This will be my final commentary on domestic Chinese models + Agents for the time being, for the following reasons:
I have essentially tested the capability boundaries of various providers, and they are mostly the same;
While the outputs generally look very good on the surface, the costs are actually extremely high if you consider scaling and normalization;
In contrast, GPT+Gemini+Claude consistently provide me with stable, controllable, and sustainable results. In this regard, domestic models + Agents still have a long way to go;
Yes, to be completely objective, especially within the domestic network environment:
Domestic models + Agents are quite good alternatives. I believe they are usable in 80% to 90% of scenarios;
However, the labor, time, and token costs behind them are much higher than imagined. This answers a question I raised a few days ago: while diligence can compensate for a lack of natural ability, "more" is sometimes "less." What looks like "less" ends up being "more."
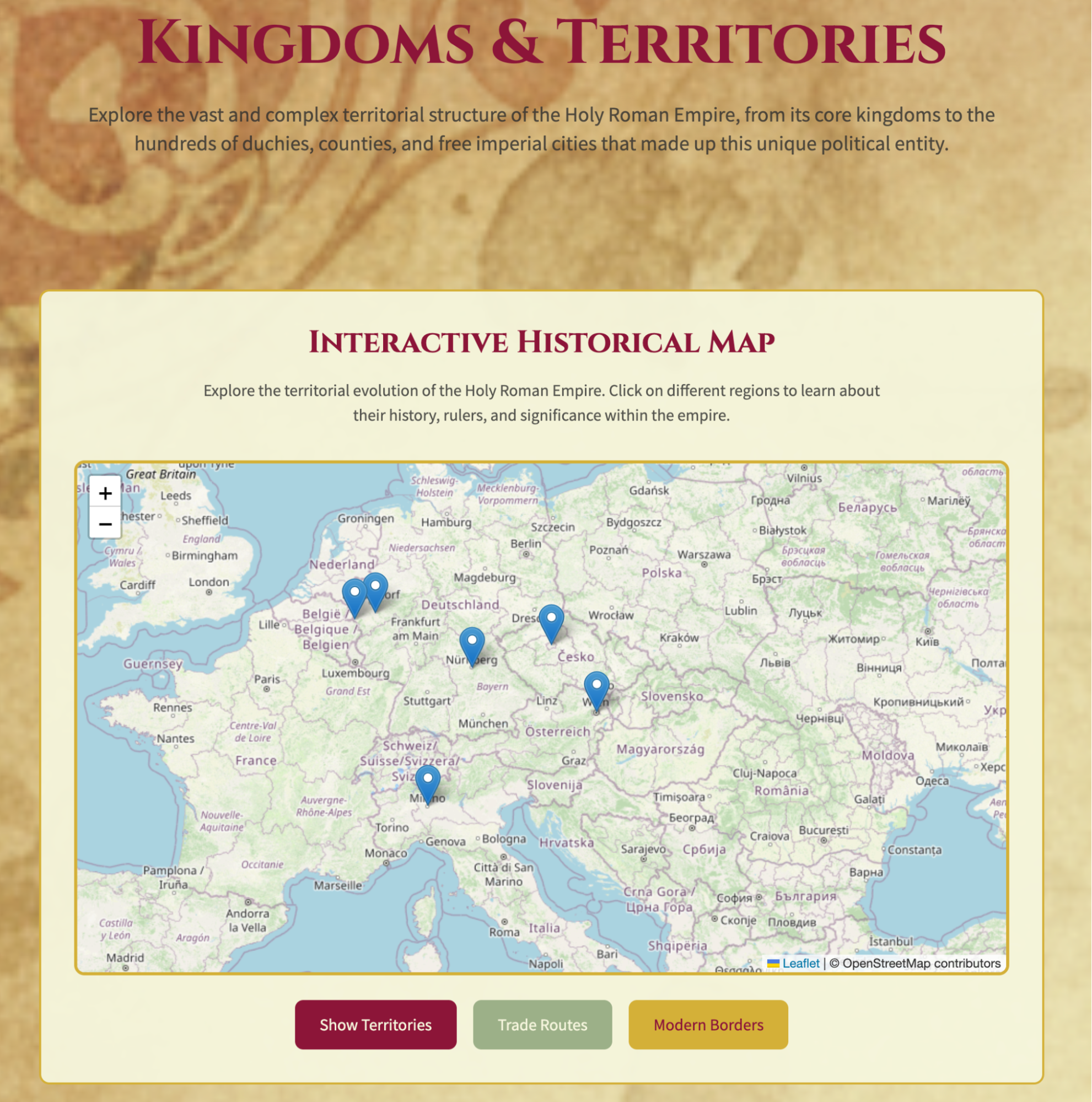
Returning to a previous piece: the "ambition" of generating a website for the millennium-long history of the Holy Roman Empire.
Indeed, the results presented in the last article were almost the limit of what Kimi OK Computer could achieve. Therefore, I used Claude Code to connect to Kimi's API, hoping to move from an Agent environment to a larger development environment. I hoped that relying on the K2 model could take the project a bit further.
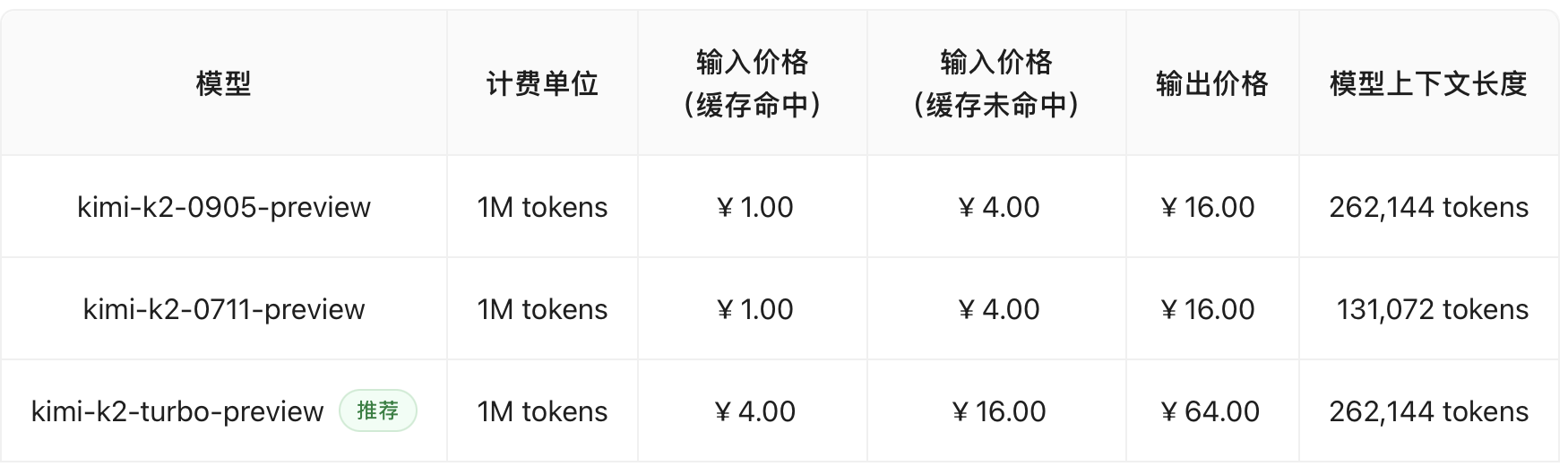
K2's pricing is actually not cheap—one might even say it's expensive—especially since the turbo model only boosts inference performance to a maximum of 100 tokens/s. In comparison, Gemini-2.5-Flash is much more capable, generates much faster, and works out to be cheaper.
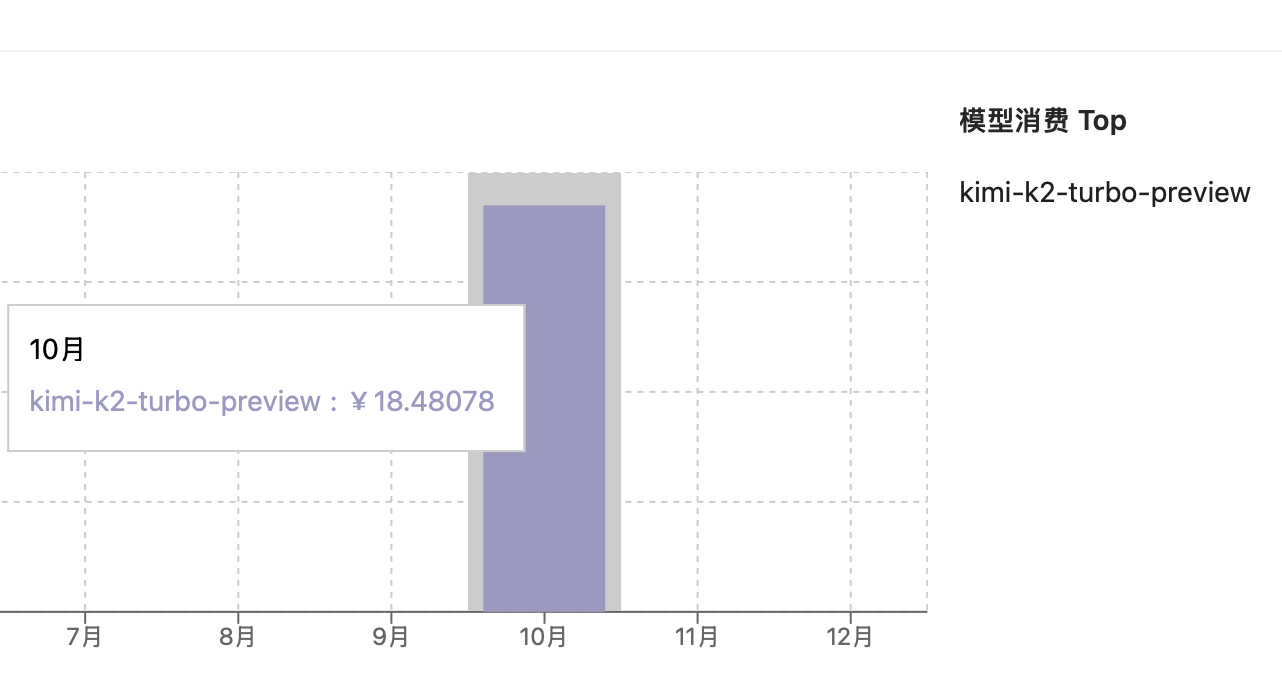
After three hours of continuous attempts and consuming 18.5 RMB, I achieved an improvement over the previous result.
The improvements were very focused: the Overview. Of course, the audio issues could not be resolved as Claude Code does not support them.


At this point, I decisively abandoned the idea of continuing to use Kimi for optimization. I never do these things just to get a so-called "good result"; rather, I value seeing how far we can go relying on the model itself with moderate human participation.
I have arrived at two answers:
This generation of models has reached its capacity limit. Agent-side optimization might increase output volume, as seen with MiniMax (which I'll mention in a moment), but there is no fundamental difference;
Overall, the cost of using the models is higher than Claude, and certainly much higher than GPT and Gemini. A $20/month Claude subscription allows me to work for an hour even under full load within every five-hour billing window—enough to optimize all the bugs in the website content section. Don't forget, the usage quota resets every five hours. Not to mention Gemini still has a large amount of free daily quota, and GPT provides subscription users with very generous usage in Codex;
Many times, more is less.
Of course, the example above is clearly because I set my expectations for Kimi too high. By reducing the load and targeting an AI daily report generated in Gemini for a multi-modal broadcast, after consuming two OK Computer requests, I obtained a complete "one-click to the end" result. The video is as follows:
At this scale, I successfully completed several small multi-modal slideshows with both sound and visuals.
Naturally, this type of Agent application pioneered by Manus (Manus doesn't have its own model and lacks an audio modality; I firmly believe that the road for general Agent applications without their own models is getting narrower) seems to have become standard for domestic models. For instance, I've been simultaneously testing MiniMax, GLM...
Then, in just a few rounds, the 5,000 points from the monthly subscription were exhausted.
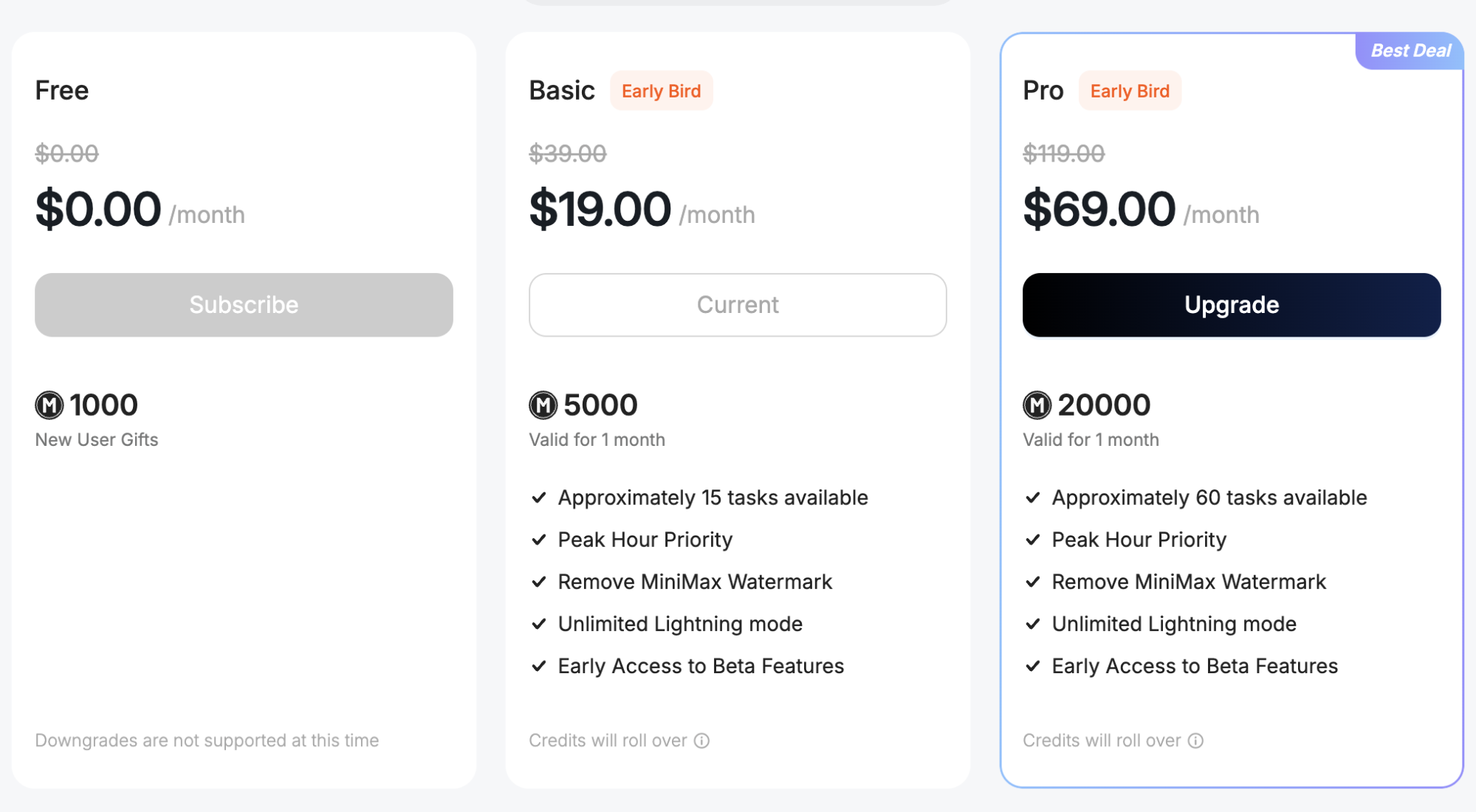

The deduction of 1,819 points was for trying to replicate the interactive audio website for the Holy Roman Empire from Kimi OK Computer. Having learned from the pitfalls in OK Computer, I wrote much longer prompts in MiniMax. MiniMax uses the Vite framework by default and carries more information, so the completeness of the result was slightly better.

Of course, while the audio portion was completed better and there were more historical maps, the overall information content was basically the same as Kimi's version. Aesthetically, Kimi is clearly more unified. Note that this MiniMax version was actually produced after I fed it screenshots of Kimi's results. The link to this result is: https://g1h6svu4arx7.space.minimax.io/
However, such a result cost over 1,800 points, meaning a $19/month subscription only allows for three such projects per month.
Yet, using Claude Code with a $20/month subscription, I can complete at least one per day. Although Claude doesn't have native audio, I can provide Gemini sample code and have it write the functionality directly—this is routine for me now. Crucially, I have dozens of free Gemini-TTS calls every day.
From this perspective, MiniMax is simply too expensive.
For those interested, you can also see the website I generated using 1,700 points: https://4m2xwqqvu8zl.space.minimax.io. Naturally, it's another "half-baked project."
In fact, if you look at many user-generated cases provided by MiniMax, they are almost all this type of website.
They look beautiful, but they are only suitable for static content. If the site above needed a data update once a week, you'd have to do it all over again—not to mention the 1,700-point cost, and the results would be unstable. In a word: it cannot be productized.
Perhaps, whether it's Build in Google AI Studio, Claude Code, or even GPT-5's Codex, even if the results don't look as pretty or flashy, they can achieve reusable productization at a lower cost. The tools supporting my various outputs every day are implemented this way. I know exactly how controllable and low the costs are.
Again, "more is less."
There is much more to say, but I'll wrap it up here with a few more conclusions:
Actually, as early as when Google released Gemini 2.0 late last year, today's examples could theoretically be achieved. While Agents significantly improve efficiency, no matter how good the Agent is, it needs the underlying model's capability to cooperate;
As another year ends and Gemini approaches the 3.0 era, the competition is no longer about a single large language model. It's about text-to-image, text-to-video, voice models, music models, and more importantly, the ecosystem;
Perhaps a single model can catch up through sheer effort to maintain or narrow the gap, but if the model library is missing pieces, or if every item exists but is just slightly inferior, the combined difference becomes massive;
This doesn't even consider the ecosystem, inference costs, user quality (willingness and ability to pay), and a series of other issues;
I have repeatedly calculated a number: before the arrival of envisioned AGI or ASI (intelligence that truly surpasses humans), the deep users of models are those few tens of millions of "programmers" and professionals (along with their companies or their companies' deep users);
In the current climate of high competition and rapid iteration driven by massive investment, failing to capture the mindshare of these tens of millions of users and failing to create multiplying revenue from them easily leads to a "vicious cycle" where more investment brings lower returns—or even a "predicament" where stopping investment means immediate exit;
I can't expand further; I hope my judgments are wrong. Regardless, as stated in the title, this is my final commentary on domestic models + Agents for the time being.