新的一年,准备对自己放松一些“枷锁”:认认真真、简简单单地更新一下观点。
因为Excalidraw推出了官方的MCP,我在vercel上部署后,连接了Claude客户端,这让我可以重新回到两年前Excalidraw画图的状态。
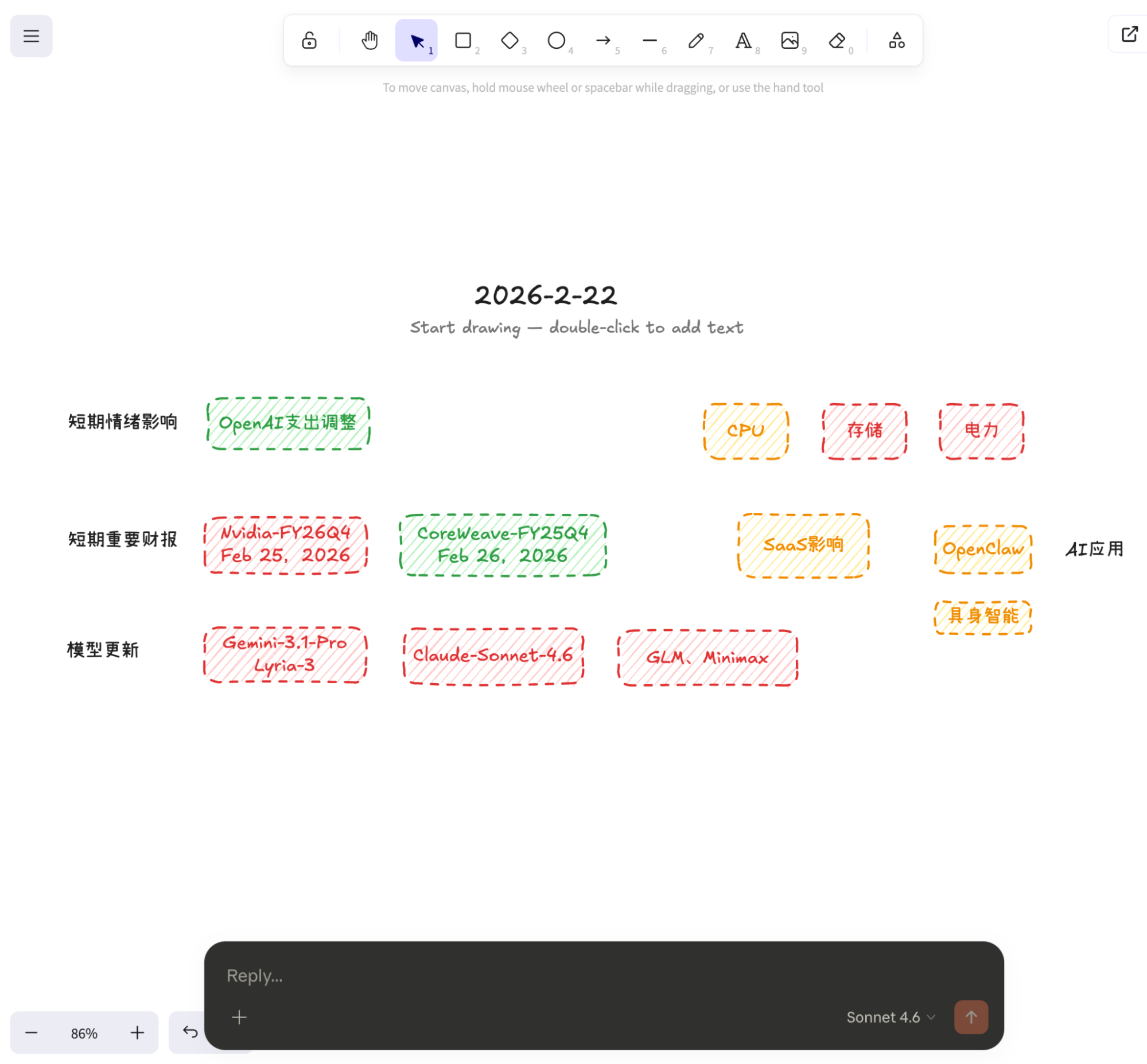
下面是我手画的,也代表希望讨论的主要内容。
而下图,是我让Claude-Sonnet-4.6根据上图内容进行自动更新和重新排版生成的(仅代表Claude的观点,不代表我的)。
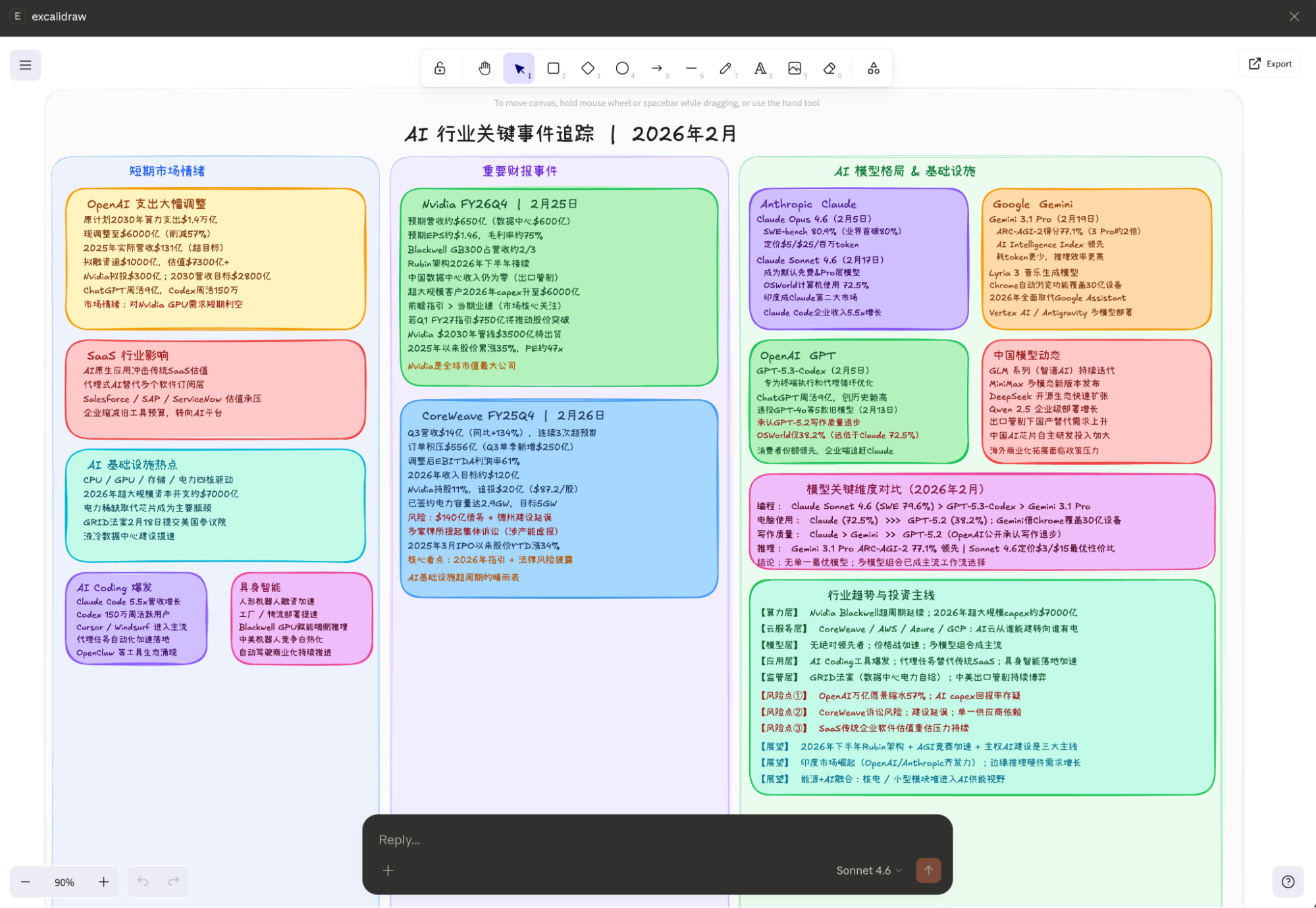
所以,第一个问题要讨论的是模型和对软件行业的影响,借Claude连接Excalidraw的实践。
一、SaaS、OpenClaw、AI应用等
对于上面这样丝滑的操作,依然有必要进行一些简单的解释:2025年初的时候,我通过Claude(coding)+Gemini(或者ChatGPT的研究)已经基本可以实现这样的结果,但是会花费我大约半天的时间,如今,配置MCP服务器大概需要十分钟,Claude“优化”我的手绘图耗时五分钟之内。
所以,这是不是一个巨大的进步,当然是:门槛大幅降低(意味着惠及的用户大幅增加)+ 自动化程度大幅提升。
但是:
这绝对不意味着对SaaS公司的无差别打击,Claude不会再造类似于Excalidraw这样的许多轮子,尽管使用了MCP和Skills,但是内容依然托管在Vercel或者Cloudflare这样的CDN上,我这里没有使用私域数据,如果用的话,还需要数据栈服务和安全服务,所以,如同算力对整个硬件链条的拉动作用一样,最终大家会发现在AI应用落地的过程中,也有非常重要的软件栈infra,虽然看到某一年某个季度夸张的收入增长,但是如果我们拉长时间看,例如三年五年,会发现规模增长更客观、稳定性更强、用户壁垒更深;
OpenClaw也爆了,在我的工作流里我暂时用不上这样的一站式框架,正如我当初推荐LangChain、Dify、n8n等,但是我并不使用一样,“套壳”的东西我都可以借助AI Coding自己做。所以,如果拉长时间维度看的话,这类应用并不值得花太多时间,这些最终都只是过客。
二、模型更新
Google方面,Gemini-3.1-Pro、音乐模型Lyria-3,Anthropic方面,Claude-4.6的Opus和Sonnet分别发布,OpenAI方面,GPT-Codex-5.3,国产模型,GLM、Minimax、QWen纷纷更新。
其实,Benchmark已经基本失去了参考意义,真实世界中的长时间任务执行的主客观评价变得更重要,但是这里有两个问题,一是“文无第一、武无第二”,Claude依旧是程序能力最强的模型,这意味着如果专注于AI Coding,那么用户基本上都会选择Claude,而如果专注于更多的知识与数据相关的多模态处理,那么,Gemini就变成稳定可靠的选项;另一个问题是,随着应用落地场景越来越多,一旦围绕模型构建了越来越多的工具或者应用流程,迁移就会变得越来越难。
当然,国产模型的继续进步自然提供了更多的选择,不过模型规模偏大(万亿及以上的MoE)依然是一个比较大的问题,而且未来几年看起来还将继续增加,这其实意味着很多基础性的问题,例如服务成本,例如私有化部署等,特别是在前沿芯片HBM配置不断翻倍以及内存价格大幅上涨的背景下。
模型公司里,可能依然只有Google拥有足够的收入和生态渗透支撑,Anthropic拥有收入的快速增长(但依然面临高度风险)。
模型进步越大,适用面越广,渗透率越高,反而越利好硬件。这是AIGC模型发展无法避免的巨大尴尬。所以,只能靠巨量的资本开支锁定稀缺的电力、算力资源,将竞争对手挡在门外,才可能活下去。
三、OpenAI开支缩减
这个新闻在假期里“发酵”了,按照CNBC的报告,OpenAI到2030年的运营开支计划为6000亿美金,相比之前多次公开场合表态的1.4万亿美金大幅缩水。
这当然是一个有点偏空的消息(虽然,这在我去年四季度以来就坚持的前瞻观点之内),但我认为目前的评论都没在要点上,真正的要点是,理性计算和市场的一致预期看起来都没有真正相信过1.4万亿这样的数字,市场也已经将OpenAI“到处放卫星”理解为泡沫,所以,6000亿可能比市场一致的预期是来的小一点,但反应自然不会是1.4万到6000这样的幅度。甚至,从另一个方向考虑的话,如果6000亿可以被认为“落地概率较高”的话,这反而是一个非常好的bottom line。
这里,要借用一下微软的RPO。因为这是一个更可信的数字(即使我不看好OpenAI,我也从没将OpenAI破产列为未来可能的场景),这个RPO平均期限是2.5年,OpenAI约为2500-2810亿。大体上,我倾向于认为这个值跟2030年前6000亿的支出数字看起来更为匹配。当然,这也意味着在未来计划里,OpenAI对微软的依赖度可能会比原先市场预期的更高。同时,结合新一轮融资落地,Nvidia大约投了300亿美金的高可信度新闻(各权威媒体均有报道了)看,OpenAI跟其他硬件供应商的“合作”规模缩水的概率反而会比较大。
另外,如果新闻属实,那么这也会意味着可能会缓解“市场对大厂资本开支过高”的担忧,本来大幅增加的资本开支计划就是一种抢资源背景下的被迫举动,是一种囚徒困境。我在去年四季度线下交流时就说过,这种囚徒困境的解法就是类似于OpenAI实际上无法实现“夸大的承诺”。
所以,市场就是很“聪明”,当微软、Google、亚马逊纷纷给出远高于预期的资本开支计划时,不仅它们股价跌了,本该是利好的算力板块也没激起什么波澜。我同样在去年说过,并且在财报解读时也强调了,大厂一定会给出非常高的资本开支计划,这是出于市场竞争和战略规划的需要,但是,实际会花多少,则会是另一个数字。我认为市场同样没有“相信”这样的开支数据,而我,也完全没有必要对自己之前预测的实际落地值进行调整。
还是那句话,这个世界,最终是物理的。
四、那么具身智能呢?
这个世界,最终是物理的。其实我不太想谈春晚机器人,太过敏感了。
同时,我也无法站在自己的立场去谈利好还是利空,我们应该倾听市场的声音。因为情况就是这么个情况,市场会如何表现,完全取决于市场本身。比如香港市场就给了大模型公司很好的反馈(这种评论超出我能力范围)。
不过,在这个问题上,我有两个想法,都是加强的,第一个想法是,只要有数据,什么都可以做到,春晚的表现就是体现了这一点,至于讨论是不是预编程没有意义,懂行的基本都知道是怎么回事,这个技术含量一点都不低,甚至很高;
第二个想法是,具身智能,比我前几年认为的要难得多,可能多五到十个数量级,这个观点,随着假期里集中精度认知心理学和脑神经科学方面的一些书籍,结合自己前段时间一边拍照一边感受时的体会,是明显加强的。我觉得真正的难点,就是数据,我们甚至可能根本不知道我们缺什么数据。
五、所以,一切都围绕数据
模型从训练阶段到应用阶段,都是数据,我们甚至于都不用去讨论Coding、多模态、视频生成这些具体的任务,就是一个进入AI时代本身,就意味着数据的持续的指数级的增长,这根本不是“大数据”的量级可以比较的。
所以,电力、GPU、存储、CPU的长逻辑都在这里。相比之下,电力看起来是最稳定的,毕竟一次投资几十年受益;存储弹性最大,因为在同样的空间里,价值量是可以成倍增长的(容量、带宽);但是这些,最终还是要通过GPU(ASIC或其他算力芯片类型)/CPU发挥作用。只不过长期来看,CPU大概就是受物理约束最大的部件(节点数量),而且CPU技术架构太稳定了,短中期里不会有什么大的突破;存储尽管弹性大,但是经过一段时间的疯狂,可以认为基本上已经基本反应了产业链里应有的地位,我从来认为内存就是非常重要的核心,但是到这个阶段,或许从赔率上而言,跟GPU、封装基本处于差不多的水平了。
当然,有一个因果倒置的变量:就是市场愿意给“超级周期”或者“周期性大幅减弱”多高的估值水平。可是,估值水平就是个结果,而不是原因,所以,为什么说是因果倒置。
我们只能让市场告诉我们它的情绪是如何的。
六、重要的财报
Nvidia下周的财报大概率还是会超市场预期,但是,承接上一个问题的最后一句话,情绪会如何,我们无法预测的。可是,我们还是有可以明确的关注的点,我相信电话会议上,分析师会问对OpenAI的投资问题(传说中的300亿美金),OpenAI的开支缩减问题,Rubin的进展,等等。
当然,就财报本身,我认为毛利率及毛利率的展望会是一个非常重要的观察点,内存价格涨了这么多,NV对上下游的真正溢价能力以及未来潜在变化,基本决定了“疯狂”的持续时间。毕竟,在PC、手机为代表的消费者领域,我们第一次看到显著的负反馈正在发生。
对于CoreWeave,我无法预测,很重要,但事实上,重要性相比前几个季度下降了,它的好坏最多决定几家neocloud公司,而不会对产业链带来太大的影响了。重心已经回到核心重要公司上了,特别是当模型竞争和资本开支竞争达到这个量级的时候。
七、最后一点:也许确定性才是2026年开始最重要的。
PS:您看,我写的,还是会跟AI输出的不一样,尽管我的第一步已经限定了它输出的范围。不过,我只是说不一样,客观而言,我认为它的准确率会高于我。
但是,我也注意到几件事情:春晚的科技感自然很足,那种填的很满信息量很丰富的风格曾经是我最喜欢的PPT风格,可我突然开始觉得有点不太对劲了;B站的所谓春晚其实绝对水平也就那样,但你会看到一个个“人”,会看到许多意外;小红书开始主打“活人答案”的广告词了,……
“活人感”。