Before starting today's update, I must admit: the network environment is having a significant impact on my productivity. Therefore, good models are important, bandwidth is important, token speed is important, and connectivity between tools is important...
I have a backlog of things to write, so I'll take them one by one. Let's start with the latest and perhaps most important: Jensen's speech at CES. I didn't stay up late to watch the live stream, so I didn't feel the same excitement and thrill I had a few years ago. I'm not sure if it was because I missed the live broadcast or if I'm genuinely experiencing some "aesthetic fatigue."
It doesn't matter; that's not what's important. Only two things are: one is the Rubin architecture, which is closely related to many people's "wallets," and the other is those "futures" that sound cool but are actually quite far from most people (actually, medical AI really has potential; after experiencing the "workflows" of various domestic medical institutions frequently recently, the insights came to me "immediately," so that's also part of the backlog).
Detailed demonstrations and summaries are no longer suitable for me to do manually; I'll leave them to NotebookLM. By simply providing the live video link, it generates output. Although my goal is for my own reference, as a public-facing product, its performance is excellent. Therefore, following my recent standard practice, I will attach them at the end.
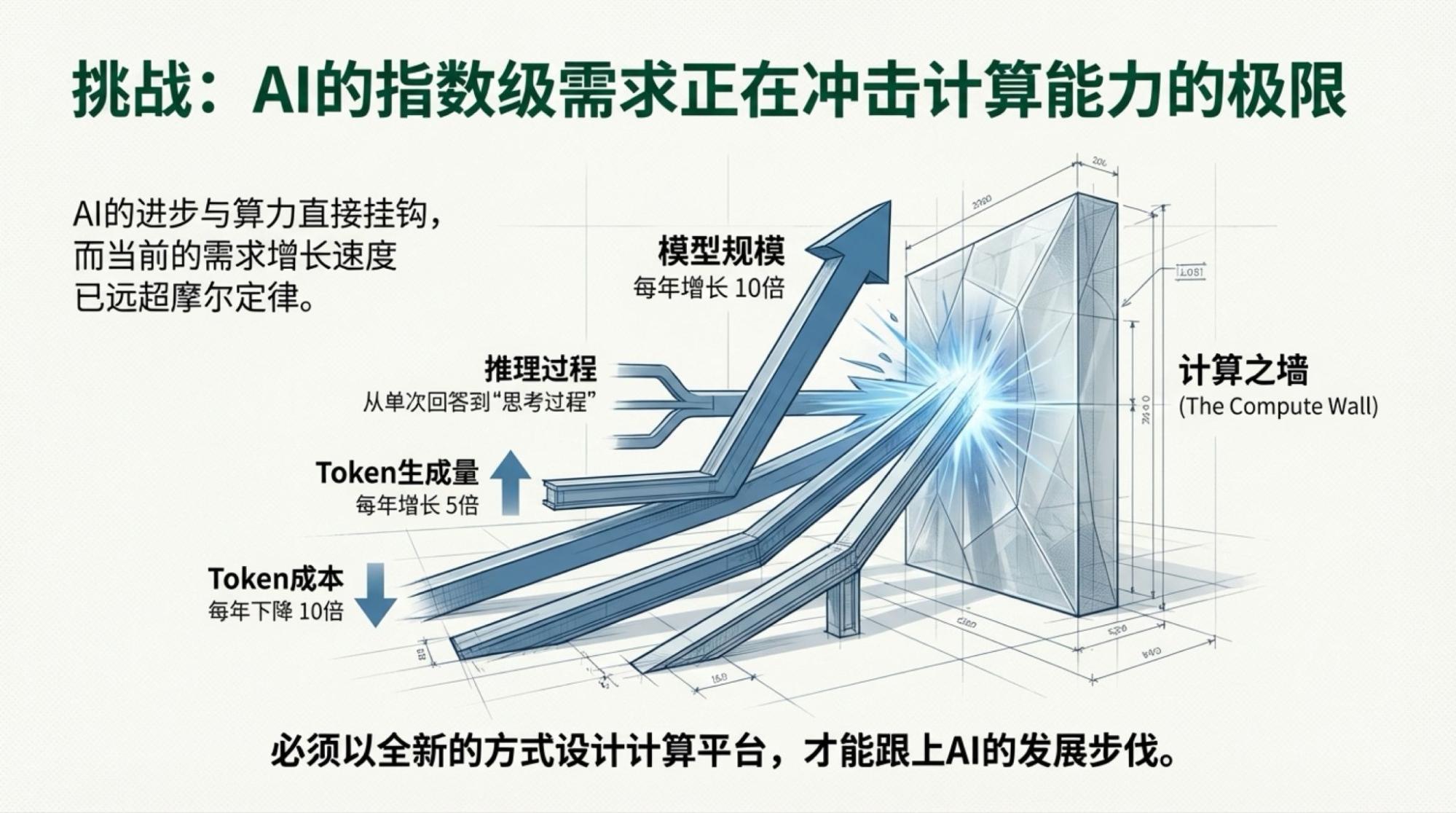
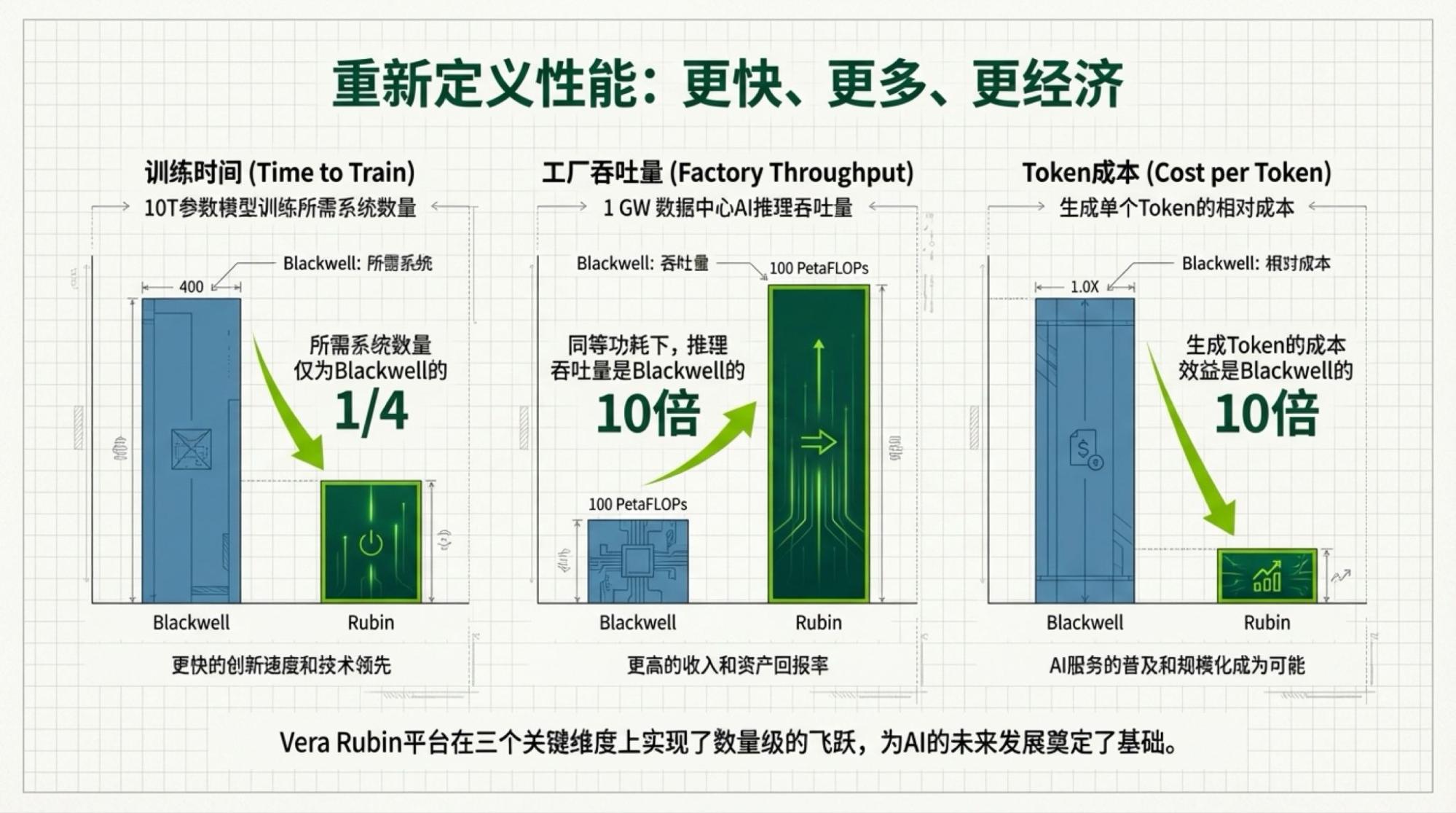
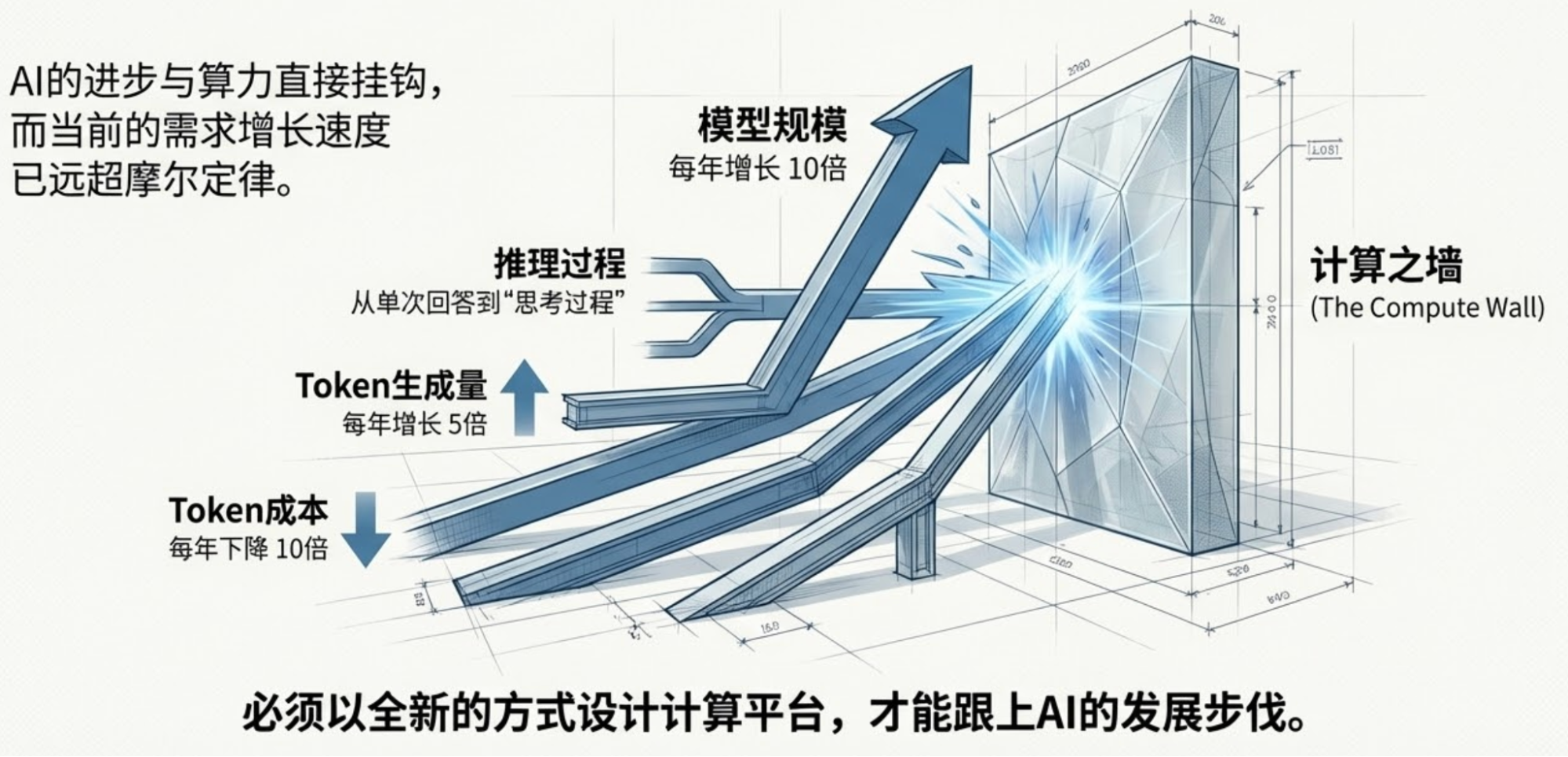
As for the part I want to write, the conclusion is simple and expressed in the title, though the facts and logic are slightly more complex: according to the host's view during the Jensen speech warm-up, token usage will increase fivefold annually. According to Jensen's description of the Rubin NVL72 system performance, inference costs will become one-tenth.
When I saw this page generated by NotebookLM, I believe I felt the same as many others: Are we entering an AI deflation era?
So, I quickly re-watched the video and found the sources mentioned earlier: the fivefold token volume came from the host's statement, and the one-tenth cost reduction came from Jensen or NVIDIA's official introduction.
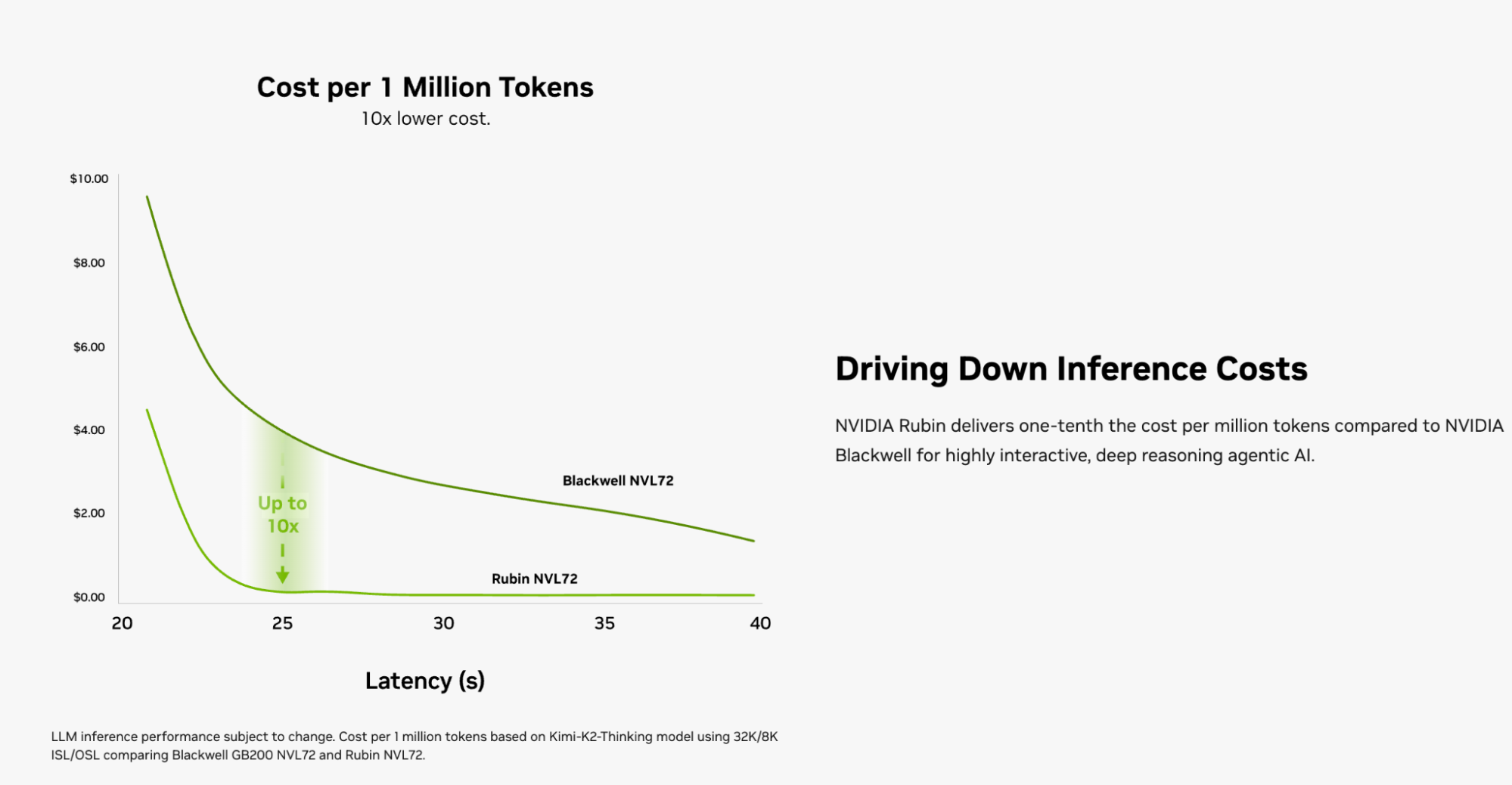
The image above is from the official website: https://www.nvidia.com/en-us/data-center/vera-rubin-nvl72/?ncid=no-ncid
Of course, we haven't seen any news of actual Vera Rubin NVL72 deployment yet. Even if deployed, it's mainly for training. Despite Blackwell shipping in high volumes, I believe most current inference is still running on Hopper architecture or earlier TPUs.
However, this presents a very interesting situation for the "Jevons Paradox" we've been discussing: which will move faster, the rate of cost reduction or the growth rate of token usage? 2026 might provide an unexpected answer.
I still maintain my prediction for 2026: token usage will "double every three to four months, while model costs drop by two-thirds." But this doesn't necessarily mean a huge growth in model inference service revenue, because competition will likely make most model inference services free.
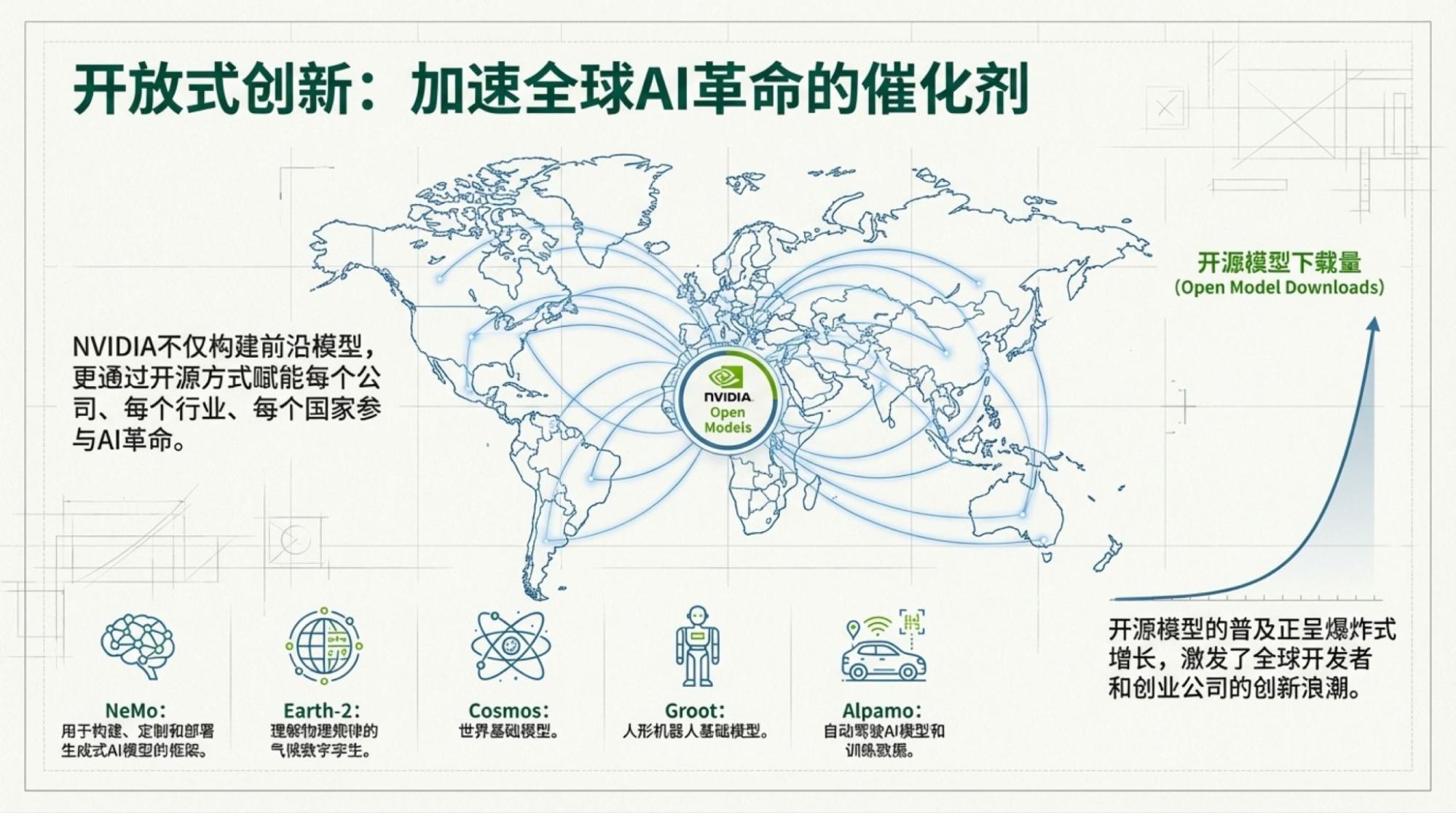
Regarding models, Jensen's key point comes from the popularity of open-source models (open weights). I've always felt that NVIDIA's understanding of the inference market isn't based on the "Big Three" (OpenAI, Google, Anthropic), but on broader "private deployment" (often within cloud environments). I also believe that private deployment of open-weight models will soon shoulder the weight of most AI tasks. Especially if we look at pure language models—even Gemini-3's progress over Gemini-2.5 isn't particularly significant—open-weight models probably only need one more generation of upgrades to meet most scenario requirements. In 2026, the Llama-3 or DeepSeek moment will likely happen again; we just don't know who will "carry the flag."
So, basically, the "scissors gap" between AI performance at the technical level and its economic performance is widening. The "AI deflation era" follows the logic of technical extrapolation but contradicts basic economic principles. Either those fundamental economic assumptions will be challenged, or economics textbooks are about to enter the dustbin of history. Whichever happens, I think it's fine.
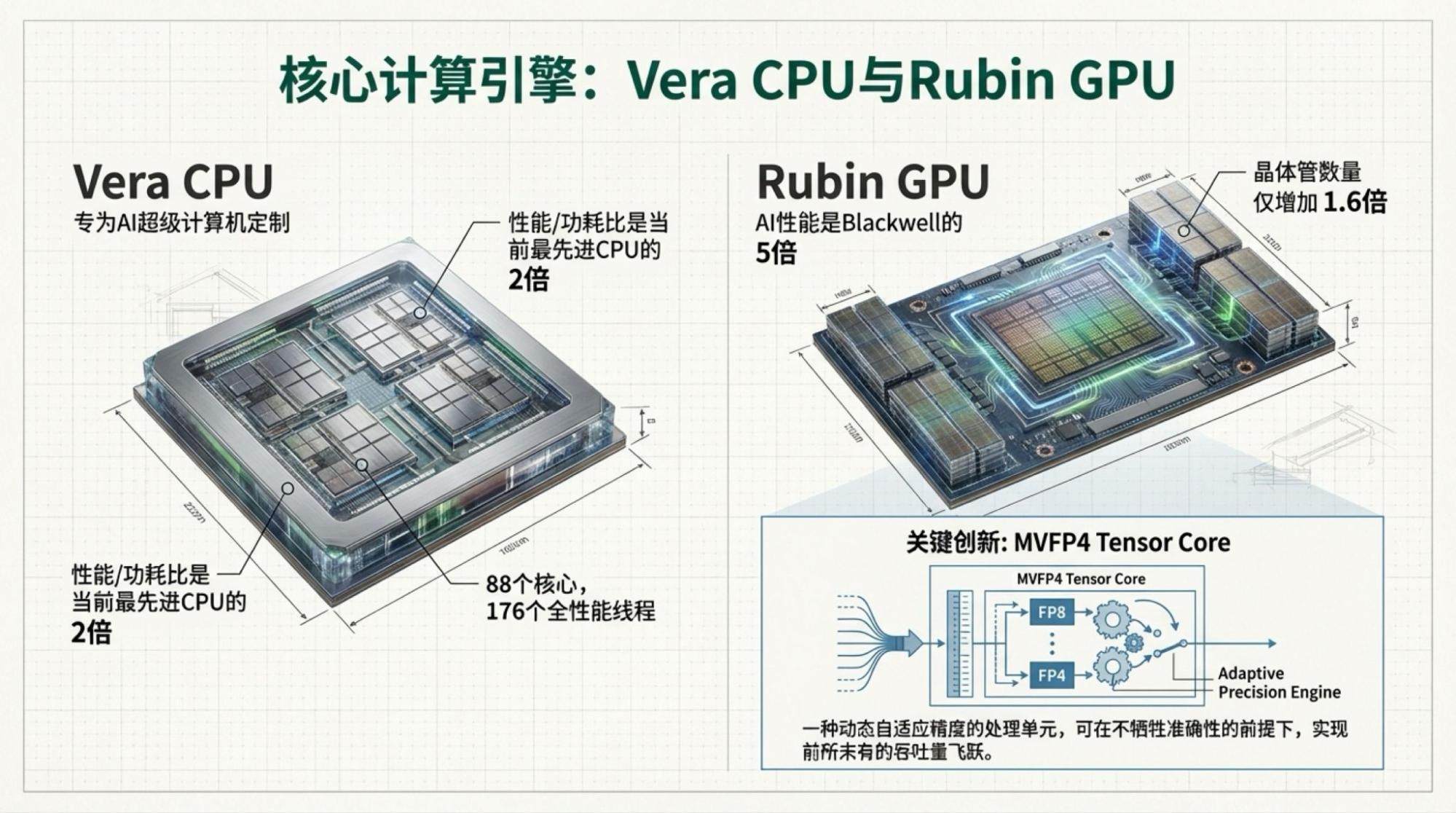
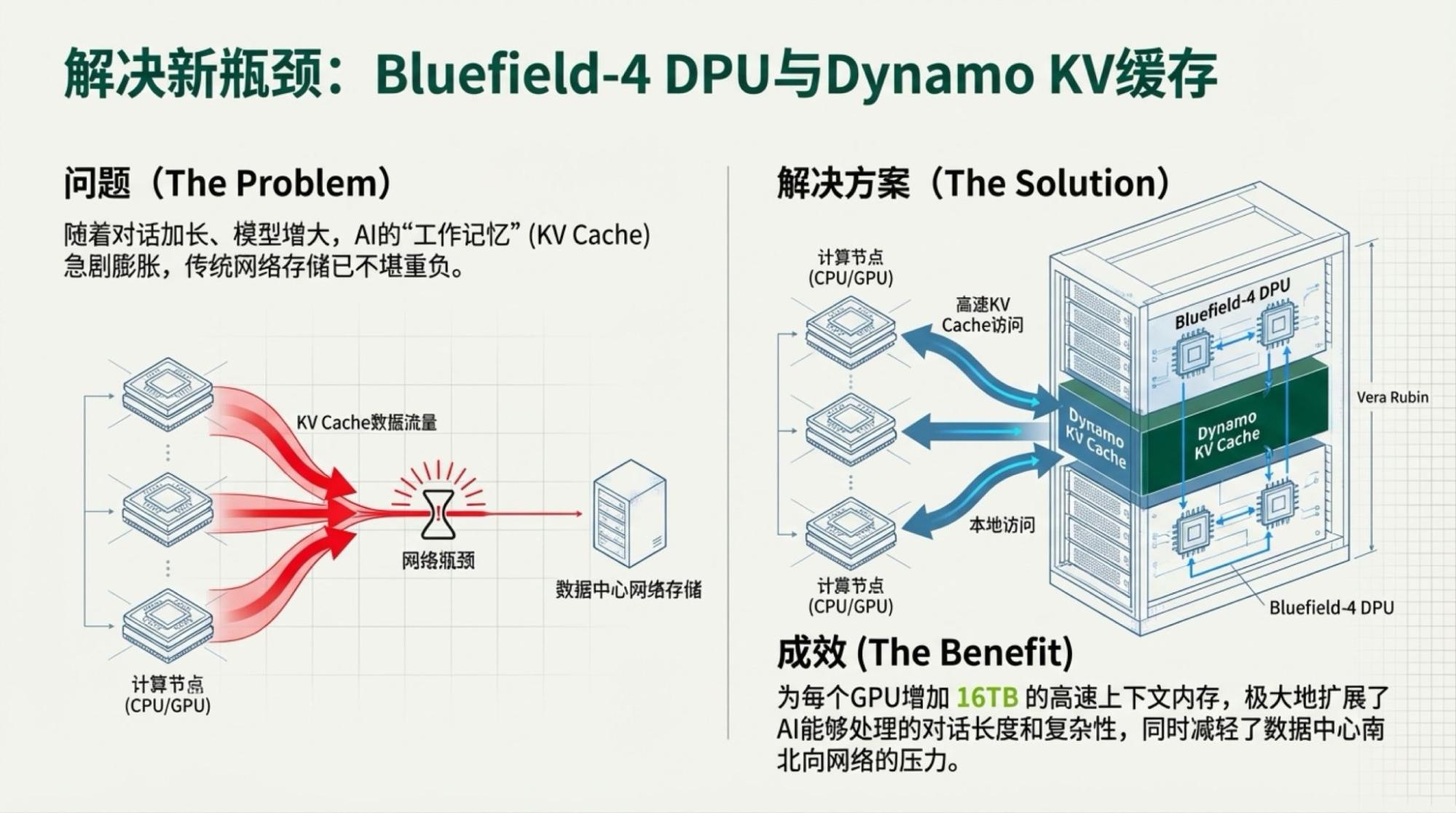
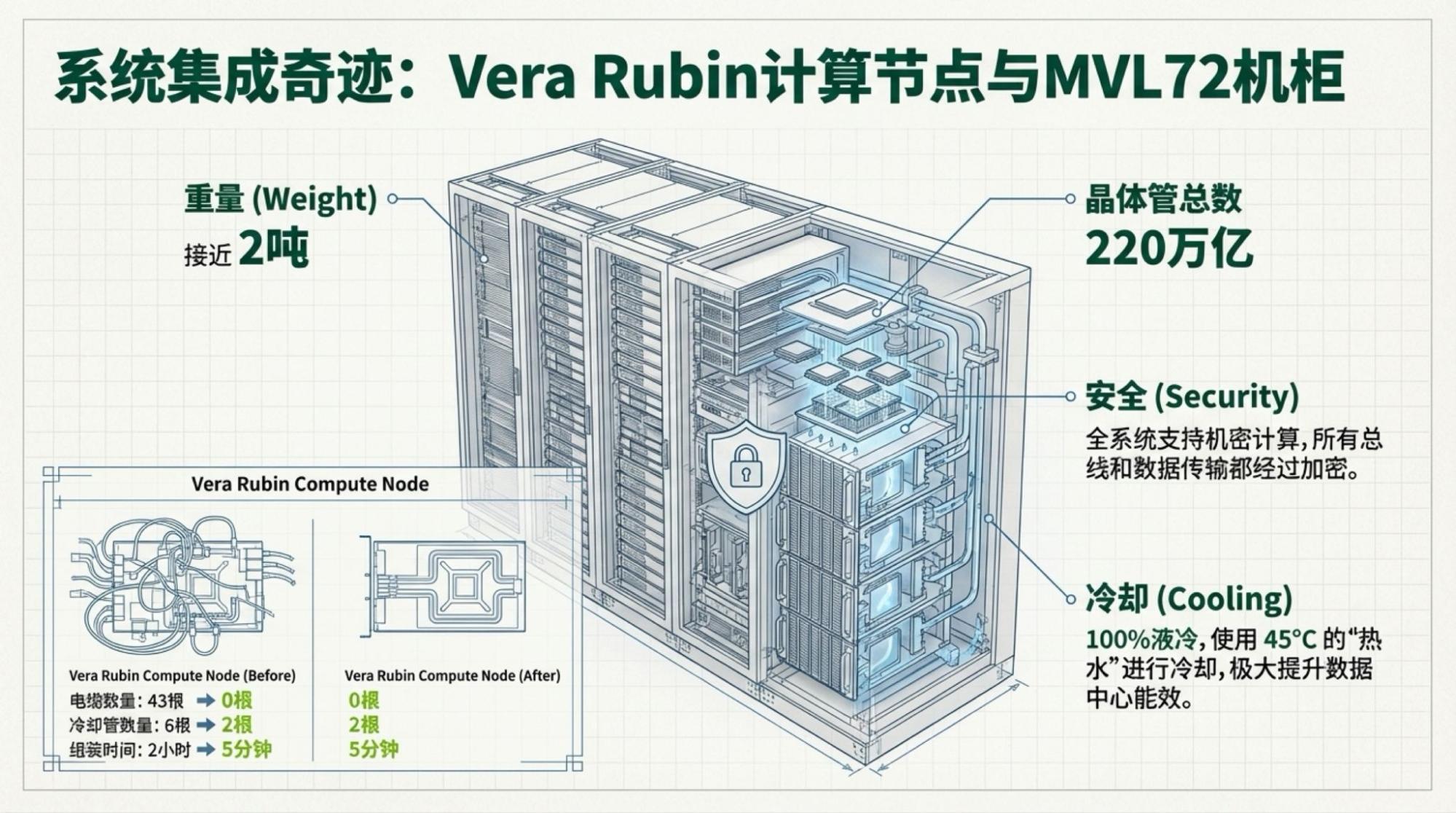
I'm also interested in Vera Rubin, even though most information is already known. Some details are quite interesting.

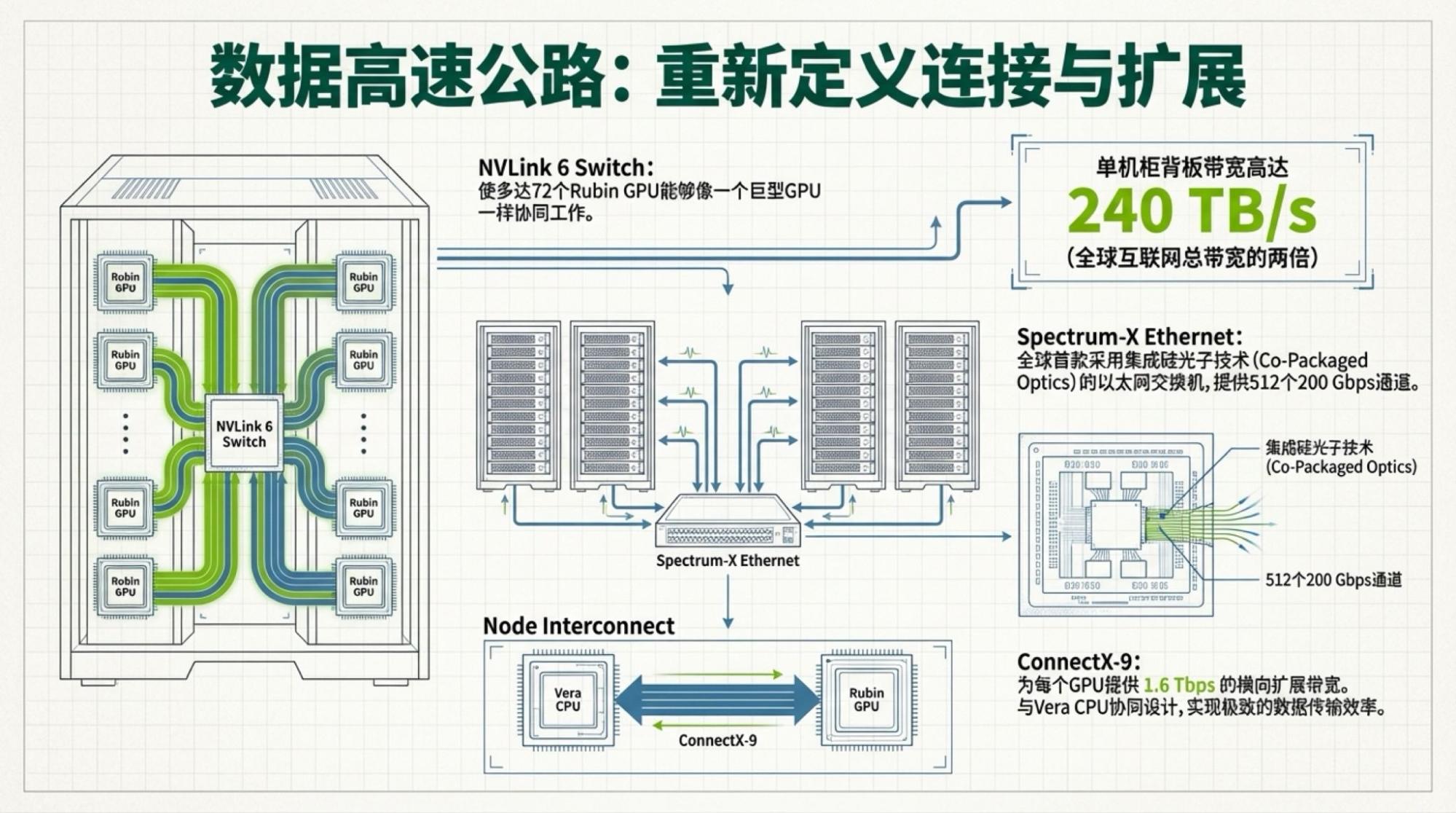
The image above is also from NVIDIA's official website. So, what does it tell us? Process technology and memory bandwidth contribute to all performance gains. What does interconnect bandwidth do? it determines how much of a "discount" is applied to those gains in process and memory. But it's very sensitive to model architecture. Obviously, MoE architectures require massive data transfer between chips, which is the primary reason why TPUs could train Gemini-3.
Thus, where the real bottleneck lies is clear at a glance.
Regardless of whether "AI deflation" arrives immediately, I can no longer manually create PPTs, draw diagrams, or write all the code myself...
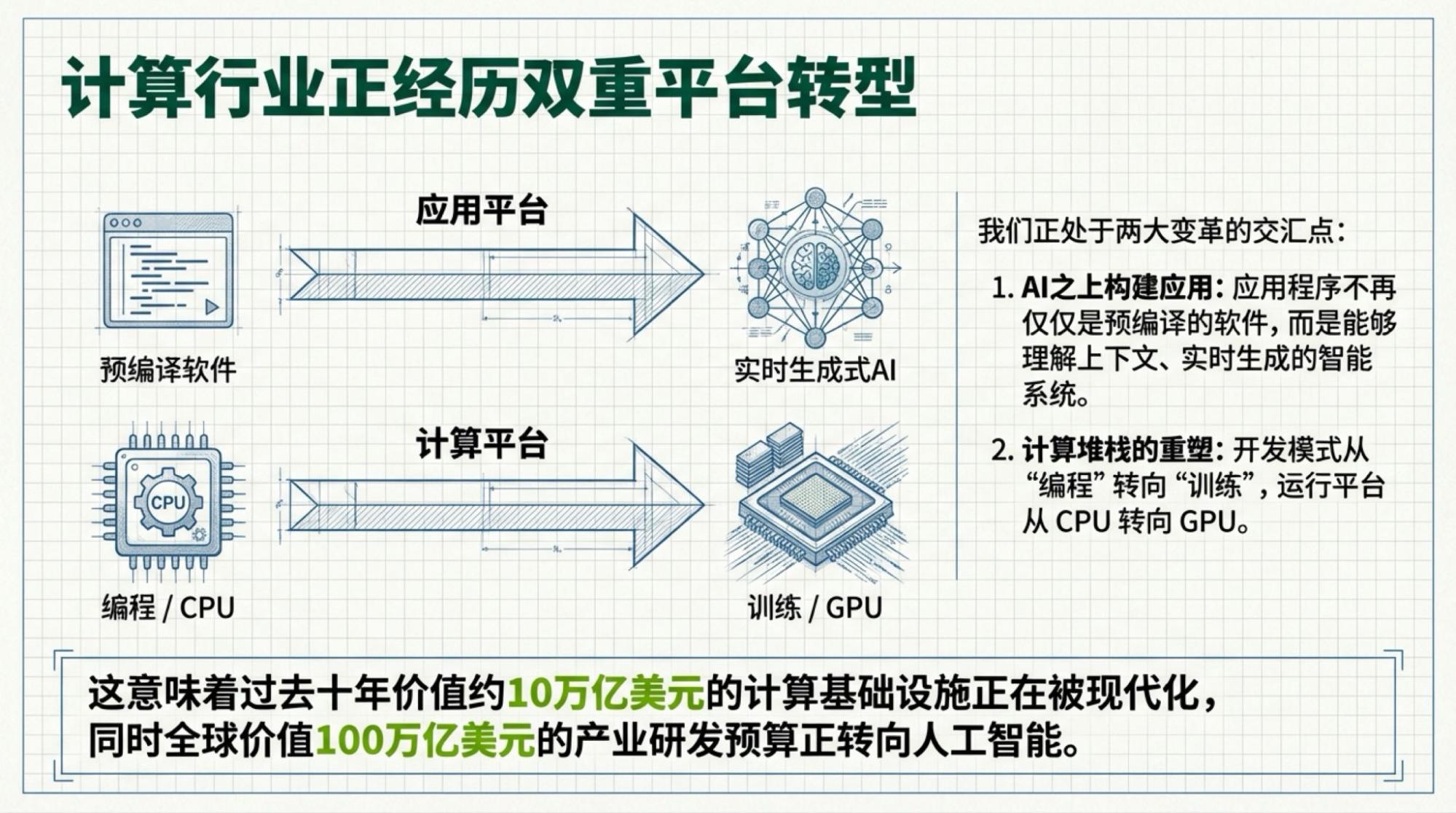
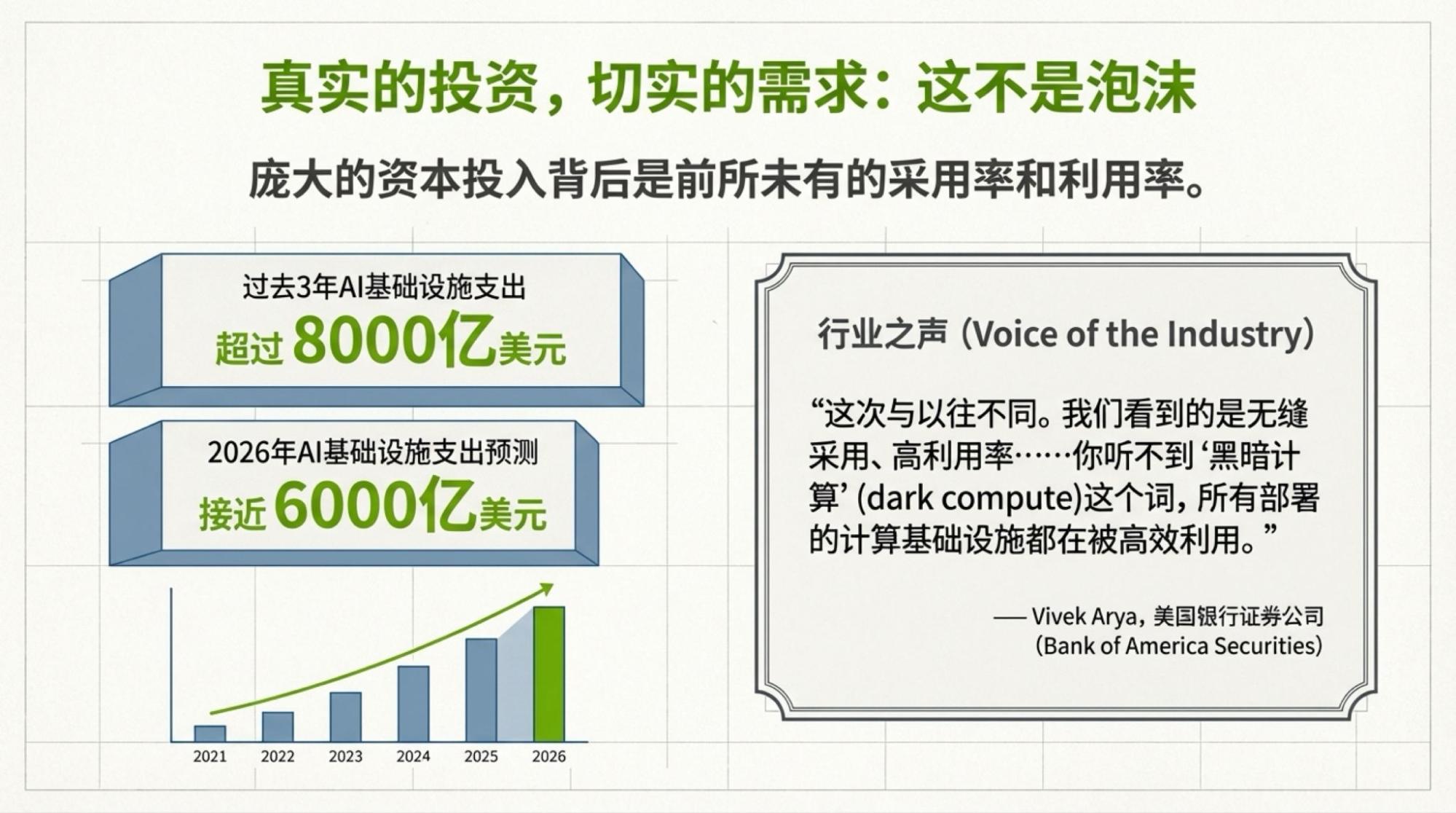
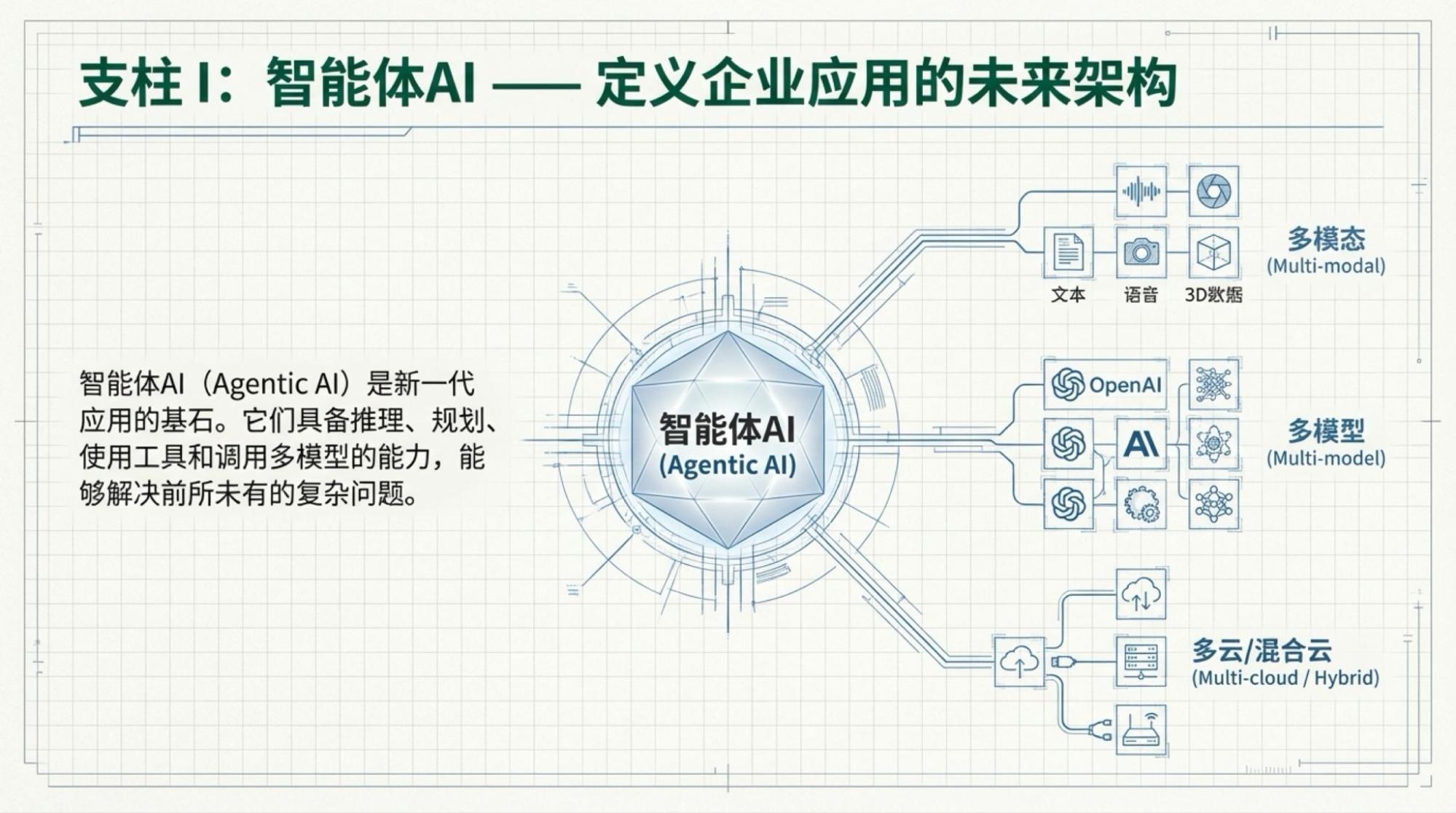
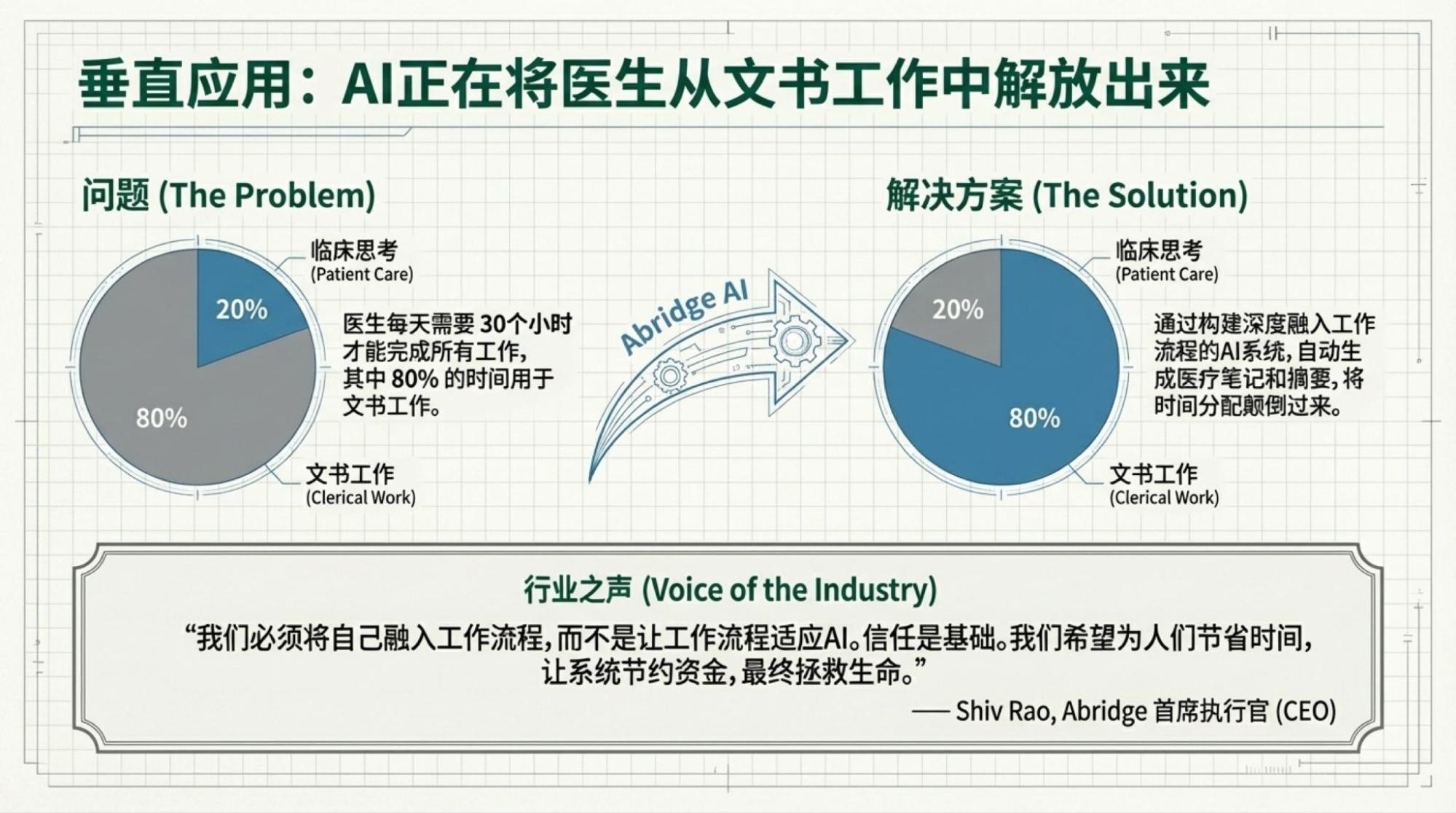
Using the live video, I used my own tools to create infographics (because NotebookLM's image quality is poor) and used NotebookLM to create the Slide Deck.
A small episode led me to create two versions of the infographic: one based on NotebookLM's direct summary of the video, and one based on its summary of the YouTube-generated transcript.
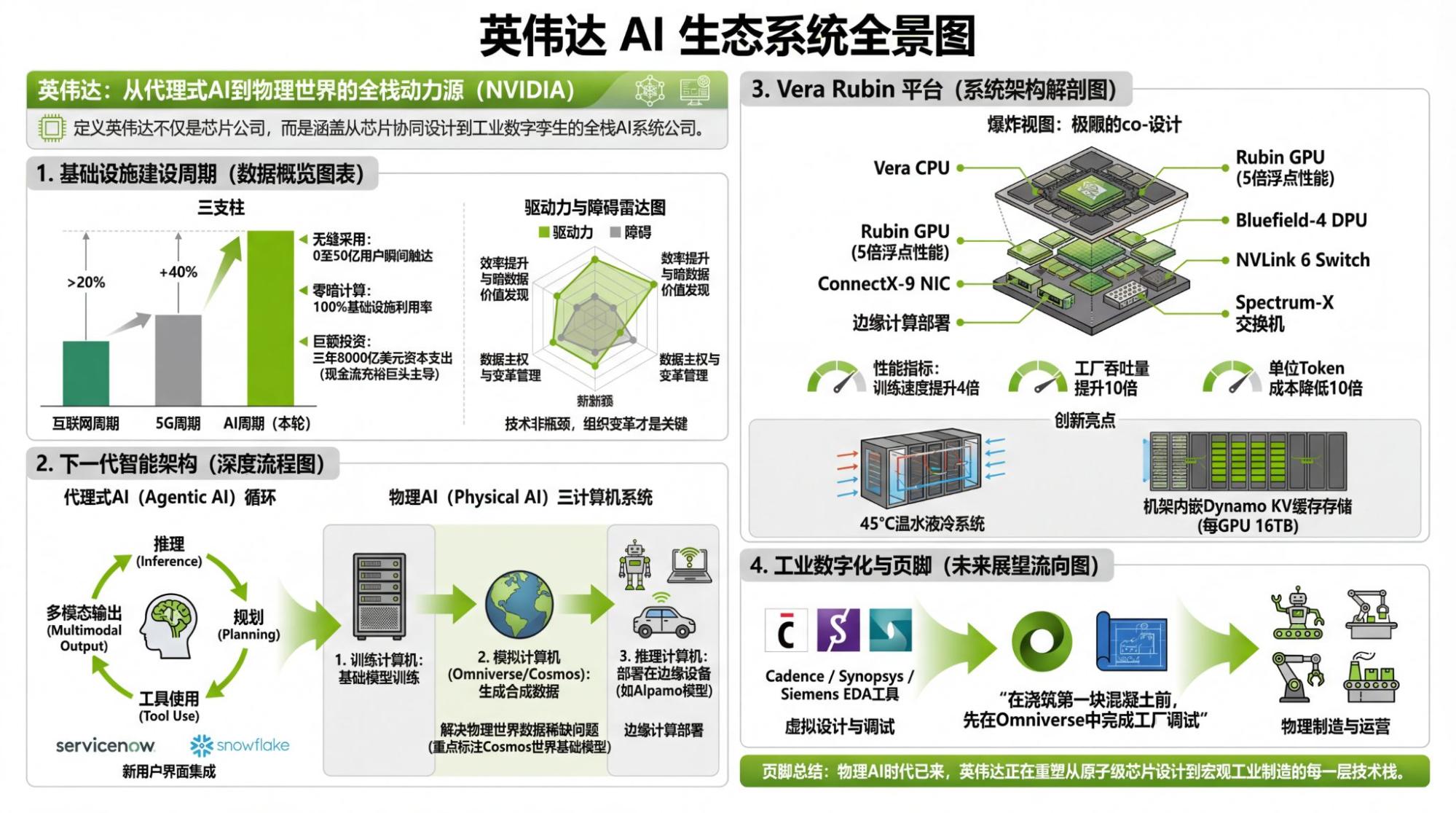
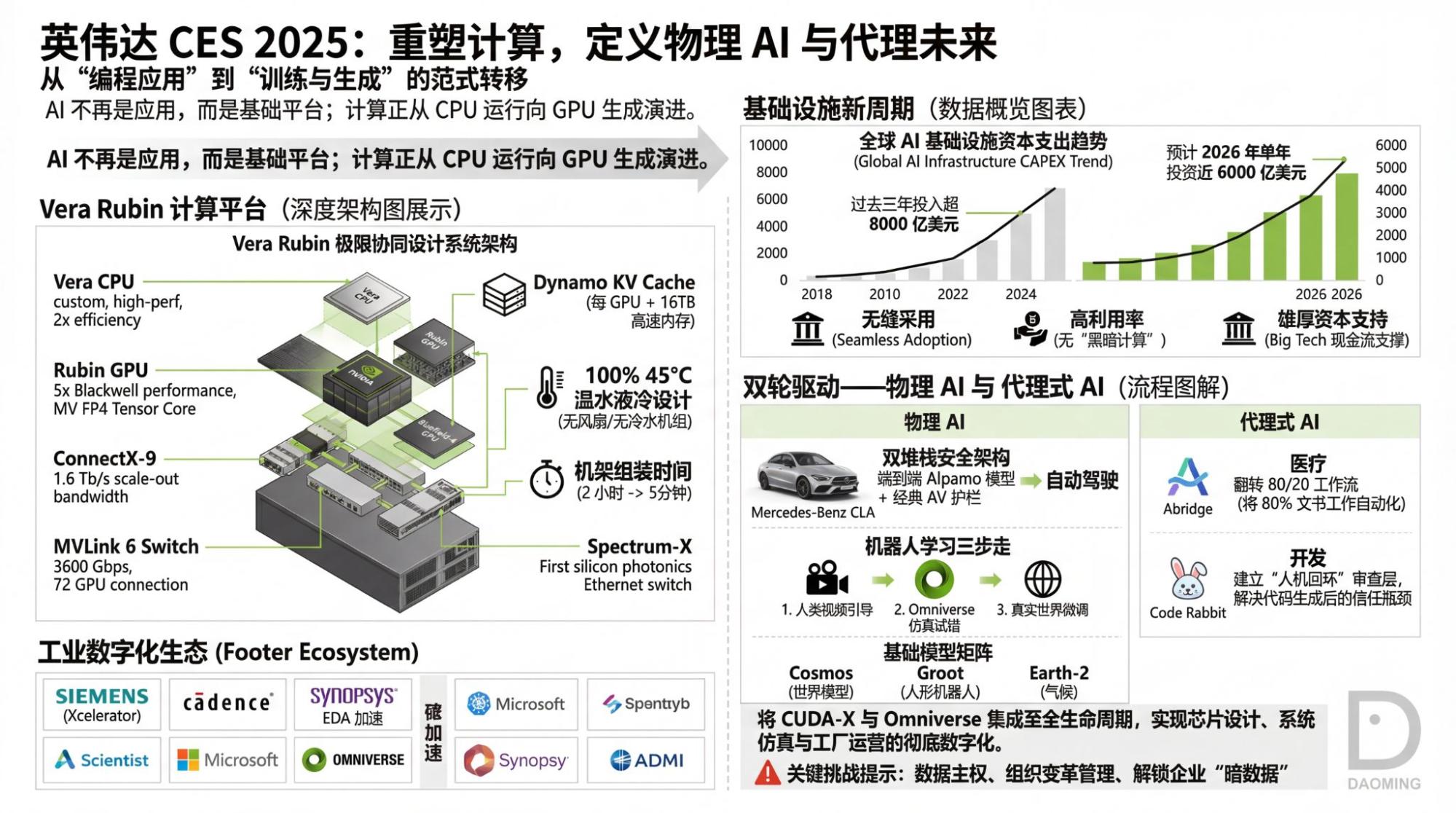
Objectively, I slightly prefer the second version (based on the YouTube transcript, though it contains an error where NVLink became MVLink—I checked, and it's in the transcript). It seems that for NotebookLM, reading text can process more information than watching video (under token limits). Of course, the error mentioned above clearly shows: the models we consider "intelligent" aren't actually "intelligent" at all.
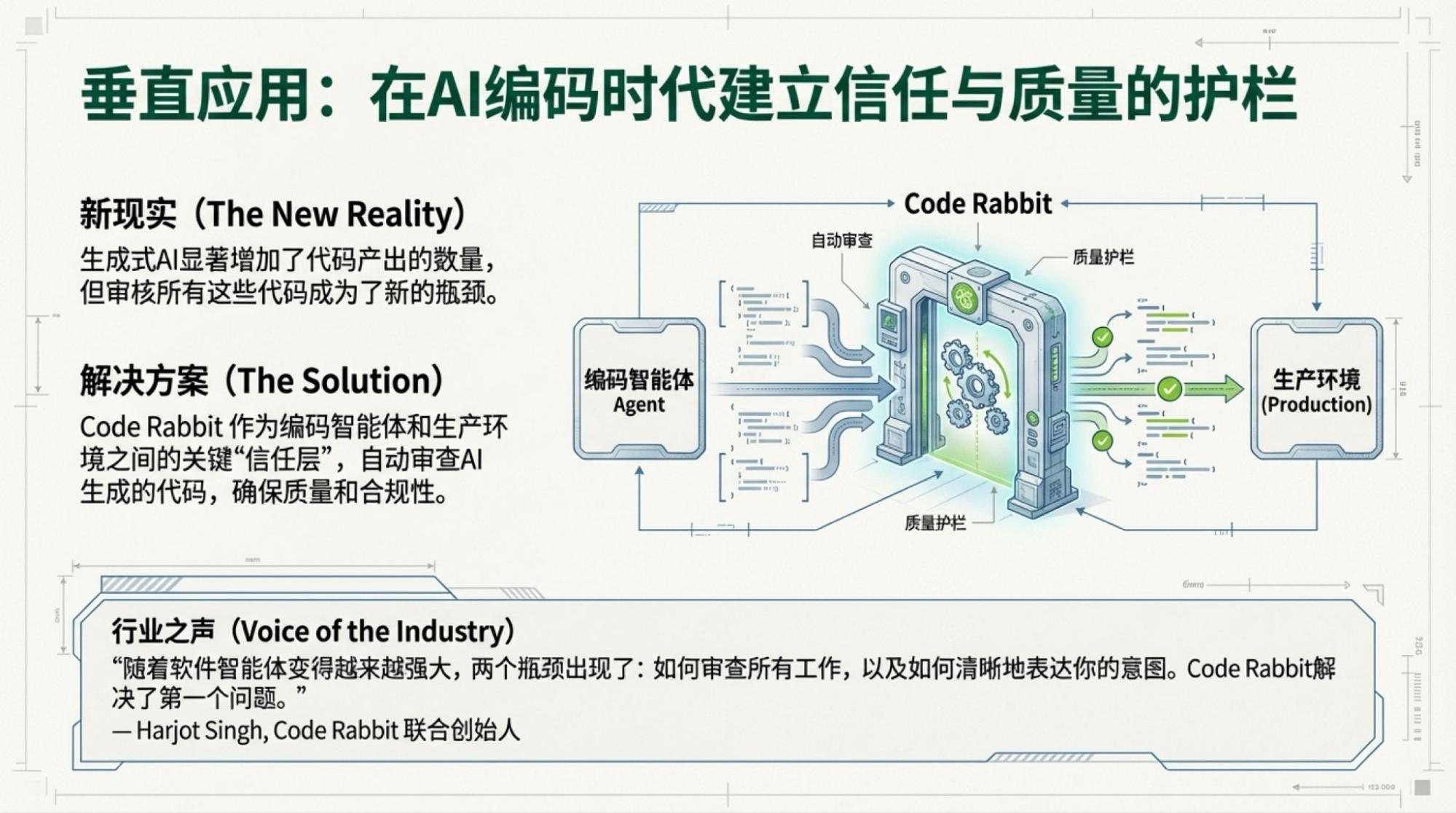
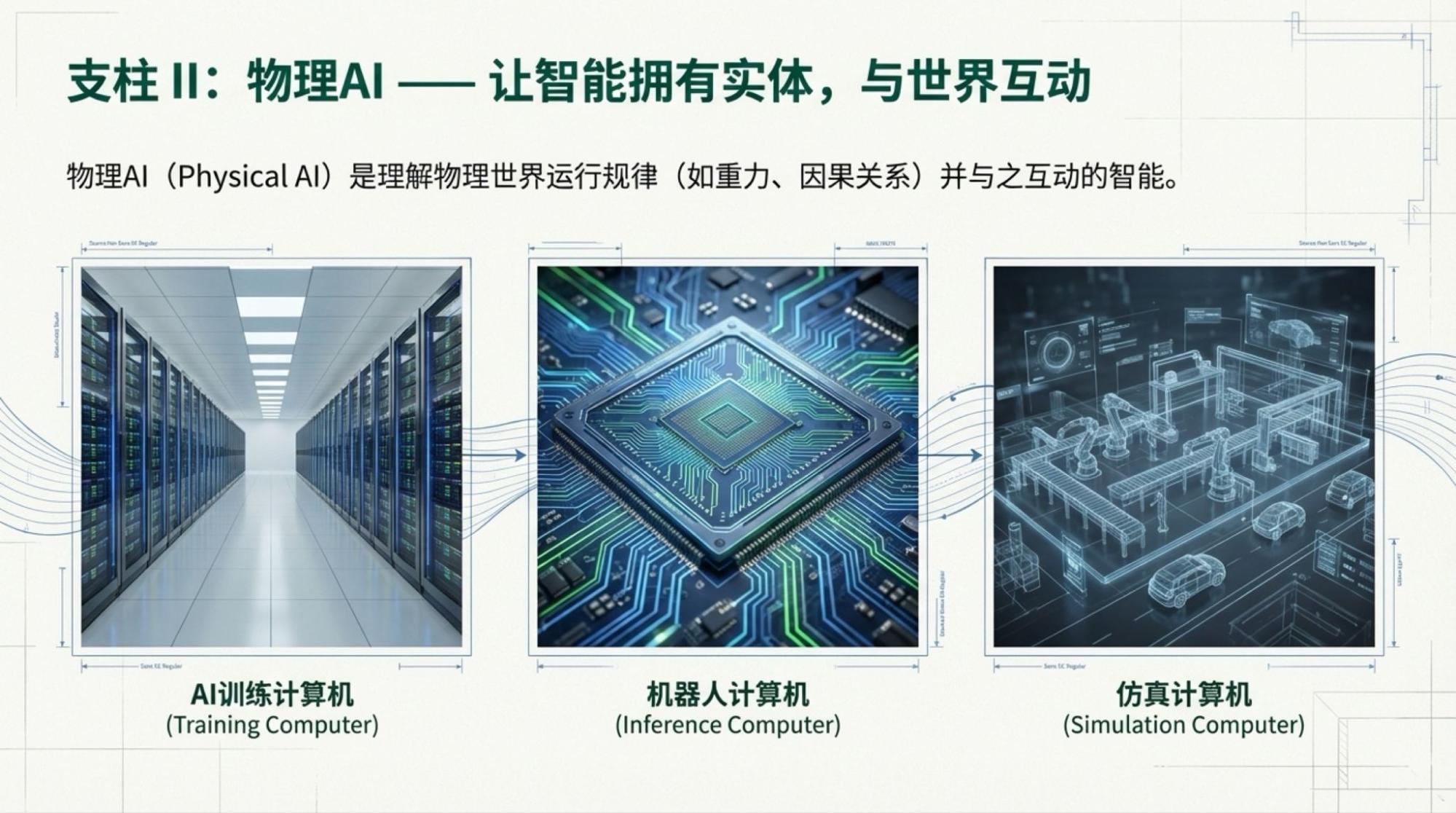
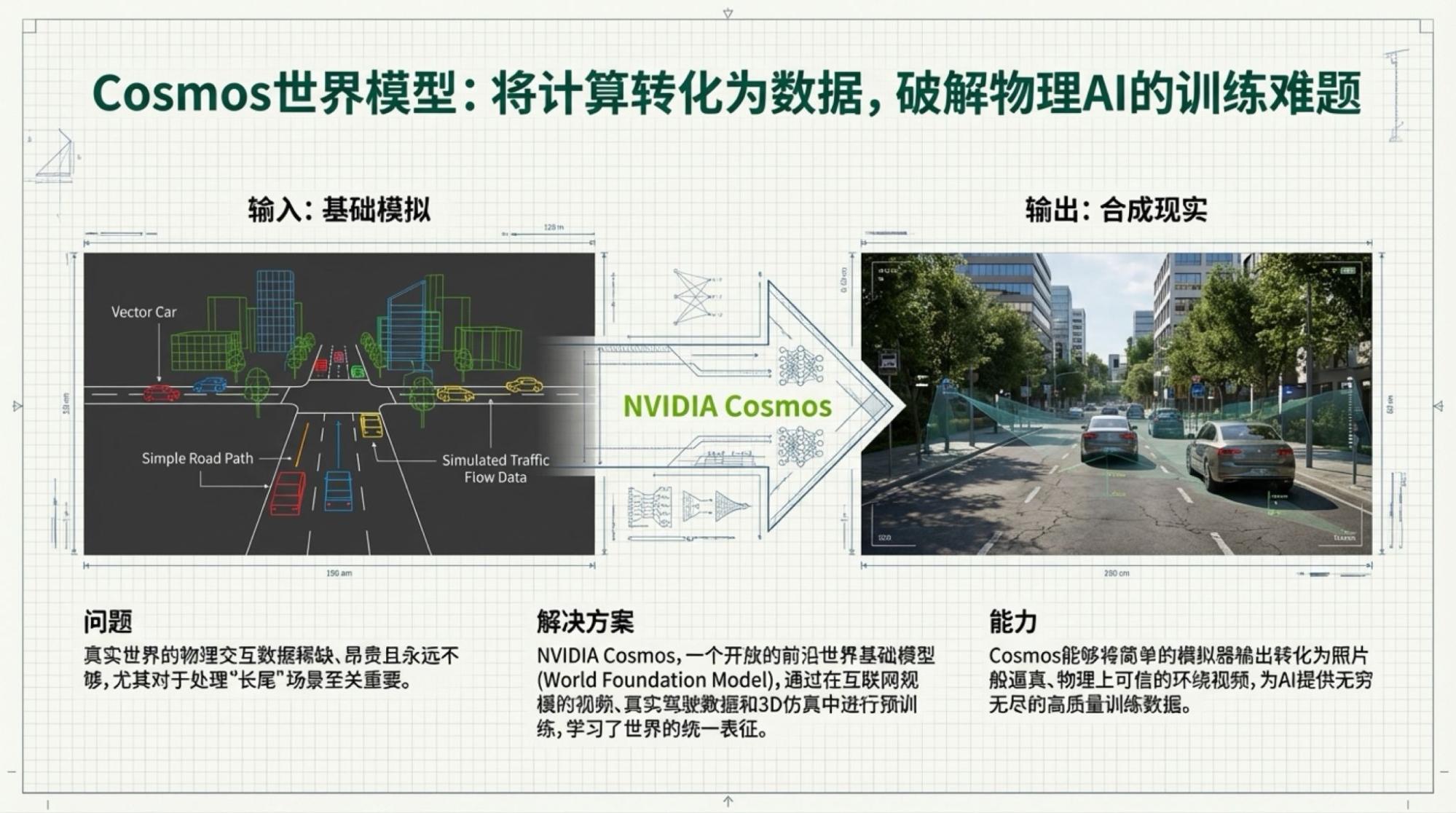
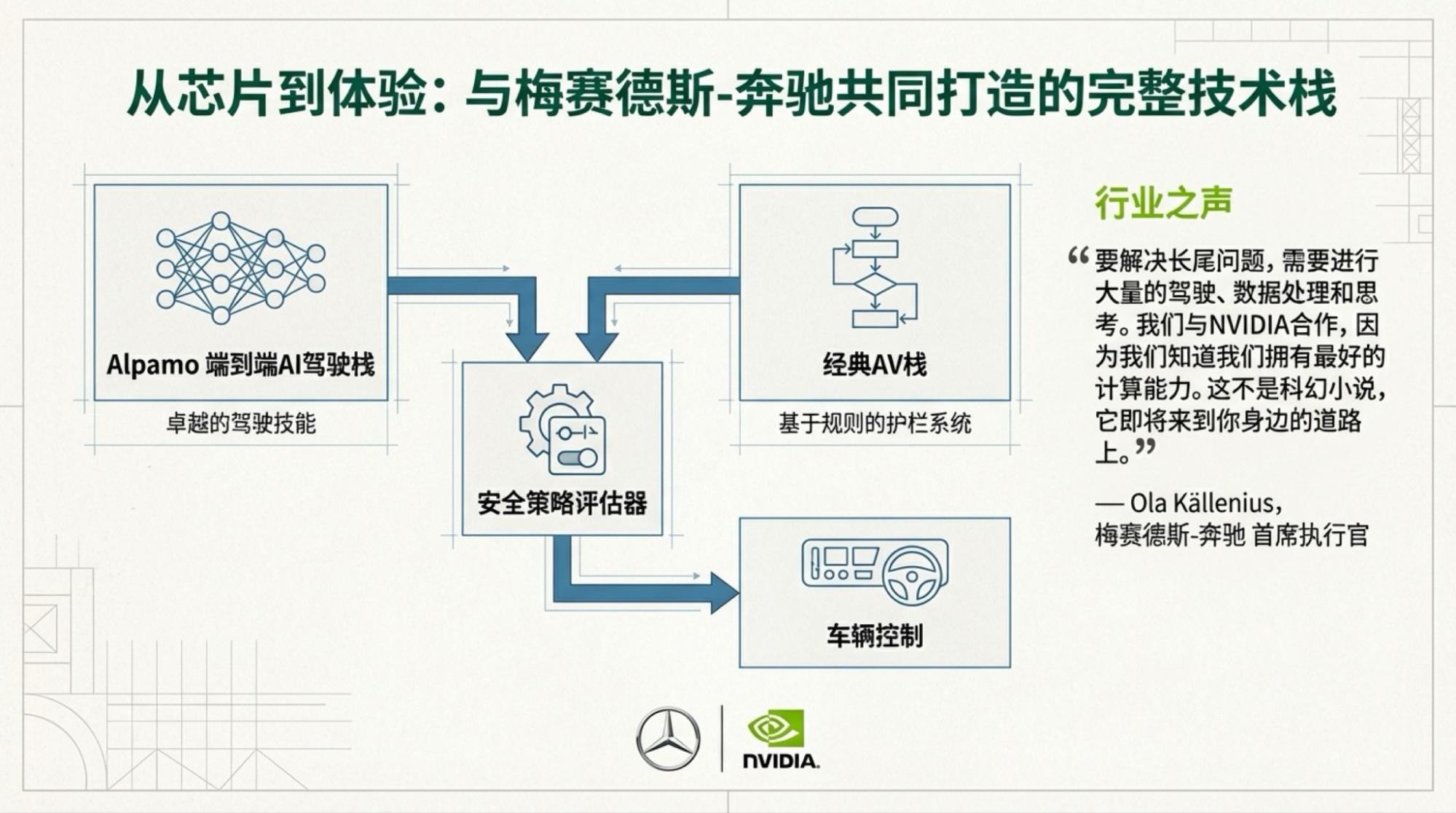
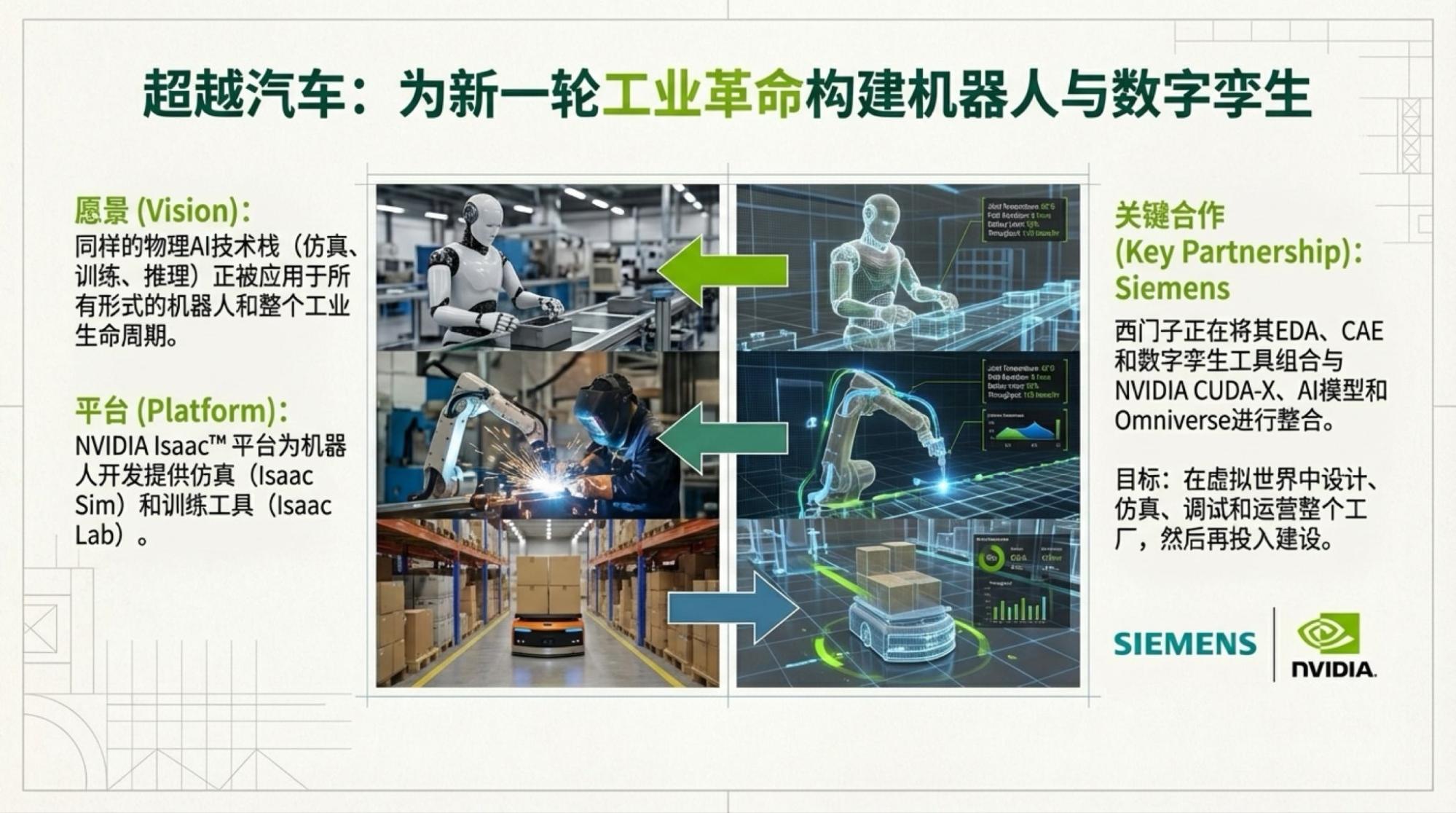
Below are the slides for each page, based on the video content.