I saw an article on signal65 recently about inference cost calculations for different architectures: https://signal65.com/research/ai/from-dense-to-mixture-of-experts-the-new-economics-of-ai-inference/. The material mainly comes from SemiAnalysis, but it is well-organized.
I wrote a related article last October, and the conclusions are basically the same, though at that time the data came more from MLPerf and covered more hardware and model categories.
In terms of basic conclusions, not much has changed compared to three months ago, but after this period, some points can be highlighted more clearly:
- Model architecture and hardware architecture are highly coupled. MoE is the most demanding on interconnects, both intra-node and inter-node. This is the scenario where NVL72 achieves its maximum performance;
- Dense models and Diffusion (text-to-image) test single-chip capabilities more, especially memory capacity and bandwidth. That’s why we see both GPUs and ASICs increasing memory and bandwidth, as this benefits almost all models;
- So, it's about the process node and HBM, right? Exactly. Looking at single-chip capabilities (official Nvidia data), the improvement of Rubin over Blackwell is indeed greater than that of Blackwell over Hopper;
There is one specific update, an opinion that has gradually strengthened:
LLMs themselves have basically reached a limit. Although larger scales and more data can bring a "perceptual" boost, it’s increasingly like the annual improvements in PC and mobile chips. Comparing parameters looks straightforward and the speed indeed seems faster, but the tasks and functions that can be achieved remain the same.
Currently, everyone is looking forward to the performance of the first model trained on GB200 or 300 clusters. To be honest, my expectations aren't that high: "surface intelligence" depends on data and data compression capabilities (model architecture). The powerful multimodal capabilities (also data) presented by Gemini-3 mask the "cruel reality" that improvements in the pure text modality are actually quite limited.
If the above is true, finding a brand-new model architecture is naturally most important, but hardware architecture will be even more critical under the context of the scaling law. Google's hidden advantage lies here: although their chip and cluster capabilities are at least a generation behind Nvidia, they are ahead in networking, framework-level optimization, and tailoring to their own model architectures.
The current consensus is that "multimodal" isn't about multimodal input, but multimodal output; "Agentic" isn't about layering an agent on top of a model, but integrating it with "multimodality."
In summary, the challenges for model and hardware architectures will grow. Google still holds the greatest advantage; Nvidia has plenty of hardware and a strong user base, allowing them to design and update product architectures based on newly discovered issues—and they are doing exactly that. As for others, whether they are GPU "alternatives" or self-developed ASICs, what they lack is "engineers" who deeply understand both algorithms and hardware.
Do such people exist? Yes, Jeff Dean is one, but there is really only one Jeff Dean in the world.
In massive data centers, strange "new problems" arise every day. When power stability, hardware bottlenecks, and software stack bugs intertwine with temperature, finding the problem always requires enough experience, some creativity, and luck.
Anyway, I've strayed a bit. One-sentence summary: when token generation cost becomes the most important economic indicator, it represents extremely high barriers—both visible and invisible. Therefore, I will continue to "diss" Nvidia's over-promotion, because the essence of these barriers is people—a few invisible individuals—and it is far from a "plug-and-play" state.
Moving to the second part: continuing to recommend NotebookLM, which is essentially recommending the Gemini ecosystem built by Google.
Objectively speaking, the output quality of NotebookLM isn't very high—perhaps only utilizing 50-60% of Gemini's model capabilities—but my reason for recommending it is direct:
It fits the human workflow better and serves as an important output node in the Gemini ecosystem. I can aggregate my own articles (written in Google Docs), internet content (text, video, etc.), and simple handwritten outlines together. This is a massive change in the AI era.
It can generate various types of output for one or multiple pieces of content: mind maps, infographics, slides, overviews, etc., such as based on the Signal65 article mentioned at the beginning.
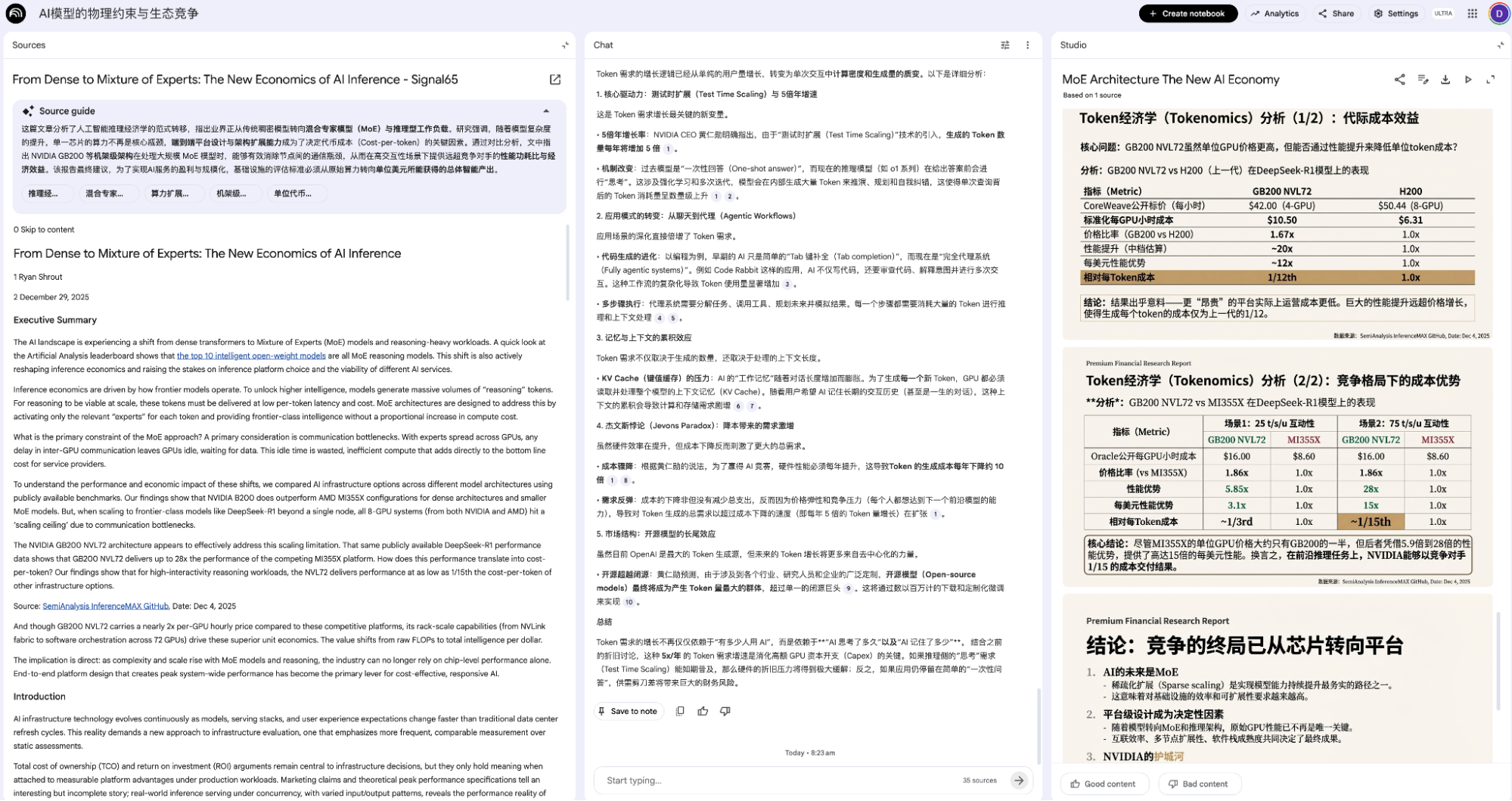
The primary purpose of the output isn't to be published directly but to facilitate quick organization and comparison. The model might mention points I overlooked; I might find some points more important than the model does; or points might be wrong—either on my part or the model's—and the reasons behind those errors are more valuable. As shown below, the rightmost part clearly has errors, and identifying where the error occurred is more important.
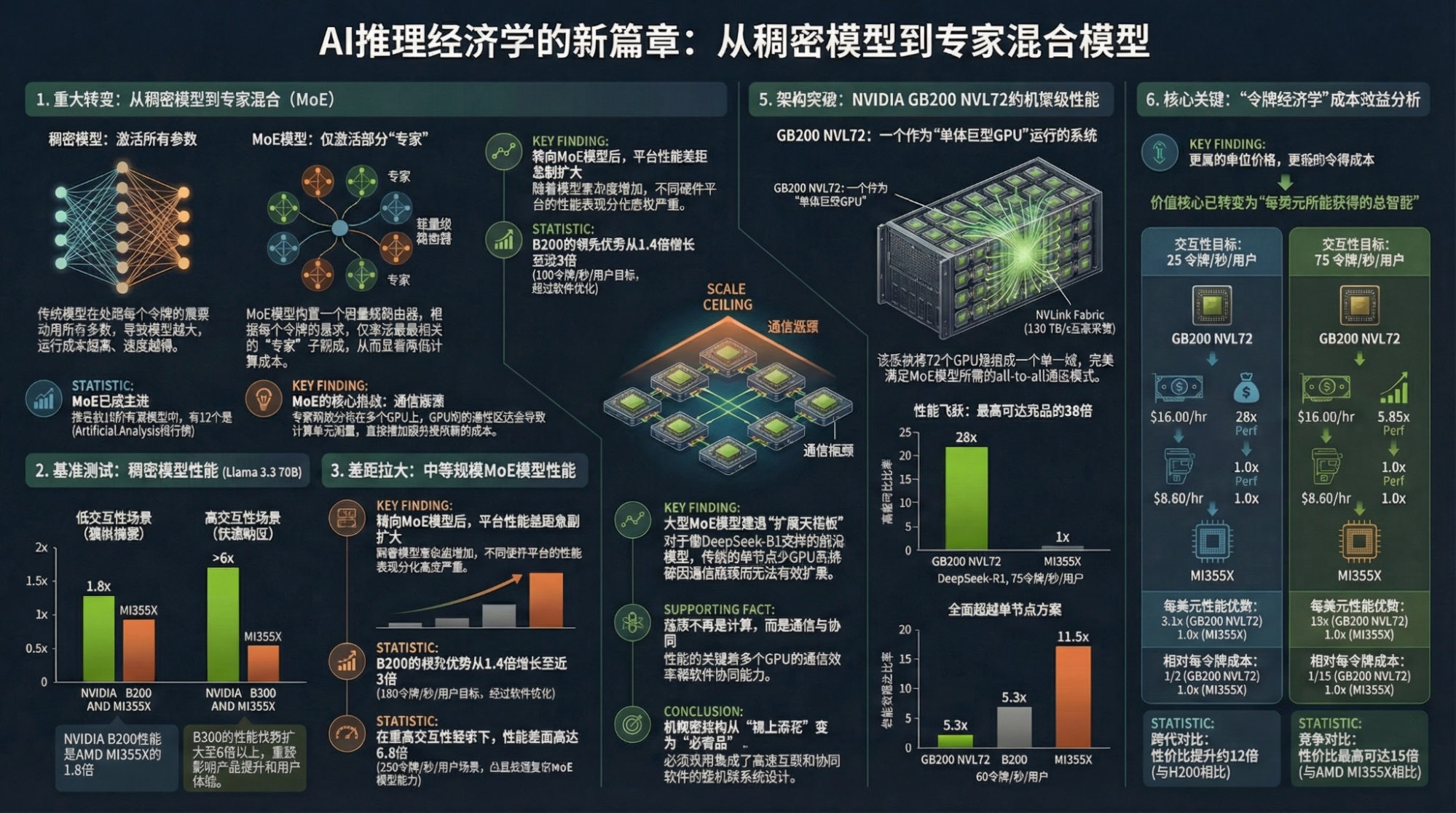
I am confident that my own tools and processes can exceed NotebookLM in generation quality, but NotebookLM is clearly superior in cost and efficiency. Efficient and cost-controlled tools are more likely to create stickiness and change human habits, which might be more important in this era.
Of course, we can find many "alternatives," and I've even made some tools myself, but NotebookLM isn't just a tool; it's Google Workspace, Google Drive, YouTube, Google Search—the intersection of all these products empowered by Gemini's multimodal capabilities.
So, it really is a good tool that helps us improve efficiency; So, it really is a good tool that helps us find needs; So, it really is a good tool that helps us optimize workflows; So, it really is a good tool that helps us understand AI;
Historically, our linear extrapolations are often wrong. Regarding 2026, it might not be about AI replacing jobs, but rather, a human counter-attack?
While this is also likely wrong, such a speculation aligns more with my recent feelings and inner sense of "insecurity."