Kimi's all-purpose Agent: "OK Computer" has been released. Fortunately, with three free trial credits, I managed to gather enough information to provide an evaluation.
TL;DR:
I absolutely love its UI. I've always felt that among domestic Chinese models, Kimi has a unique aesthetic and a certain programmer-esque "coolness" (in a positive sense);
Capabilities (Pros): The Agent component is very well-optimized. Searching, browsing, Python coding, web coding, and deployment are all quite smooth, generally yielding results with solid workflows and architectures;
Capabilities (Cons): The limitations of the underlying foundation model are quite evident. Tool selection feels a bit "rigid," showing signs of a typical "test-taker" mentality; the generated page styles are somewhat "random";
Hence, my evaluation is somewhat contradictory. When trying various domestic models recently, my overall feedback has been positive. I believe current models, combined with "reasoning" and Agent orchestration, can handle 70-80% of AI-reachable scenarios. However, there's always a feeling that something is missing. OK Computer helped me identify this missing piece: while "thinking" and preset Agent enhancements can compensate for the model's "innate deficiencies," it leaves a slightly "melancholic," cold-toned impression.
Now, for a detailed discussion. I conducted three tests using my usual workflows: two daily report generations (two because, in the first attempt without specific prompts, OK Computer surprisingly didn't use web search) and one "Deep Research" session based on existing prompts.
First, the results of the first "Daily Report." I used prompts that are already very mature in my ChatGPT-Agent daily tasks.
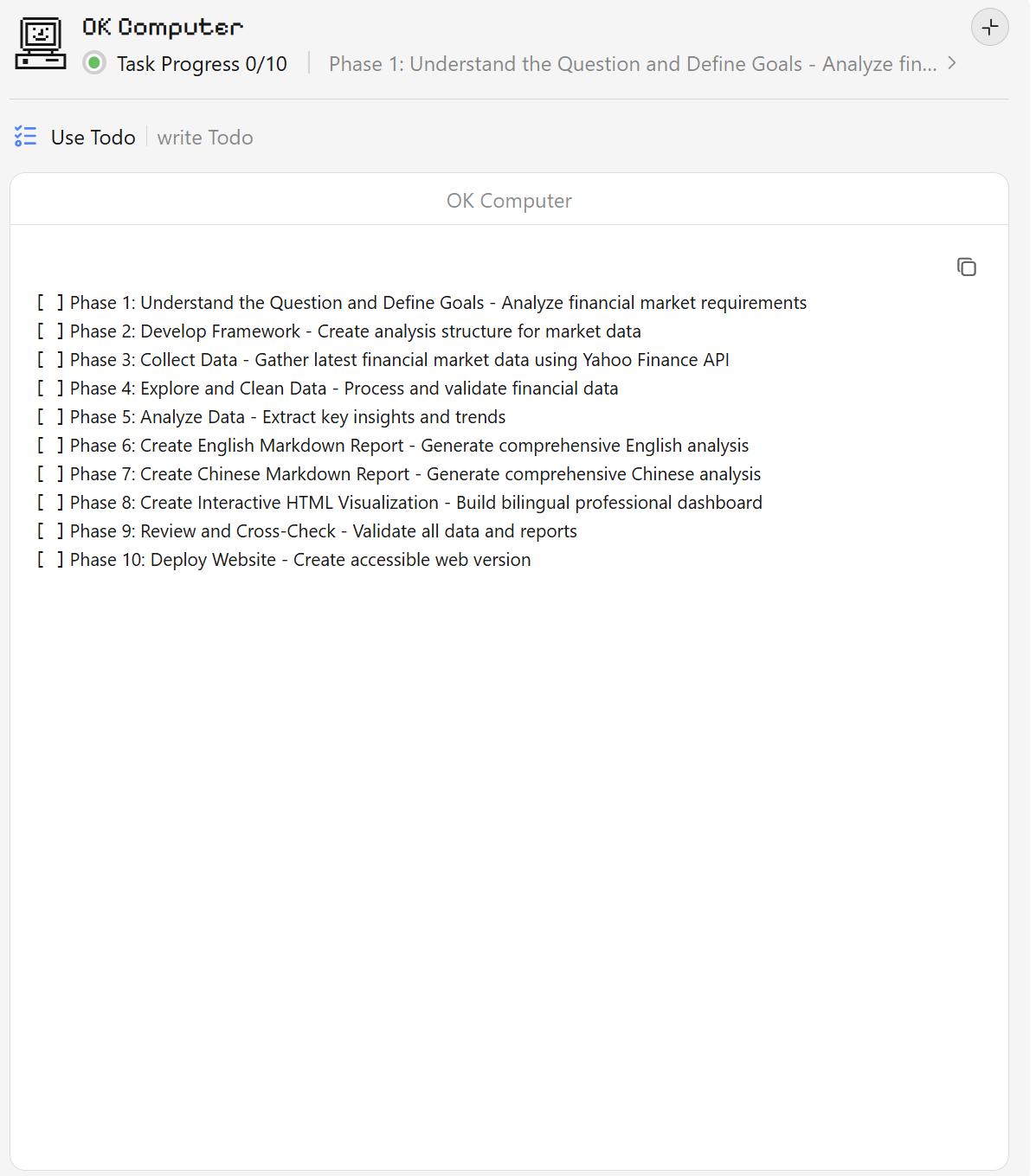
The To-do List feels very familiar.
However, because there was no explicit prompt to use search tools, it spent all its effort using Python code to access the Yahoo Finance API.
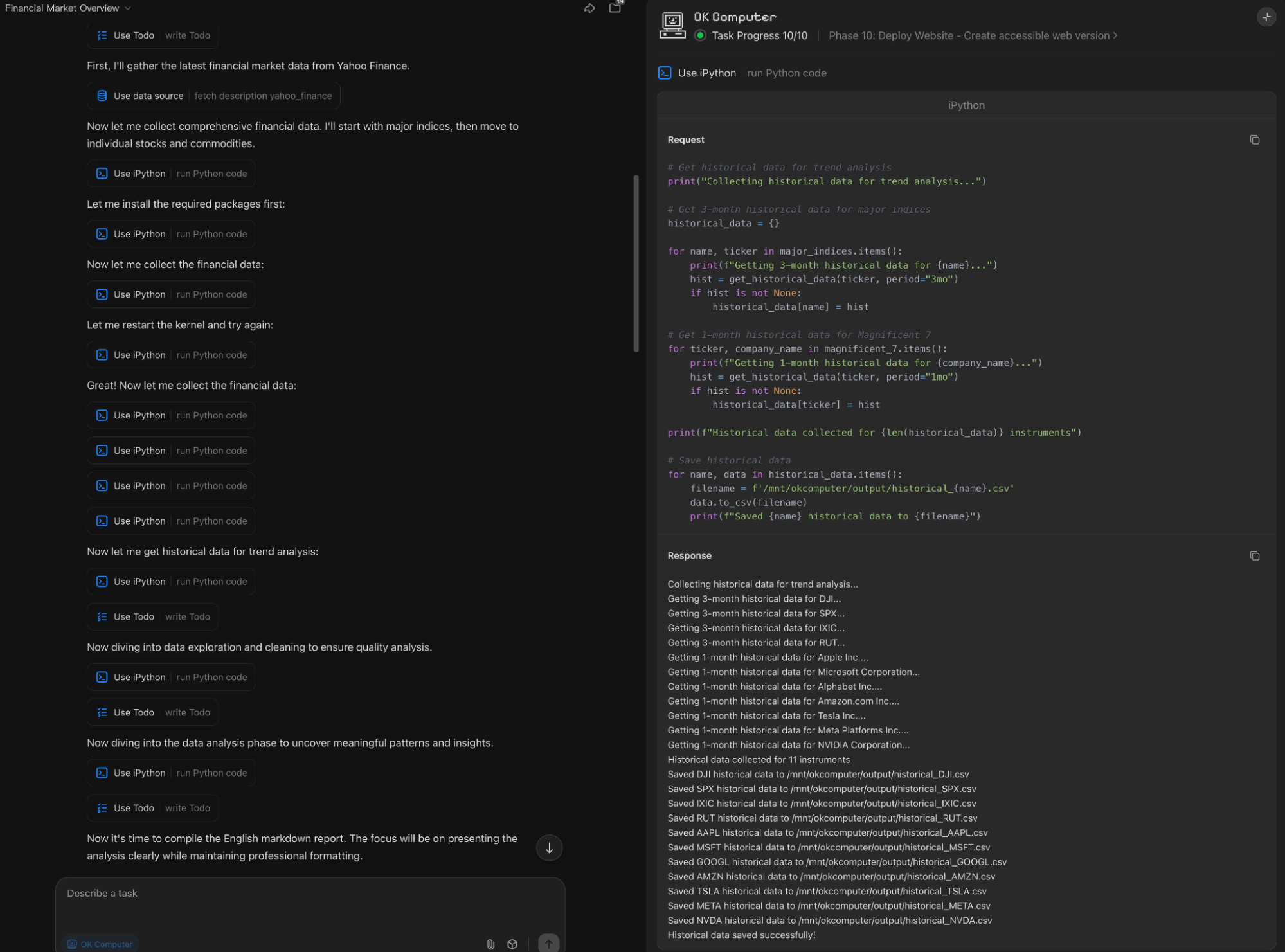
While the final numerical results were correct, the Markdown output suffered due to the lack of search—most notably in the timestamps. Furthermore, it missed critical market-driven analysis, resulting in a report that only discussed numbers.
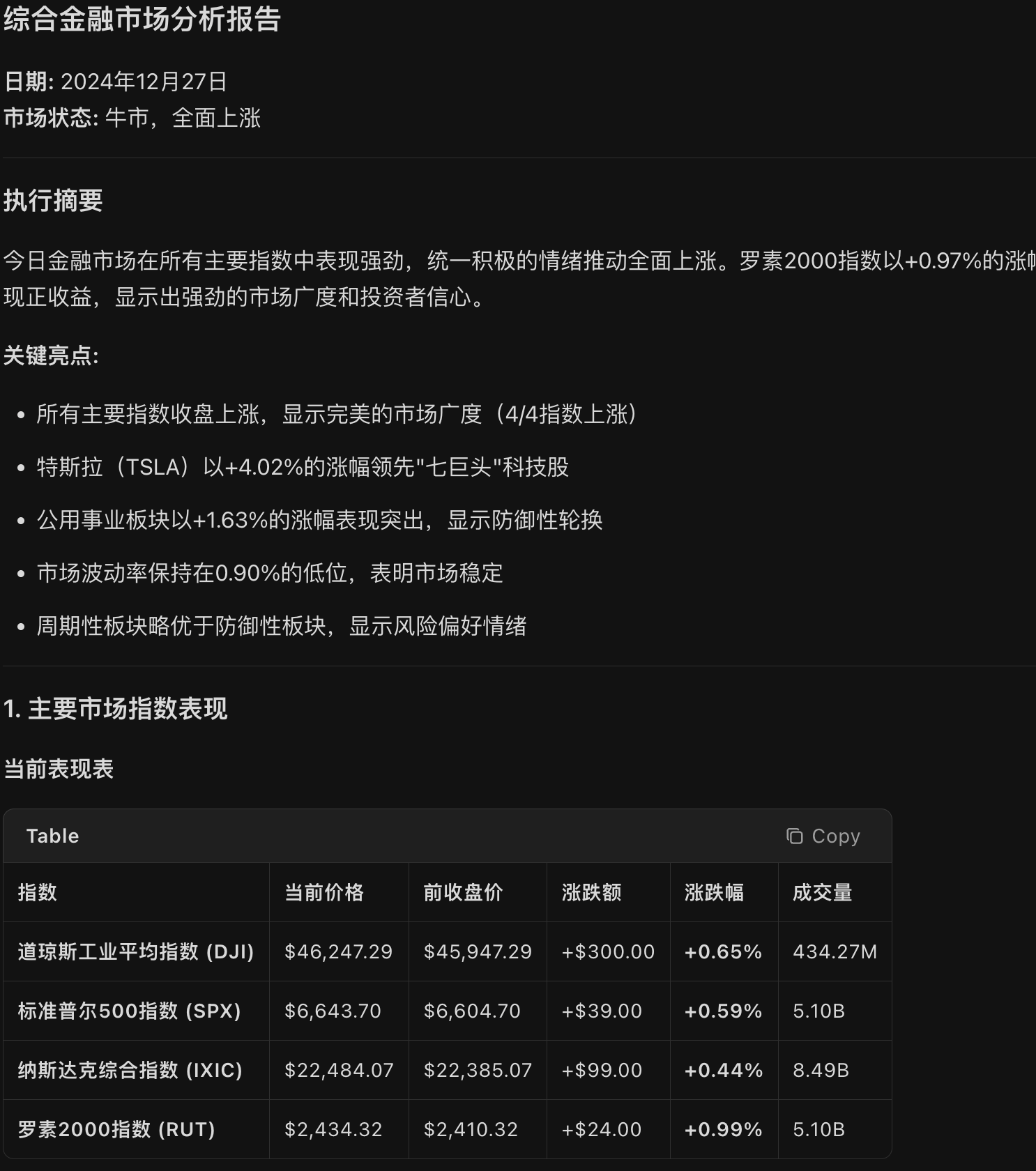
Additionally, the indices above were forced into a "$" format, leading to the following display issues on the page.

I didn't provide style prompts for the webpage generation, but the style it produced was actually quite good. However, it felt too familiar, triggering a negative association: the color scheme is almost a "light" version of a style I started using two or three months ago, which I had fine-tuned from a default Gemini app style. Here is that style: it's basically just the difference between dark and light modes.
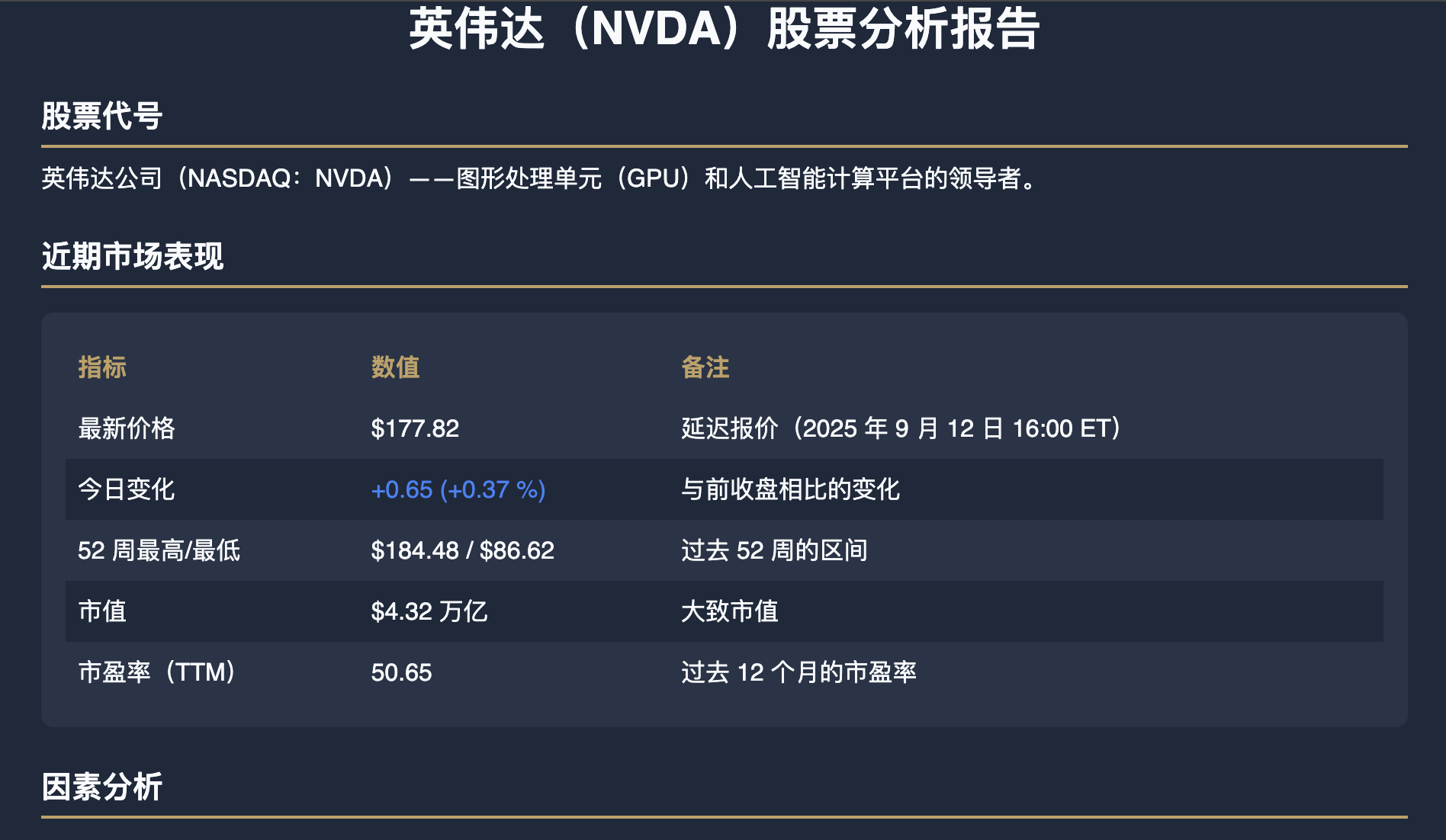
OK Computer took about 30 minutes to execute this workflow. The code generation speed was slow, roughly equivalent to running an open-source 120B model locally on a Mac.
The page code quality is mediocre. Usually, my HTML reports with more information are around 400-500 lines. Kimi generated nearly 1000 lines, with excessive redundancy in styles and charts. Its handling of bilingual support was also questionable: Claude, GPT, and Gemini typically include both languages in div attributes and use a global switch.
Initially, after the first test, my evaluation was mediocre—failing to trigger search was a major flaw, and the code seemed to lack "intelligence."
However, the second test significantly improved my opinion: a "Deep Research" task using two templates from my open-source project OpenResearch: the execution template instruct_v2 and the visualization template vis. I used the examples directly from my README but added explicit requirements to use search and browsing tools.
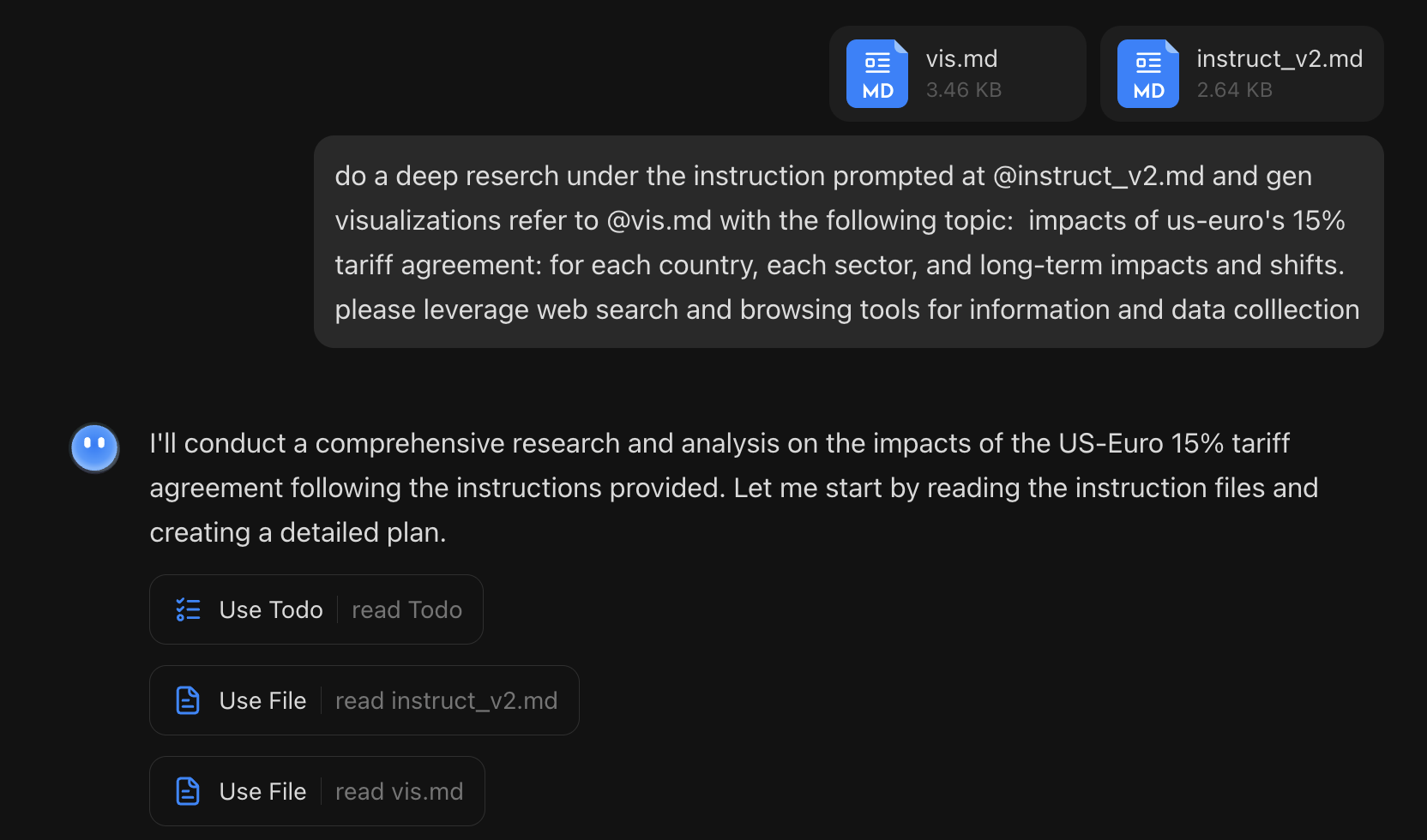
The process and results were satisfying. It not only enabled search but also faithfully generated files according to my requirements. This workflow runs smoothly in Gemini-Cli, and seeing it work in OK Computer reinforces my view that "instructing the model how to work" is paramount: the plan, tasks, logs, reports, and webpages were all named and structured as requested.
For the web preview, since Kimi defaults to a website structure requiring an index.html, it generated one to wrap the requested visualization results.
The data, styles, and charts were all fine. The charts were created using Plotly, which seems to have been a focus of its specialized reinforcement learning.

This example redeemed its reputation, so I decided to try the Daily Report again, this time explicitly requiring search.
This time search was active, and it was reflected in the results.
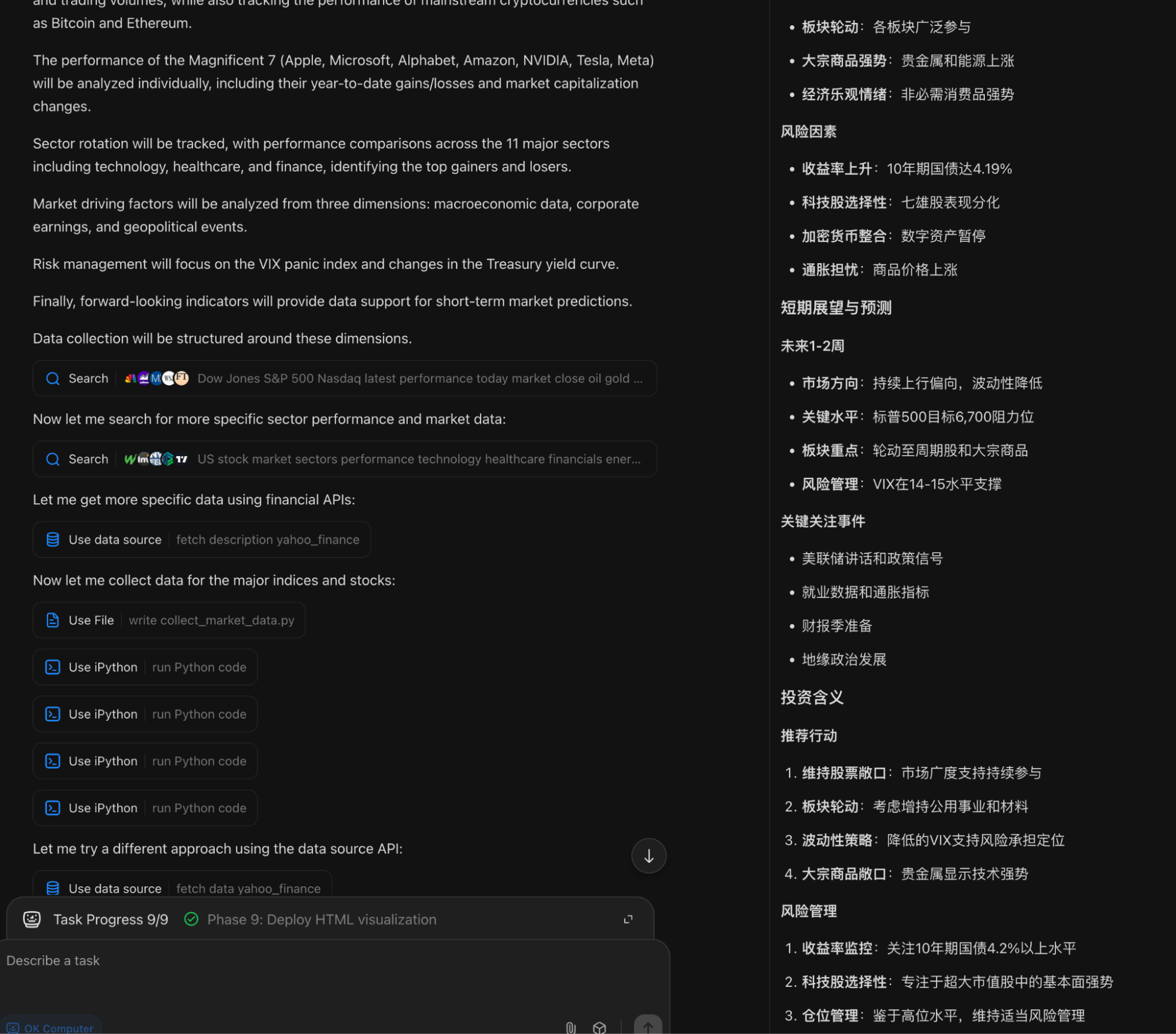
Again, I didn't specify a page style. The result was as follows: a completely different style—ugly, hollow, and lacking both in layout and content.

Compared to my mature daily workflow based on ChatGPT-Agent + Gemini, the gap is massive. Watching OK Computer execute, it seems to perform every step but loses focus during output:
It seems reinforced to do dry data analysis rather than effectively utilizing searched information;
It doesn't seem to understand that events and dates are more important, nor does it understand that an index is not a price and should not have a "$";
Without comparison, one might not realize the gap. The ChatGPT-Agent result (taking 17 minutes vs. 30 minutes) looks like this:

I can only conclude that the gap in foundation model capabilities is actually larger than it currently appears. I feel similarly when looking back at other domestic models.
Specific enhancements in "reasoning" and reinforcement learning might close the gap in scores and leaderboard rankings, but in actual production, the disparity becomes glaring.
This is why I chose the title "A Contradictory Evaluation." It's not just about pros vs. cons, but about deeper, awkward issues: you know this isn't the right way forward, but you also know there's no better path. You can see "data convergence" behind "model convergence," and understand why domestic models top leaderboards in clusters—"catching up and surpassing." You can sense the shifting "lineage" between versions, much like OK Computer providing wildly different styles for the same task.
This path might not be entirely correct, but if we don't take it, we might find ourselves with no path at all.
That is my contradictory evaluation: one with a melancholic undertone, yet filled with hope: at least, in many scenarios, they are already quite good.