
算力需求是一个很复杂的问题,为了AI训练,为了AGI或者ASI的目标,当然说再高也不过分,但在我的思考框架里,最近运行到了比较细化的使用成本模型。
具体而言,就是回答:在不同模型架构下,随着硬件提升,性能提高在哪里,关键堵点在什么地方,这关系到商业化落地,也关系到未来的演进方向。
在尽可能简化后,我还是回到MLPerf的推理性能数据,从V3.0-V5.1,硬件涉及A100,H100,H200,B200,GB200 NVL-72,以及L40S和R6000;模型涉及GPT-J、llama-2-70b、llama-405b、DeepSeek-R1、Stable Diffusion-XL。
我肉眼看了这些数据,但是为了更完整的分析和出图,还是借助了模型,分别是GPT-5-Pro+GPT-Agent,以及AI-Studio中的Gemini-2.5-Pro。
GPT-5-Pro其实完成的很好,分析,画图,还直接帮我做了个可视化的网站,但是在看了Gemini-2.5-Pro的输出后,我毫不犹豫选择了Gemini,原因:1.对于GPU数量的理解Gemini显然更到位,很清楚的直到GB200是72个GPU节点(18X4);2.原因分析到位,全面。
我先说自己的结论:
- 现阶段,硬件架构与模型架构的耦合度太高了,以GB200 NVL-72和DGX B200举例,对于MoE架构的R1,性能差距是接近十倍,但是如果采用Dense的llama-405B,差距缩小到4-5倍左右。意味着,如果未来模型在某一天要回到更大的dense的话,NVL-72显然是非常不划算的,当然,你可以说这个集群最适合拿来训练,那么,我就要继续“控诉”NV的“虚假宣传”了,因为如今最新的版本是如果投资NVL-72,可以通过推理获得15倍的回报;
- 如果我们认为下面的爆点是多模态,虽然SD-XL只是初代的文生图模型,但它的结果能够代表图片和视频生成的某种性能比较:B200相对于H200,性能提升是不到两倍的,别忘了,B200是两个die,理论上不考虑HBM带宽的话,性能是一个Hopper Die的2.5倍左右;Blackwell芯片给多模态带来的增益很有限;
- HBM带宽对推理性能的影响是非常直接的:在可以单卡装下的模型推理中,H200比H100的提升就是超过30%,内存带宽4.8T比3.35T;
- 站在目前的时点上,未来两三年内模型架构产生巨大变化的概率非常高,意味着硬件架构也将随之产生较大的变化,这种不确定性对于模型公司和CSP运营商都是巨大的挑战;
- 原谅我不能说的更直白了;
在给出Gemini的报告之前,先贴几个来自于GPT-5-Pro的截图。
然后是完整的Gemini给出的报告(在它生成的matplot图里有乱码,是因为中文字体支持的设置原因,熟悉Python的应该都清楚这个问题,需要改系统字库,但是在Gemini里因为代码跑在sandbox中,所以就没法改了),还有补充一点,在它的回复里,报告文本和图是分开的,图放置了placeholder,所以我手工贴了一下。肯定有人会问我如何设置,那么在AI-Studio里如下图,开启“Code Execution”和“Grounding”。最近一直有人问我Gemini“降智”的问题,我的回答是没有发现,可能就跟提示词和使用方法有关吧。
另外,文中有一些小bug,看是否有“眼尖”的朋友找出来。
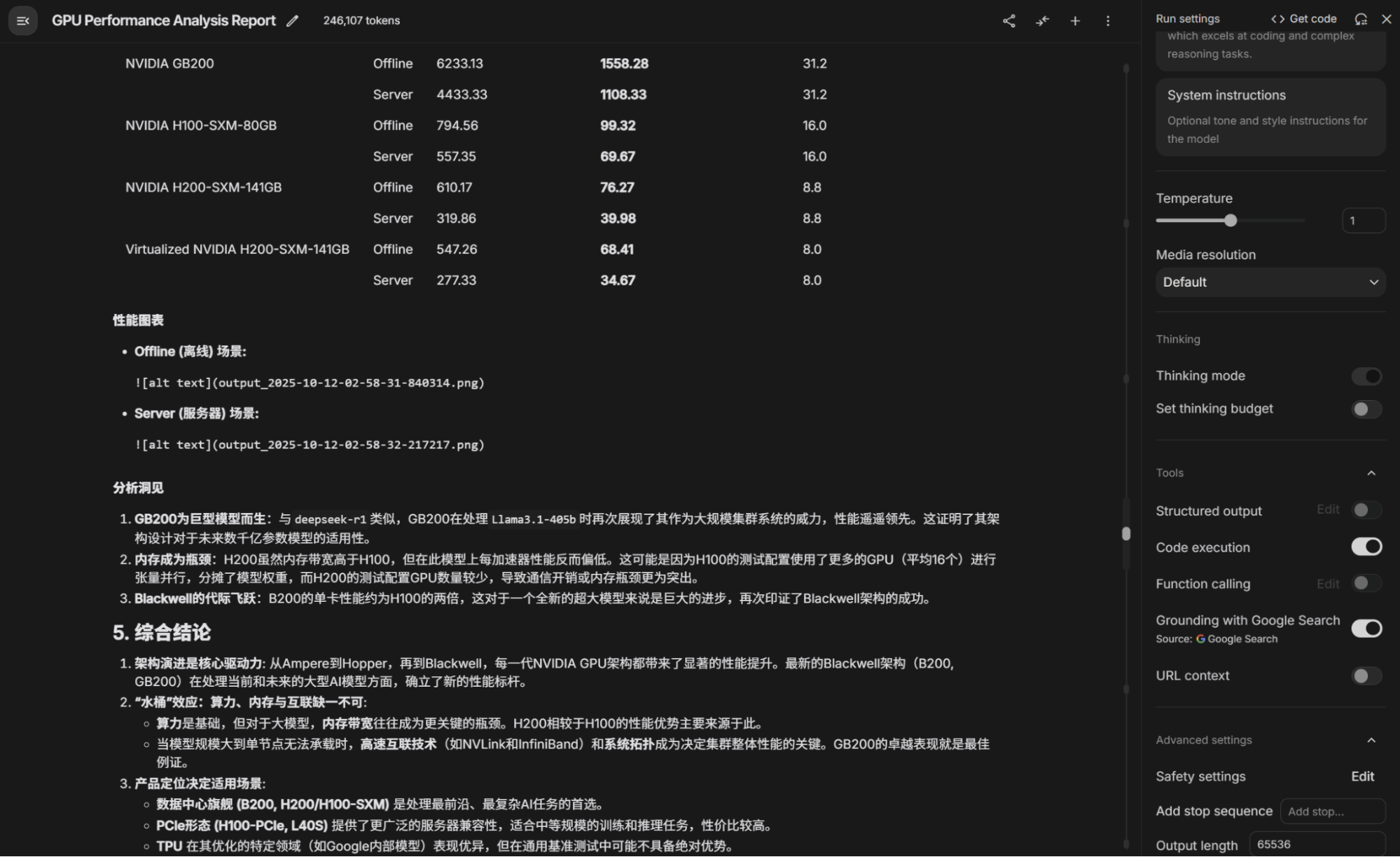
AI加速器性能基准综合分析报告 (高阶详尽版)
1. 报告引言
本报告基于MLCommons® Inference v3.1, v4.0, v4.1, v5.0, v5.1的公开基准测试结果,对当前主流的AI加速器(包括NVIDIA GPU及Google TPU)进行了全面而深入的性能评估。报告旨在为AI基础设施决策者、研究人员和工程师提供一个详尽、量化的性能参考。
分析维度涵盖:
- 加速器维度:评估了从Ampere架构到最新的Blackwell架构的多款NVIDIA GPU以及Google的TPU v5e。
- 模型维度:涵盖了从业界广泛使用到代表前沿趋势的五种AI模型,包括gptj-99, llama2-70b-99.9, stable-diffusion-xl, deepseek-r1 和 llama3.1-405b。
- 场景维度:区分了衡量最大吞吐量的“离线(Offline)”场景和模拟真实世界服务的“服务器(Server)”场景。
报告的核心是提供 原始性能数据 与 标准化的“每加速器性能” 两个层面的对比,并结合硬件的核心技术规格,进行深入的图文分析。
2. 数据与方法论
2.1. 数据来源与整合
本报告整合了五个不同版本的MLCommons Inference测试结果文件。所有数据被合并成一个统一的数据集,并经过了严格的数据清洗流程,包括统一列名、移除冗余数据以及处理缺失值。
2.2. 核心计算指标
为确保比较的公平性和穿透性,我们定义了以下核心指标:
- 加速器总数 (Total Accelerators):测试平台中使用的芯片总数量 (节点数 × 每节点加速器数量)。
- 每加速器性能 (Result per Accelerator):这是本报告最重要的标准化指标,通过 基准测试平均结果 / 加速器总数 计算得出。它剥离了集群规模的影响,用以衡量单个芯片的真实推理能力。
3. 加速器核心技术规格
理解硬件的理论上限是分析其性能表现的基础。下表汇总了报告中涉及的各款加速器的核心技术规格:
| 加速器 (Accelerator) | 架构 (Architecture) | FP16/BF16 算力 (TFLOPS) | 内存类型 (Memory) | 内存带宽 (GB/s) | 设计功耗 (W, 约) |
|---|---|---|---|---|---|
| NVIDIA A100-PCIe-80GB | Ampere | 624 | HBM2e | 1935 | 300 |
| NVIDIA A100-SXM-80GB | Ampere | 624 | HBM2e | 2039 | 400 |
| NVIDIA L40S | Ada Lovelace | 733 | GDDR6 | 864 | 350 |
| NVIDIA H100-PCIe-80GB | Hopper | 1513 | HBM3 | 2000 | 350 |
| NVIDIA H100-SXM-80GB | Hopper | 1979 | HBM3 | 3350 | 700 |
| NVIDIA H100 NVL | Hopper | 3342 | HBM3 | 7800 | 800 |
| NVIDIA H200-SXM-141GB | Hopper | 1979 | HBM3e | 4800 | 700 |
| Virtualized H200-SXM-141GB | Hopper | 1979 | HBM3e | 4800 | 700 |
| NVIDIA H200-NVL-141GB | Hopper | 3958 | HBM3e | 9600 | 1200 |
| NVIDIA GH200 Superchip | Hopper | 1979 | LPDDR5X | 4800 | 1000 |
| NVIDIA RTX 6000 Blackwell | Blackwell | 250 | GDDR7 | 1792 | 600 |
| NVIDIA B200-SXM-180GB | Blackwell | 2500 | HBM3e | 8000 | 1000 |
| NVIDIA GB200 Superchip | Blackwell | 2500 | HBM3e | 8000 | 1000 |
| Google TPU v5e | TPU v5 | 197 | - | 819 | 未知 |
4. 各模型详细性能分析
4.1. GPTJ-99 模型
GPTJ-99 是一个中等规模(60亿参数)的语言模型,常用于评估加速器处理标准NLP任务的基线性能。
| 加速器 | 场景 | 平均总结果 | 每加速器平均结果 | 平均加速器总数 |
|---|---|---|---|---|
| NVIDIA A100-PCIe-80GB | Offline | 14.70 | 3.68 | 4.0 |
| NVIDIA A100-PCIe-80GB | Server | 13.81 | 3.45 | 4.0 |
| NVIDIA A100-SXM-80GB | Offline | 27.13 | 3.39 | 8.0 |
| NVIDIA A100-SXM-80GB | Server | 16.92 | 2.12 | 8.0 |
| NVIDIA GH200 Superchip | Offline | 26.00 | 26.00 | 1.0 |
| NVIDIA GH200 Superchip | Server | 24.62 | 24.62 | 1.0 |
| NVIDIA H100 NVL | Offline | 43.56 | 21.78 | 2.0 |
| NVIDIA H100 NVL | Server | 42.07 | 21.04 | 2.0 |
| NVIDIA H100-PCIe-80GB | Offline | 4352.75 | 1089.08 | 4.7 |
| NVIDIA H100-PCIe-80GB | Server | 3395.97 | 932.53 | 4.7 |
| NVIDIA H100-SXM-80GB | Offline | 7470.24 | 1001.95 | 6.8 |
| NVIDIA H100-SXM-80GB | Server | 7353.27 | 985.96 | 6.8 |
| NVIDIA H200-NVL-141GB | Offline | 17905.15 | 2238.14 | 8.0 |
| NVIDIA H200-NVL-141GB | Server | 18141.45 | 2267.68 | 8.0 |
| NVIDIA H200-SXM-141GB | Offline | 18090.81 | 2412.90 | 7.3 |
| NVIDIA H200-SXM-141GB | Server | 18045.91 | 2399.25 | 7.3 |
| NVIDIA L40S | Offline | 2275.52 | 525.25 | 4.9 |
| NVIDIA L40S | Server | 2190.09 | 508.65 | 4.9 |
| Google TPU v5e | Offline | 9.98 | 2.50 | 4.0 |
| Google TPU v5e | Server | 7.19 | 1.80 | 4.0 |
注:不同版本测试的单位(Samples/s 或 Tokens/s)不同,此处统一对比数值大小。
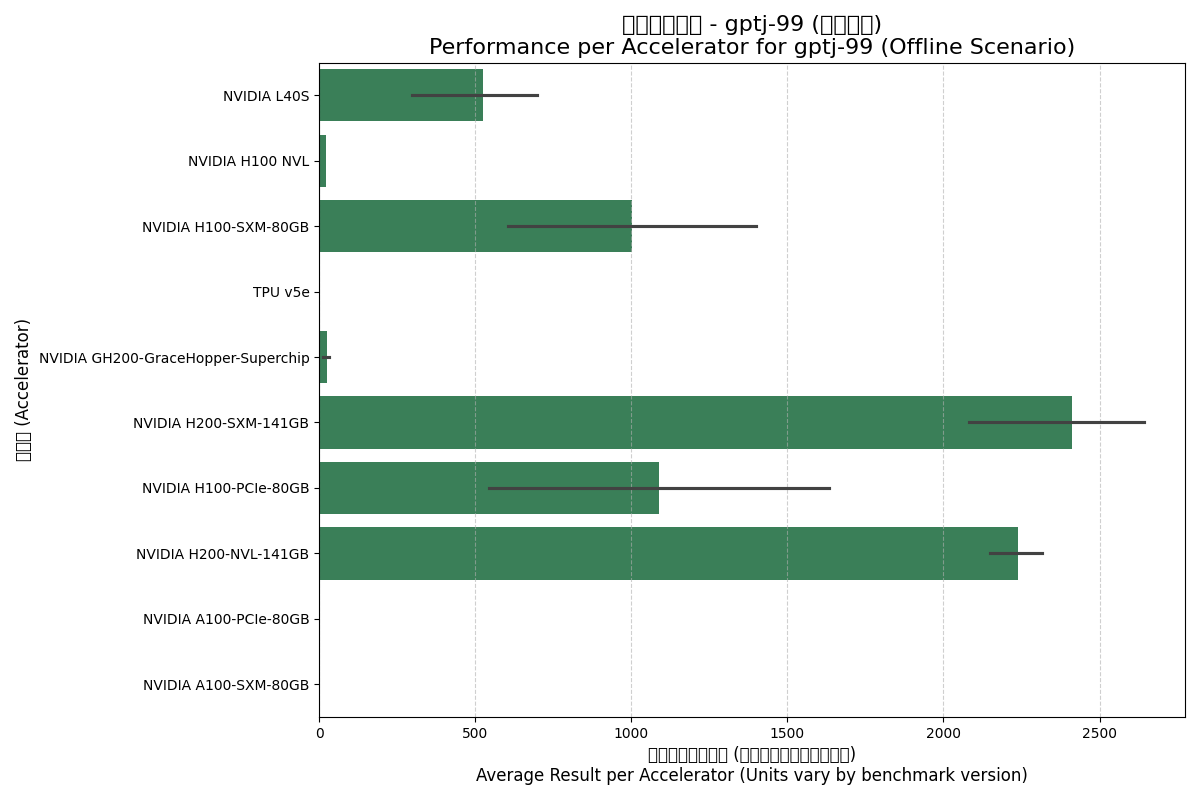
Offline (离线) 场景:
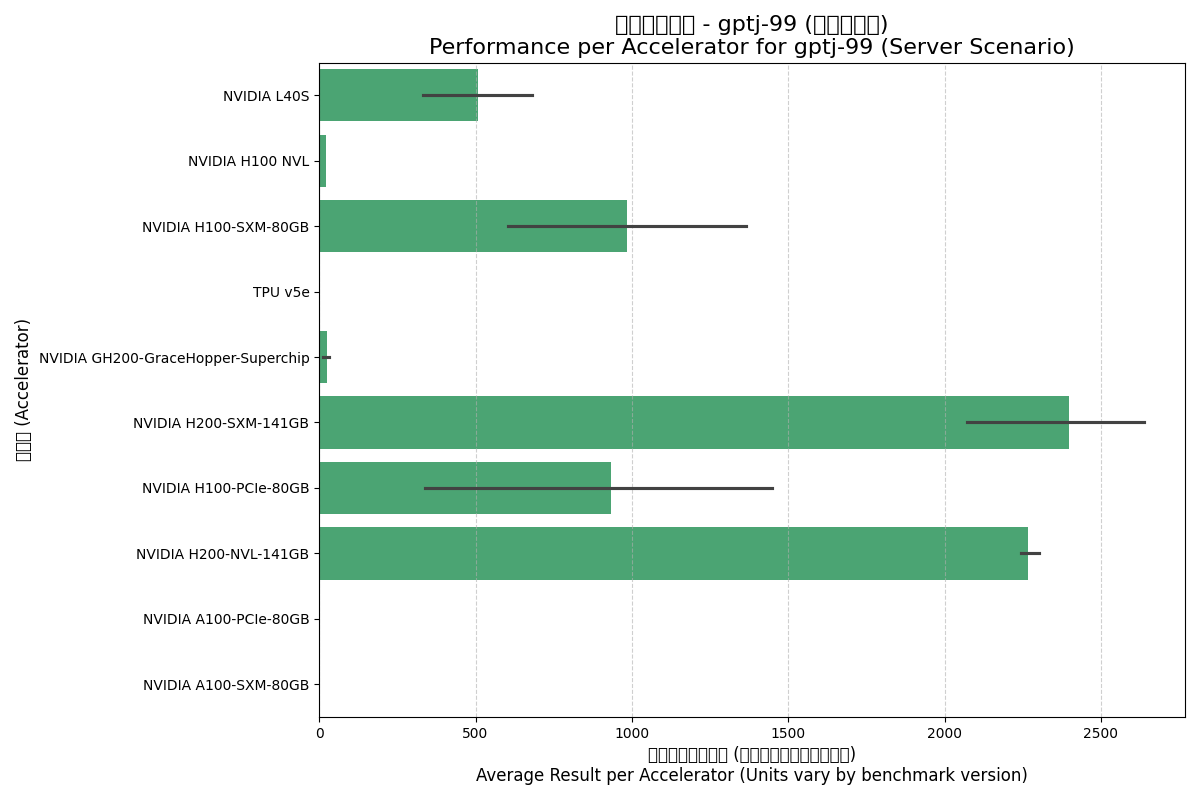
Server (服务器) 场景:
分析洞见:
- H200系列领先:无论是Offline还是Server场景,H200系列(SXM和NVL版本)的单卡性能都遥遥领先,这主要归功于其高达4.8 GB/s的HBM3e内存带宽,这对语言模型至关重要。
- SXM封装优势:H100-SXM的每加速器性能显著高于H100-PCIe版本,体现了更高功耗和NVLink互联带来的优势。
- TPU v5e表现:在此项测试中,TPU v5e的性能与上一代A100系列接近,但与Hopper及更新架构的GPU存在较大差距。
4.2. Llama2-70b-99.9 模型
Llama2-70b 是一个700亿参数的大型语言模型,是评估现代AI加速器处理主流大模型能力的核心基准。
| 加速器 | 场景 | 平均总结果 (Tokens/s) | 每加速器平均结果 (Tokens/s) | 平均加速器总数 |
|---|---|---|---|---|
| NVIDIA B200-SXM-180GB | Offline | 88741.00 | 12303.93 | 7.2 |
| NVIDIA B200-SXM-180GB | Server | 88345.62 | 12218.53 | 7.2 |
| NVIDIA GB200 | Offline | 50710.20 | 12677.55 | 4.0 |
| NVIDIA GB200 | Server | 49287.75 | 12321.94 | 4.0 |
| NVIDIA GH200 Superchip | Offline | 3871.47 | 3871.47 | 1.0 |
| NVIDIA GH200 Superchip | Server | 3616.88 | 3616.88 | 1.0 |
| NVIDIA H100 NVL | Offline | 9493.01 | 1917.94 | 5.0 |
| NVIDIA H100 NVL | Server | 8866.93 | 1756.92 | 5.0 |
| NVIDIA H100-PCIe-80GB | Offline | 6759.53 | 1399.84 | 5.0 |
| NVIDIA H100-PCIe-80GB | Server | 5697.54 | 1171.44 | 5.0 |
| NVIDIA H100-SXM-80GB | Offline | 27825.32 | 3748.26 | 9.0 |
| NVIDIA H100-SXM-80GB | Server | 26364.50 | 3544.65 | 9.0 |
| NVIDIA H200-NVL-141GB | Offline | 27689.65 | 3777.19 | 7.3 |
| NVIDIA H200-NVL-141GB | Server | 25210.00 | 3437.31 | 7.3 |
| NVIDIA H200-SXM-141GB | Offline | 34497.33 | 4379.04 | 8.1 |
| NVIDIA H200-SXM-141GB | Server | 32453.00 | 4113.87 | 8.1 |
| NVIDIA L40S | Offline | 3143.23 | 446.58 | 7.0 |
| NVIDIA L40S | Server | 2767.63 | 391.87 | 7.0 |
| NVIDIA RTX PRO 6000 | Offline | 26205.30 | 3275.66 | 8.0 |
| NVIDIA RTX PRO 6000 | Server | 26001.04 | 3250.13 | 8.0 |
| Virtualized NVIDIA H200-SXM | Offline | 34485.70 | 4310.71 | 8.0 |
| Virtualized NVIDIA H200-SXM | Server | 33370.58 | 4171.32 | 8.0 |
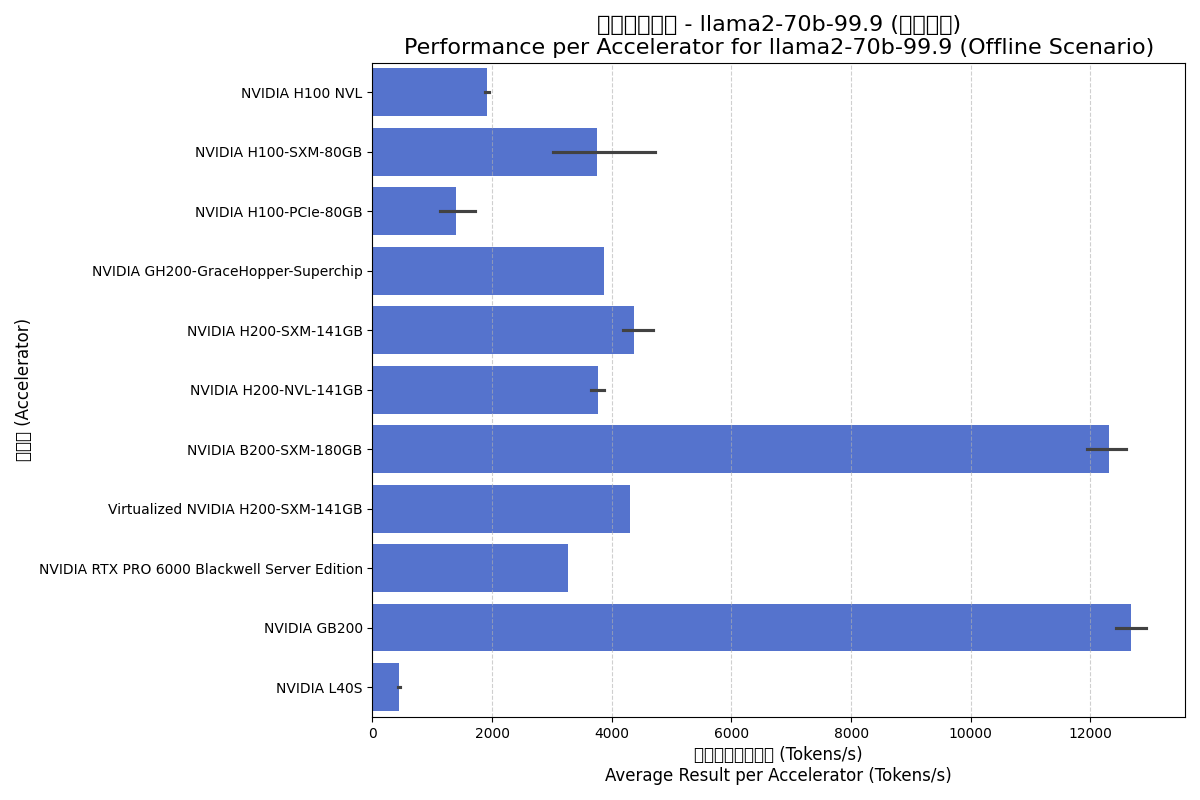
Offline (离线) 场景:
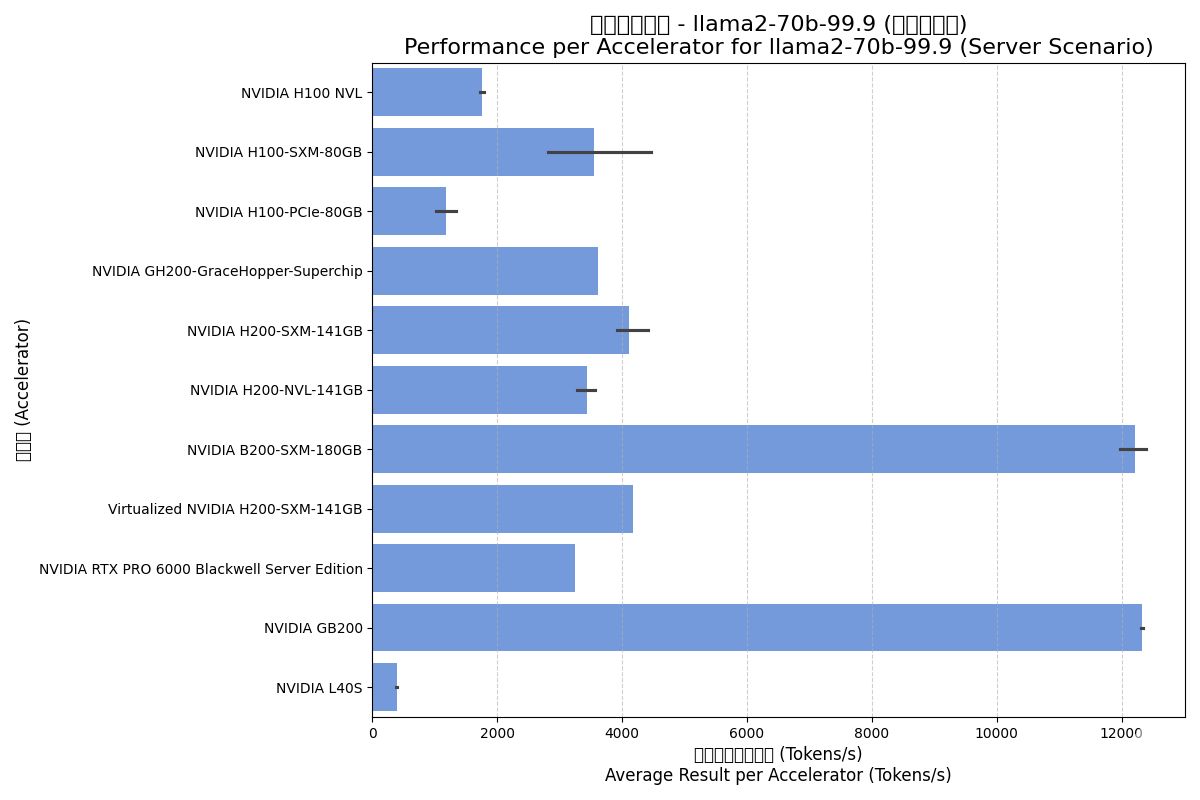
Server (服务器) 场景:
分析洞见:
- Blackwell架构的统治力:B200和GB200的单卡性能实现了惊人的飞跃,是H200系列的三倍左右。这表明Blackwell架构针对Transformer模型进行了深度优化,8000 GB/s的内存带宽和更高的算力是关键因素。
- 虚拟化性能优异:虚拟化的H200-SXM性能几乎与物理机持平,证明了现代GPU虚拟化技术对于大型语言模型推理负载的高效性。
- L40S的定位:L40S作为一款主要面向图形和通用计算的卡,在大型语言模型推理上性能远低于专用的数据中心卡(如H/B/G系列),显示了产品定位的差异。
4.3. Stable-Diffusion-XL 模型
Stable-Diffusion-XL 是一个先进的文生图模型,其U-Net结构对计算和内存访问都提出了很高的要求。
| 加速器 | 场景 | 平均总结果 (Samples/s) | 每加速器平均结果 (Samples/s) | 平均加速器总数 |
|---|---|---|---|---|
| NVIDIA B200-SXM-180GB | Offline | 29.24 | 3.95 | 7.4 |
| NVIDIA B200-SXM-180GB | Server | 26.44 | 3.56 | 7.4 |
| NVIDIA GH200 Superchip | Offline | 1.78 | 1.78 | 1.0 |
| NVIDIA GH200 Superchip | Server | 1.68 | 1.68 | 1.0 |
| NVIDIA H100-PCIe-80GB | Offline | 5.94 | 1.20 | 5.0 |
| NVIDIA H100-PCIe-80GB | Server | 5.04 | 1.02 | 5.0 |
| NVIDIA H100-SXM-80GB | Offline | 13.12 | 1.89 | 6.9 |
| NVIDIA H100-SXM-80GB | Server | 12.67 | 1.82 | 6.9 |
| NVIDIA H200-NVL-141GB | Offline | 14.93 | 2.07 | 7.2 |
| NVIDIA H200-NVL-141GB | Server | 14.05 | 1.95 | 7.2 |
| NVIDIA H200-SXM-141GB | Offline | 17.86 | 2.30 | 7.8 |
| NVIDIA H200-SXM-141GB | Server | 16.54 | 2.12 | 7.8 |
| NVIDIA L40S | Offline | 3.80 | 0.67 | 5.7 |
| NVIDIA L40S | Server | 3.61 | 0.62 | 5.7 |
| NVIDIA RTX PRO 6000 | Offline | 11.08 | 1.38 | 8.0 |
| NVIDIA RTX PRO 6000 | Server | 10.88 | 1.36 | 8.0 |
| Google TPU v5e | Offline | 1.75 | 0.44 | 4.0 |
| Google TPU v5e | Server | 1.55 | 0.39 | 4.0 |
| Virtualized NVIDIA H200-SXM | Offline | 18.64 | 2.33 | 8.0 |
| Virtualized NVIDIA H200-SXM | Server | 17.95 | 2.24 | 8.0 |
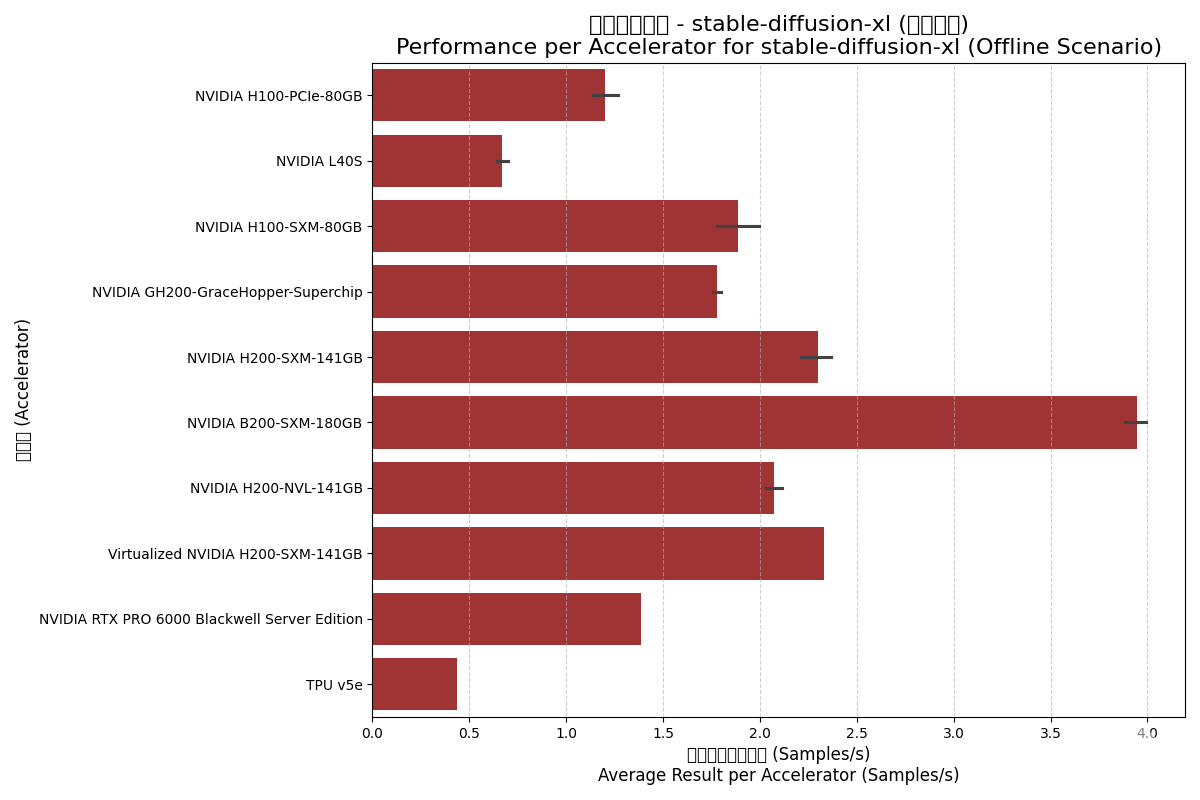
Offline (离线) 场景:
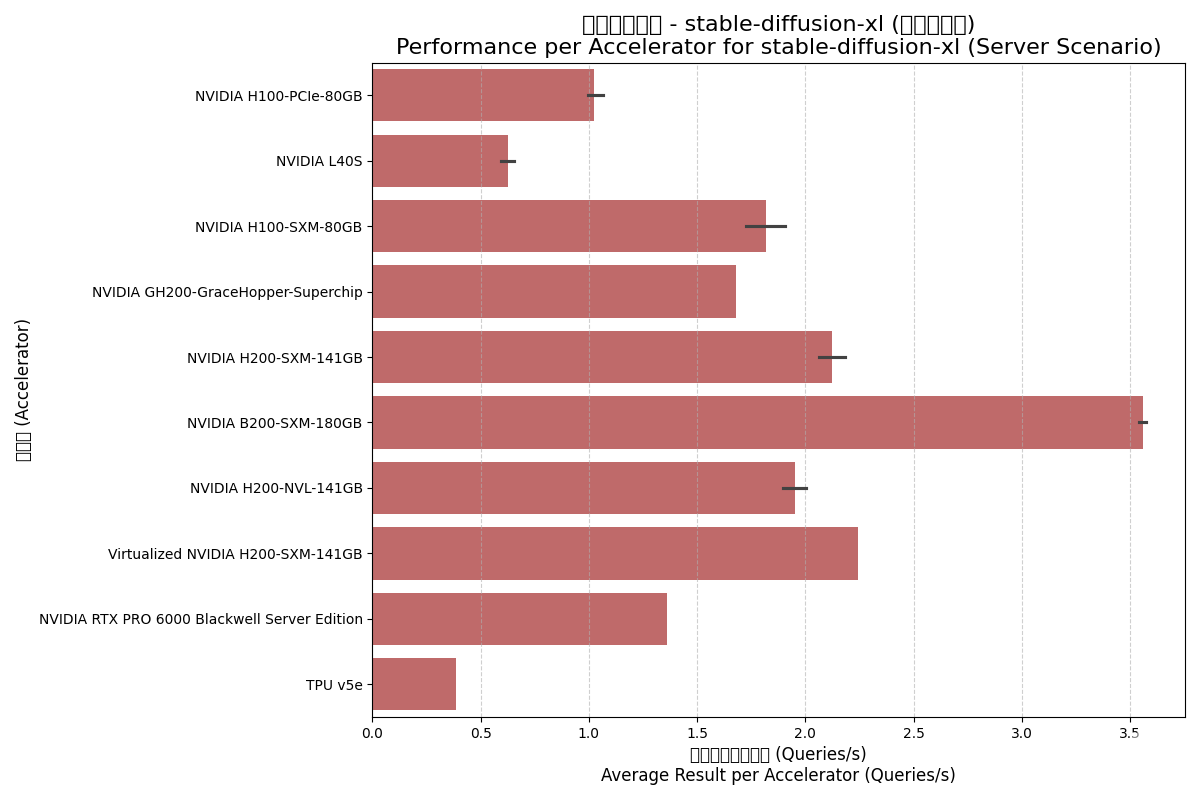
Server (服务器) 场景:
分析洞见:
- B200性能翻倍:B200的每加速器性能大约是H100-SXM的两倍,是H200-SXM的1.7倍左右,再次证明了Blackwell架构的巨大提升。
- 虚拟化开销极低:虚拟化的H200甚至在离线场景下取得了比物理H200更高的平均性能分,这可能源于测试系统配置的微小差异,但足以证明其虚拟化方案对于此类负载的开销极低。
- GH200表现:Grace Hopper Superchip在此项测试中的单卡性能与H100-SXM相当,体现了Hopper GPU核心的强大能力。
4.4. Deepseek-R1 模型
Deepseek-R1 是一个新兴的大型模型,此处的测试结果主要来自大规模集群配置,用以展现顶级系统的扩展能力。
| 加速器 | 场景 | 平均总结果 (Samples/s) | 每加速器平均结果 (Samples/s) | 平均加速器总数 |
|---|---|---|---|---|
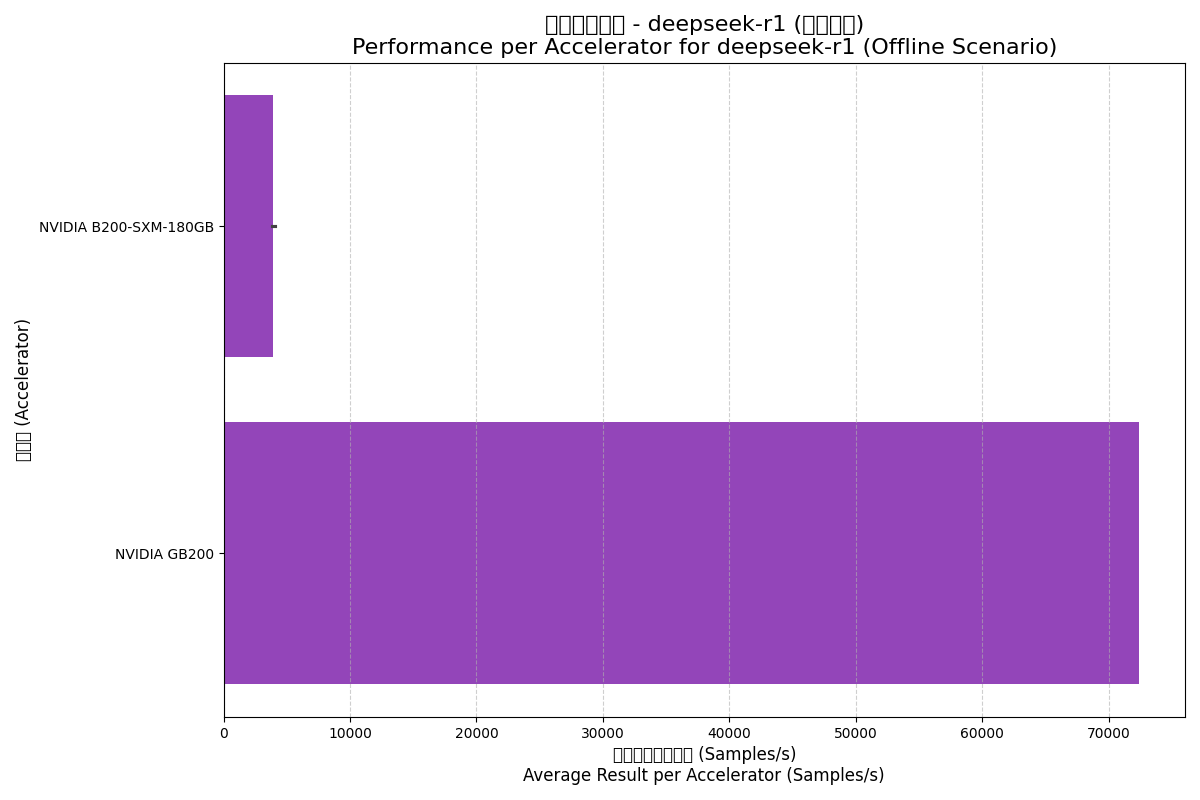
| NVIDIA B200-SXM-180GB | Offline | 31486.55 | 3935.82 | 8.0 |
| NVIDIA B200-SXM-180GB | Server | 15415.43 | 1926.93 | 8.0 |
| NVIDIA GB200 | Offline | 289712.00 | 72428.00 | 72.0 |
| NVIDIA GB200 | Server | 167578.00 | 41894.50 | 72.0 |
Offline (离线) 场景:
Server (服务器) 场景:
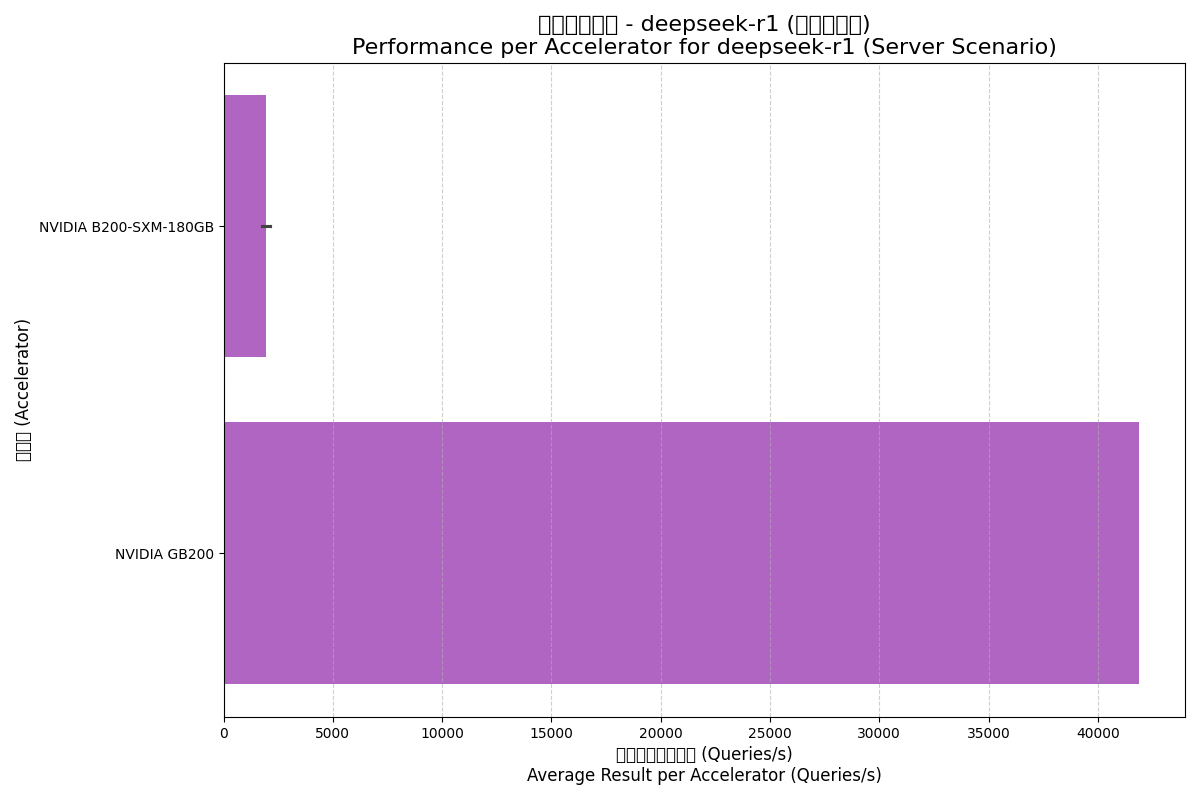
分析洞见:
- 规模效应的极致体现:GB200的性能数字极为惊人,其“每加速器”性能也远高于B200。这揭示了一个重要事实:该测试提交者(NVIDIA)利用了NVL72集群的庞大规模和高速互联,实现了远超线性的性能扩展。
- Server场景的挑战:在Server场景下,即使是GB200集群,其每加速器性能也相比Offline场景大幅下降,反映了实时、低延迟约束下的利用率挑战。
4.5. Llama3.1-405b 模型
Llama3.1-405b 是一个拥有4050亿参数的超大规模模型,是目前对AI硬件性能和内存容量的终极考验。
| 加速器 | 场景 | 平均总结果 (Samples/s) | 每加速器平均结果 (Samples/s) | 平均加速器总数 |
|---|---|---|---|---|
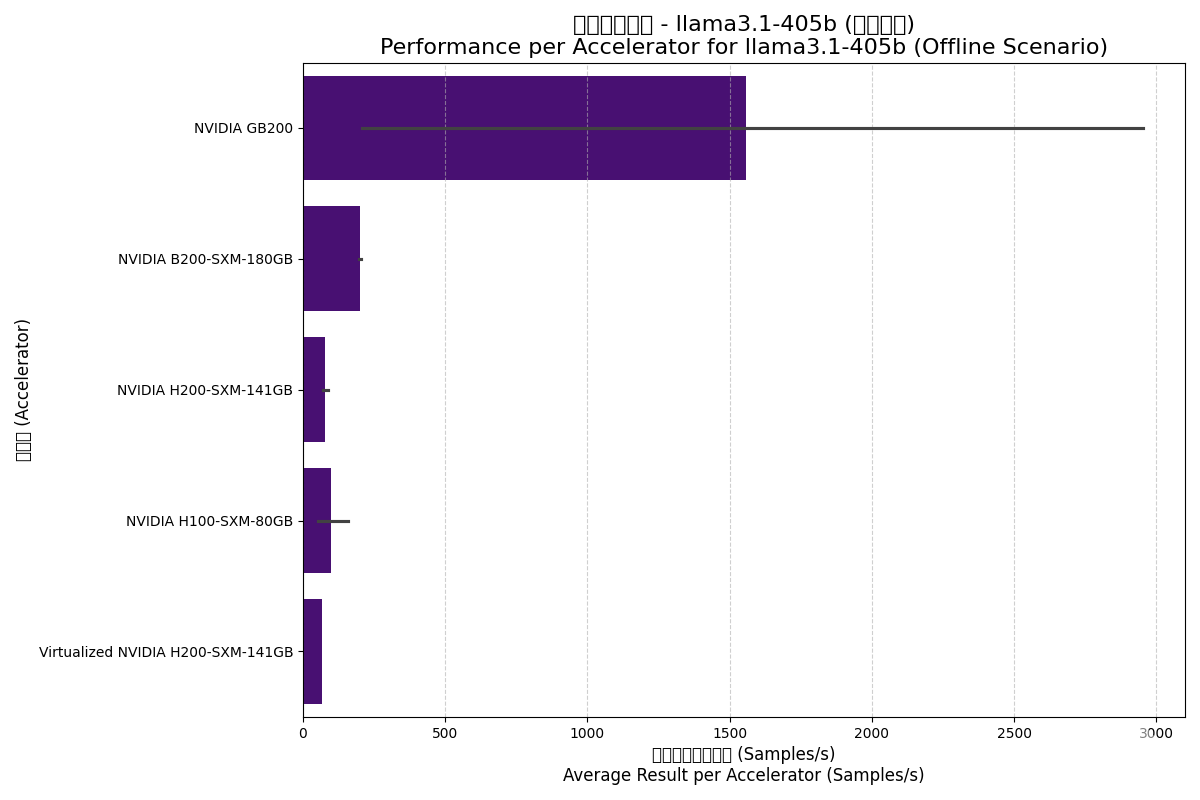
| NVIDIA B200-SXM-180GB | Offline | 1613.16 | 201.65 | 8.0 |
| NVIDIA B200-SXM-180GB | Server | 1179.05 | 147.38 | 8.0 |
| NVIDIA GB200 | Offline | 6233.13 | 1558.28 | 31.2 |
| NVIDIA GB200 | Server | 4433.33 | 1108.33 | 31.2 |
| NVIDIA H100-SXM-80GB | Offline | 794.56 | 99.32 | 16.0 |
| NVIDIA H100-SXM-80GB | Server | 557.35 | 69.67 | 16.0 |
| NVIDIA H200-SXM-141GB | Offline | 610.17 | 76.27 | 8.8 |
| NVIDIA H200-SXM-141GB | Server | 319.86 | 39.98 | 8.8 |
| Virtualized NVIDIA H200-SXM | Offline | 547.26 | 68.41 | 8.0 |
| Virtualized NVIDIA H200-SXM | Server | 277.33 | 34.67 | 8.0 |
Offline (离线) 场景:
Server (服务器) 场景:
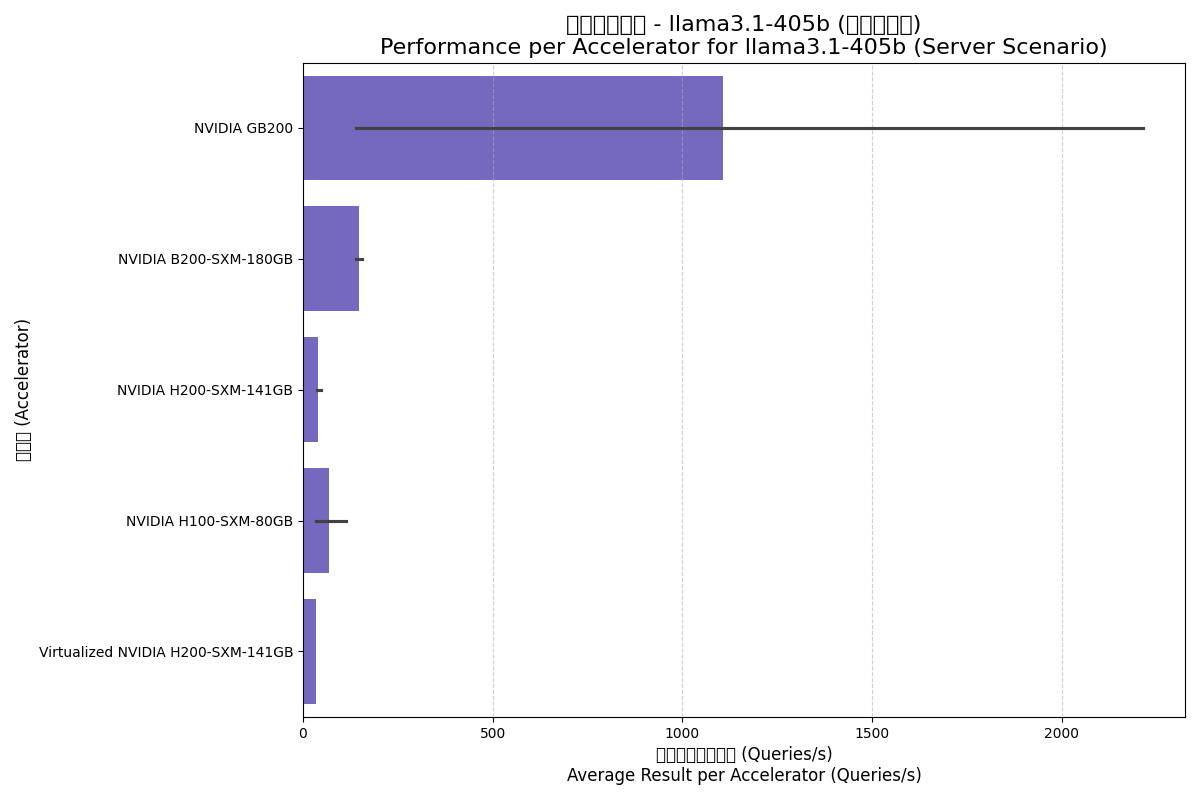
分析洞见:
- GB200为巨型模型而生:与deepseek-r1类似,GB200在处理Llama3.1-405b时再次展现了其作为大规模集群系统的威力,性能遥遥领先。
- 内存成为瓶颈:H200虽然内存带宽高于H100,但在此模型上每加速器性能反而偏低。这可能是因为H100的测试配置使用了更多的GPU进行张量并行,而H200测试配置GPU数量较少,导致通信或内存瓶颈更为突出。
- Blackwell的代际飞跃:B200的单卡性能约为H100的两倍,印证了Blackwell架构的成功。
5. 综合结论
- 架构演进是核心驱动力: 从Ampere到Hopper,再到Blackwell,每一代NVIDIA GPU架构都带来了显著提升。最新的Blackwell架构确立了新的性能标杆。
- “水桶”效应:算力、内存与互联缺一不可:
- 算力是基础,但对于大模型,内存带宽往往成为更关键的瓶颈。H200相较于H100的优势主要来源于此。
- 当模型规模大到单节点无法承载时,高速互联技术(如NVLink)成为关键。GB200的表现就是最佳例证。
- 产品定位决定适用场景:
- 数据中心旗舰 (B200, H200/H100-SXM) 是处理最前沿任务的首选。
- PCIe形态适合中等规模任务,性价比较高。
- 虚拟化技术已然成熟: GPU虚拟化方案在AI推理场景下表现出极低的性能开销。
综上所述,AI硬件的选择是一个多维度的决策过程。本报告通过对MLCommons基准数据的详尽分析,希望能够为相关决策提供数据支持。