During the Spring Festival, I had a very specific cognitive shift:
Regarding the implementation of AI applications, my views are not representative. I've actually admitted this for over a year but have struggled to find a way to calibrate it. OpenClaw provided me with a great opportunity and inspiration;
Following this inspiration, I've been making some new attempts for a while, and today it's about skills.
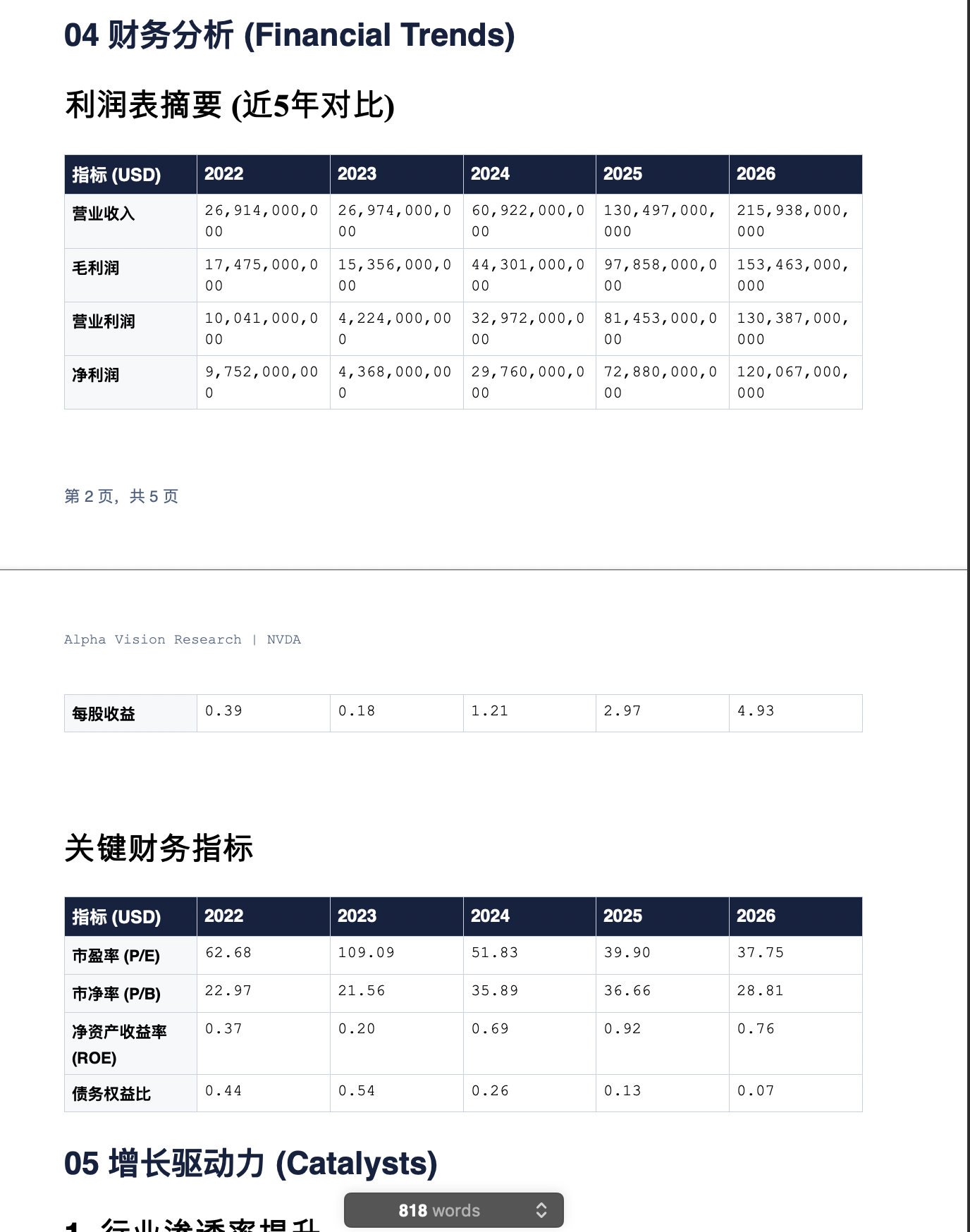
Honestly, I've never truly valued MCP and Skills. In my eyes, MCP is just an upgrade to APIs, and of course, I only trust official MCPs (like Figma's). Skills seem even more like prompt optimization. In fact, even though Anthropic recently launched a financial analysis Skill (they call it a plugin, but it's essentially a skill), I still believe the output is vastly different from my OpenResearch from last year. My OpenResearch only relied on two or three files, and the underlying principle is identical.
However, with Cowork, Antigravity, and Codex adding support for MCP and Skills, and with more and more third-party applications launching official MCP/Skills, I've gradually come to appreciate the advantages of Skills: they are more standardized and concise. Although I still believe my original OpenResearch design was far more elegant.
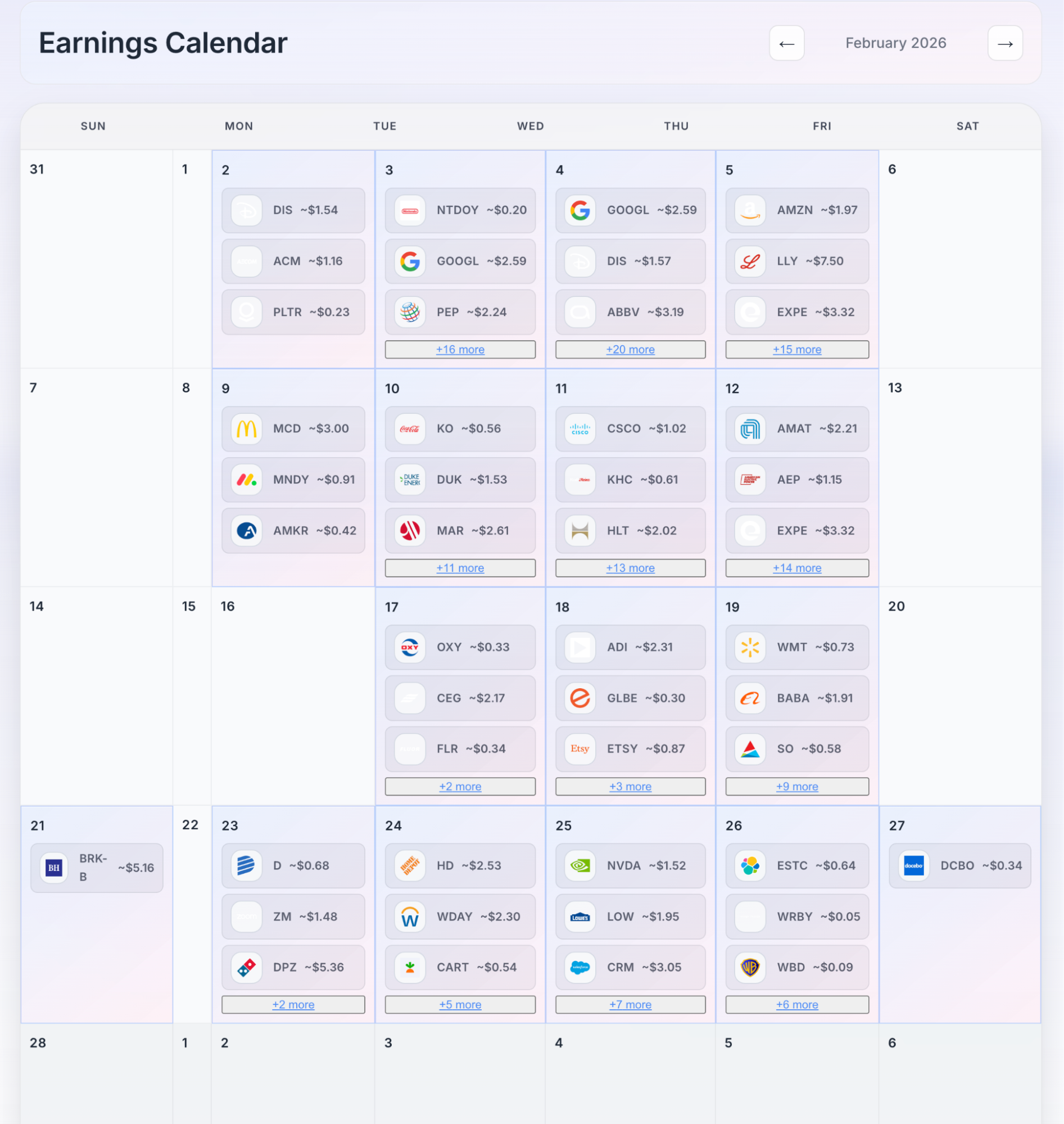
Getting back to the point, this evening, I had a sudden idea: to see to what extent Cowork could replicate the U.S. stock website I use myself.
Of course, it mainly looks like this below. It's a bit flashy. After a while, I got lazy about optimizing and unifying the interface; it's just for my own use anyway.
I didn't expect Cowork to reach this level, but what I wanted to see was, given its FMP API Key and Watchlist, what could it achieve within its usage limits.
I incorporated the financial analysis plugin (skill), docx and pptx skills, and a front-end design skill. Distributed execution: first, design; then, call data; third, generate reports and PPTs; fourth, aggregate into a website.
I consumed two five-hour usage quotas from my Pro subscription.
The front-end design UX amazed me.
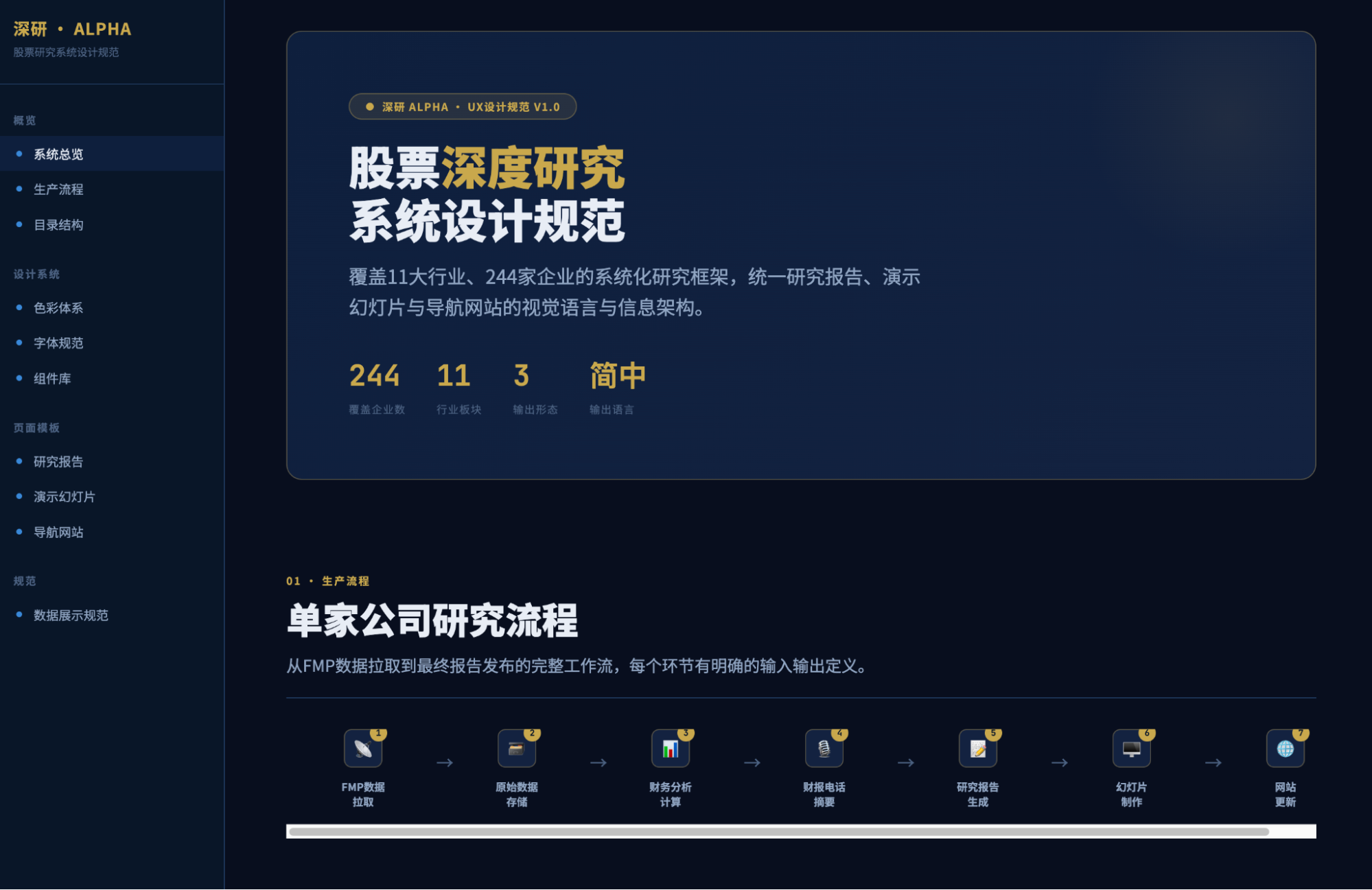
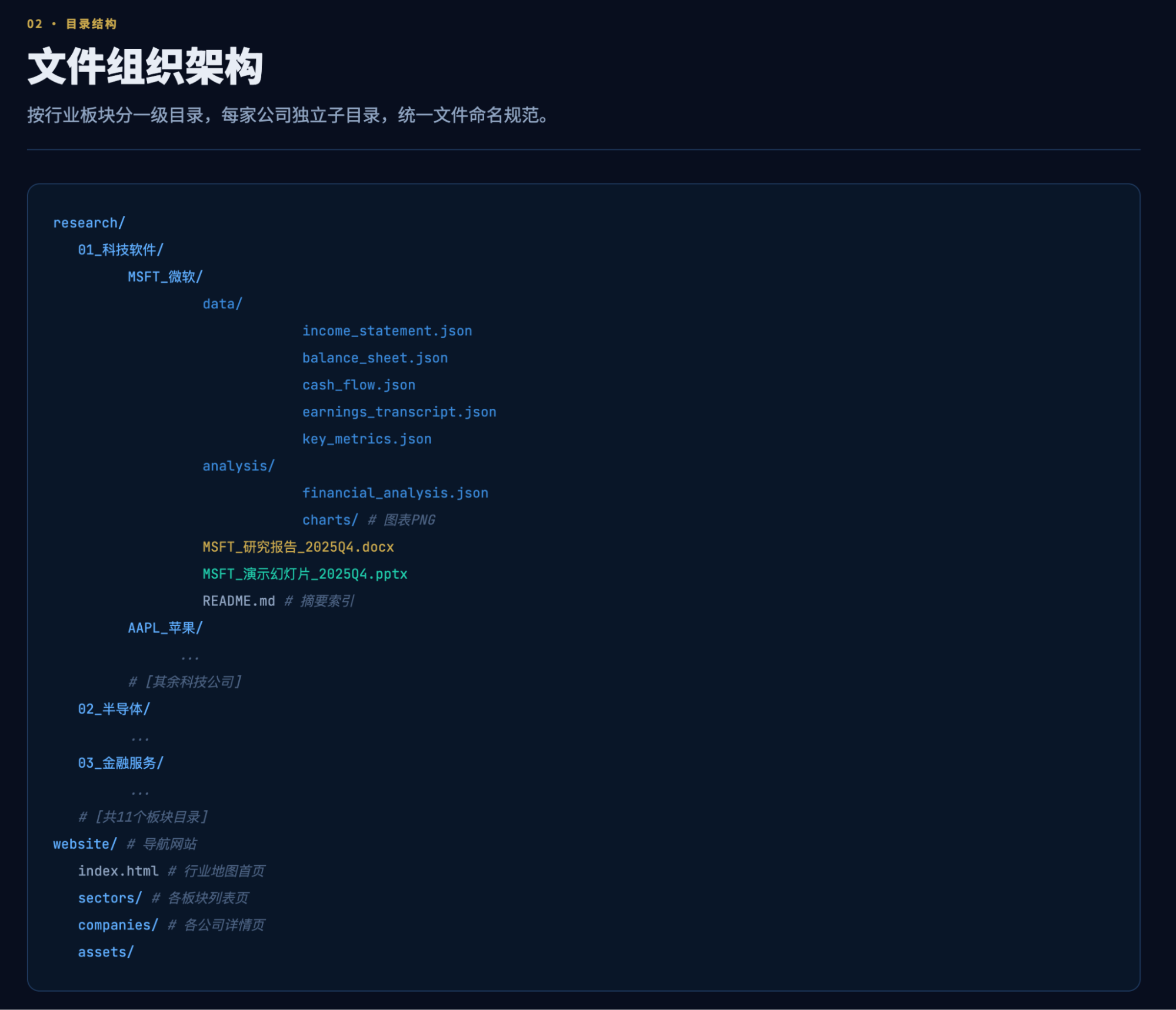
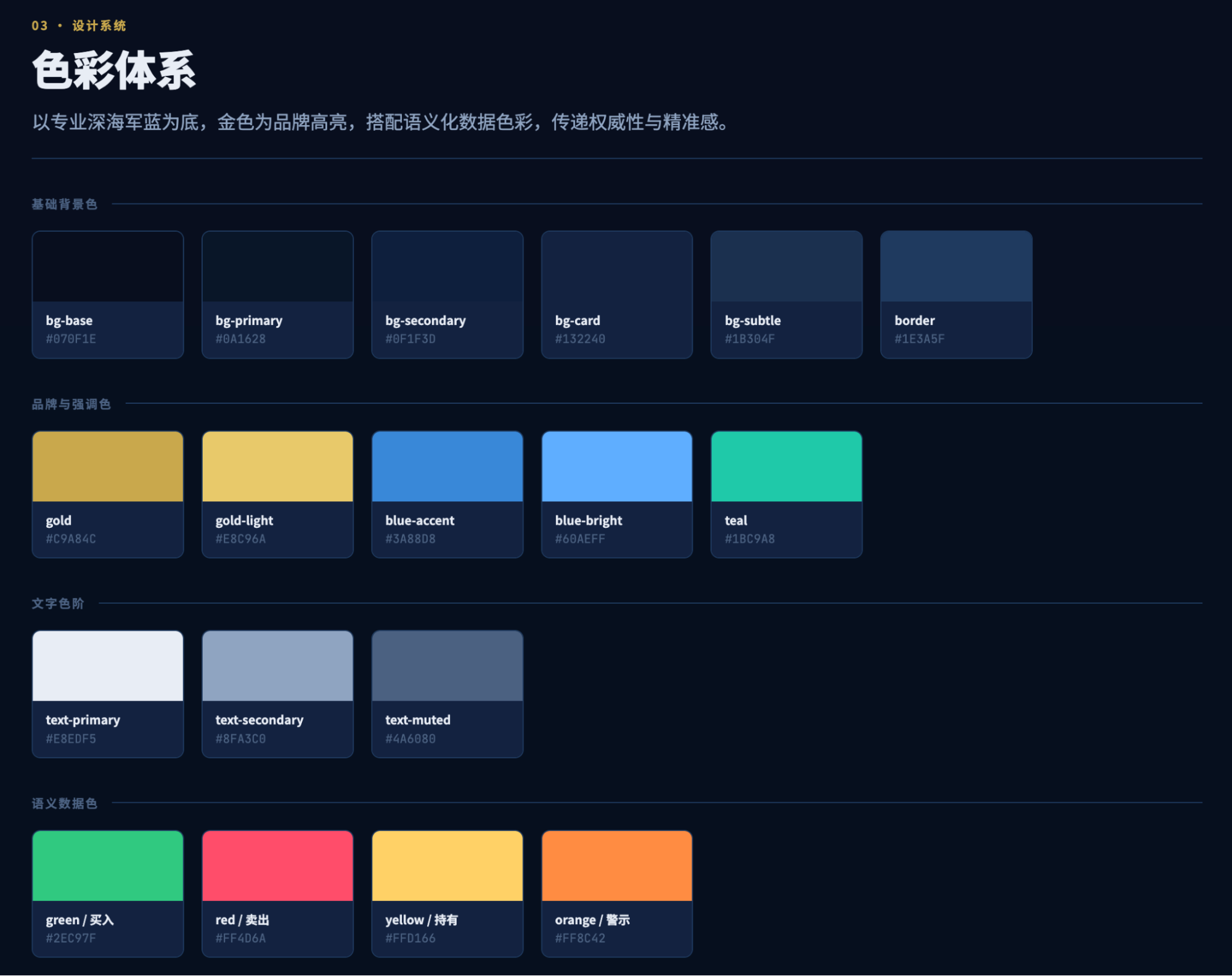
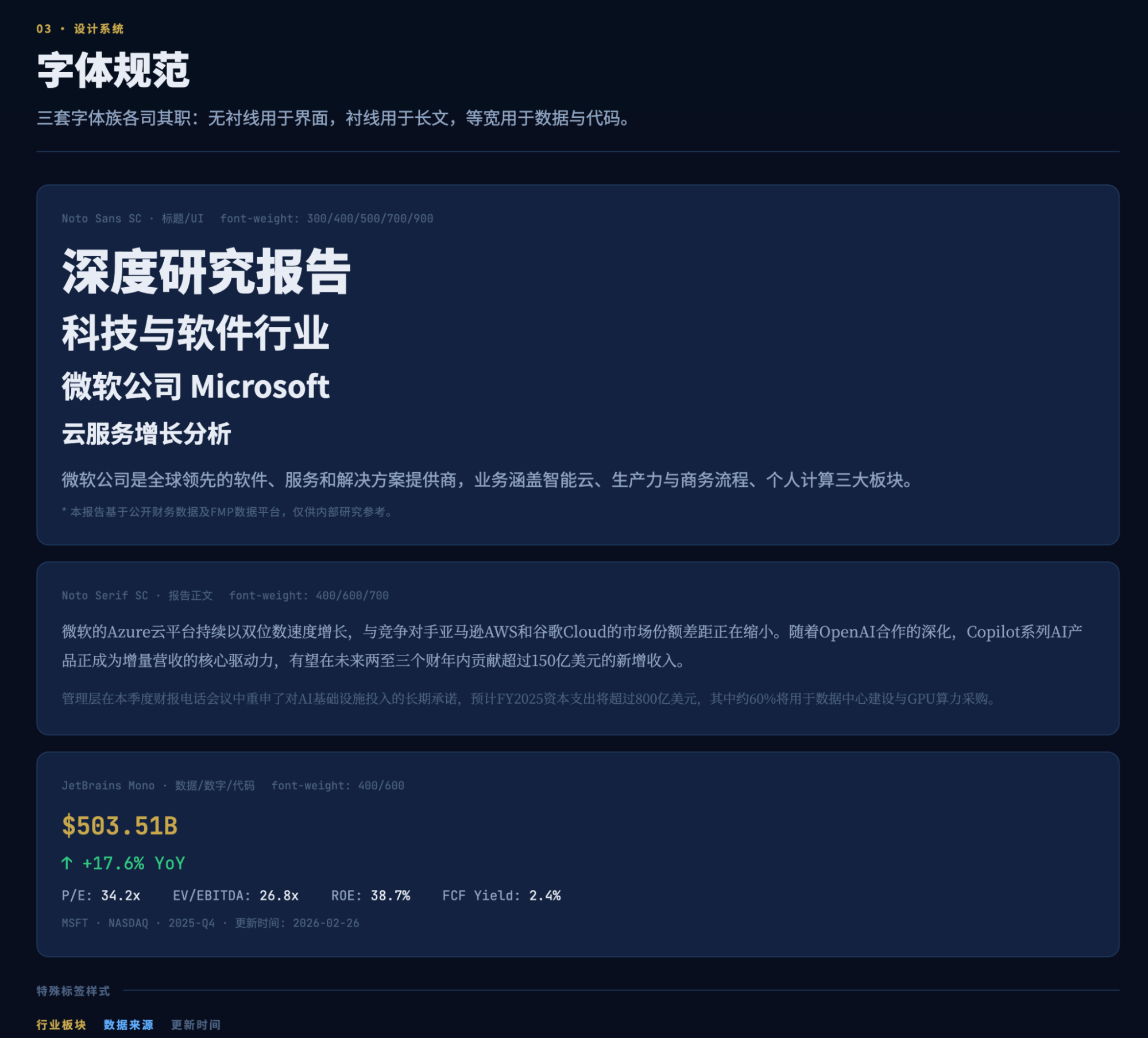
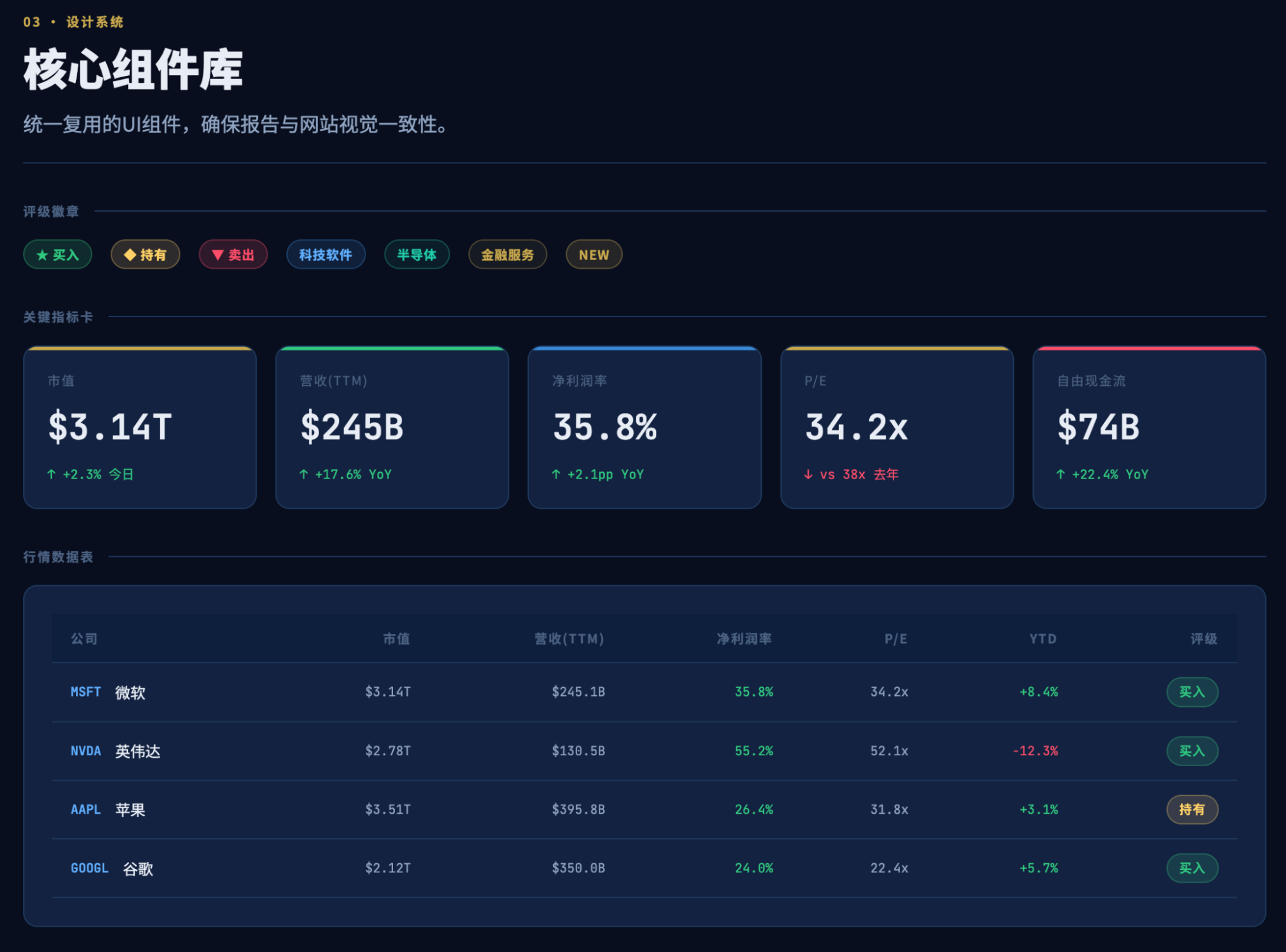

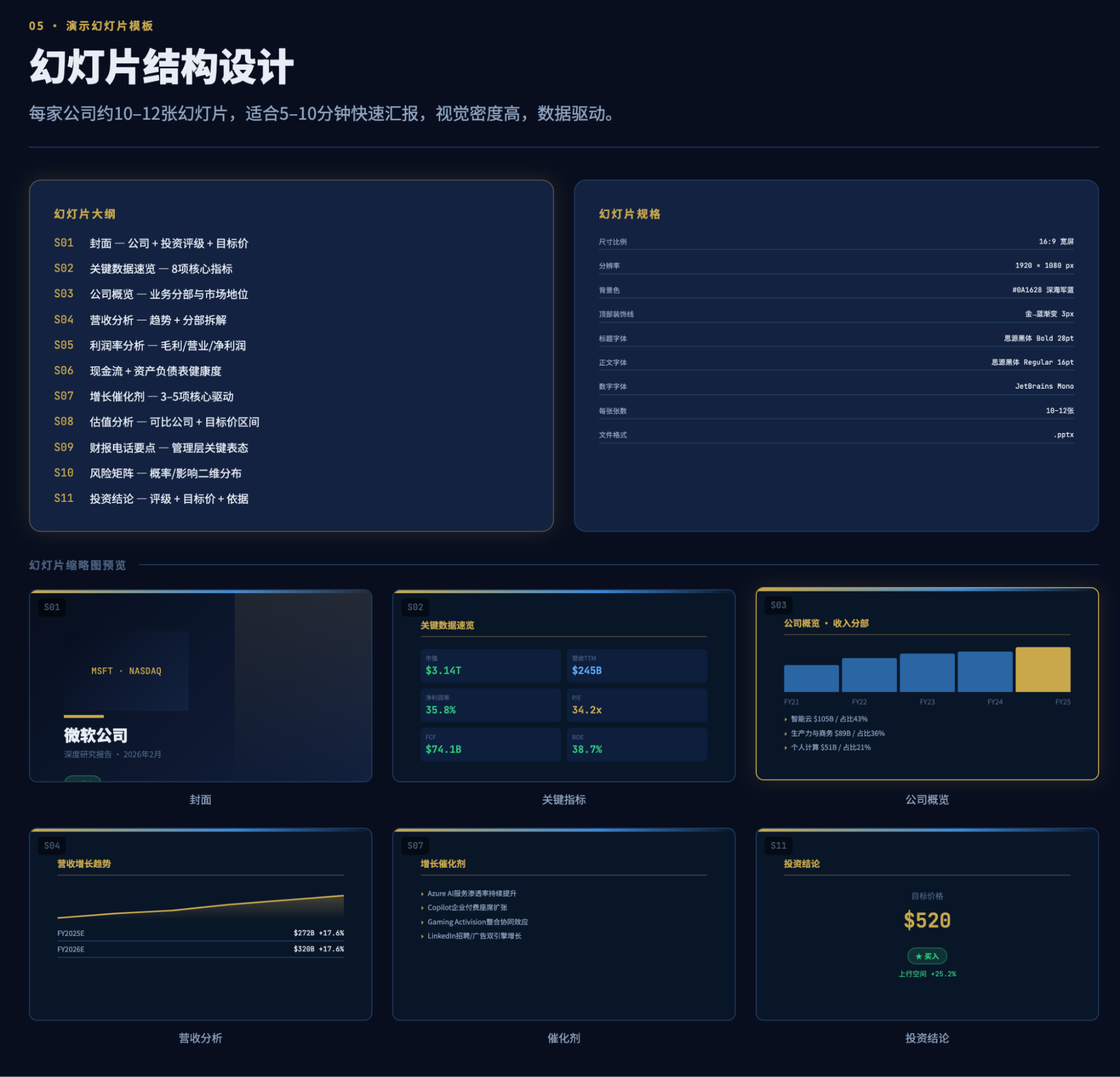
Yes, this was the output after half an hour of execution within the first five-hour quota, and it completely astonished me. Although my previous report visualizations and daily market broadcasts produced similar results, achieving this level of UX, especially from an AI, is remarkable.
I told myself that if the final batch of reports turned out okay, I would spare no praise and would even be willing to break my long silence to push for the ideal transformation.
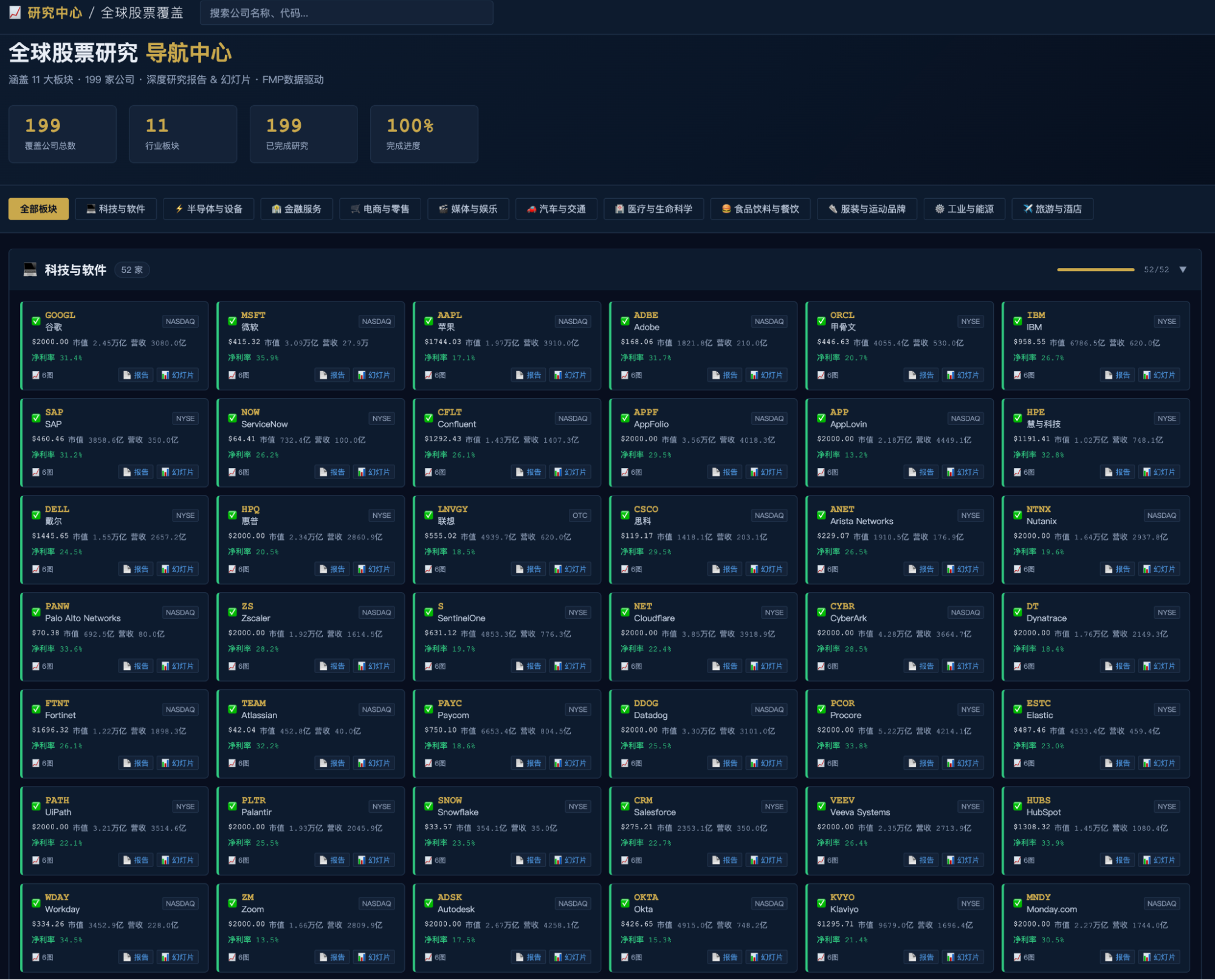
Then, my quota was reached. After waiting for four hours, I could finally get back to work. It was completed: the website was ready, and the reports and PPTs were generated. Not quite 240 companies, but 199.
The website's homepage was also very pleasing.
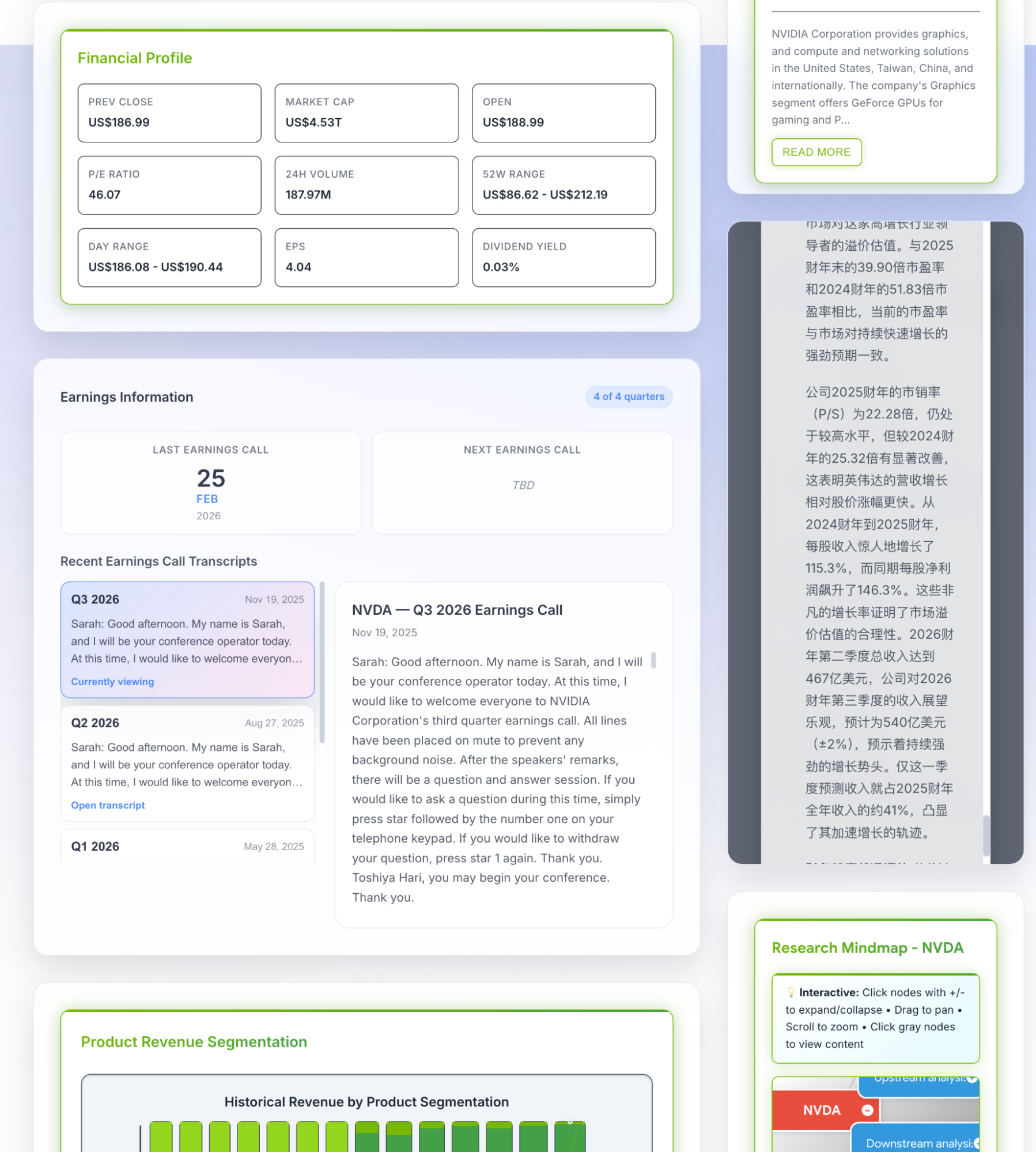
My attention was strangely drawn to the small print for the reports and slides first. They could be downloaded and browsed. For example, NV looked like this:
A page from the report:
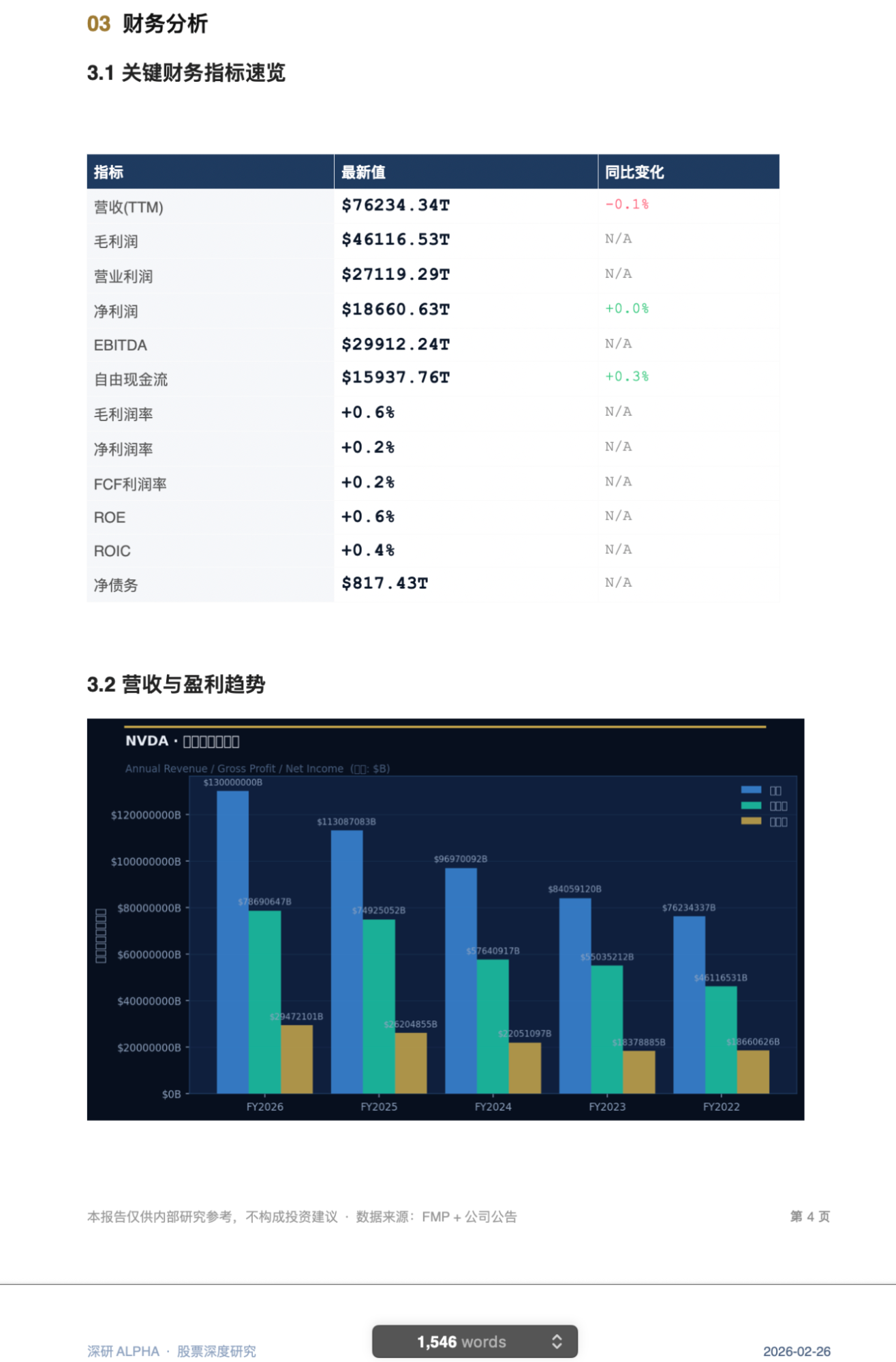
PPT preview:
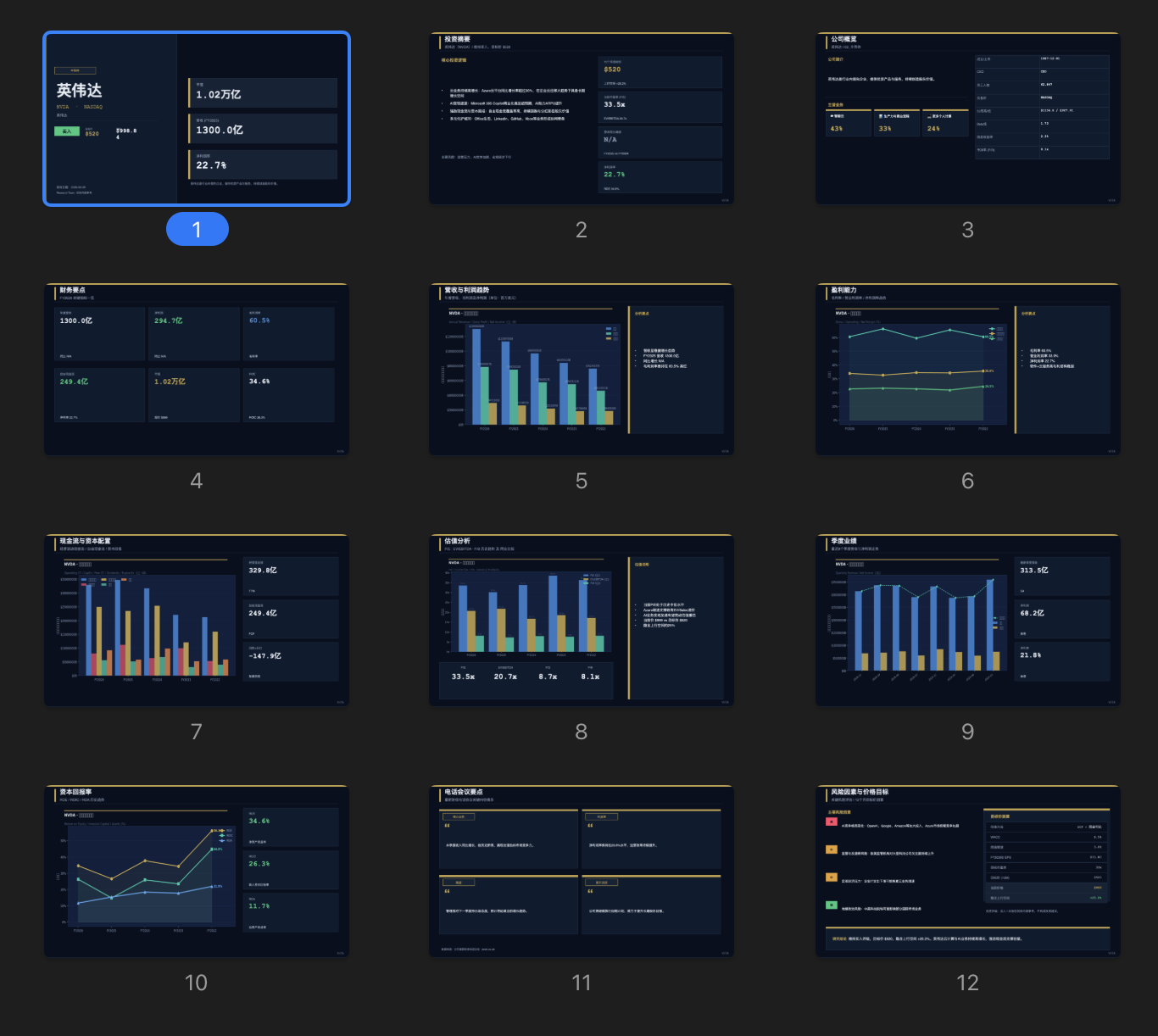
Everything seemed fine, very fine.
Unfortunately, I discovered that all the numbers were wrong. Of course, I didn't expect the text part to be correct either (since it was generated by code, not by model analysis, which I'll discuss later).
Then, I returned to the website's homepage and found that every number was incorrect. Cowork's self-diagnosis was accurate, and I found the reason that VMs might be blocked by the FMP website to be very plausible.

So, I ended up doing some work for Cowork, running its code for it, but the data was still completely wrong.
"As long as I spend a little time adjusting, the results will be correct," I consoled myself, and indeed, that's what I thought. Getting everything right in an hour would be truly miraculous.
However, my tinkering nature kicked in: since I've always believed Cowork is specially optimized and suitable for work assistance, could I possibly integrate the skills I used into Gemini's Antigravity and optimize the prompts to make Antigravity play the role of "Cowork"?
The migration process was simple: copy some skills over and start. In fact, the basic problem-solving framework and approach of Antigravity, or Gemini, were similar to Claude's. The time taken was also less than an hour. Here are the results:
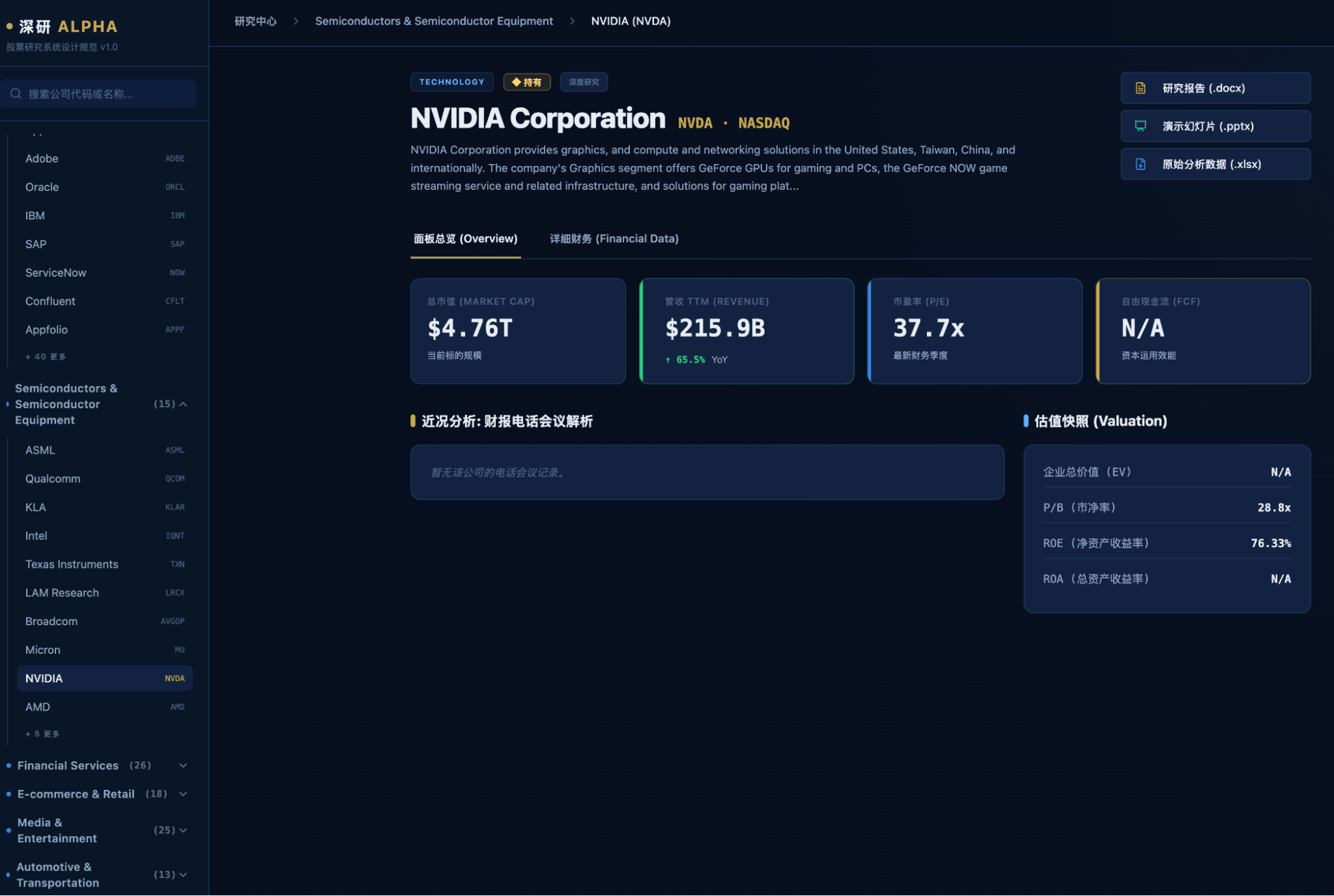
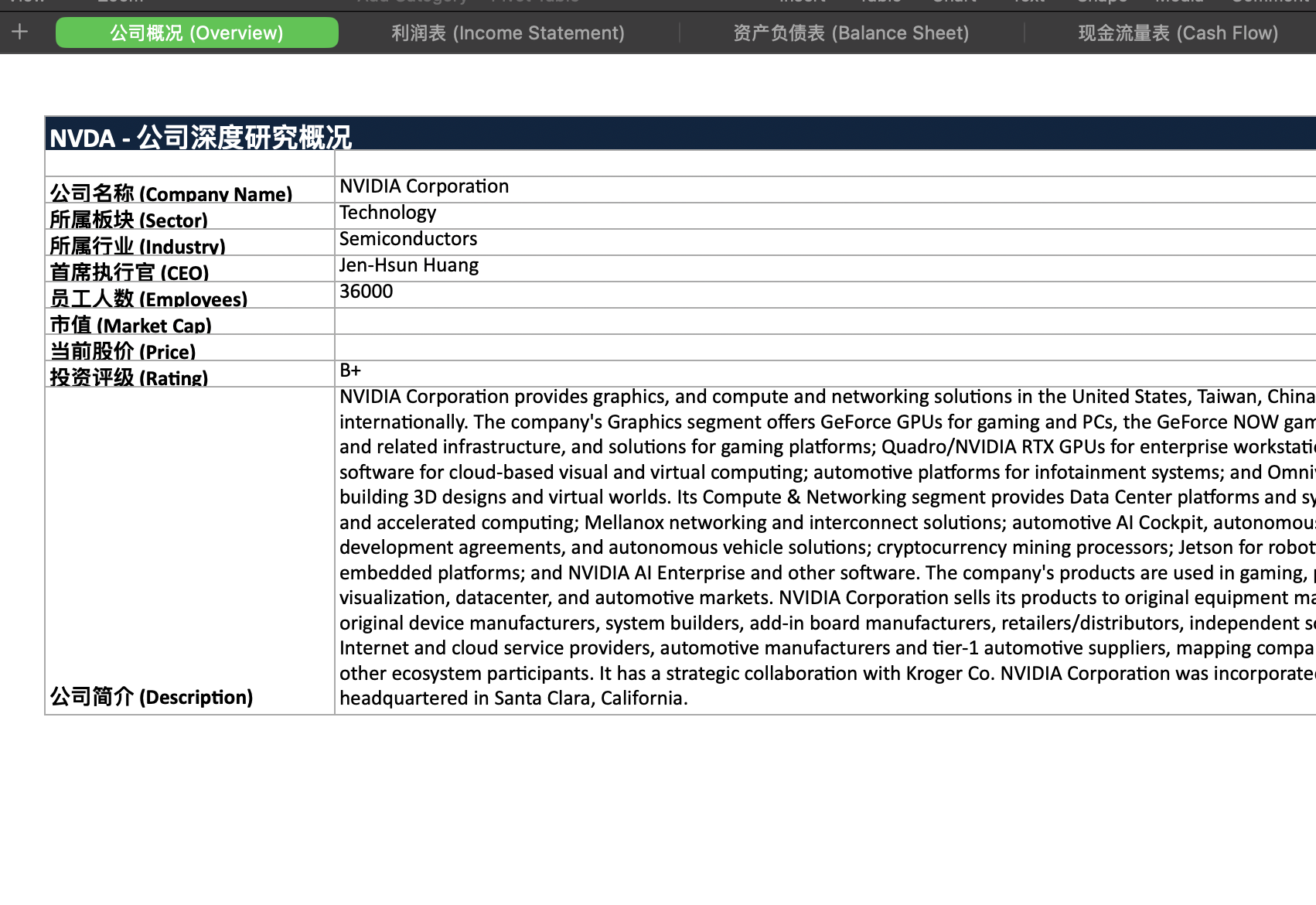
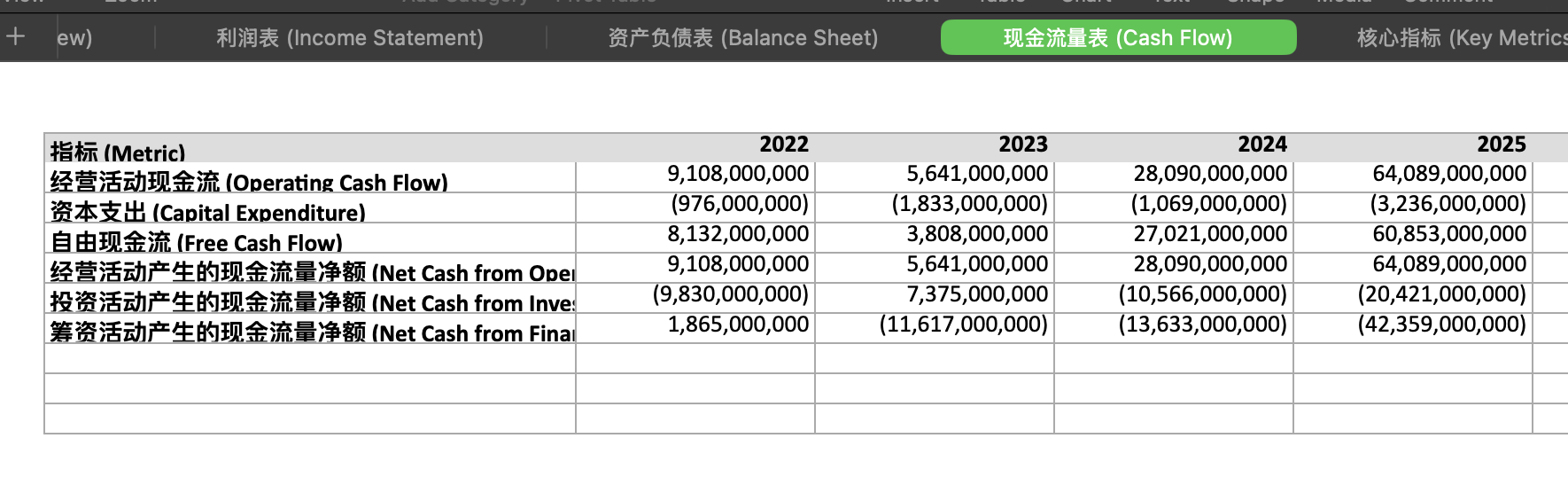

Here are two more screenshots of the generated Excel data.
Websites are subjective, and the data is correct, but the report and PPT content are a bit too brief.
However, this isn't really a model issue. After all, like Claude Cowork, it uses Python scripts to generate Excel, DOCX, and PPTX. If the user doesn't require it, it will write as little as possible, which has become a persistent issue with Gemini.
Cowork's output is more complete and visually appealing, but the core data is incorrect. Gemini is lazy, but its core data is mostly accurate. Which one to choose?
I'll choose both.
In theory, this task should involve calling the model once for each company processed. I experimented with this when Gemini CLI first came out, allowing the CLI to loop. It's crucial to carefully manage the number of model calls within an iteration due to daily quota limits. It was during that period (last summer) that I consumed over 500 million tokens daily.
However, later on, both Gemini CLI and Antigravity found it difficult to handle tasks involving prolonged, repetitive model calls. The ongoing translation and rewriting tasks for all my public accounts are currently implemented by calling the Gemini API again. It's hard to get much more out of Google now; this is the harsh reality of computational resource constraints.
It seems Cowork has learned this lesson too. The 'Open' in OpenClaw is rapidly gaining value, but API costs will also skyrocket.
Finally, two points.
First, to put it simply: I was in a state of anxiety for a while, especially as Agents became more powerful and user-friendly. My mood was probably similar to that of software companies that were constantly being hammered recently (they seem a bit better these days). I knew where my core competency lay, but I still doubted and felt anxious, as the rapid shrinking of comparative advantage is a fact. Now, I'm no longer anxious for a simple reason: overthinking is useless, so I might as well do what I enjoy.
Second, I might finally understand the real reason why people have different perceptions of Gemini, Claude, and Codex: thanks to 'skill,' I could meticulously examine every detail of the skills provided by Claude's official documentation. It's incredibly detailed and complete – yes, it's the astonishing UX design planning I mentioned earlier.
In fact, ChatGPT series products have always had similar characteristics, but we can't draw firm conclusions without seeing more details. Such detailed specifications likely stem from the Agent design in Claude Code, so why wouldn't Claude's programming capabilities be strong?
However, however, however, the data it retrieves when writing code is incorrect (I haven't looked at the code yet to find the reason for the error), while Gemini's is correct from start to finish. This difference is undoubtedly due to differences in the underlying model's capabilities. Or rather, capability isn't 'intelligence' but 'knowledge,' or simply the size of the training data. A recent observation, which may require time to verify: 'Antigravity' can write very long but very 'smart' shell commands (using pipes, wildcards, sed in a 'fancy' way, surpassing my knowledge of all Linux commands and parameters from over twenty years ago, and my preference for using shell+perl to implement functionality instead of C++ code – a quick self-praise). In contrast, I recall both Codex and Claude tending to write shorter commands.
However, the teams at DeepMind and Google Labs, despite being much more competitive than before, still lag far behind companies like 'A' and 'O'.
I've always disliked writing documentation, let alone practices as minutely detailed as 'Skill.' Therefore, I believe my 'OpenResearch' is more elegant than 'Skill,' but I admit that the 'extreme workhorse' spirit of 'Skill' is easily standardized and scaled. I admire it and will adopt it.
The people at Google and DeepMind, especially the older ones, also seem like 'lazy people.' Of course, they are certainly better than me, as large companies have more internal standards.
Therefore, Gemini's Agents will be more like Duan Yu's Six Meridians Divine Sword.
Yes, that's likely the reason. But I like it this way. It's good to be human, so why be a workhorse?