For automated daily reports following each US trading day, real-world scenarios not only continuously test the stability of models but also serve as targets for ongoing optimization.
In fact, the process for the daily videos I post on WeChat Channels is now relatively stable; over the past two weeks, only one significant error occurred.
Under the current workflow, there are four steps: 1. ChatGPT-Agent scheduled daily task to generate a text report; 2. A Gemini-based tool (developed using Gemini) to generate visualizations and the voiceover script; 3. Gemini's TTS model to generate audio; 4. Video synthesis (manual iMovie, taking half a minute).
Of course, within these four steps, human actions include: two copy-pastes, one screenshot, one dragging of video assets, one video export, and one upload to Channels. During this manual participation, a content "review" is conveniently completed.
The ideal scenario would be complete automation. However, considering that models likely won't guarantee 100% accuracy for a long time, reducing it to two steps (text generation and video generation) or three steps (video generation turning into automatic asset generation plus editing) could save some tedious labor (it doesn't actually take much time, but it feels "repetitive").
I once tried to use a model to help generate a project to complete the second step in one click, but the results were unstable (Gemini's TTS API was a bit inconsistent), so I set it aside.
While I was in the midst of testing domestic Chinese models and Agents, I noticed that Kimi, GLM, MiniMax, and Qwen all have TTS models. This led me to test those with Agent modes (Kimi's OK Computer, GLM's Full Stack, and MiniMax's Agent).
I posted the results in a video this morning, as follows:
Actually, the results are quite clear, but I can elaborate on the implementation details:
First is Kimi's OK Computer; here is a screenshot of the progress:
Partial page screenshot:
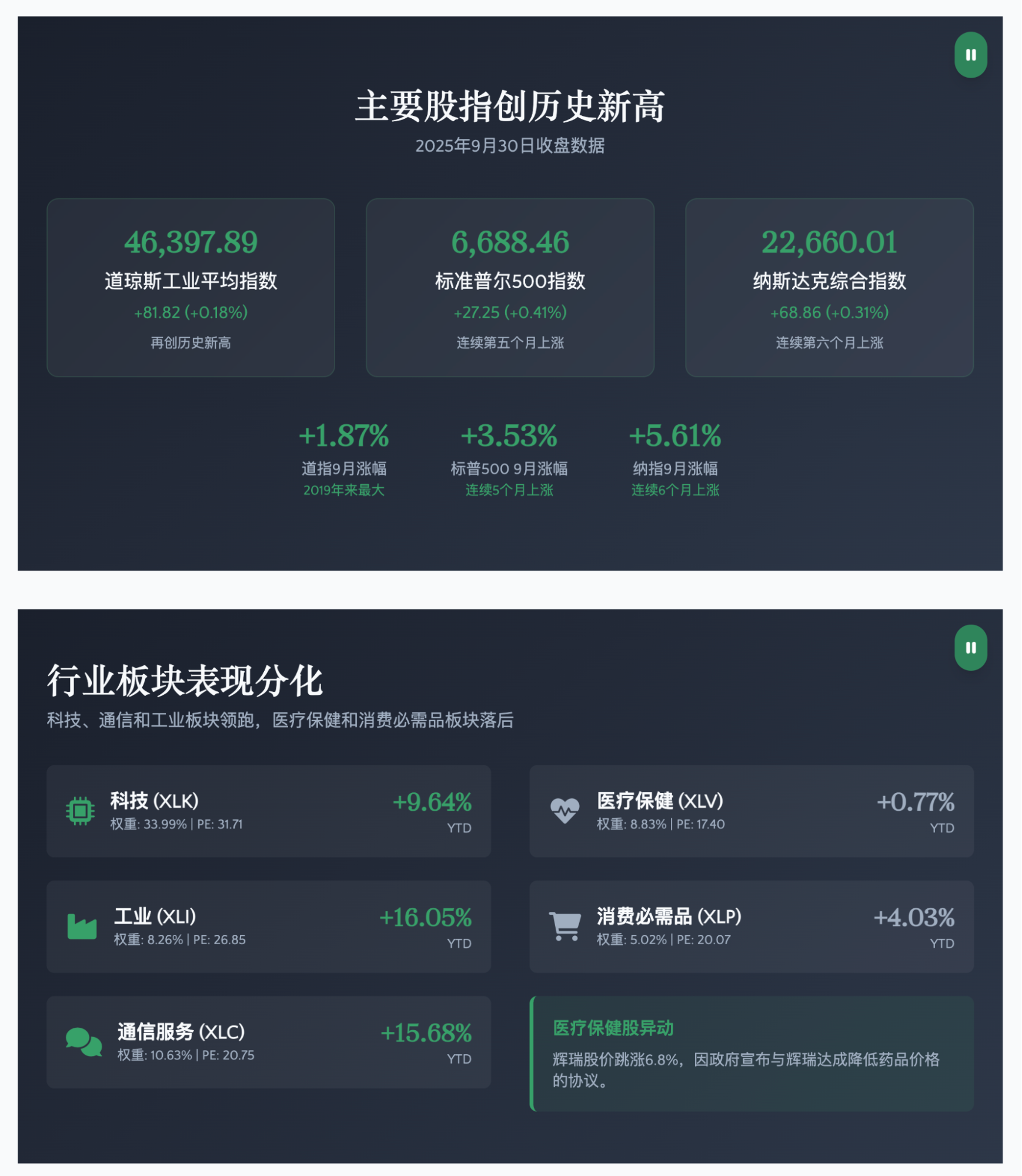
Pros: Among the three domestic options, I find its UI to be the most attractive; The information density is just right; Generation speed is the fastest, taking about ten-plus minutes; The number of project files is the most streamlined. I believe this reflects the model's capability—it suggests fewer preset templates and more reliance on the model's own logic.
Cons: The voice quality feels inferior to MiniMax; Given the same prompt requirements, both GLM and MiniMax could achieve audio playback functionality in a single request (functionality, not necessarily correct code). OK Computer made me make two extra requests: one to convert the text to speech as seen in the screenshot, and another to ask it to redeploy so I could find the generated audio files in the HTML. Kimi provides 20 requests per month to $19 subscribers; what should have been one task wasted three. If I encounter code errors that need fixing, I highly doubt these credits could cover a week's work.
Next is GLM, using the Full Stack mode after the 4.6 model upgrade. Project progress and page screenshots follow:

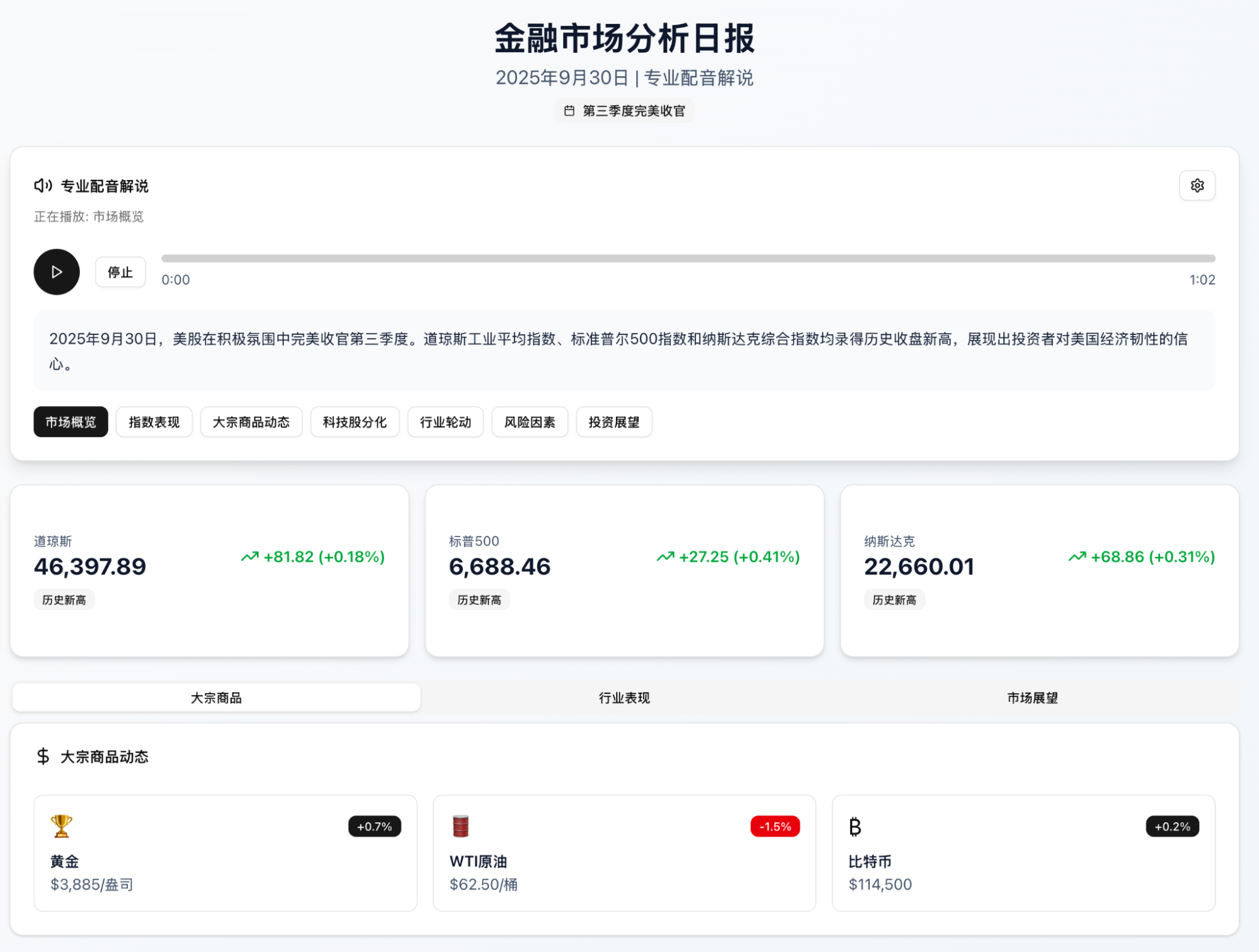
Pros: Compared to the other two, it has almost no advantages. If I had to pick one, although the voiceover didn't use a model (I tried several times unsuccessfully) and instead used the browser's built-in text-to-speech (sounding like a robot from a last-century sci-fi movie), it automatically switches sections during the broadcast via a row of tabs. This is a feature I really wanted.
Cons: The content is the simplest; It fundamentally fails to integrate its own TTS model, despite claims that it exists; The code generated on the first try was wrong. I had to help it debug several times, fearing that like Kimi, every fix would consume a request (even Claude Code isn't that stingy). GLM-4.6 generates quickly, but the errors are frequent; The project structure is the most complex, coming with a bunch of default components. It’s clearly preset. From an engineering standpoint, this is fine, but I don't consider this true AI (more on this later).
Third is MiniMax:
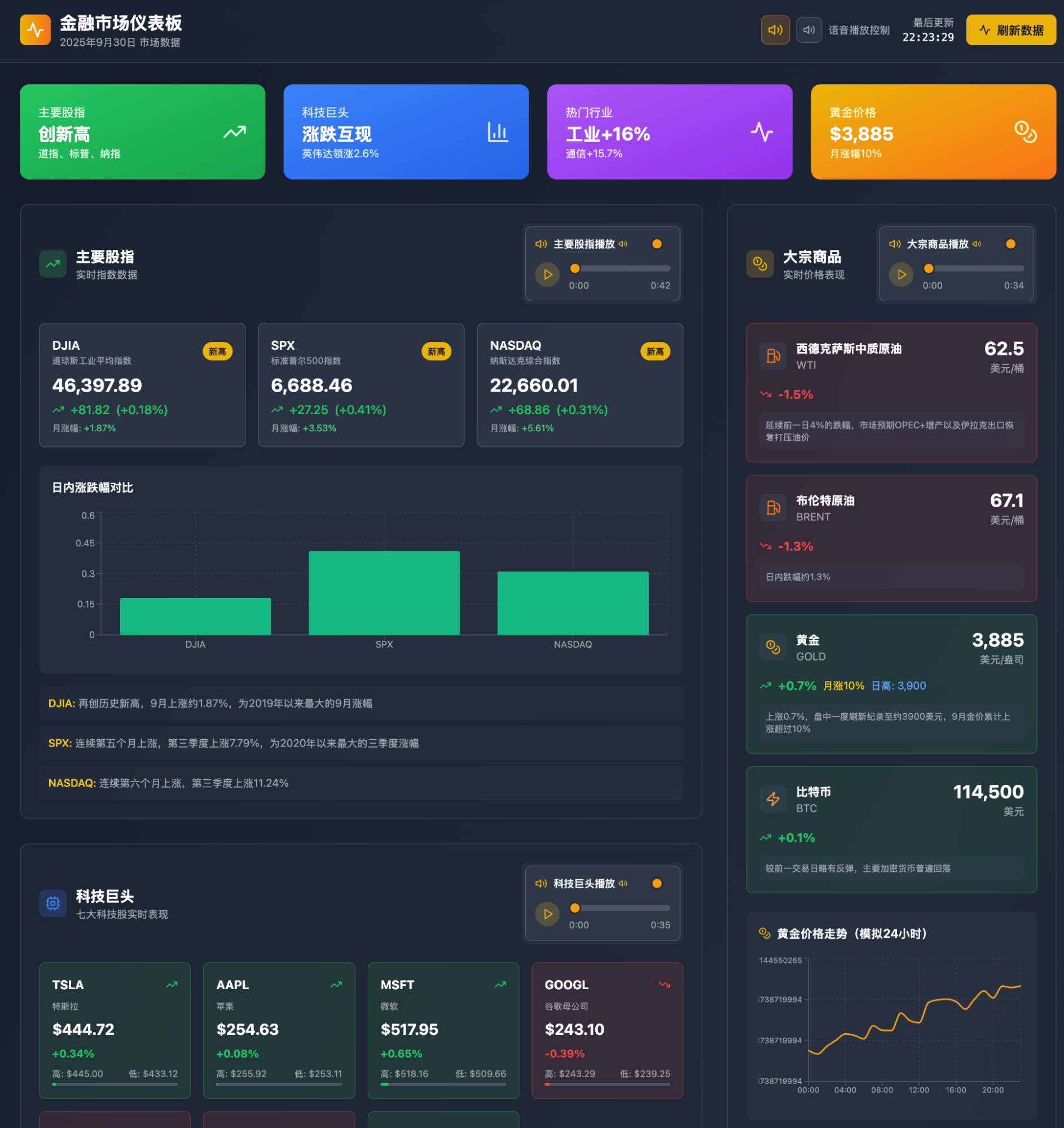
Pros: The only one that confirmed the plan with me; The richest content; The most natural voice.
Cons: Overthinking led to many "hallucinations," such as trends for gold prices; if it's just a simulation, it's better not to simulate at all; The page layout is a bit messy and unclear; Too diligent—it searched for and inserted a ton of illustrations; It took over half an hour.
Overall, the results from these three Agents exceeded my expectations. They also opened up new ideas for me, which I went back and applied to Gemini's Canvas (I had tried before, but one step wasn't handled well), and it worked.
Direct video upload below:
It's just an HTML file with fewer than 500 lines of code. The time for code and voice generation was less than five minutes (mostly due to the voice generation taking a bit longer).
I optimized the process again by presetting a "Gems" in Gemini. Now, I only need to copy and paste the text report content once, then use Command+Shift+5 to record the screen.
Pros: The content is specifically suited for video generation, and the overall broadcast flow is more cohesive; The generation time is short; if considering production, the cost would be far lower than the three domestic options; The HTML code is environment-agnostic, and voice generation is called directly through HTML code using Gemini-2.5-TTS. As long as you have an API key, it works anywhere.
Cons: Only if you count occasional instability, but it is at least much more stable than the three above.
In previous articles, people often commented on how great domestic models are. This example clarifies the situation:
Achieving a seemingly practical result by putting massive effort into the Agent layer is not the true path for the AI era. The direction we understand for AI development today is "native intelligence."
I admit that in terms of productization, domestic models + Agents (excluding Manus, which is an Agent application) are doing much more than overseas companies. This is a point I have emphasized recently: in at least 80% of scenarios, they perform very well.
However, because the Agents are overly preset, each link is too deeply bound, resulting in a loss of flexibility. This is why OK Computer "stupidly" consumed three chances, and GLM-4.6 required my repeated help to deliver correct code...
Some will argue and recommend workflow orchestrators like n8n or Dify. Frankly speaking, five years ago, I had used almost every workflow tool and solution imaginable—whether data pipeline concepts or MLOps, open-source or closed-source. When ChatGPT first arrived and everyone was talking about "Chat," I was already talking about and using workflows. I even wrote my own flow tools for orchestration. Workflow is engineering, not AI; workflow is business logic, not core technology. To use a buzzword: those who know, know.
Actually, with model development today—whether by learning from advanced experiences or rapid self-improvement—the capabilities of domestic models are not bad. But the reality is that the best users (those with the strongest willingness and ability to pay) have already been captured by the three leading global models. Tuning the Agent layer to look pretty and focusing on "foolproof" or "one-click output" is a great marketing point.
Yet, perhaps the biggest "lie" of the AI era is "simplification" and "one-click output." High quality without effort inevitably requires a massive accumulation of business and technical ingenuity behind the scenes. Using heavy presets in engineering can produce great demos, but then what?
So, it's not that they've done too little, but rather that they've done too much.
Looking back at Gemini: a better, more versatile model that produces more stable results that meet requirements in a more time- and cost-effective way. Not every triangle is an "impossible triangle."
Finally, on Day 1, I used my own generated results to "criticize" the overhyped Manus, but in truth, I have always admired Manus's vision. Similarly, I admire the products of the three domestic Agents mentioned above. I still try Manus occasionally; many cases and processing workflows provide me with continuous inspiration.
However, we may be entering an era where "diligence can no longer compensate for a lack of talent." Yes, as I write this, the underlying tone of my mood is once again somber.