春节期间,我有一个很具体的认知改变:
在AI应用落地上,我的观点不具备任何代表性,这个问题我其实已经承认了一年多了,但是始终找不到校准的方法,OpenClaw给了我很好的契机和启发;
正是沿着这个启发,一段时间以来,我一直在做一些新的尝试,今天是skill。
其实从内心里我从来没重视过MCP和Skill。在我眼里,MCP就是API的升级,当然,我只信任官方(比如figma这种)的MCP,Skill就更像提示词优化了,实际上,即使这两天Anthropic推出了金融分析的Skill(它叫做plugin,其实就是skill),我还是认为产出的结果跟我去年的OpenResearch差距依然很大,我的OpenResearch也仅仅靠两三个文件,其实原理是一模一样的。
但是,随着Cowork、Antigravity、Codex都加入了MCP和Skill的支持,随着越来越多的三方应用推出了官方MCP/Skill,我渐渐体会到了Skill的优势:更标准化、更简洁,虽然我还是认为我当初OpenResearch的设计还是优美的多。
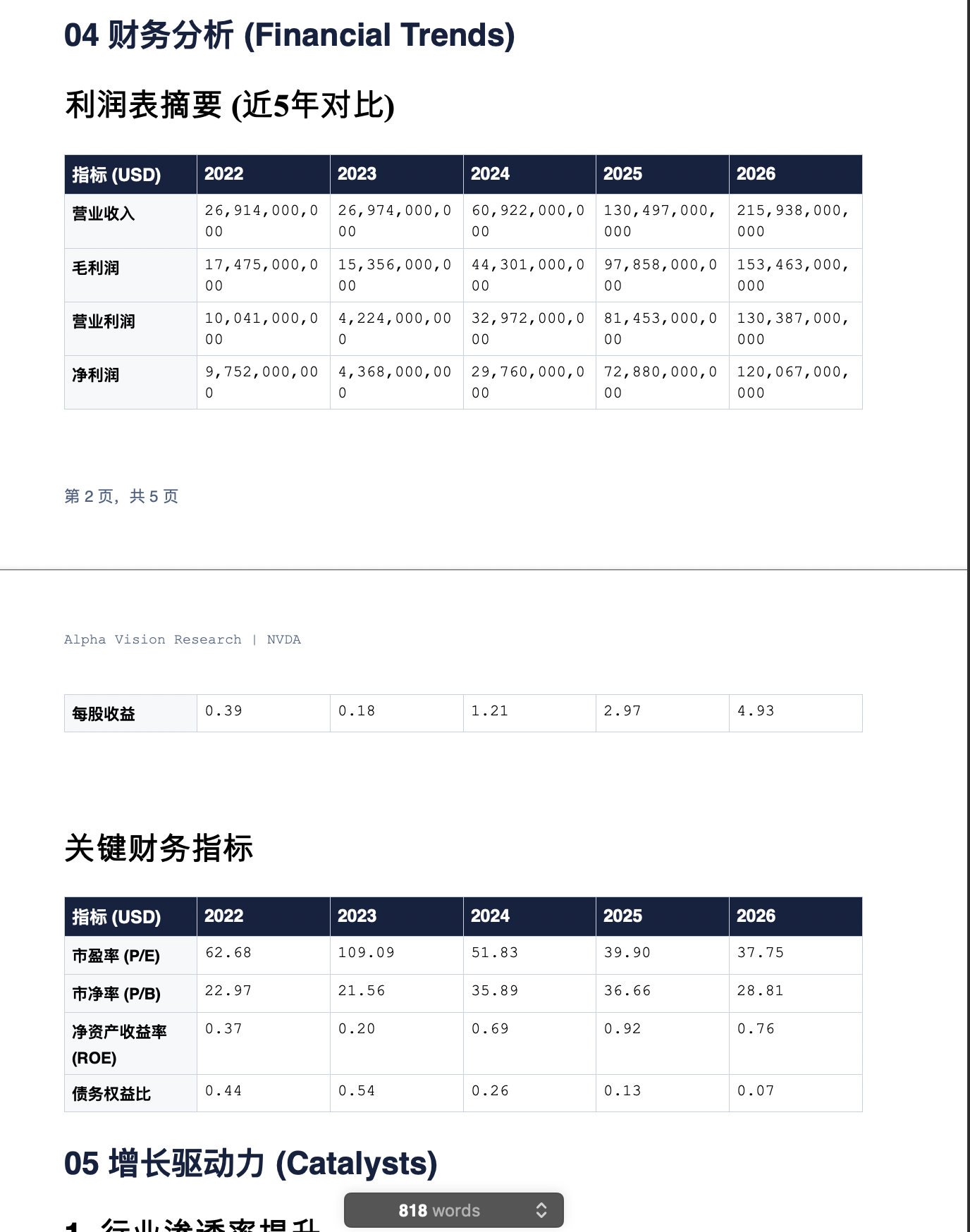
言归正传,今天傍晚,我突发奇想,想看一看如果让Cowork工作,可以多大程度上复刻我自己用的美股网站。
当然,主要长下面的样子,有点花里胡哨,一段时间后懒得去优化和统一界面了,反正也就是自己用。
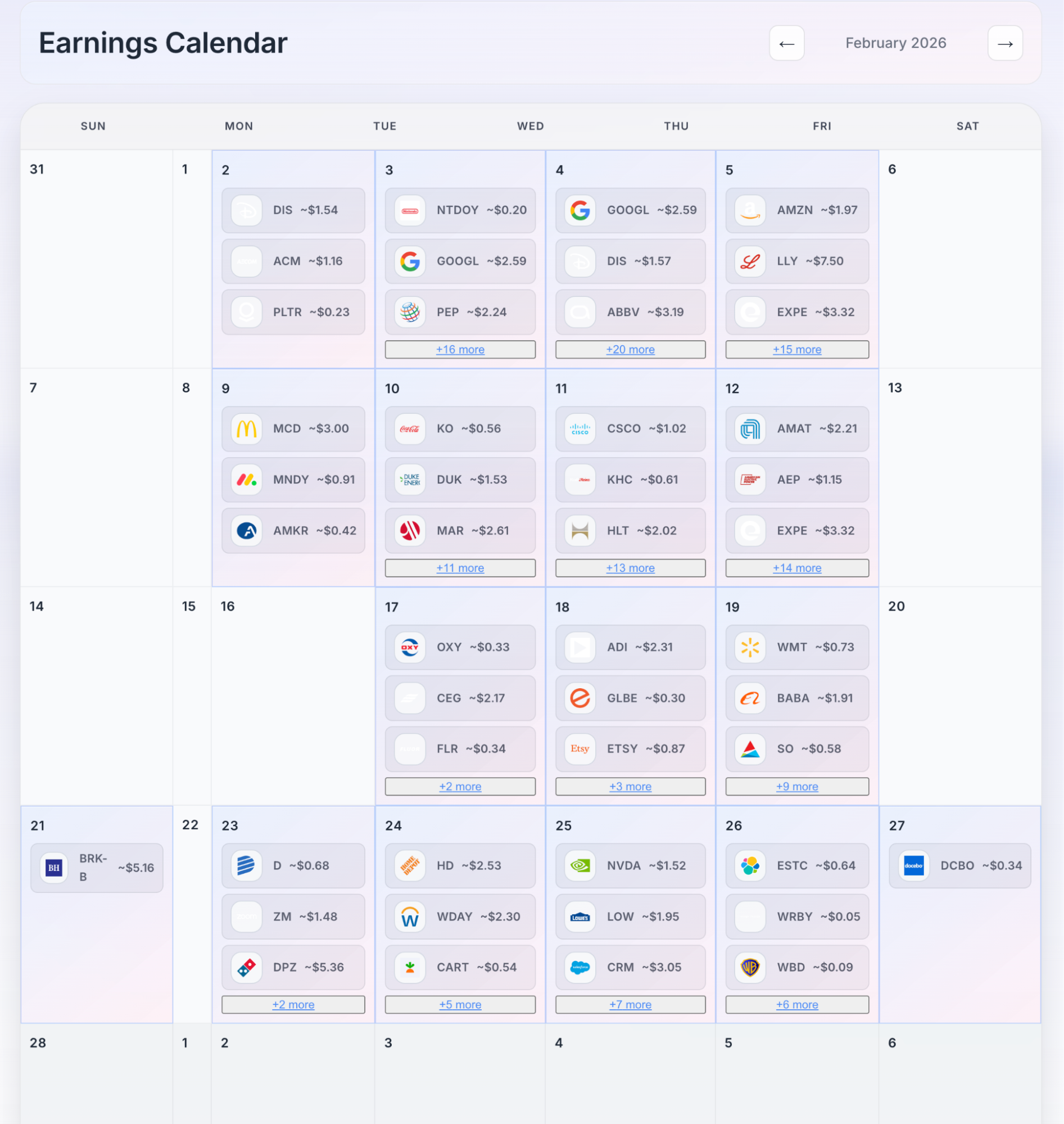
没有指望Cowork可以达到这个程度,但是我想看得就是,给它FMP APIKey和Watchlist,它能够在用量的额度内达到什么程度。
我引入了金融分析插件(skill),docx和pptx的skill,前端设计skill。分布执行:先是设计,然后是调用数据,第三步是生成报告和ppt,第四不是汇总到一个网站。
我消耗了pro订阅两个五小时时间段的用量额度。
前端的设计ux让我无比惊艳。
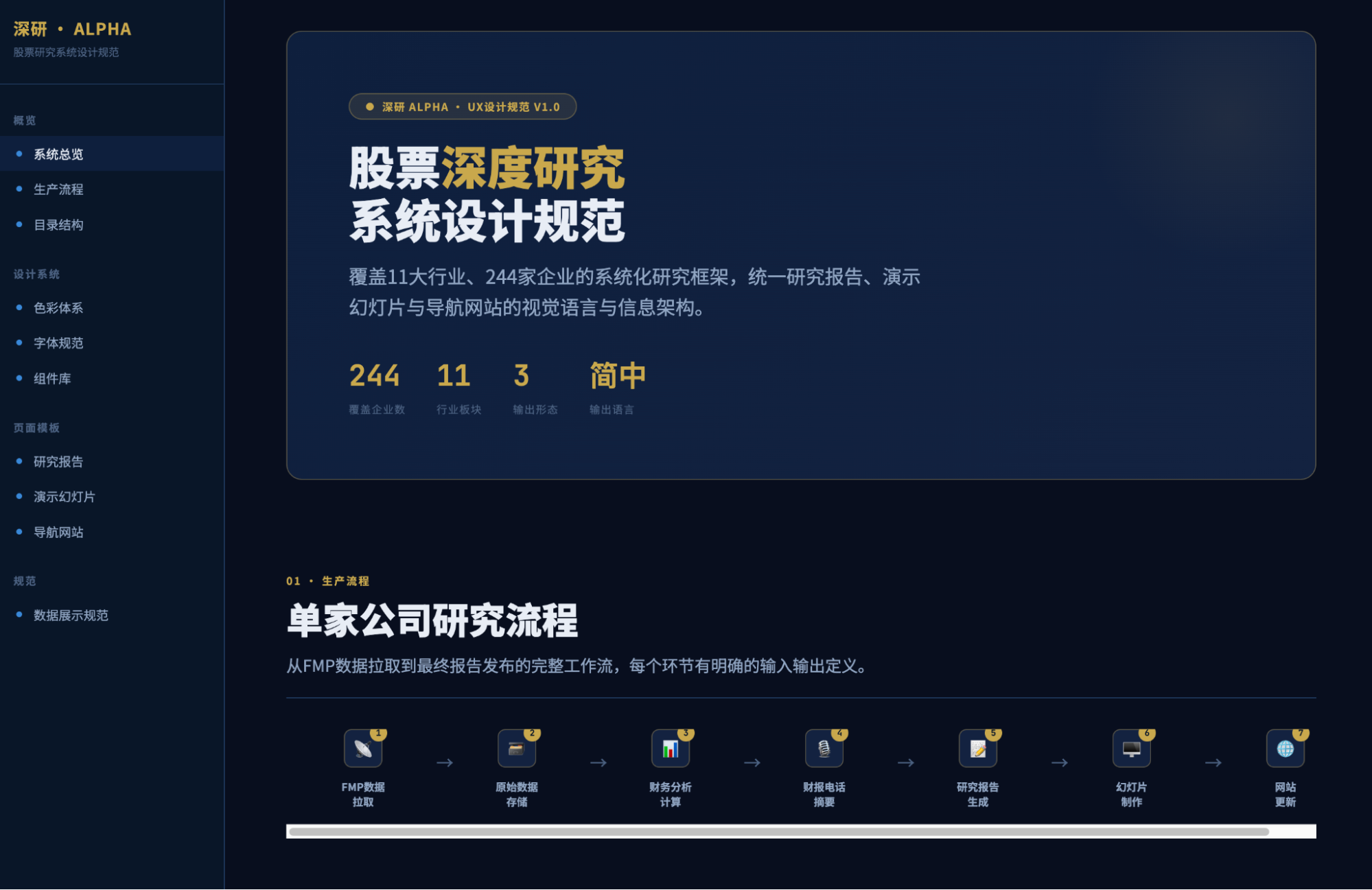
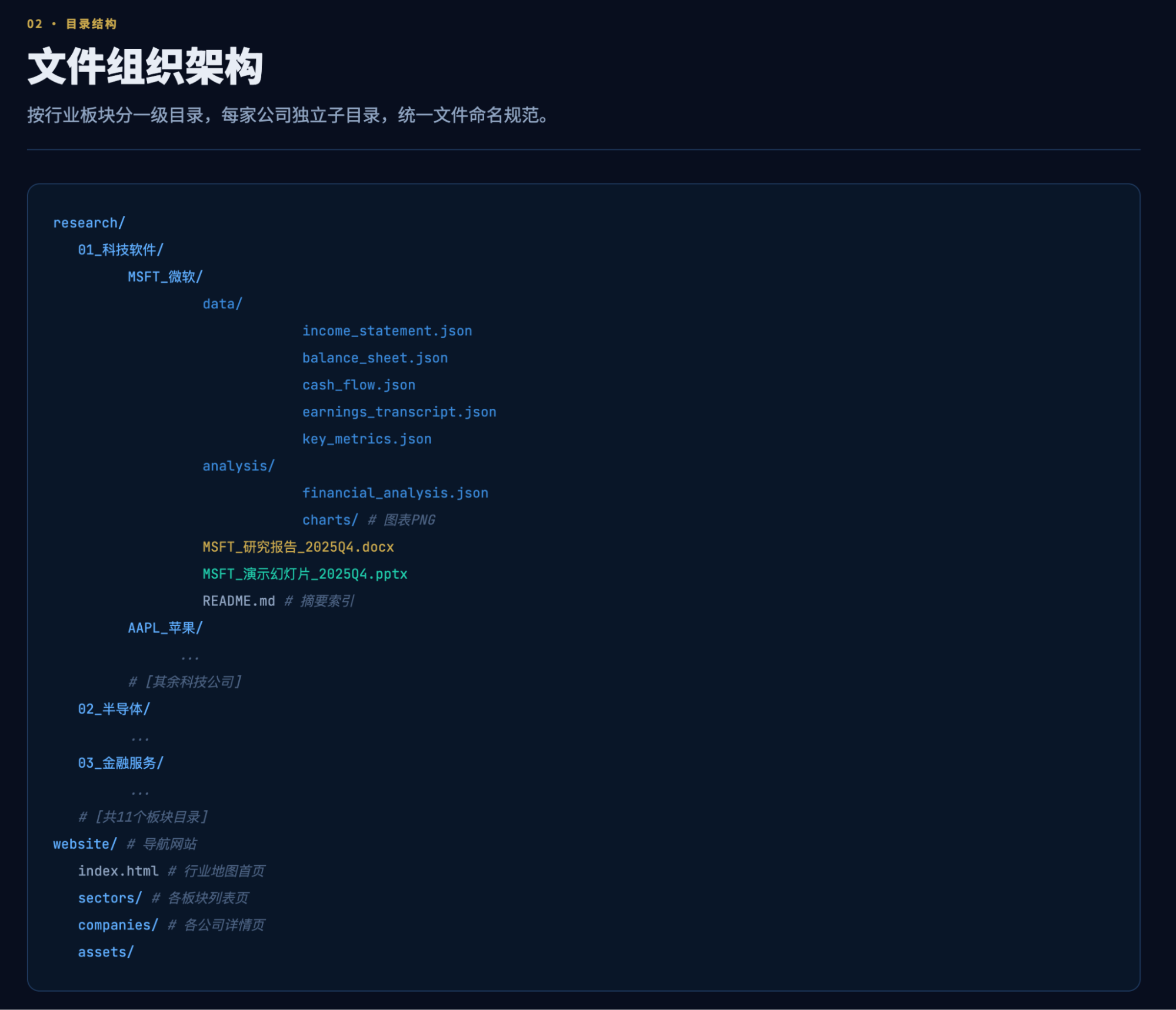
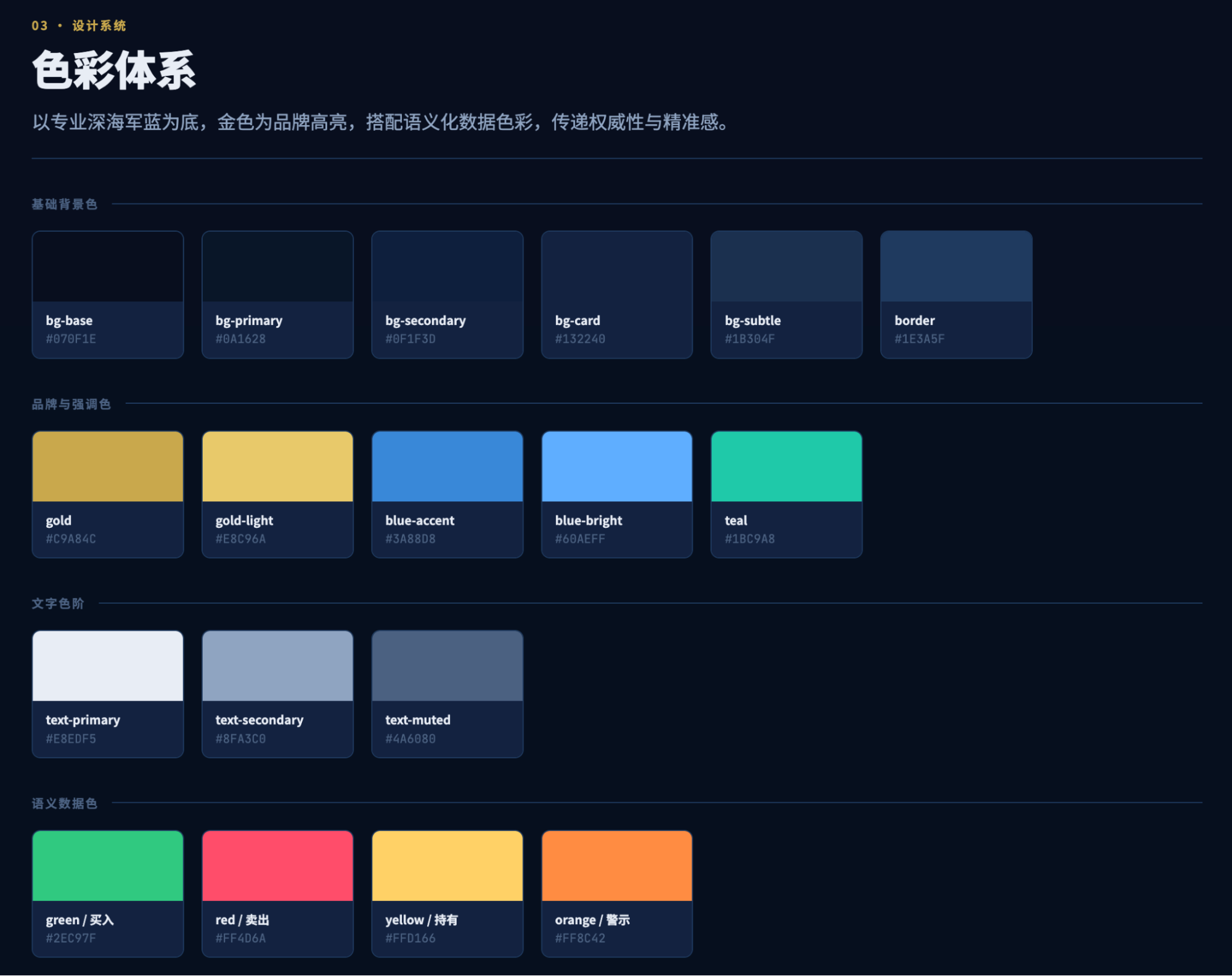
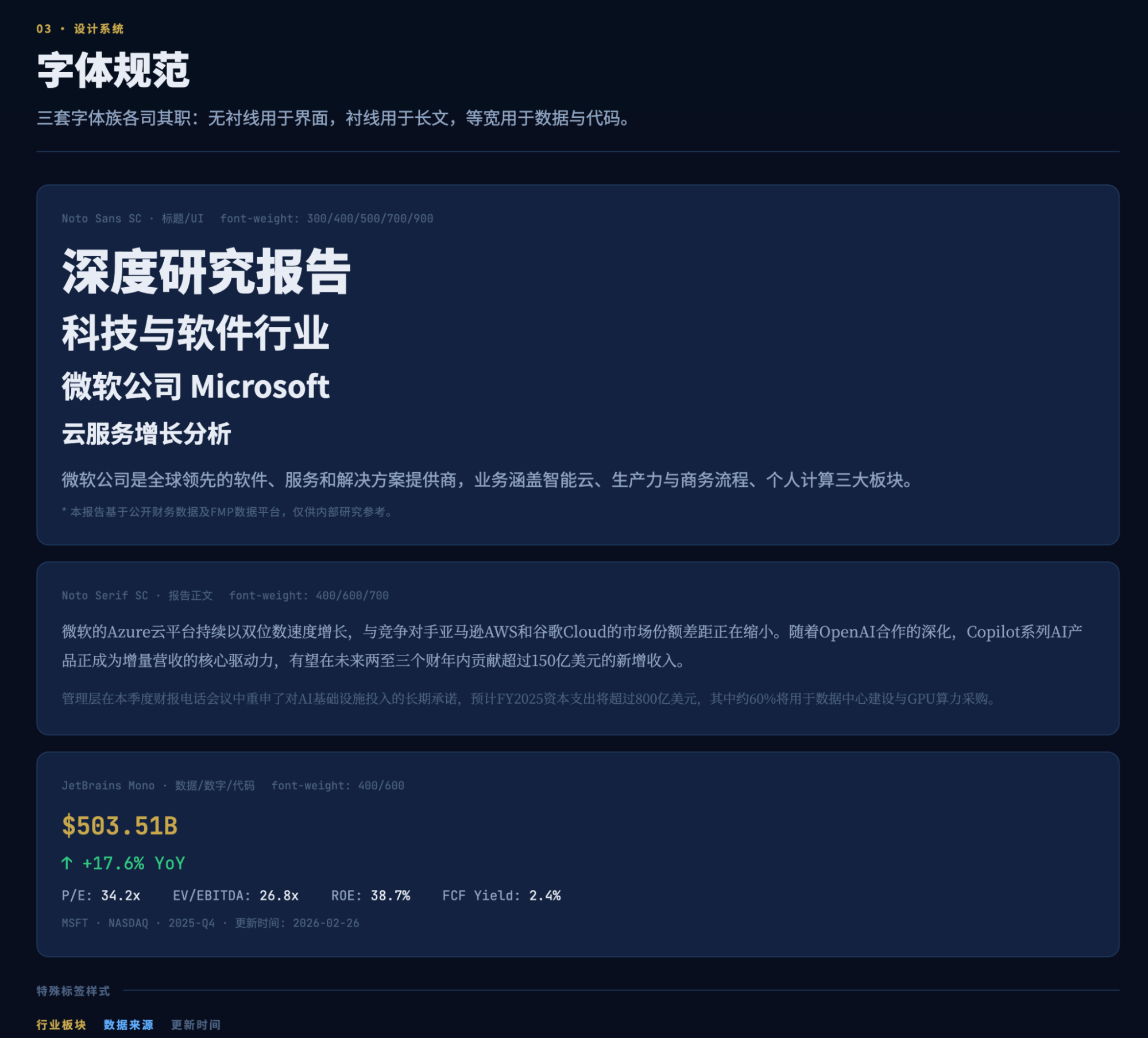
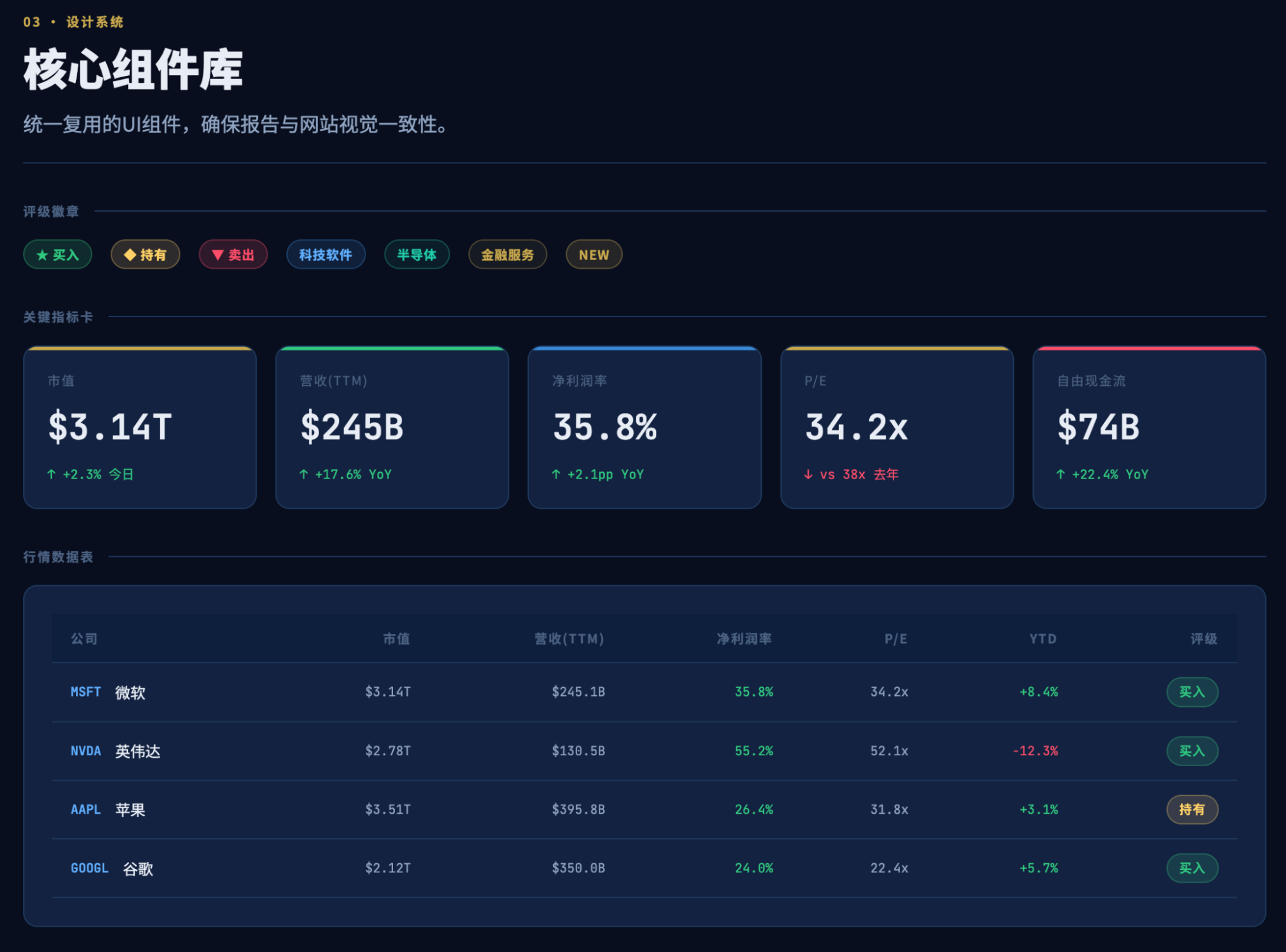

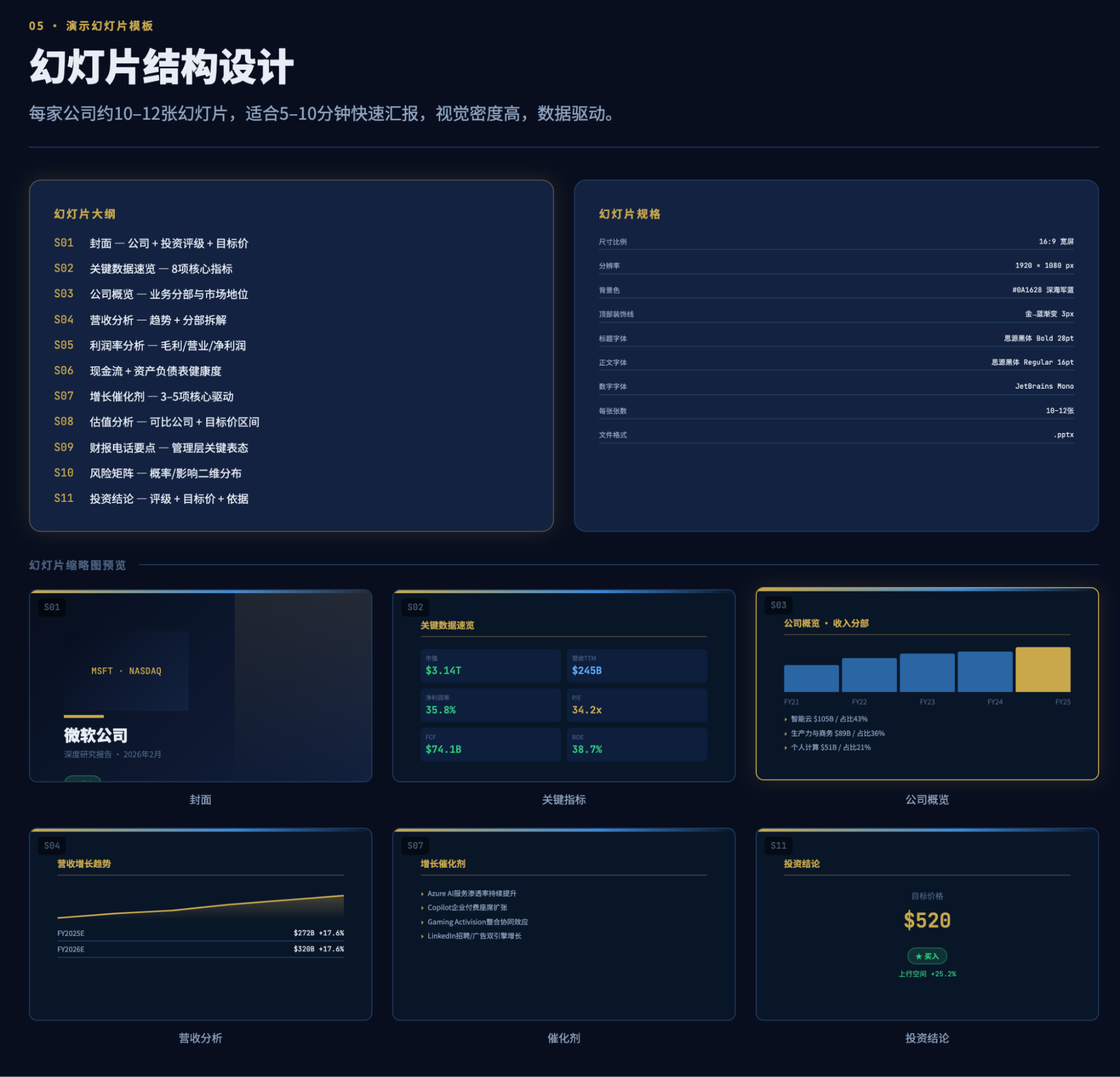
是的,这是在第一个5小时时间额度里,执行半小时后的出品结果,完全让我惊叹了。虽然我以前的报告可视化和每日市场播报的生成结果跟这个相近,但是能把ux做到这种程度,这毕竟是AI啊。
我跟自己说,如果最终批量报告出来的结果ok,我就不吝一切赞扬的词句,我还愿意为了这个结果豁出去,打破长时间的沉默状态,去推动理想中的转型。
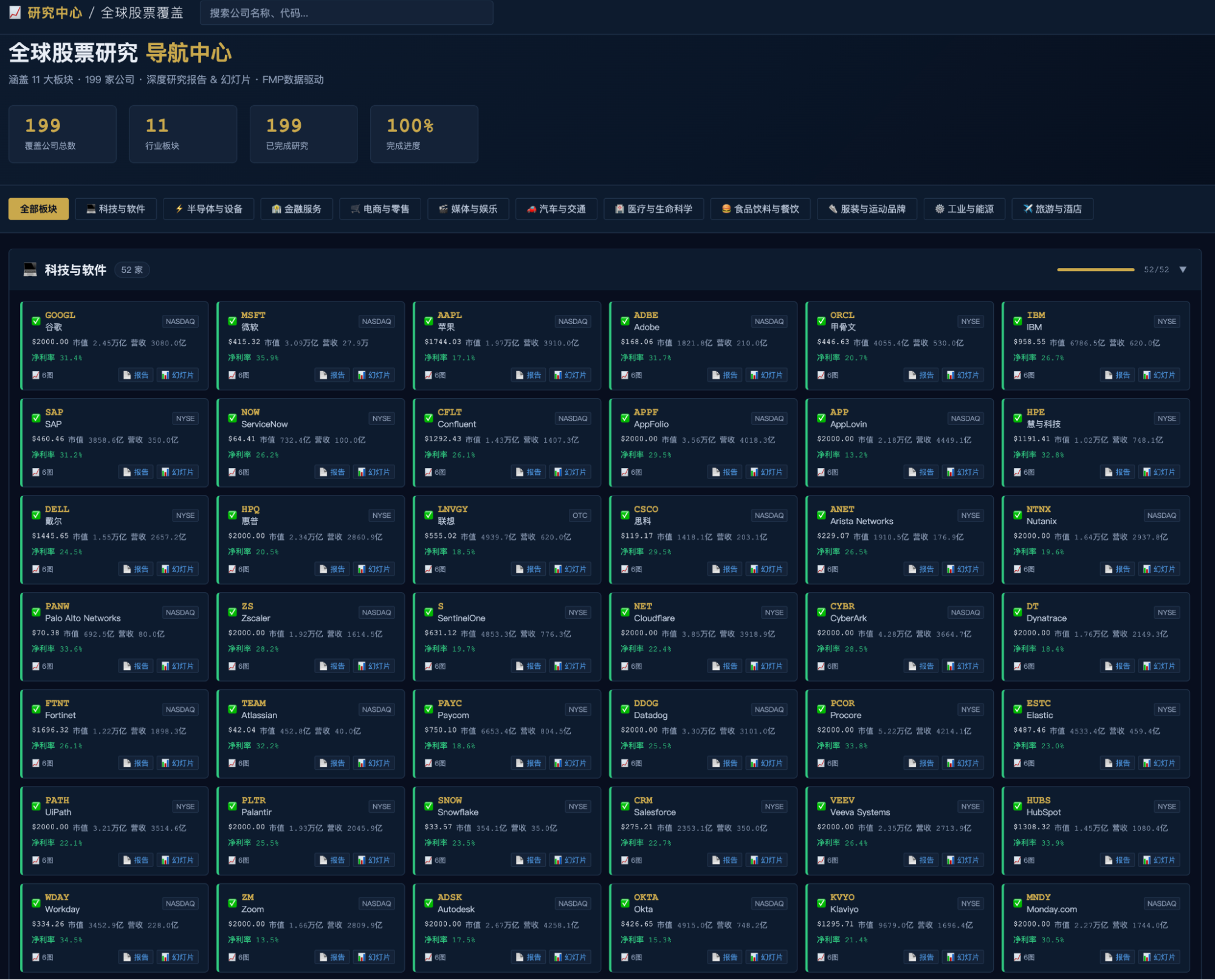
然后额度到了,在四个小时的等待后,终于可以继续干活。居然完成了,网站好了,报告、PPT都生成了,没有240家那么多,199家。
网站首页也让人很喜欢。
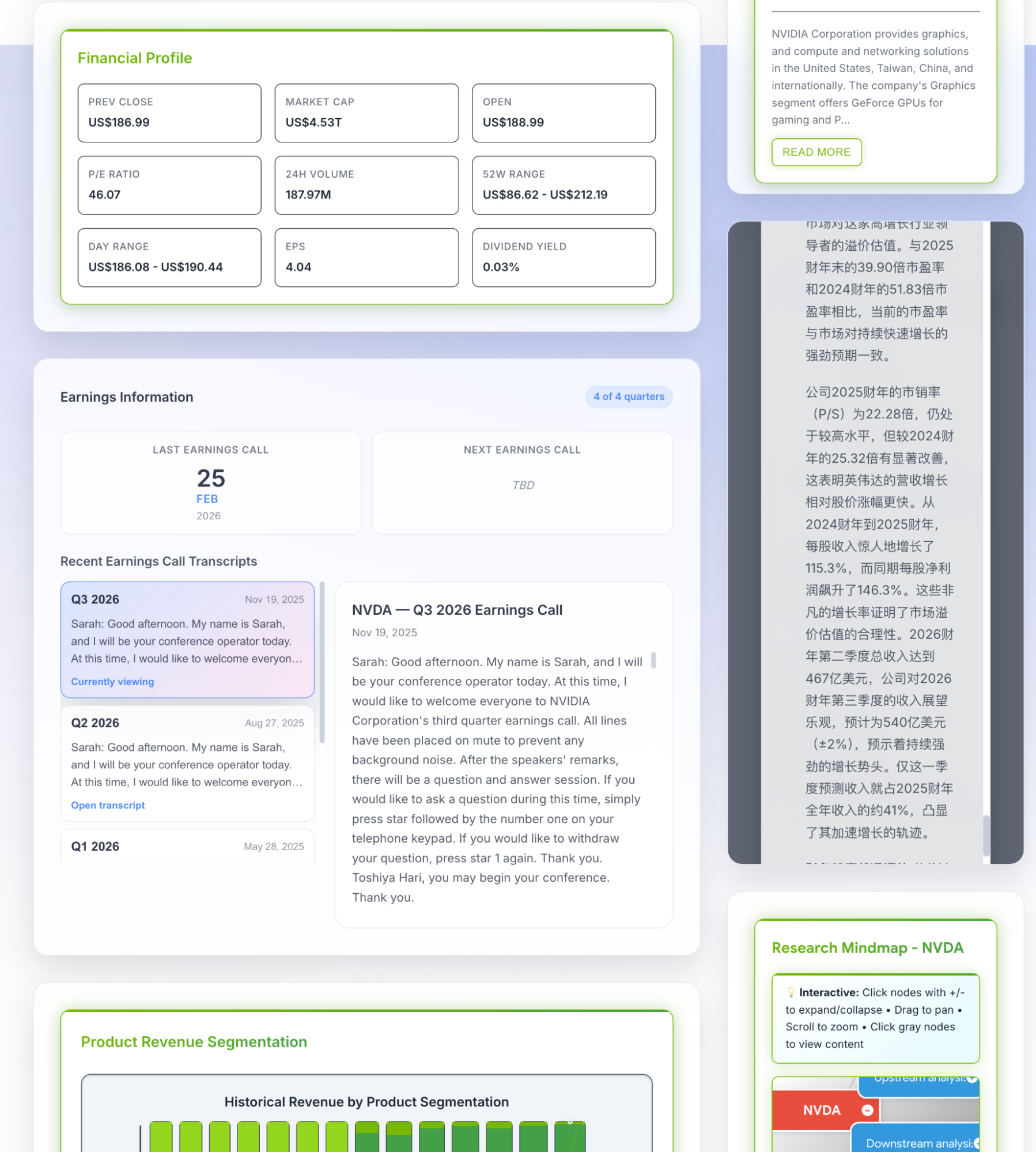
我的注意点很奇怪,居然是先去点报告和幻灯片的小字,可以下载,浏览。比如NV的长下面这个样子。
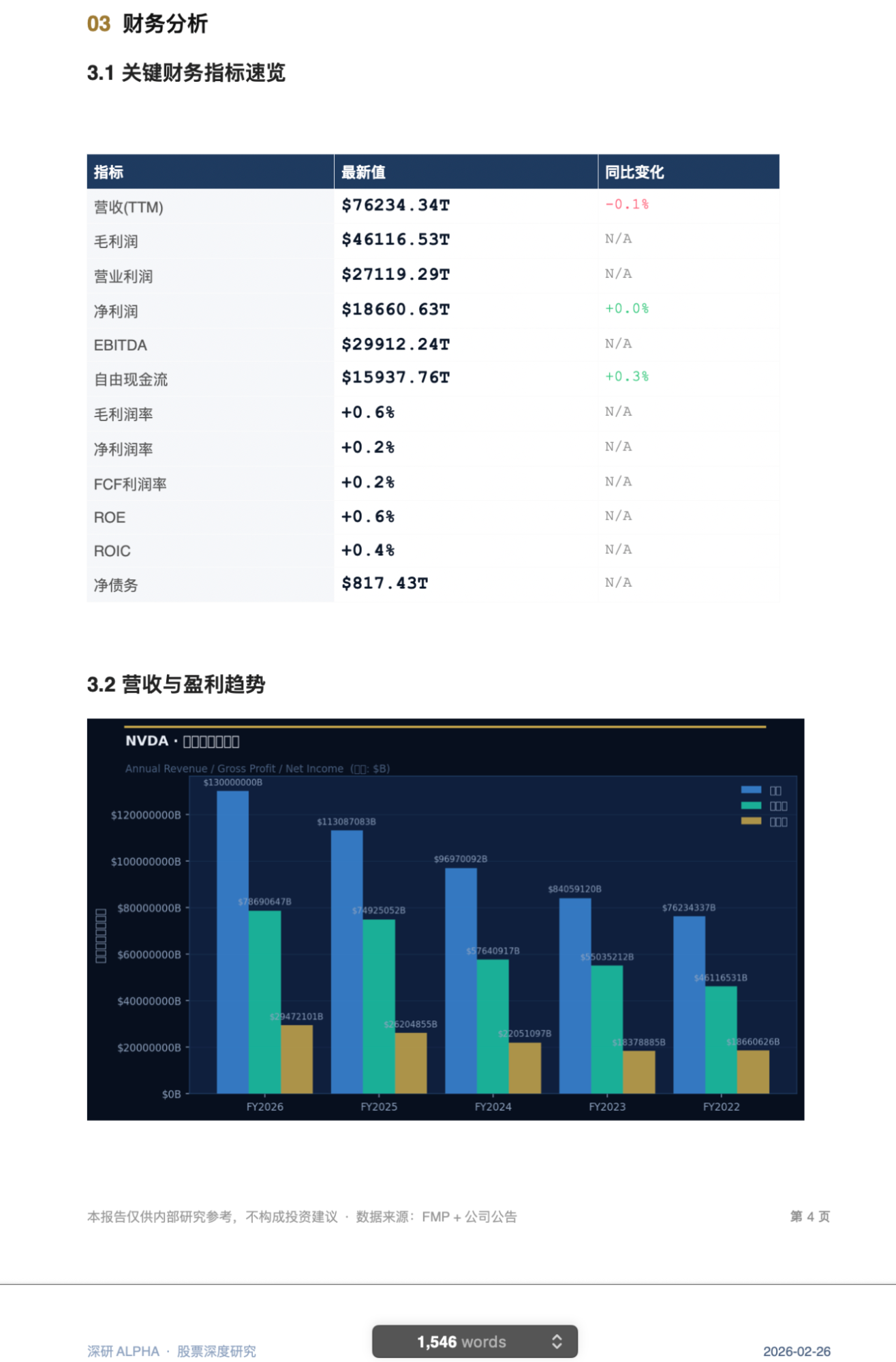
报告中的一页:
PPT预览图
一切似乎都很好,很好。
可惜,我发现数字全是错的,当然文字部分我并没有指望它正确(毕竟是生成代码生成的,而不是调用模型分析的,这个放到最后再去讨论)。
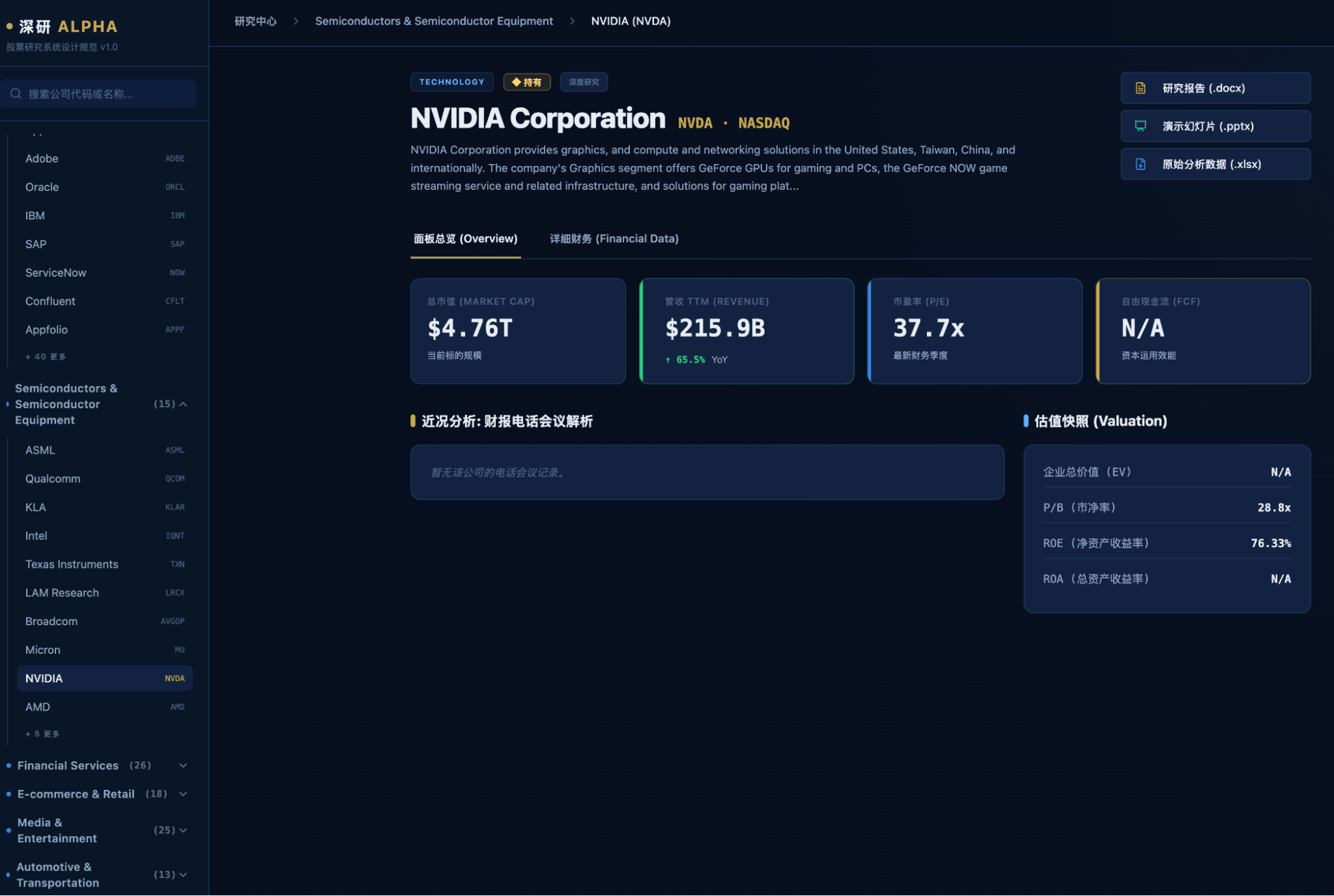
然后,我才回到网站首页,发现每个数字全是错的。Cowork自己的原因定位很准确,我觉得VM会被FMP网站屏蔽这个原因也非常合理。

于是,我帮助Cowork打了一次工,帮它运行了代码,但是,数据依然全是错的。
“只要我花点时间调整,结果都会对的”,我是这么安慰自己的,当然,我也是这么想的。一个小时,全部搞对,才是真的逆天呢。
可是,我爱折腾的本性还在:既然我一直认为Cowork是特别优化过的,适合用来辅助工作的,那么,我有没有可能把用到的skill加入到Gemini的反重力中,然后优化一下提示词,让反重力也扮演一次“Cowork”?
移植的过程很简单,拷一些skill过去,然后开干,其实,基本的解决框架和思路,反重力或者说Gemini的表现,跟Claude差不多。大概用时也差不多是一小时不到,贴结果:
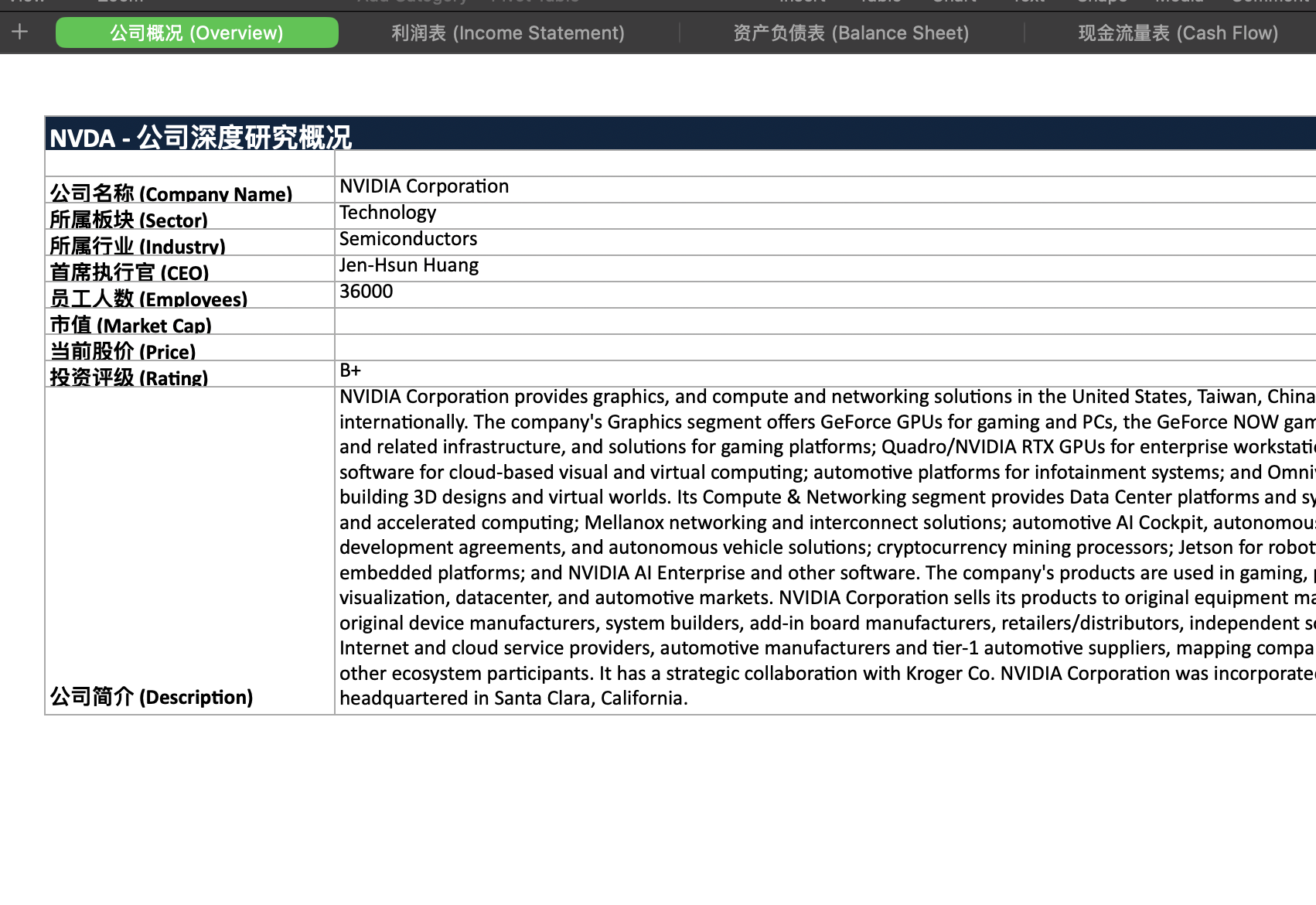
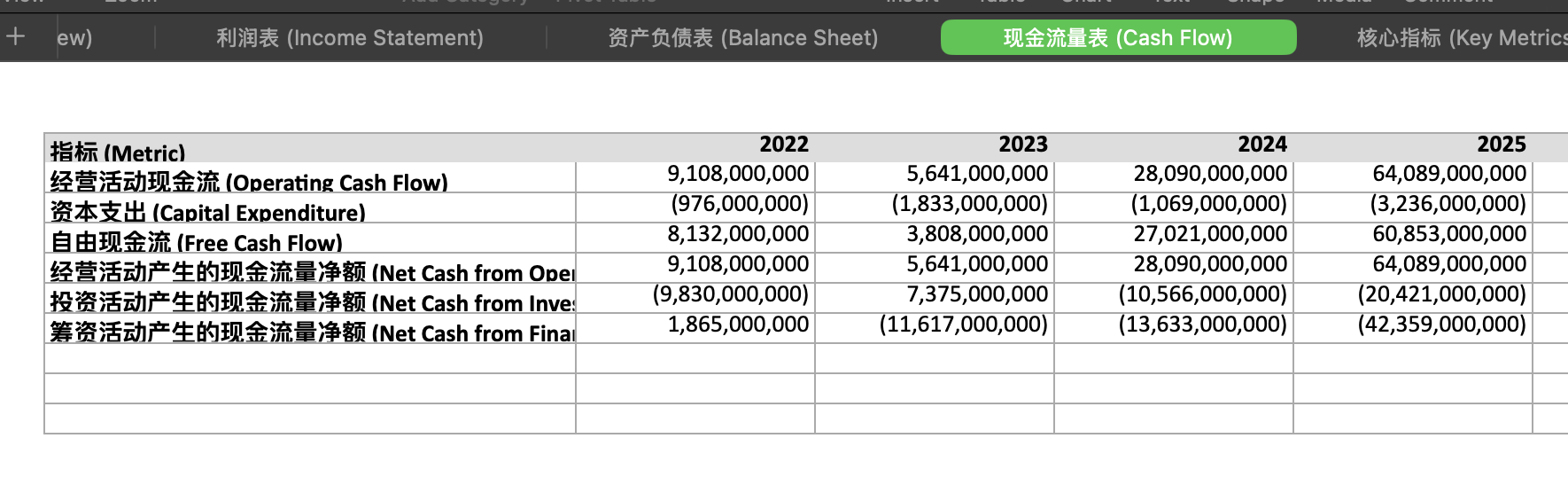

多贴两张输出的excel的数据截图。
网站见仁见智,数据都是对的,但是报告和ppt内容有点太简略了。
不过,这不太算是模型的问题,毕竟它和Claude Cowork一样,都是通过python脚本来生成excel,docx和pptx,如果用户不要求,就能少写就少写一点已经是Gemini的“顽疾”。
Cowork生成的更完整,更漂亮,但是最核心的数据部分是错的,Gemini很偷懒,但是核心的部分没什么错误,选择哪个?
我都选。
理论上,这种任务应该是每处理一家公司就调用一次模型,都用模型来处理,这种尝试我在Gemini CLI刚出来的时候就做了,那时候是可以让CLI进行loop的,要特别精打细算一个iteration里模型调用的次数,因为每天是有额度限制的,也正是在那段时间(去年夏天),我每天消耗5亿以上的token。
但是后来,无论是Gemini CLI还是Antigravtity都很难接受长时间的模型反复调用的任务了,如今我后台正在跑着的所有公众号文章的翻译和改写任务也是靠再调用Gemini API实现的。很难再从Google身上薅太多羊毛,就是算力紧张下的残酷现实。
看起来,Cowork也学会了。OpenClaw的Open两字的含金量快速提高,不过,API费用也会飞涨的。
最后,两点。
第一点,简单一点,我曾经有一段时间一直在焦虑之中,特别是Agent越来越强越拉越傻瓜化的时候,我的心情估计跟前段时间一直被爆锤的软件公司一样(这两天看起来好点了),内心其实知道自己的核心竞争力在哪里,但就是也会怀疑和焦虑,毕竟比较优势快速缩小也是事实。如今,对我而言,不焦虑的原因很简单,想太多也没用,不如索性爱干什么干什么;
第二点,我可能终于知道了为什么大家对于Gemini、Claude和Codex体感不同的真正原因了:多亏了skill,我可以非常认真的看claude官方给出的skill的每一个细节,写的太细、太完整了,对的,就是我上面说的让我震惊的ux设计规划。
其实ChatGPT系列产品也一直有类似的特点,只不过目前看不到更多细节,不太好下定论,如此之细的规范,估计也是承袭自Claude Code中Agent的设计,所以,Claude编程能力怎么会不强?
但是,但是,但是,它写代码获取的数据是错的(我还没去看代码,找出为什么错误的原因),而Gemini却从头到尾就是对的,,这种差异毫无疑问就是基础模型的能力差异,或者说,能力并非“智商”,而是“知识”,或者说就是训练数据的大小。一个最近的感觉,可能还需要时间去验证:反重力可以写出非常长但是非常“聪明”的shell命令(管道、通配符、sed,用的那个“花哨”,比二十多年前背下所有linux命令和参数的我,以及能用shell+perl实现功能,就坚决不用c++代码的我,有过之而无不及,赶快表扬一下自己),而印象中无论Codex还是Claude都会倾向于写的短一点。
但是无论Deepmind还是Google Labs的团队,尽管比起以前卷了太多太多了,但是相对于A家和O家,那还是差远了。
我一直不喜欢写文档,更别说类似于Skill这种细节bt到极致的做法了。所以,我就是认为我的OpenResearch写的比Skill漂亮,但是我承认Skill这种“极致牛马”的精神很容易标准化规模化,我很佩服,会拿来用。
Google和Deepmind的人,尤其是年纪大的那些,看起来也都是“懒人”,当然肯定比我好,毕竟大厂内部规范就是多。
所以,Gemini的Agent就会更像段誉的六脉神剑。
对的,应该就是这个原因了。但我就是喜欢这个啊,做人多好,为什么要做牛马?