an intern nurse is likely to miss a vein. But it is through countless repetitions and attempts that they achieve mastery. I suspect that much of the data during their growth process was not explicitly recorded, but our brains likely initiate an "invisible data training mode" without us realizing it, eventually making us faster, higher, and stronger.
I don't know if explicitly recording all this data would allow a model to achieve such "mastery," though it likely could. However, it likely would not follow the same "growth path" as humans. A human can significantly increase the speed of arithmetic after a certain period of training. For a model, increasing speed might rely more on increasing computing power.
Even with enough data, repeated training on the same hardware might not improve a model's speed. Although many algorithmic optimizations can significantly increase speed, just like many computer algorithms, we try our best, but perhaps moving from O(N*N) to O(NlogN) is the limit of what we can achieve.
But what if we don't apply discipline or optimization? If there is enough data, will the model one day find a way to significantly optimize itself? If we believe in the "arduous lesson," we should believe this—at least I do.
We haven't found these methods simply because they are still in our so-called "blind spots of knowledge." But with enough data, the unknown can become known.
So, will it be world models?
I cannot give a specific definition of a "world model," and even teams or leaders claiming to study world models might give wildly different answers. Some think we need a completely digital mirror of this world; some say it needs an expression of force; others say it must conform to physical laws...
However, they seem to converge on one point: data. Yet, they also seem to contradict themselves: if data is the most important thing, why are we still imposing rules?
To some extent, what is called a "world model" today might just be another mistake following the reasoning model: we always want to use our own "successful experience" to discipline the model, but we ourselves don't actually understand the data at all.
But it doesn't matter. Whichever path is taken, wherever the future path truly lies, accumulated data will most likely be a necessary prerequisite.
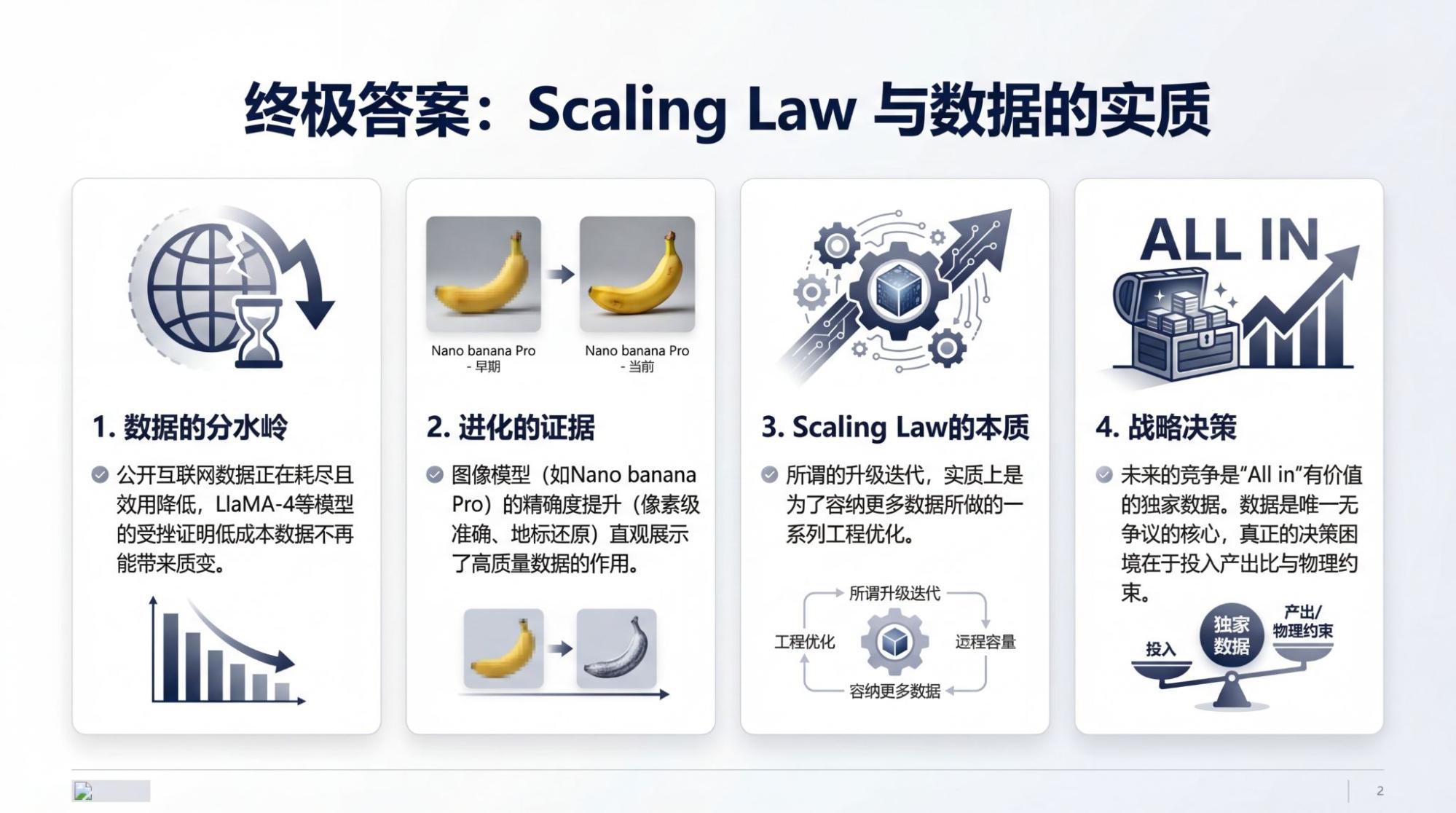
Public internet data is indeed being exhausted rapidly. However, even if public data is still used on a large scale, the data that truly brings improvements to models will no longer be this low-cost data. Otherwise, the LlaMA-4 model wouldn't have failed, and the Grok series models wouldn't look good on paper but always perform below expectations in use...
Today's models are too "direct." So direct that in generation after generation of model iteration, visible progress can be explained by data. If text models aren't intuitive enough, then image models like Nano Banana (Pro) clearly show evidence of the effect of increased data volume. This doesn't just come from rendering text correctly, but from the precision of depicting the real world, the accuracy of landmark information, and the accuracy of every element in an infographic.

Returning to an infographic that many people find uncomfortable—the issue was never whether it looked good or bad; the issue has always been in the details.

We will soon achieve pixel-level total correctness while obtaining constantly improving resolution, from 1k to 4k. Why can't the next step be 8k?
Every pixel is a testament to the fact that models are containing more and more data. So-called upgrades and iterations are nothing more than a series of engineering optimizations to accommodate more data—this is the essence of the Scaling Law.
Go all-in on all nodes that generate large amounts of valuable, exclusive data. The decision dilemma—whether it is worth a larger investment to accommodate so much data, or whether to wait for the accumulation of hardware progress to iterate at a lower cost—gradually becomes a trade-off under physical constraints and break-even considerations.
Data is the only thing that is undisputed. What is disputed is simply: which data?