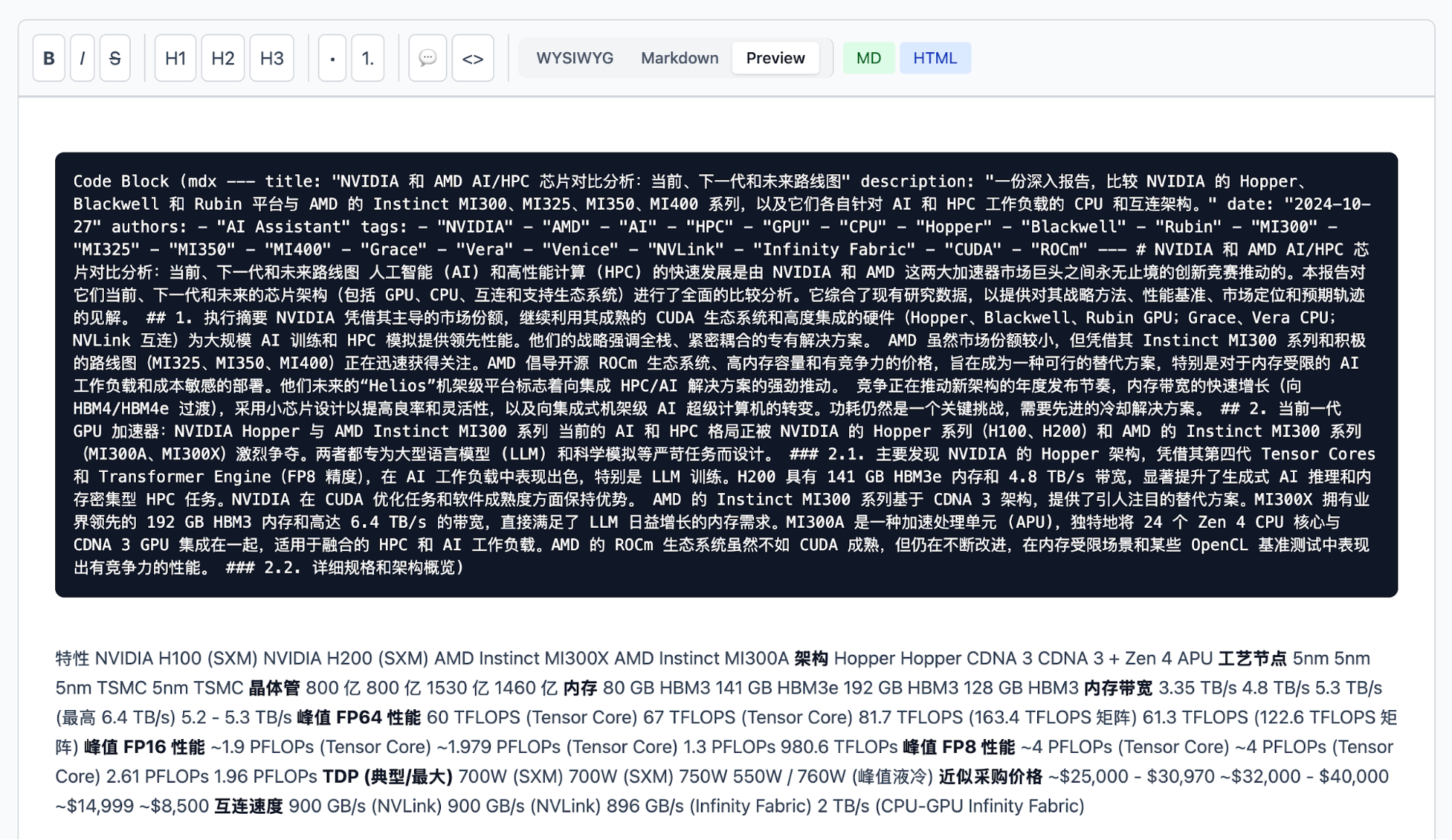
My weekend project was to continue optimizing the GUI part of OpenResearch. I originally planned to revamp the preview effect of the MDX editor, but that required quite a lot of changes. I used to frequently use the Astro framework, so I really underestimated the detail-oriented issues of not relying on an existing framework. This was quite challenging for Claude Code. After a few rounds of back-and-forth, I ended up with something like the image below; of course, I need to stop and think about the component architecture later.
A small interlude: Claude Code likes to add some page testing steps. This time, without me noticing, it replaced the data of an entire article with test data. Fortunately, the backup information was all there, so I manually modified the database data to restore it.
Then, during the restoration process, I discovered a redundancy in the backend data saving logic. Without thinking much about it, I subconsciously let Claude Code change the architecture. Halfway through, it hit me: on one hand, it was exactly this redundancy that allowed me to restore the data manually so easily just now; on the other hand, I just want a functional tool that produces results—is it really necessary to change such redundancy?
It's another classic case of "perfectionist fantasies" affecting execution.
However, during the modification process, the database structure had already been changed, and there was no turning back because rolling back the code wouldn't fully restore everything to its previous state.
So, halfway through, the familiar notification appeared.

Before August 20, Claude Code would warn you when you were about to hit the limit. Now, it just pops up suddenly and takes effect immediately. Fortunately, the progress was interrupted by lunch and a nap, so the "time-out" lasted less than an hour—just enough time to write a post to "criticize" it.
Before this "project," I generally used Cursor or Claude to generate code in two ways: first, create a minimal MVP and gradually transform it; or first have GPT, Gemini, or Claude produce a design plan, and then have Cursor or Claude Code handle the execution.
Interestingly, among the tools I am currently still using, all were implemented using the first method.
But the OpenResearch project is a little different:
First, it has a pure frontend part. I drew a sketch and let Gemini's Deep Think (the model that claims to be an International Mathematical Olympiad gold medalist but is limited to five uses a day) turn the sketch into a design document, then handed it to Claude Code to implement in phases—specifically in the ui directory under the GitHub repo.
Second, I used Gemini Cli to generate an architecture description document for the pure frontend MVP part (in this regard, Gemini Cli is slightly better than Claude Code).
Third, I gave this architecture document back to Deep Think, told it my complete vision for the front and back ends, and had it generate a design document.
Fourth, I handed the design document to Claude Code for implementation. This process involved several iterations, constantly modifying the architecture based on problems Claude Code encountered, going back to Deep Think for documents, then implementing and modifying again. There were at least five major overhauls.
I once thought the above method would fail and I'd have to wait for the next generation of model updates. But, thanks to luck, it's mostly working. Furthermore, the CloudFlare backend compatibility is good, maintenance costs are very low, and it's very favorable for the "secondary development" of generated content. Of course, another complete backend option could have been Supabase, but the maintenance load would be significantly higher.
This process leads to the first question: Has the emergence of tools like Cursor and Claude Code lowered the barrier to software development? My answer is the same as many programmers with over ten years of experience: a negative one. This isn't out of conservatism (clearly, I'm not conservative at all).
Over the past year, I've shown many examples of one-click visualizations, websites, and tools. These undoubtedly lower the barrier significantly. But once slightly complex interactions are involved, the barrier rises sharply. The success of an AI-generated project ultimately depends on the human: human judgment and process oversight capabilities.
Yes, I believe Deep Think is currently the "smartest" model. Claude Code can implement the design plans it generates without "collapsing." But before delivering that design plan to Claude Code, it is "I," the human, who makes the judgment of "good" based on failed experiences and lessons that don't appear in training data.
In the execution phase, I often let Claude Code automate batch tasks, but I'm not idle; I'm "monitoring" almost the entire process. Once I notice something is wrong (accessing too many project files, adopting unnecessary execution methods), I interrupt and adjust it. This is similar to what Karpathy mentioned on X recently. This also comes from the "confidence" of humans based on lessons learned from data that cannot be trained.
Therefore, I have always believed that AI will completely disrupt "Software Engineering" (that thing I've hated for over twenty years), but it will never replace programmers. AI is simply the programming language of the new era, expressed in natural language.
Second question: the way of working. In another side task, Gemini Cli burned through 1.5 billion input tokens to finally complete the first step of a new idea (after re-evaluation, I think the token consumption could be reduced to a few hundred million. But I won't determine the optimization direction until I have a relatively complete result. Without GPT-4, it would have been impossible for DeepSeek to train V3 with only five million dollars in GPU time costs). During this period, I didn't let Gemini Cli generate a single line of code; it delivered structured information processing results.
Is this a program? Of course. Everything that deals with the digital world is a program.
However, in this process, it also frequently made errors and veered off course. I needed to stop, help it recalibrate its direction, and even manually fix the "disaster sites" along the way.
Just like every line of code we write, every program, and every project, bugs are always flying everywhere. But we have gradually become accustomed to using programs as much as possible to solve problems encountered in our work and hobbies; it makes us better.
So, is AI Coding still the same as the code itself? Of course not. It is our workbench for solving all digital world problems. It frequently gives you "aha" moments and frequently creates "car crashes," but working with it is our ultimate answer and, of course, our greatest challenge.
So, does the AI era mean we shouldn't choose Computer Science as a major?
Perhaps the answer is quite the opposite. I even had a thought: maybe in the future, a PhD (Doctor of Philosophy) should be renamed to CSD (Doctor of Computer Science).
Because Computer Science doesn't teach us how to write code; on the contrary, programming languages are the least important part of the discipline. What truly matters is how systems run, how algorithms are used to solve real-world problems, and how humans continuously create and fix disasters through "limitless" experimentation.
Conveniently, my Claude Code limit has been lifted. Back to my weekend project, OpenResearch. In the beginning, I wanted to do "Research," but now I feel that only "Open" is important—not just open-sourcing code, because code is "trash" and worthless. The thing that truly needs to be "Open" is always oneself.