Recently, the "intelligence drop" issue I experienced with Claude Code has finally received an official response: it's a reasoning stack issue.
I also believe this is the reason, rather than an attempt to save computing power.
A few friends asked me to evaluate Claude Code against Codex Cli (based on GPT-5), so I conducted a few small tests.
TL;DR, here are the conclusions first:
I am very uncomfortable with the changes in Claude Code. It has even made me slightly worried about the future of these models: if a small fraction of data or subtle changes in reinforcement learning logic can cause such a massive shift in model output, does that mean models won't be ready for production environments with high reliability requirements for a long time?
We can clearly see that in the era of Agentic AI, the three major models have very distinct differences. Regardless of external evaluations, they remain the three most distant peaks (with the strongest independence) in the model lineage, whereas other models often feel like they are clearly "derived from the same bloodline."
At least in programming development, Codex Cli cannot yet replace Claude Code. Despite many enhancements, GPT-5 is still not a model perfectly suited for code generation. Its best application is actually its relatively unique agent capabilities—flexible and "specific." While it might not be "smart," it's well-suited for "dirty work" with clear instructions; perhaps diligence can make up for a lack of brilliance.
Below are the details of the tests.
The first is a non-programming task. Since Microsoft just signed a large contract with Nebius, I used my earliest version of OpenResearch (a prompt workflow) to test the output of Claude Code, Codex Cli, and Gemini Cli.
During execution, Gemini was the shortest, completing the task with a few web searches. Codex took the longest because it used different tools. Claude Code, however, produced the largest amount of information, as evidenced by the file sizes below.
Claude Code thinks a lot, but I recall it wasn't like this before the "intelligence drop." This might be exactly why its programming capability has declined. For the same question, Gemini and Codex didn't expand too much, but Claude Code expanded significantly.
However, in the visualization part, Claude Code left an unfinished project: it set up the HTML framework at the start but left a massive amount of content incomplete.
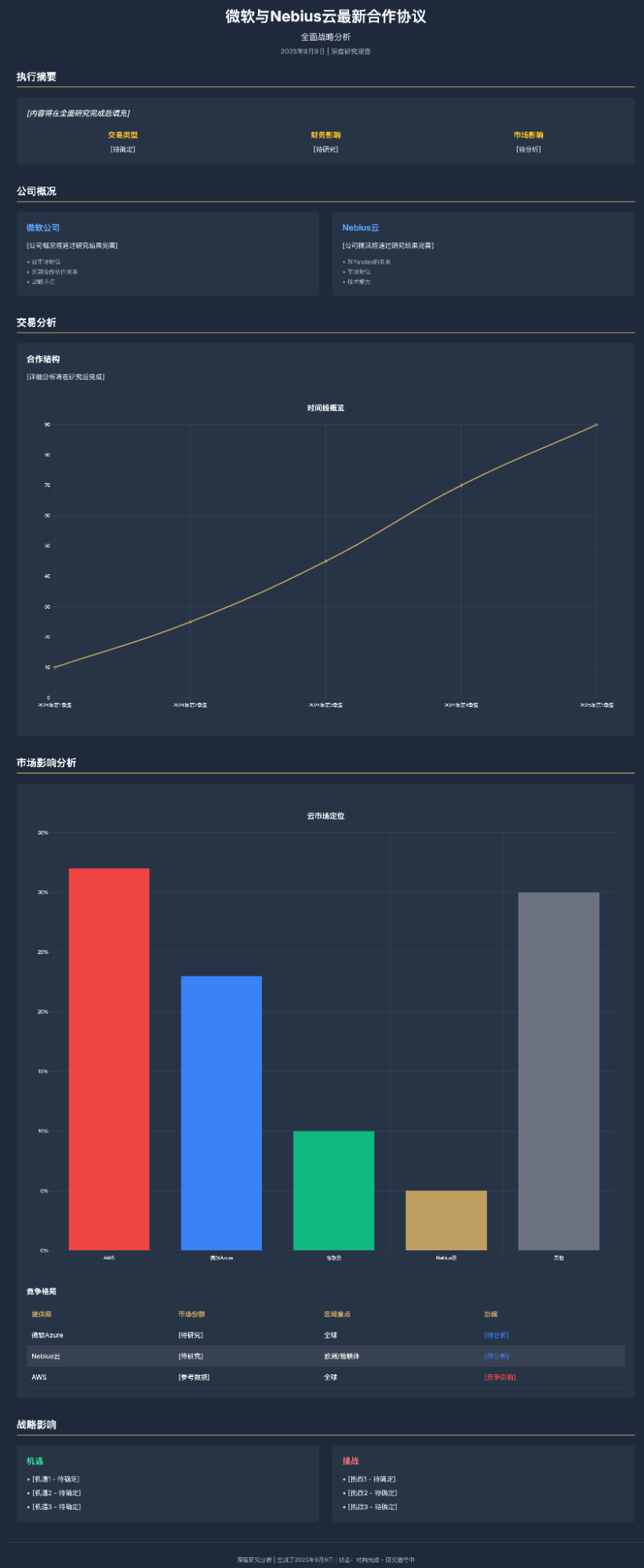
In contrast, Gemini completed it fully, including everything it should have without overthinking. However, we see a clear problem: excessive information repetition.

Codex represented another form of information "redundancy": invalid charts.
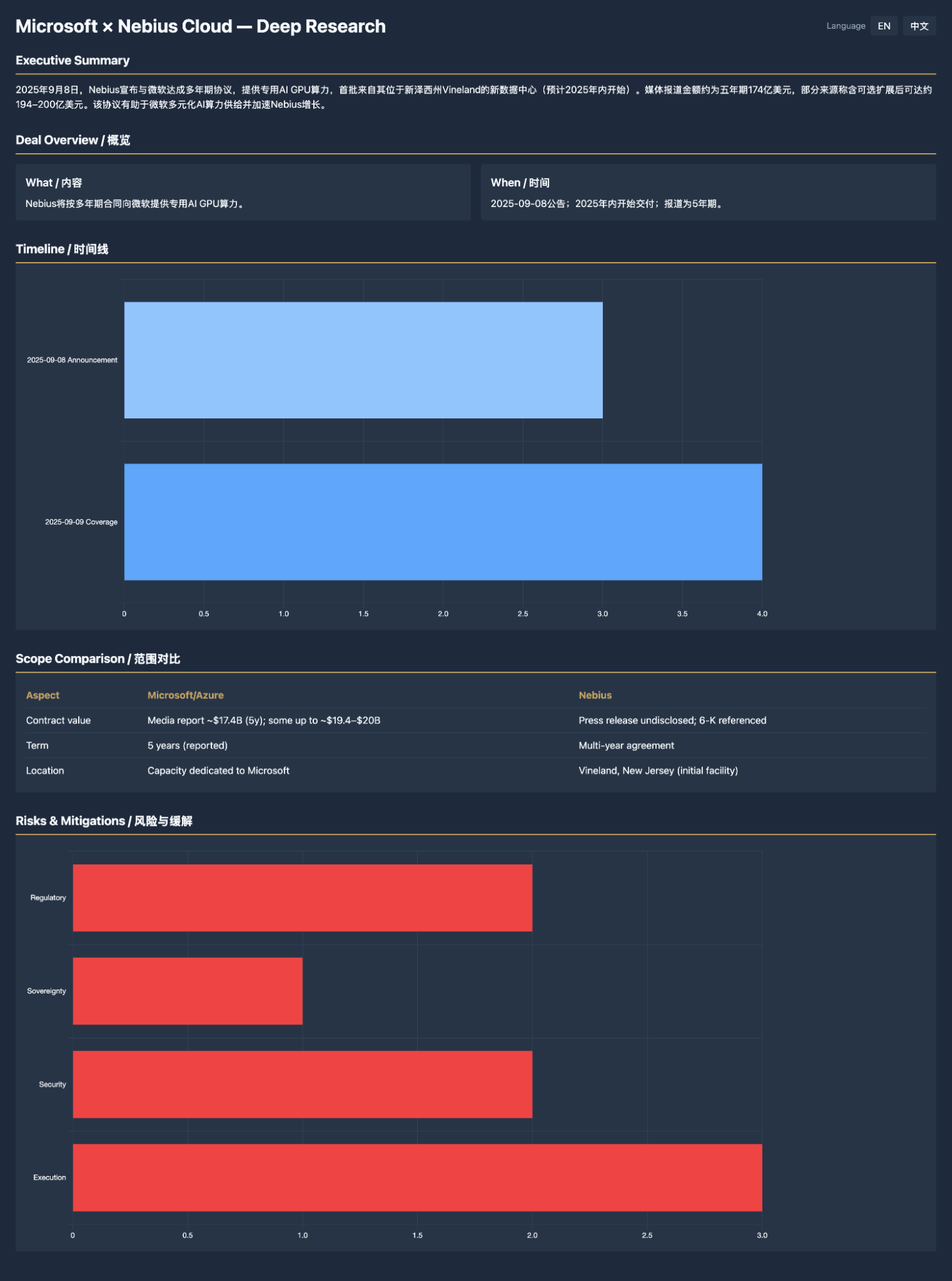
This issue actually highlights the fatal flaw of "overthinking" in current models: for a question that seems important but actually contains little information, the models appear too "rigid." Claude Code's overthinking even led to many "hallucinations."
As a comparison of tools, however, I value their workflows and methods more. I used Gemini to analyze the conversational output of the three tools.

The table above basically reflects my feelings: 1. In this scenario, Gemini's search capability is fast and accurate; Codex lacks a web search tool and has to rely on constant curl commands to process info; Claude has a search tool, and its "thinking" makes it look like it's gathering a lot of info, but its "hallucination rate" is as high as ever. 2. Gemini Cli is the most accurate in instruction execution, while Codex is more flexible and has a decent thinking process.
For non-programming tasks, especially searching, Gemini Cli remains in its "comfort zone."
The second test is one I've done and written about before: building a photography website. The prompt is just five lines:
ok, polish the project to be a photographer's art website:
- gallery of photos;
- reviews of gears;
- blog style articles;
- support videos;
Gemini's performance was unchanged from last time—even the way it "slacked off" was identical, so I won't expand on it. The focus is on Codex and Claude Code.
Codex was the fastest, succeeding in one go. The page, how should I put it, had a "wrong aesthetic": various colored blocks acting as photo placeholders, which felt a bit...
The video selection above reminded me of Gemini's results from previous tests. Exactly the same choices. I'll link the previous article at the end for those interested in comparing.
What shocked me was Claude: it was too "abstract." I admit it thought a lot, but compared to the website I generated last time, it was far worse.
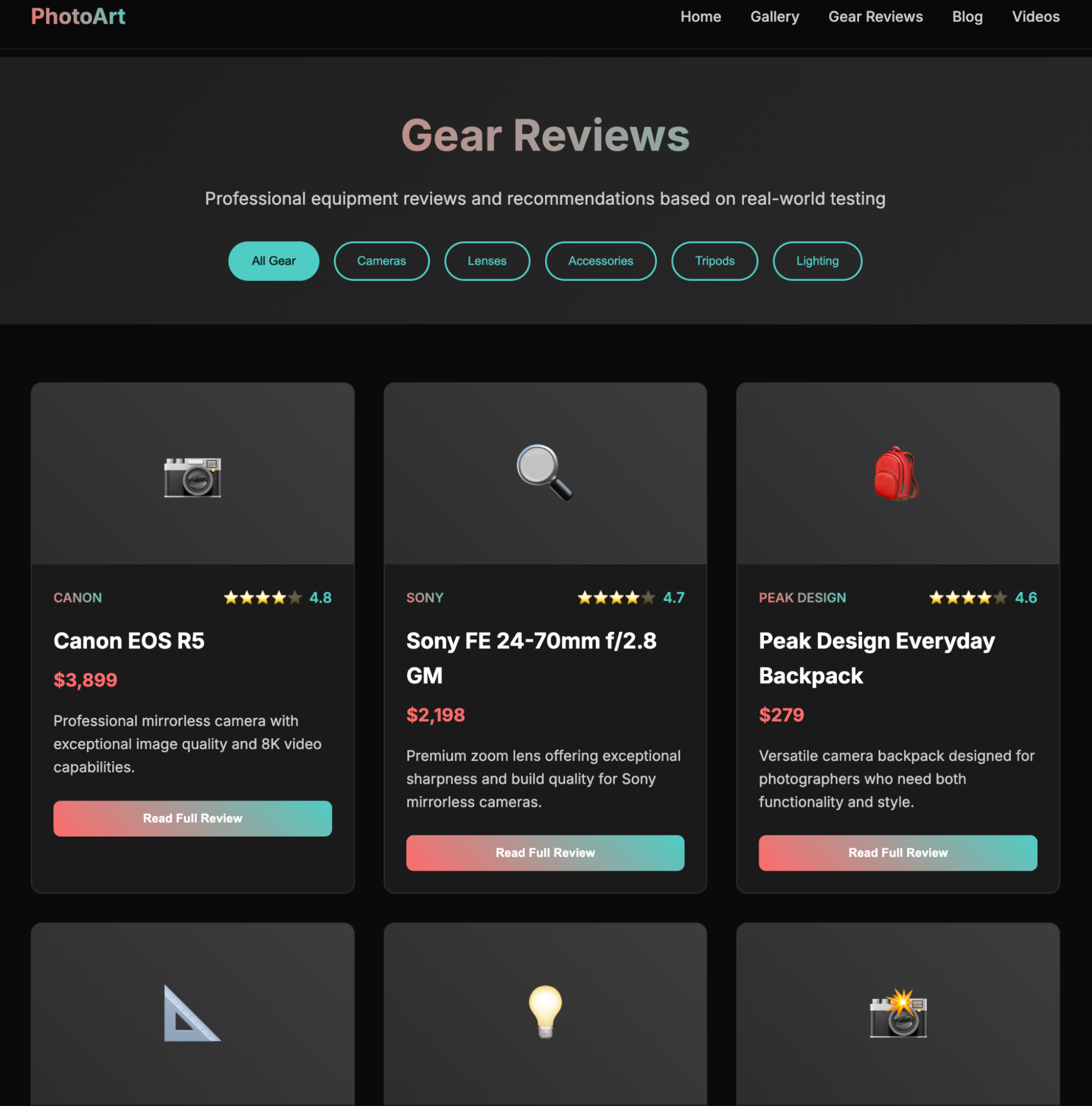
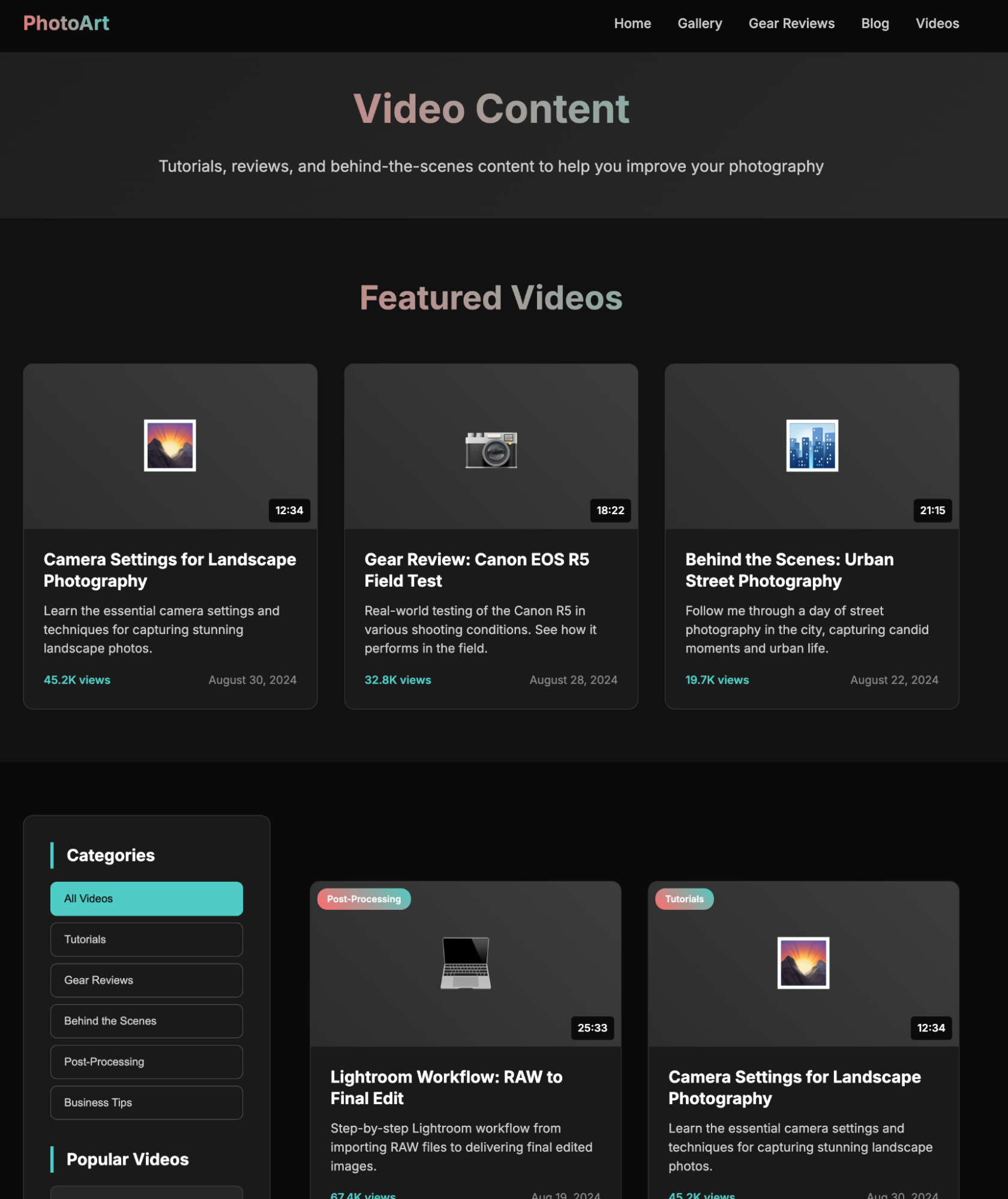
Of course, the same problem with Claude Code from last time persisted: I used the Astro framework, but the project didn't seem to understand the standard usage of Astro. It hardcoded every page, so it's still not a usable product.
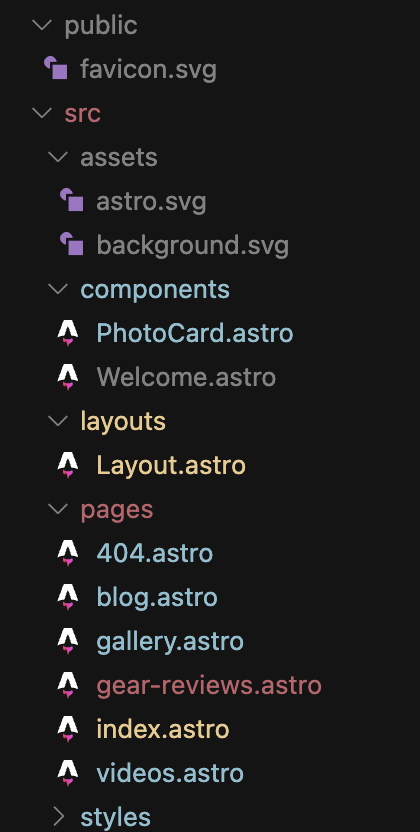
While Gemini is lazy, it's "smart," using Astro exactly as it should be used.
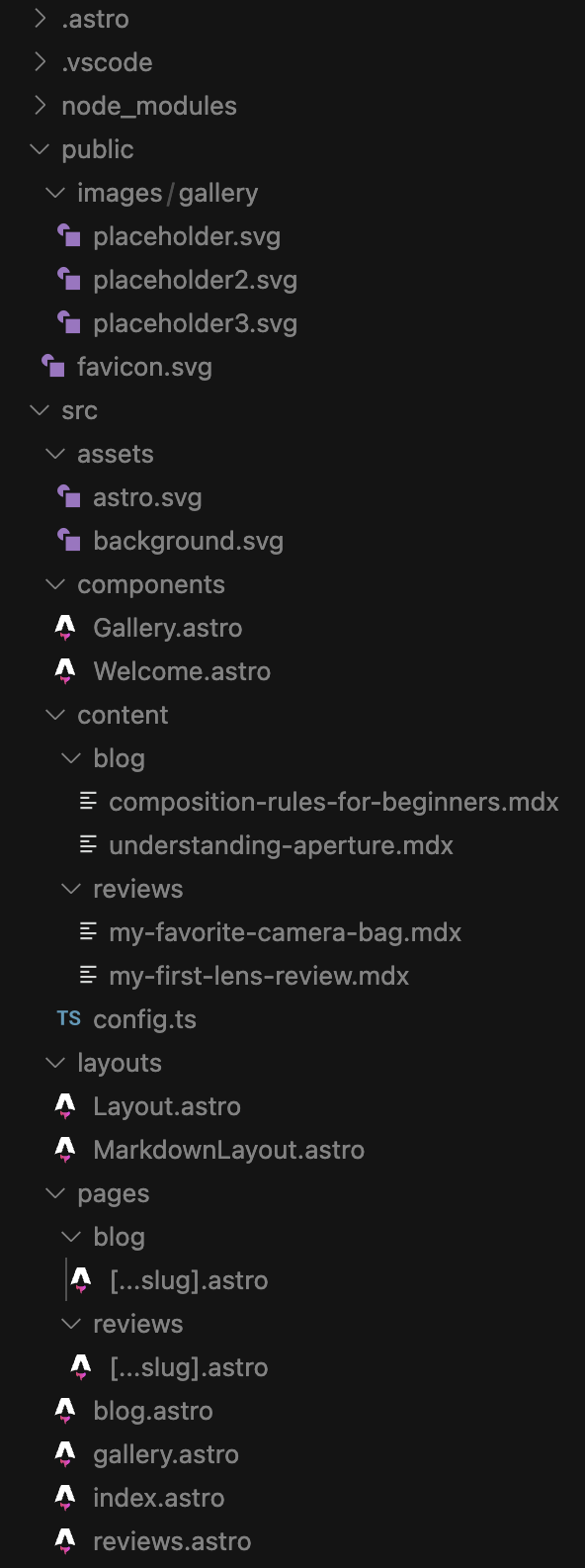
Codex was also good.
Yes, these two tests might be controversial. But I stand by my view: the critical area for AI Coding is various tools, focusing on specific business logic implementation rather than so-called "algorithms." These tests are what I believe reveal the most issues.
Conclusion: I am very uncomfortable with the changes in Claude Code. It has made me worry about the future of models: if minor logic changes in data or RL can cause such drastic shifts in output, does it mean models won't be ready for high-reliability production for a long time?
We can see clearly that in the Agentic AI era, there are significant differences between the three major models. Regardless of external opinions, they remain the three most distinct peaks in the model genealogy, while other models often feel like they share the same clear lineage.
Finally, back to the original purpose: at least in programming, Codex Cli can't quite replace Claude Code yet. Despite the improvements, GPT-5 is still not a model suited for code generation. Its best application is its unique agent capability—flexible and "specific." While it may not be "smart," perhaps diligence compensates for that.