Bubbling?
The existence of a bubble is obvious, but from an emotional standpoint, the current situation may differ significantly from history:
- AI investment is rapidly "Crypto-fying": Many neo-cloud providers transitioned from crypto mining. Practitioners' "obsession with the future" is increasingly similar to that of early Web3 practitioners.
- Nvidia's "Implicit Guarantee": Although the vast majority of revenue flows to Nvidia, the company is essentially providing a form of "implicit guarantee," which means a bubble "burst" might exhibit different characteristics.
- Big Tech Leverage: Tech giants are using their own revenue as leverage to provide substantial "collateral."
However, typical bubble characteristics are also present:
- High Depreciation Rates: Models become worthless if they aren't updated; the depreciation rate is very high.
- Compute Depreciation: The depreciation of computing power hardware is also extreme.
- Hypothesis-Driven Optimism: Much of the current "optimism" is built on the assumption that "AGI" will emerge before 2030. However, market scrutiny will become harsher every year, and a "liquidity crisis" under strict scrutiny could happen at any time.
While the market will always face these debates, the following discussion will remove as much emotional bias as possible.
From a fundamental perspective, the sector is divided into four layers and five aspects: Upstream (Energy and Data Center Equipment) and Storage (Memory, SSD, and HDD), Compute (TSM, Nvidia, AMD, Broadcom, and Google), Models, and AI Applications.
Multiple Layers of Cycles
First Layer: Revenue—Compute, Models, and AI Applications.
The market has passed the stage of just "telling AI stories." It now demands to see revenue growth exceeding expectations, user growth exceeding expectations, and gross margins remaining stable or even rising. In other words, the market needs "AI to appear more in revenue items rather than cost items." Consequently, the entire AI sector has entered a stage of "strict scrutiny" regarding revenue. Currently, the virtuous cycle from models to revenue hasn't fully formed. Model training still requires massive investment, and the seesaw effect between models and applications is becoming more apparent: the faster a model improves, the more applications are empowered, but costs also rise. If model progress slows, there might be more room for applications and faster cost reductions. This is the first very tricky point.
Personal View: Regardless of the speed of future model progress, the positioning of models as a new programming language has already "taken hold," and penetration will increase rapidly. Experience and knowledge in vertical markets are the most important competitive advantages, as these niche markets are difficult for big companies to enter. It is more likely that new business types will emerge.
Second Layer: Energy—Compute and Power.
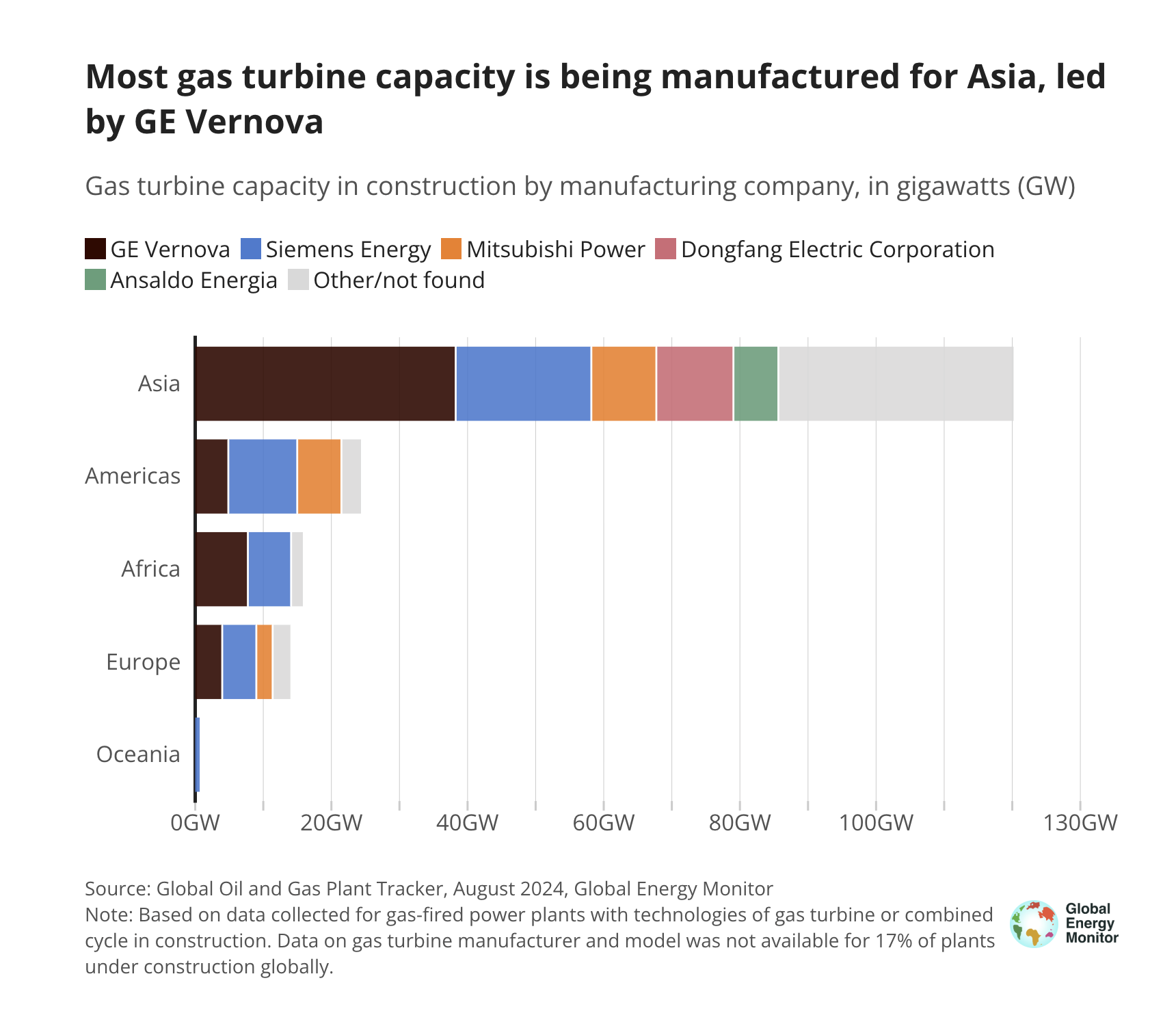
According to current CoWoS capacity forecasts, Blackwell shipments will be around 5 million units in 2025, and Blackwell + Rubin will exceed 7 million units in 2026. Calculating 1kW per unit, multiplied by 1.5 at the rack level, and considering a PUE of around 1.4, the new power demand for Blackwell + Rubin over two years = 12M × 1kW × 1.5 × 1.4 = 25.2GW. This doesn't even account for Google's TPU, AMD's MI series, Amazon's in-house chips, or chip exports to China.
GE Verona (Note: likely GE Vernova) and Siemens can each deliver over 10GW of gas turbine units annually, with a combined market share of 60%-70%, nearly 50% of which is linked to AI data centers. However, considering regional order distribution and the fact that many gas turbines are used to replace old coal power, there may only be a maximum of 30GW available for AI over two years. The actual power constraint is much more severe than imagined. This will lead to issues with the shipping cadence of Nvidia's Rubin.
Of course, if even Nvidia doesn't have "warm shells" for installation, then AMD needn't even be considered. Amazon's self-developed chips would also be affected, while Google would likely be less impacted.
Third Layer: Power and other AI Infra, Compute and Storage
In theory, all AI Infra prepared for data centers is in a super-strong upward cycle. However, there's a catch: the relevant supply chain could already foresee the current situation by late 2024, and much preliminary work has started. But just as GE Verona and others remain cautious about expansion, supporting enterprises will only fulfill based on order visibility. Therefore, opportunities will be structural.
Currently, the fastest-growing area is related to SOFC (Solid Oxide Fuel Cells).
Storage, however, is a completely different story: First, the logic for high-end HBM is obvious. Second, the high compute density of AI significantly increases the demand for low-to-mid-end memory in switches. Third, AI generates massive data access needs, so the shortage of SSDs and HDDs will persist. Furthermore, much storage will be added to traditional data centers, which won't be as directly affected by power shortages.
Fourth Layer: Models and Compute
This is a very complex issue that no one can clearly explain yet. Will higher compute power truly push AI toward AGI? This is an unfalsifiable path, so OpenAI is leading everyone down a road toward either destruction or success.
One difficult question: setting AGI aside, suppose at some point next year GPT-6 (assuming a 10x compute increase per generation) becomes even more powerful. Compute spending increases by 50%, but inference prices drop by 50%. To maintain the same gross margin for model services, model unit revenue must also drop by 50%, requiring usage to double just to break even. It would take triple the revenue to make the model training investment worthwhile. In a competitive environment, this is not an easy goal. Moreover, market expectations for OpenAI and Anthropic revenue are nearly doubling every year (4X annually) through 2028. From a pure usage standpoint, this growth seems possible, but monetization becomes increasingly difficult in a competitive landscape.
Another reality is that current models, supported by Agents, may already be capable of handling over 90% of scenarios. In the future, for cost reasons, users may opt for models that are not the most advanced, which adds greater uncertainty to revenue growth expectations.
Finally, regarding companies:
- T0: Google
- T1: Nvidia, TSM, MU
- T2: Apple, Microsoft, Amazon, AVGO
- Others to watch: NET, SNOW
- Moderate Avoidance: AMD, Meta
- Avoidance: Oracle, CoreWeave
Specifically, Nvidia > AMD: If power is scarce, compute investment will prioritize Nvidia, leaving very little capacity for AMD.