
Work efficiency varies significantly across different environments and states. This week, I have gradually entered output mode. Just in time for earnings season—yes, every starting point is based on Gemini's Deep Research, combined with NotebookLM's Slide Deck. This has become a benchmark, a baseline to examine the current level of AI.
Therefore, unlike some of my recent articles, I will post the results first. A disclaimer: These results represent only what Gemini generated and do not necessarily reflect my actual views. To avoid unnecessary controversy, I have removed two pages regarding "regulation."

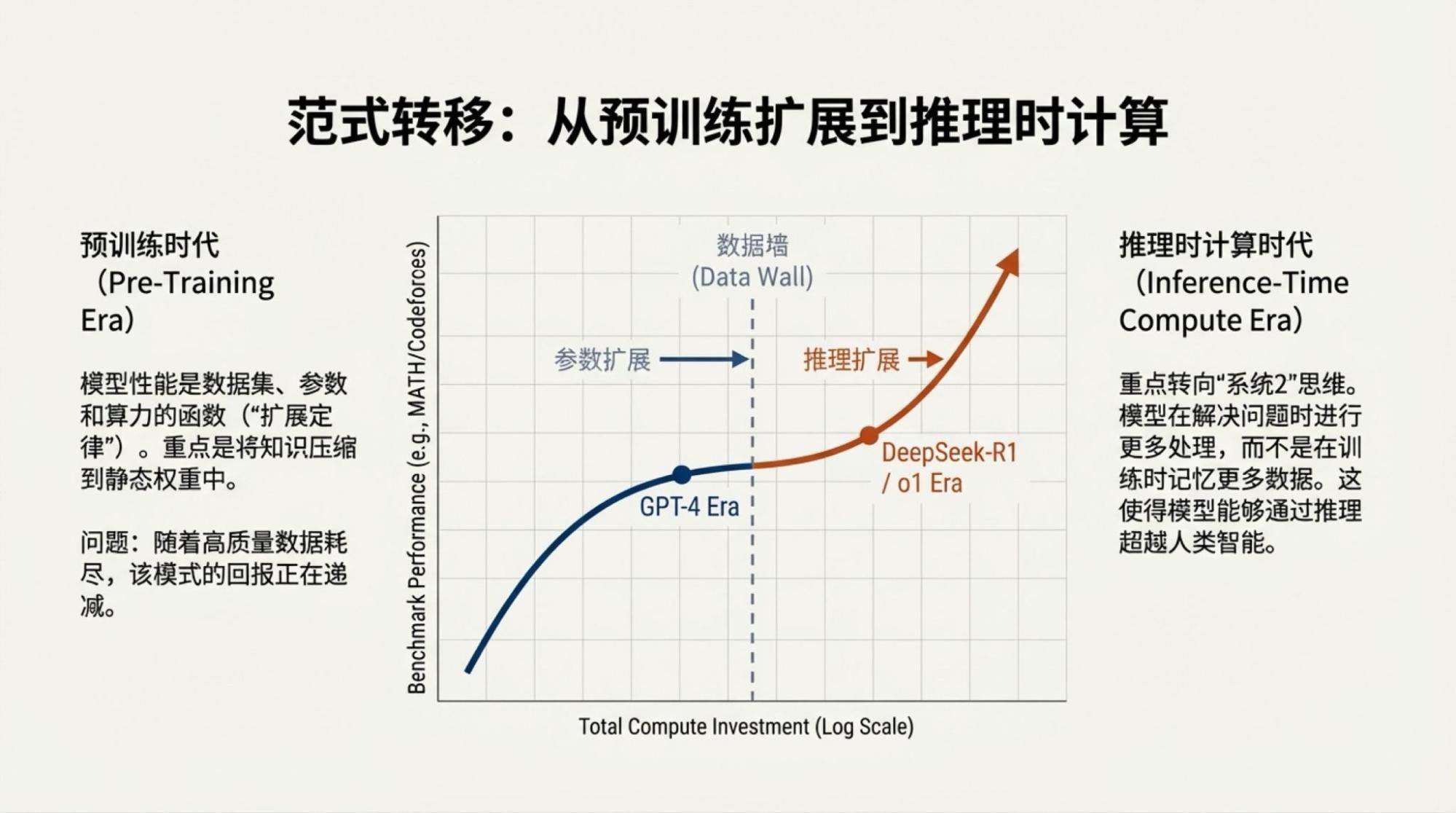


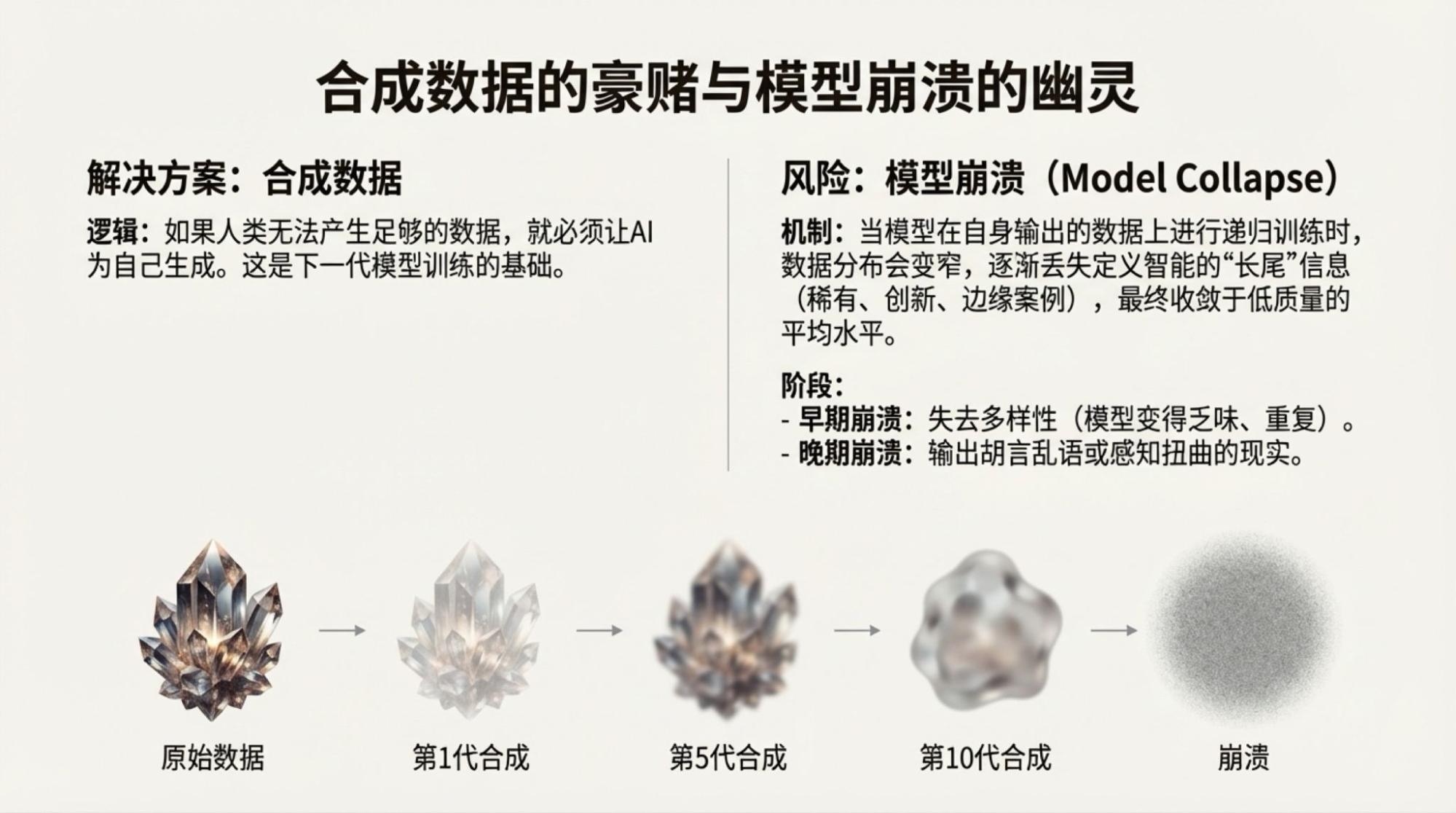
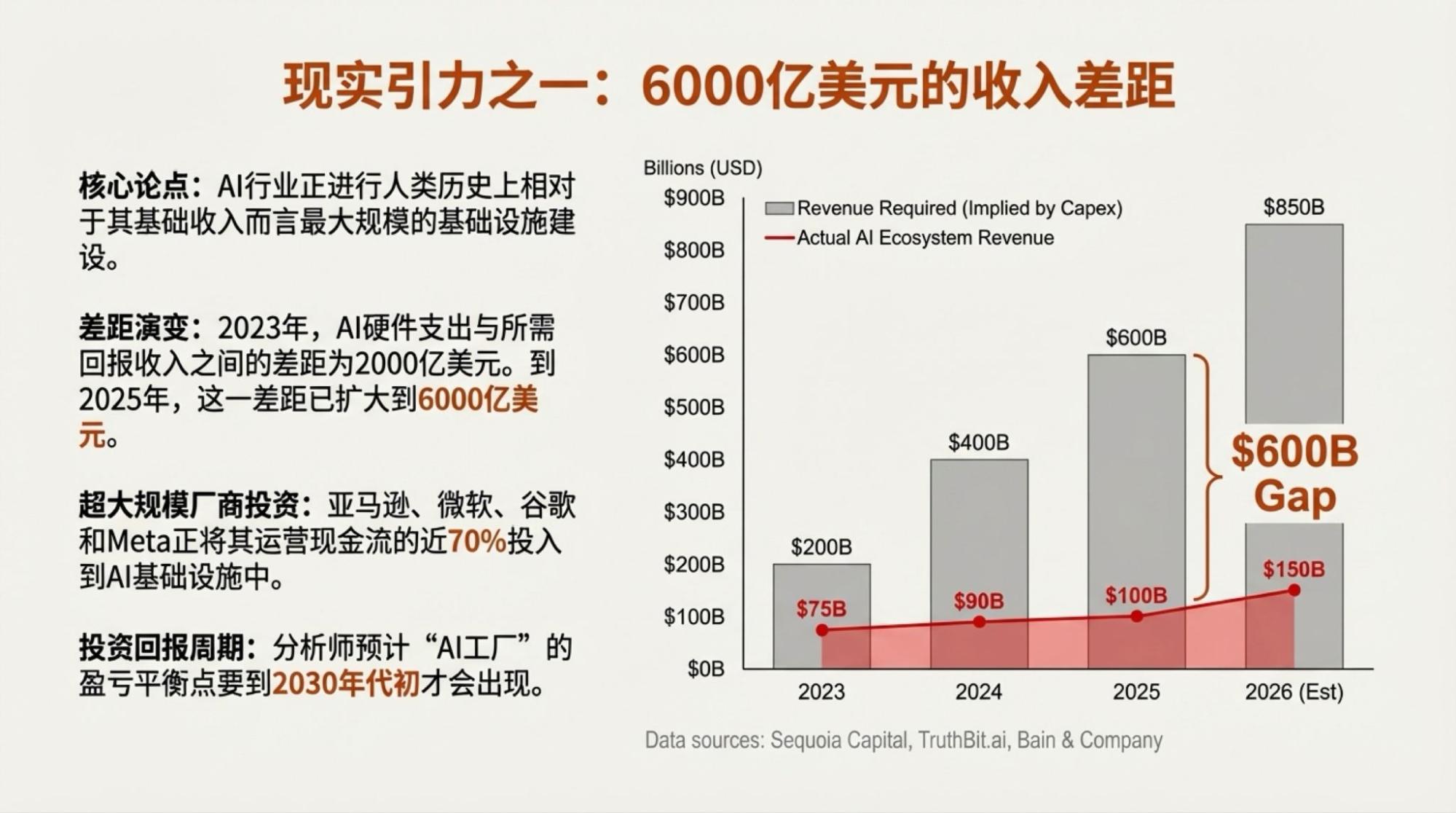
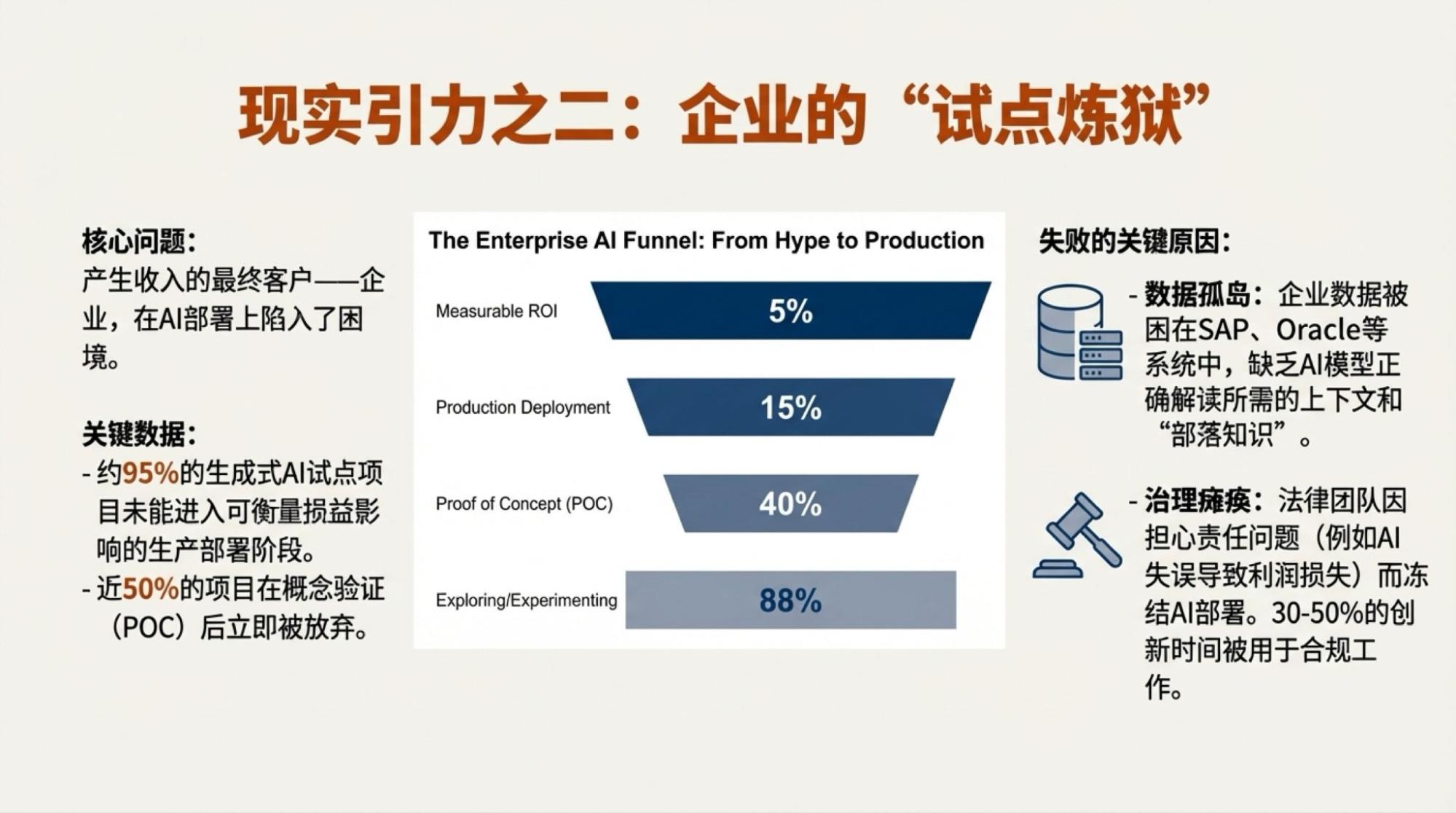

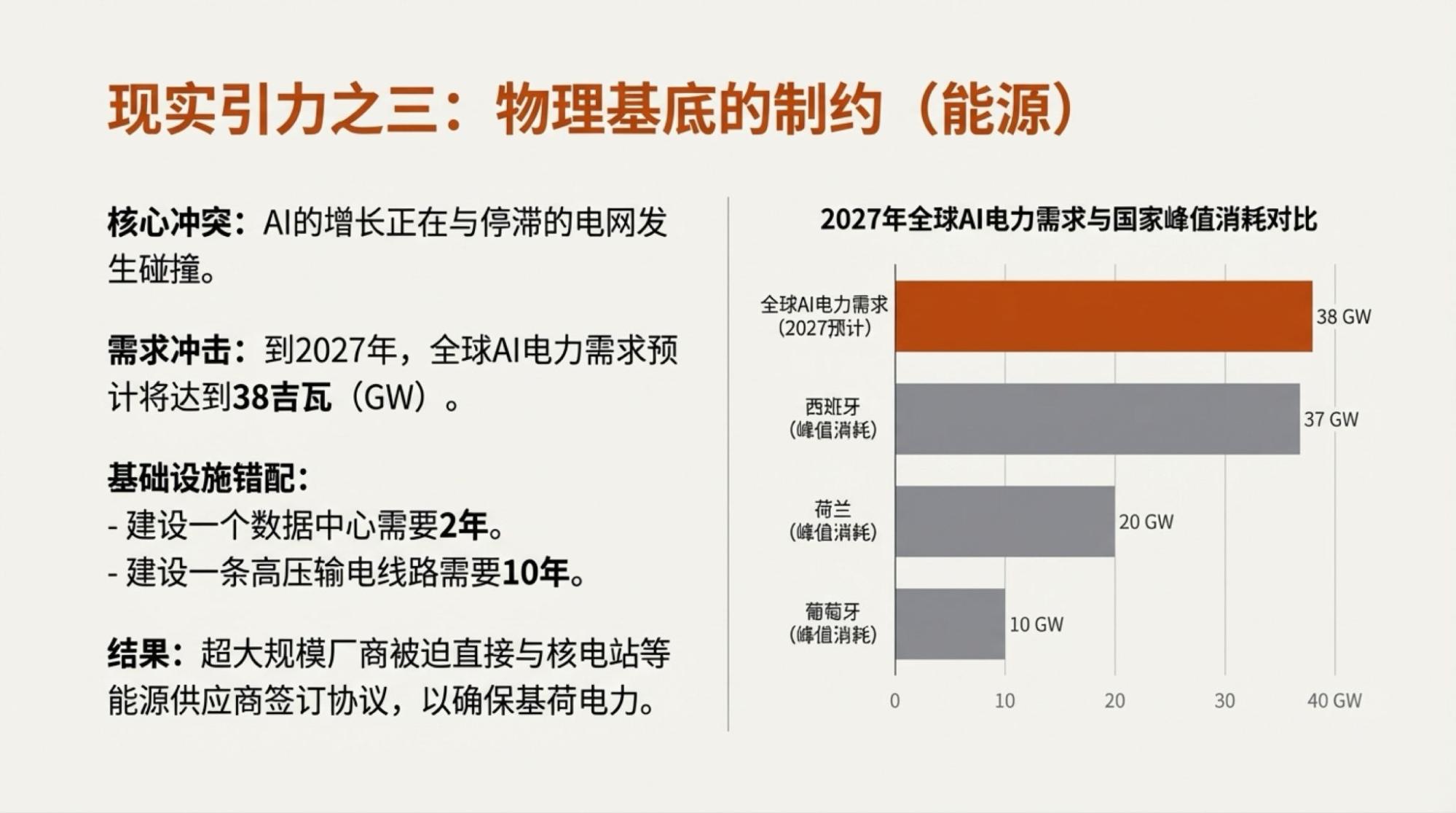




Of course, saying that the above content was entirely autonomously generated by Gemini isn't the whole truth. I highlighted several points of contention, and then the content was generated by two model-driven tools: Deep Research and NotebookLM.
Objectively speaking, Gemini-3 powered Deep Research has indeed made significant progress. For example, it can now attach charts and has added stricter time alignment requirements during the planning process (this was to correct the "temporal hallucination" issue that the Gemini model failed to solve from version 2.5 through 3).
However, these are optimizations at the Agentic level, not improvements brought by the pre-training stage.
Naturally, with the addition of the NotebookLM Slide Deck, it looks much more "advanced." At the same time, the problems have become more apparent, specifically regarding the boundaries of AI capability:
The model loves using "buzzwords." The culprit, of course, is internet data—us, the "attention economy." "Rubbish in, rubbish out." Some people might like these big words, but I personally dislike them.
In terms of Gemini-3's performance, Deep Research is more robust. NotebookLM, enhanced by Nano Banana Pro, looks "pretty," but its attention is clearly lacking, and "hallucinations" are more obvious.
Comparing Gemini-3 and Gemini-2.5, I subjectively feel there is improvement, but in terms of attention, there is almost no progress. This is a fundamental flaw of the model. The direct result is that if the context exceeds 200K, output quality drops significantly. In this regard, version 3 seems slightly worse than 2.5—I understand this as a side effect of "thinking."
Many discussions suggest that models trained on Blackwell clusters in Q1 or Q2 will see a "quantum leap." I remain relatively cautious about this. Under the Transformer architecture, I believe the bottleneck has clearly pointed toward data and the architecture itself. We might expect architectural optimizations that allow smaller models to approach the capabilities of current frontier models, but achieving a "quantum leap" in frontier models simply through scaling is much more difficult.
While 2025 looks like a year where models can complete much more work thanks to Agents and multimodality—and that is true—taking Gemini as an example, the places where 2.5 made mistakes are still where 3 fails. The real highlight remains multimodality, but how much further token-based multimodality can progress remains to be seen.
So, the question arises: entering the controversial year of 2026, can the boundaries be pushed further?
Based on my habit, I'll discuss this on two levels. The first level is how to improve the model's output quality:
Clearly, as models upgrade, output quality will improve. So, "waiting" is always the best answer.
Improving human input—not just simple prompts, agent calls, or context engineering, but something like Claude's skills.md. However, "skills" are more about rule conventions, whereas human input must contain some sort of outline-style thinking. It's about personal, independent inspiration.
The second level is how to improve the quality of the final output, meaning how humans function within the iteration:
Tools and workflows: There can be many AI tools. Under "vibe coding," there’s no shame in "use and discard." What matters is how humans "build with blocks" to achieve the final business result. There’s no real distinction between liberal arts and science students here.
Human-AI iteration: If LLMs are essentially a form of compression, then the state of humans working with AI is a repeating cycle of "Expansion -> Compression -> Expansion -> Compression" until the result is satisfactory.
Should humans edit AI results? No. We lack the capacity to manually fix results produced by machines with productivity levels a hundred times our own.
If we believe that AI can completely change this world, then the necessary immediate step is to let AI enter our world. Models are still improving. Even if true AGI arrives, it won't solve every "last mile" problem. Boundaries are ultimately broken by humans, but we don't necessarily need to do the manual labor ourselves. Playing the role of a "Human Mentor" to AI for now and the foreseeable future is a process that can, at the very least, be quite enjoyable.