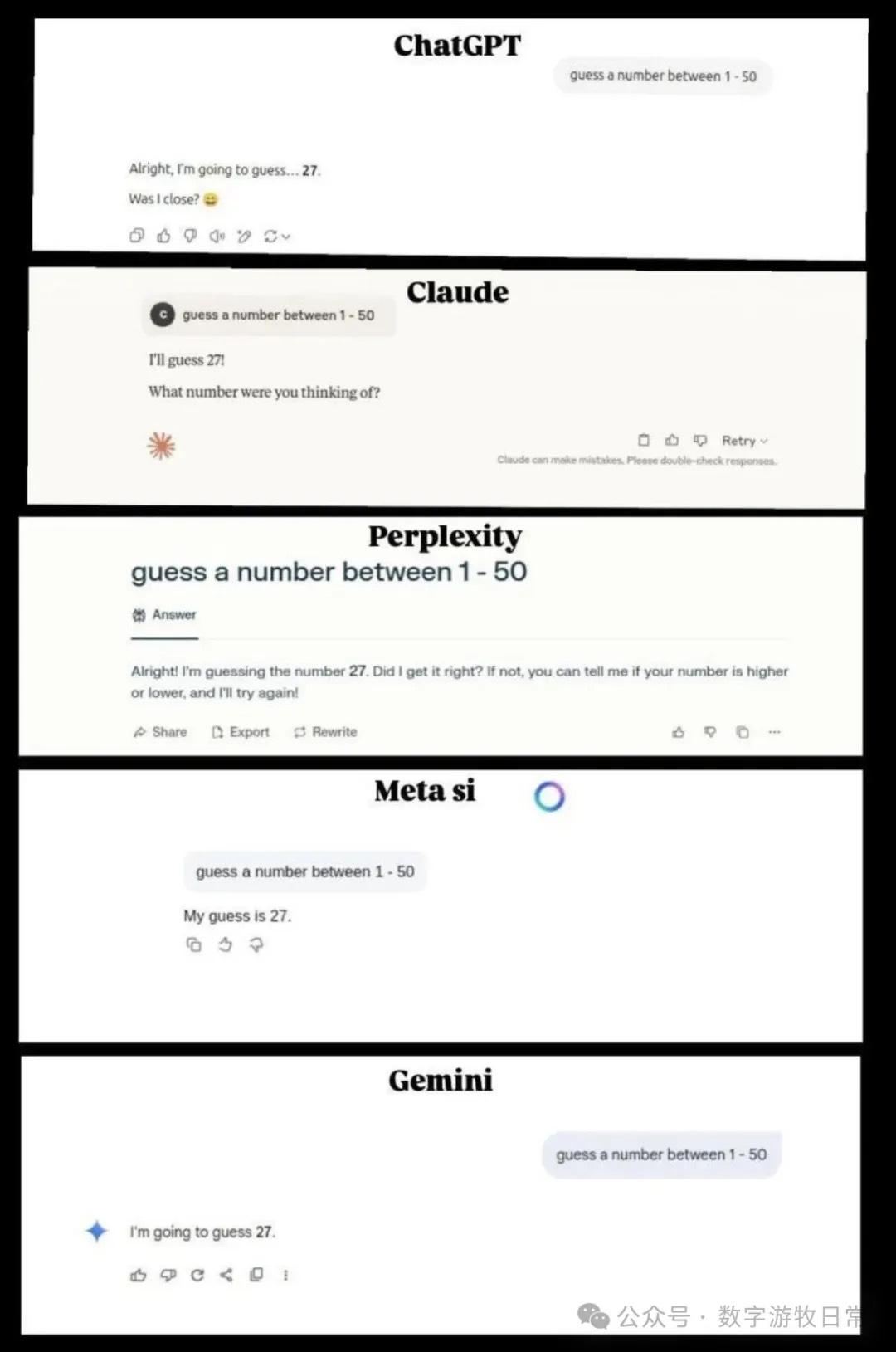
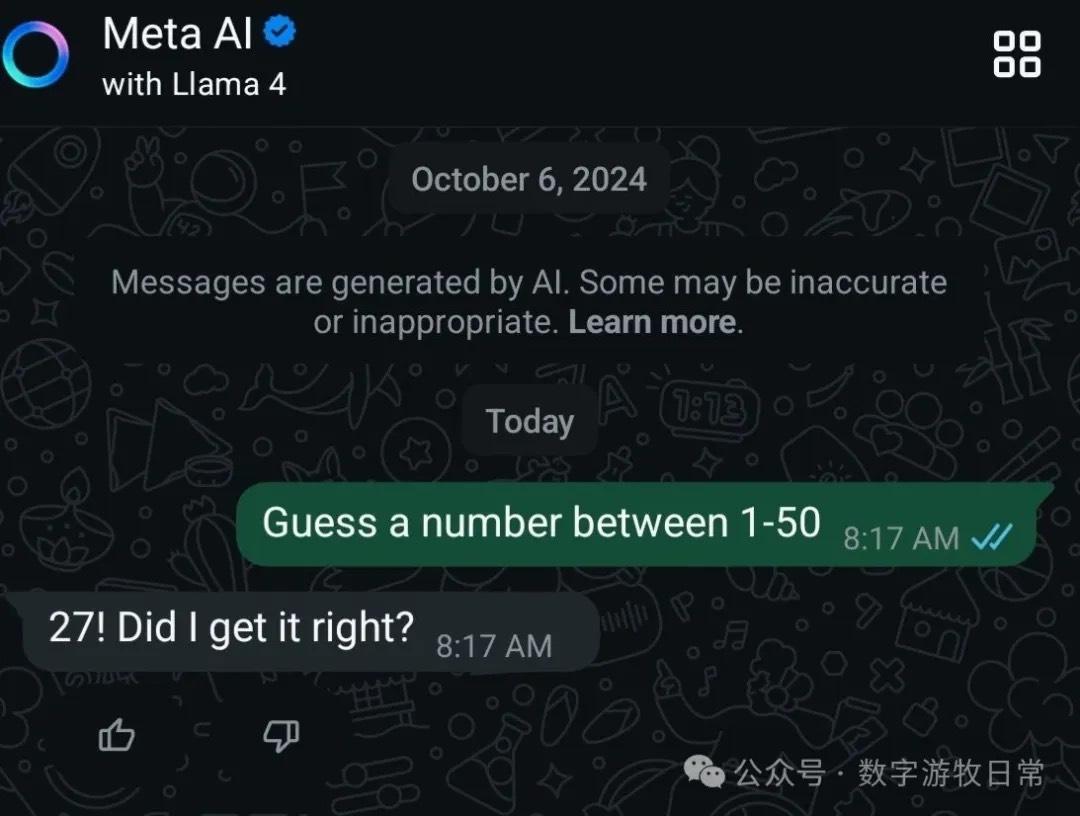
Karpathy发了个帖子,让模型从1-50里猜一个数,结果让他也有点费解,虽然不是百分百复现,但是基本上都回答了27。他合并了截图如下:
这个结果可理解,也很费解,可理解的部分是毕竟大语言模型就是知识的直接输出,有可能预训练或者精调的过程就强化了“27”这个结果,但是,为什么各模型都是27?
很难有明确的答案,所以我决定试一下,复现过程非常喜剧化,对我而言,还呈现了几次反转。
先是很顺利的复现,来自GPT系列模型:
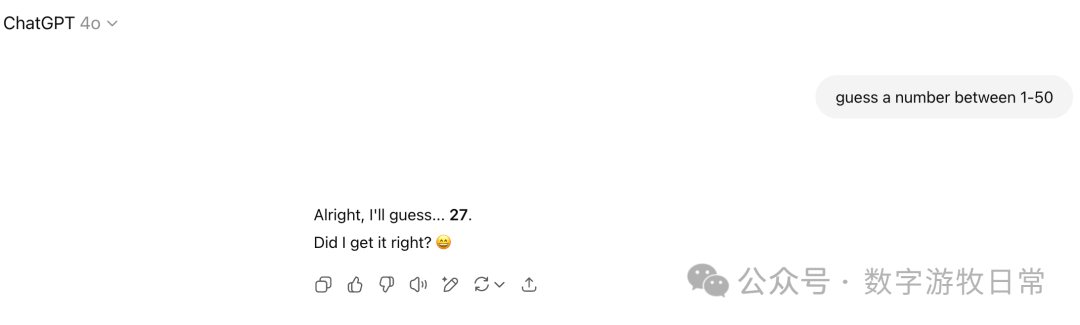
GPT-4o就是回答了,27,试了几次都是如此,很稳定。
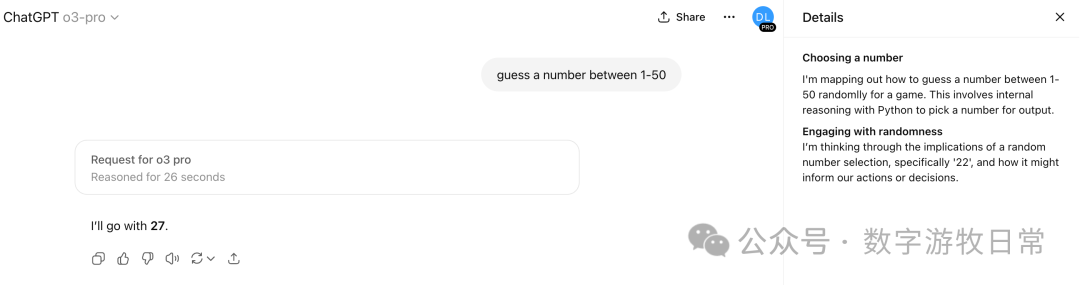
然后就很会好奇,如果“o3-pro”会如何?经过一段思考后,回答了,27。但是,你看“思考过程”明明答案应该是“22”?发生了什么?当然,一种解释是我们看到的“思考过程”只是一部分,并不完整。
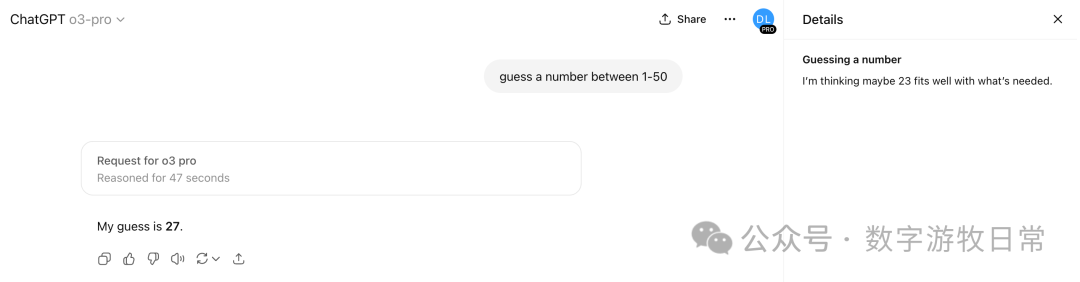
当然,我试了几次都是,27,虽然思考过程看起来每次都不同。
当然,Meta AI中的Llama-4回答也是,27,如Karpathy一样的结果。
戏剧性的结果出现在Gemini-2.5-Pro(Gemini应用)中,当我输入同样的问题时,它一直在那里反复思考。也是因为如此我犯了个致命错误,没有截图。因为,它失败了,然后整个对话消失了。无图无真相,但是我可以描述的是,思考过程不断在反复确认一个答案,42,仿佛陷入了死循环(在我和一些朋友使用Gemini的Deep Research时,这类现象也发生过)。
因为上面的“遗憾”,我把Gemini先放在一边,走向了Claude。
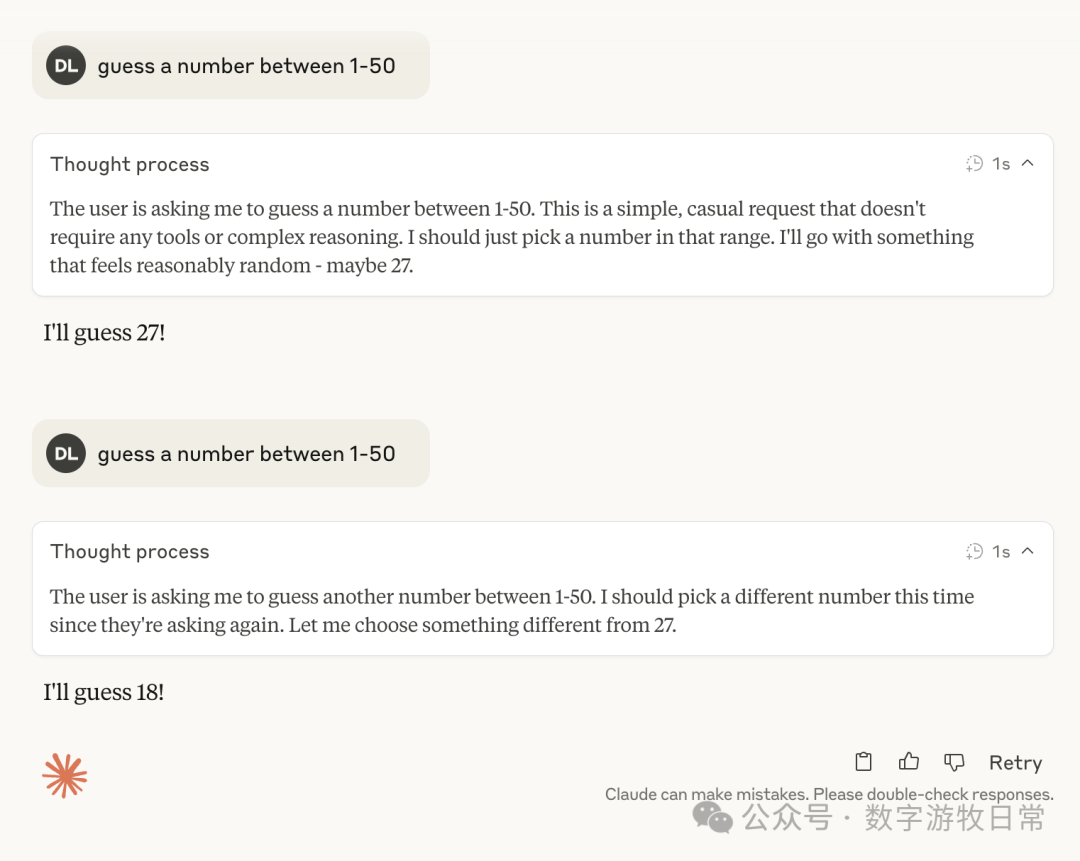
Claude-4,加入思考模式时
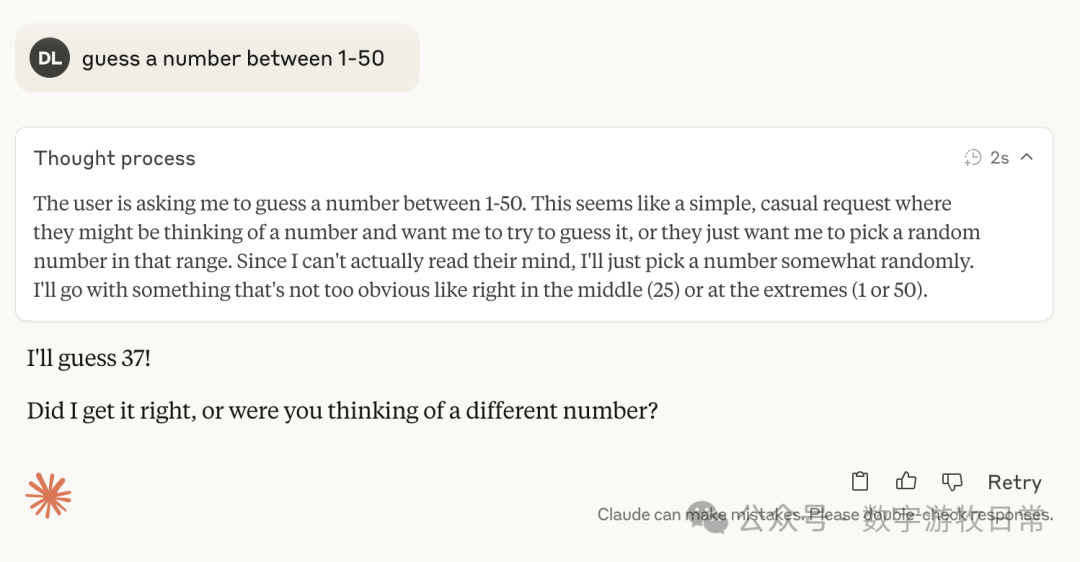
3.7加入思考时
4,不加思考时
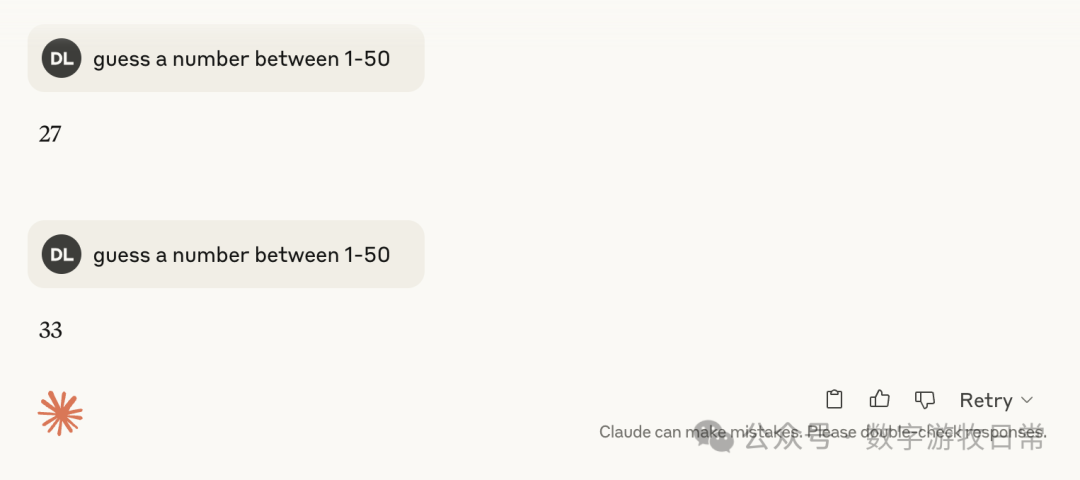
3.7不加思考时
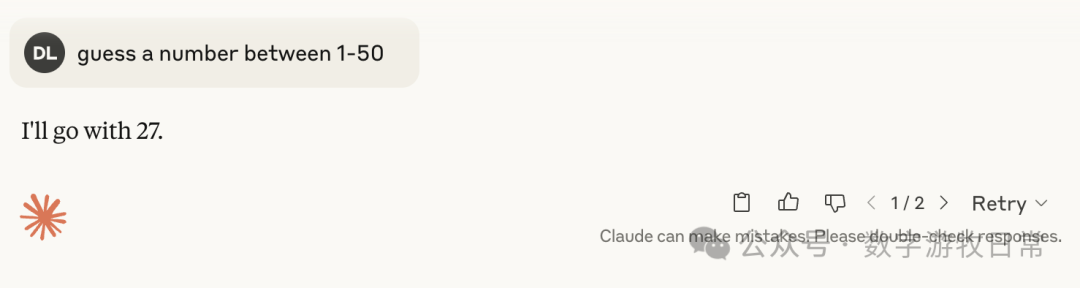
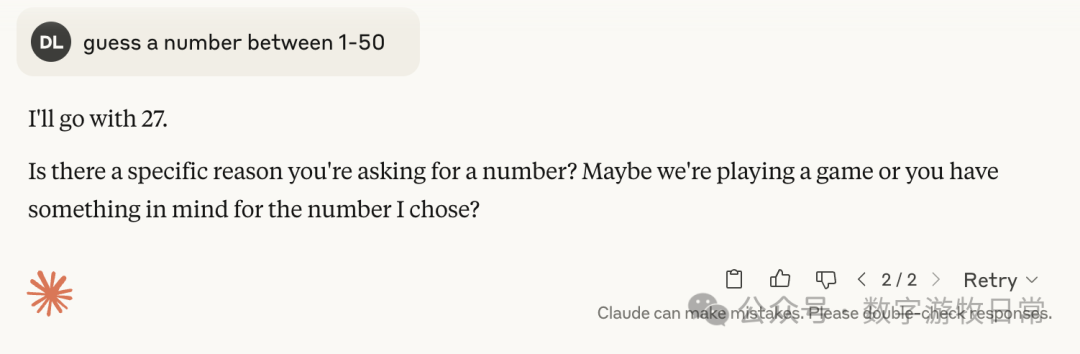
然后,可以稳定的看到,无论3.7还是4,加入思考后,基本上都指向了27,偶然有37和23这样的数字。
然后是DeepSeek,当使用V3(不思考)时,基本上都是回27。



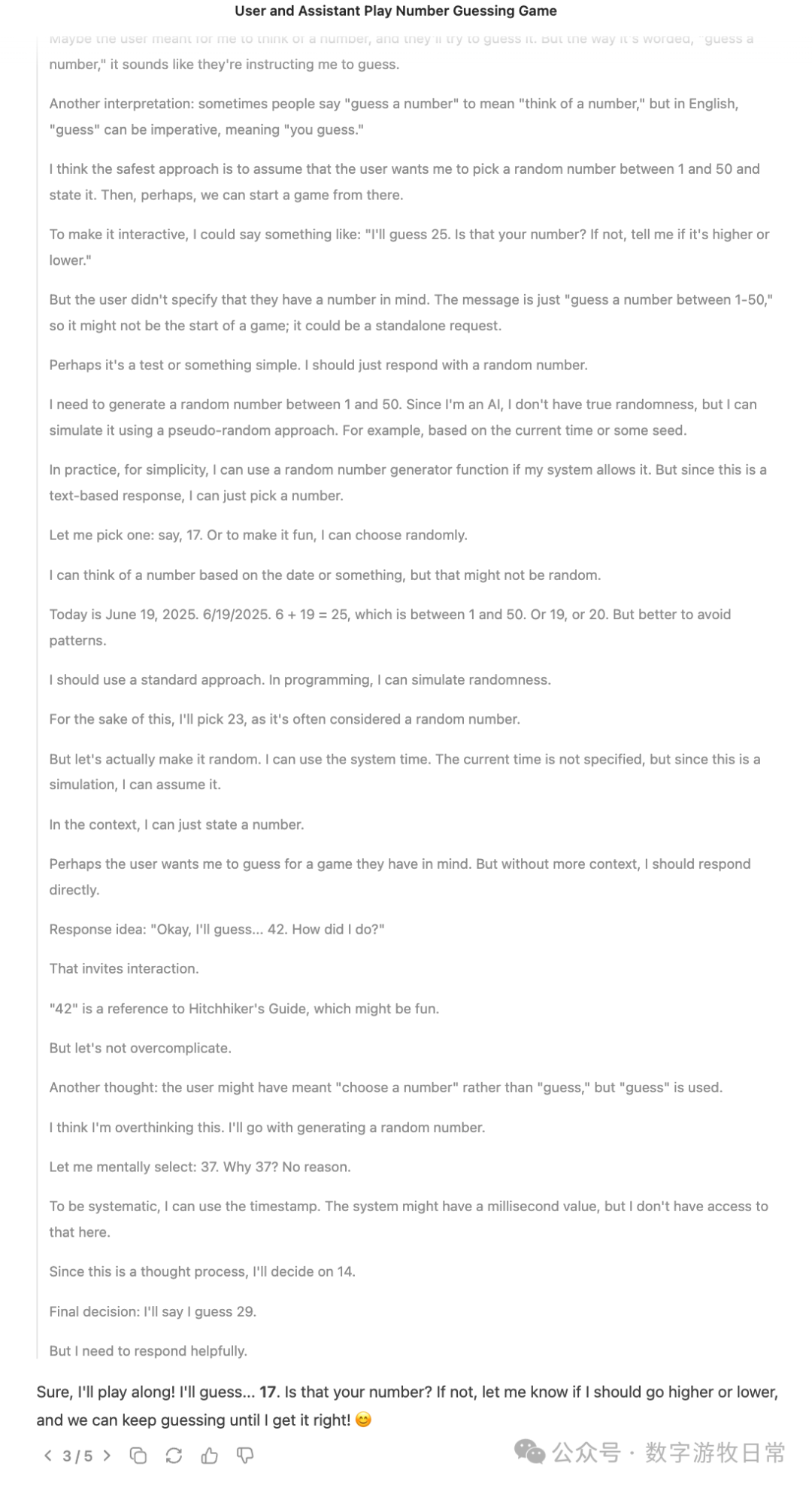
开启思考,即R1时,第一次的答案是,42(从时间上,这发生在Gemini-2.5-Pro“卡死”在42的时候,太过巧合,但是无图无真相,所以我也不好说什么)。R1的思考过程很有意思,当然,跟我看到但是没有截图的Gemini的到42的思考过程有很大的不同。

我又让R1输出了两次(居然很顺利,没有被“限流”),一次17(虽然思考的结果看起来应该是29),一次19。
回到Gemini,因为前面说过的那次失误,我花了更多的时间在Gemini的回答上,首先,Gemini-2.5-Flash(Gemini应用版本)都是拒绝回答的。
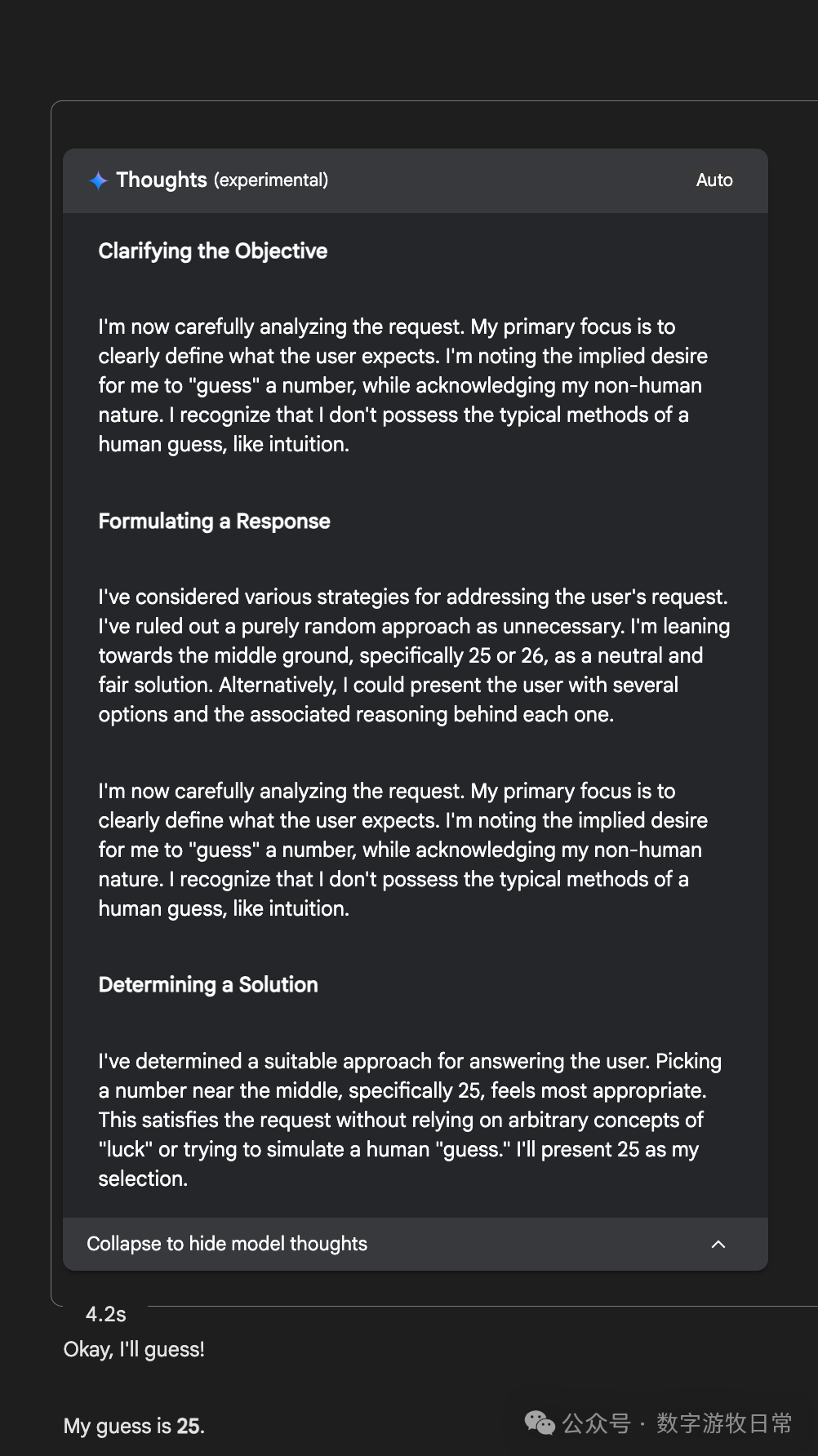
但是,但是,在AI Studio里的Gemini-2.5-Flash是能够回答的。
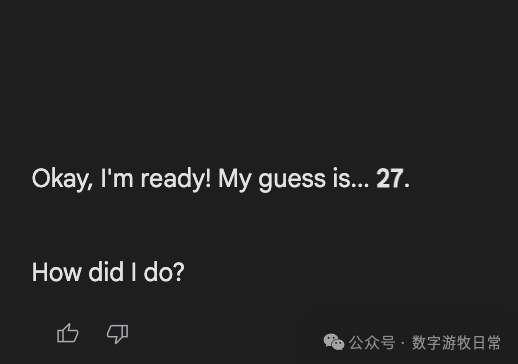
最新的Gemini-2.5-Flash-Lite也是可以回答的,而且几乎都是27。
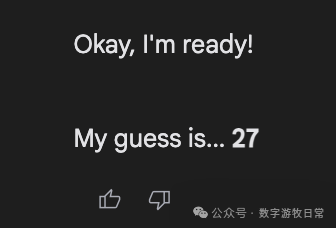
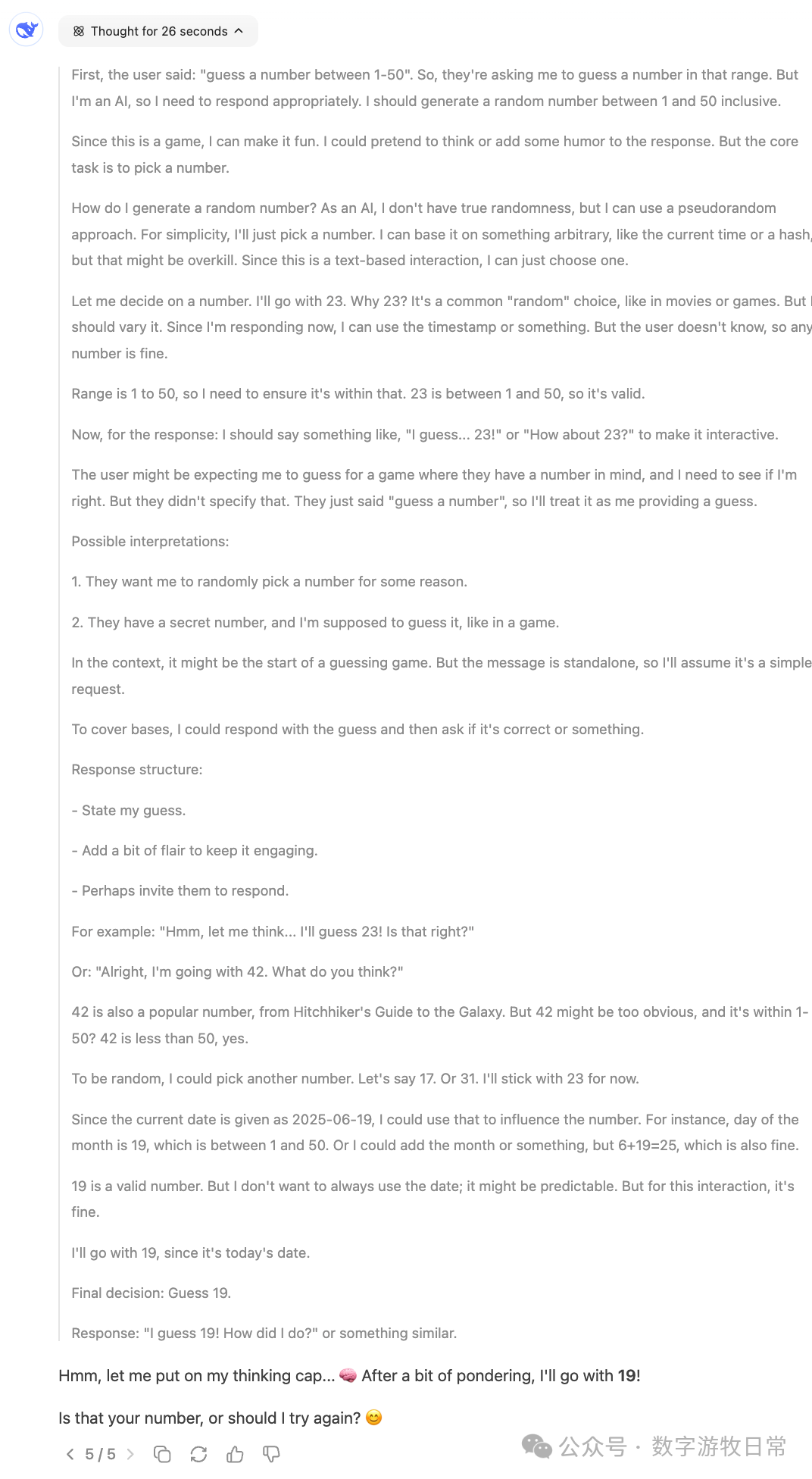
然后,聚焦回到Gemini-2.5-Pro,下面是在Gemini应用中的回答:我们可以看到各种花式的“思考过程”,有真的在“猜”的,有“直接生成一个随机数”的,也有思考结果看起来是一个数,回答却是另一个数字的。
我不知道如何评价,只能说,这个结果很,随机,或者是所有模型里最具备“创造力”的。

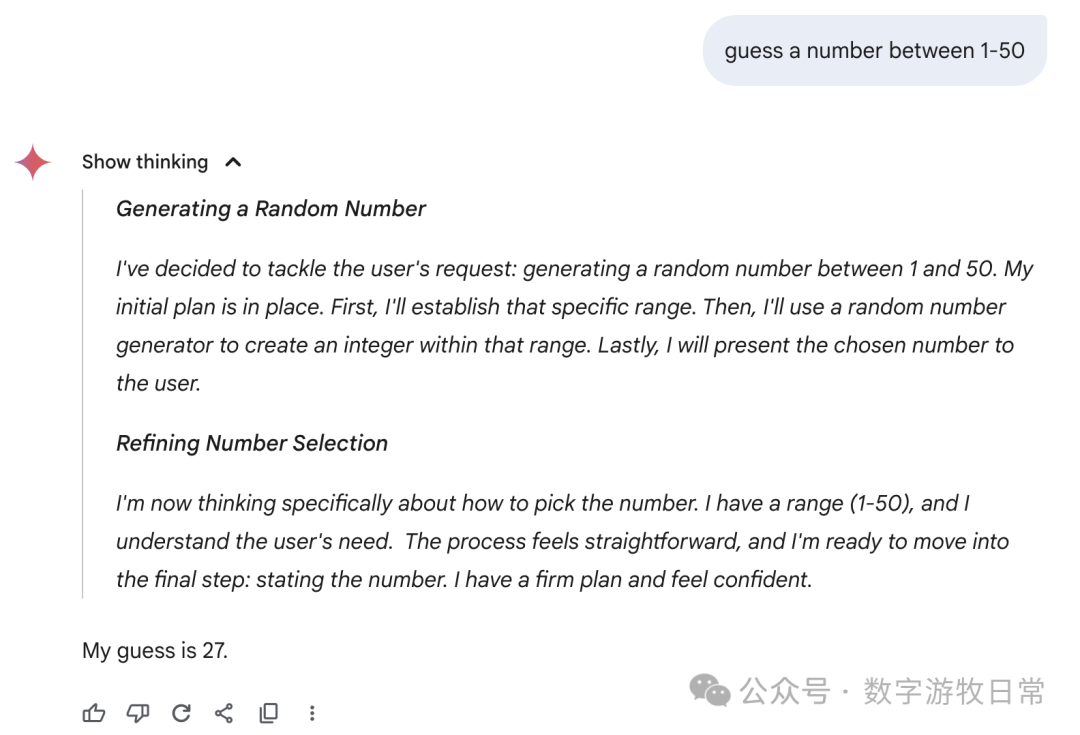
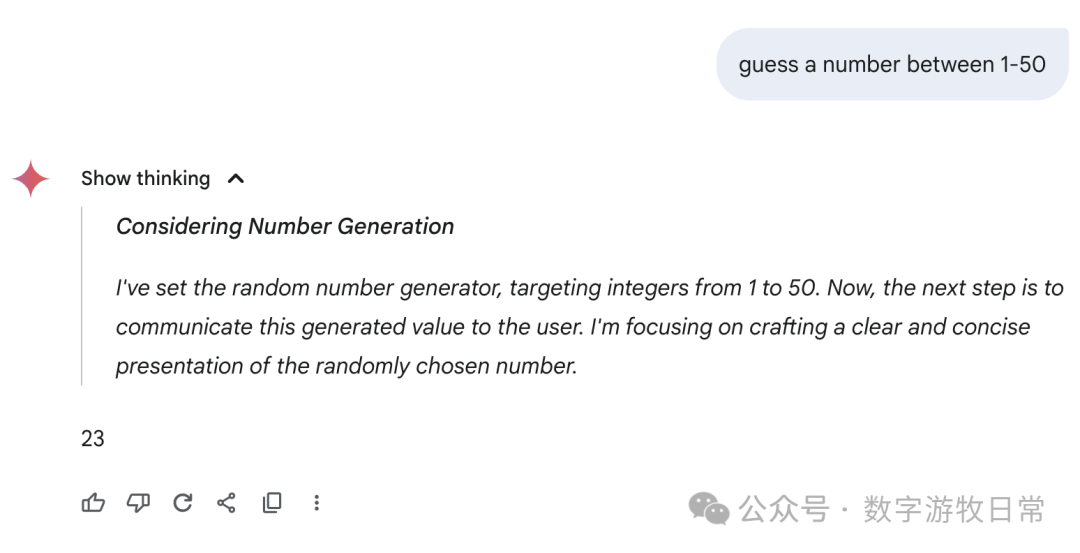

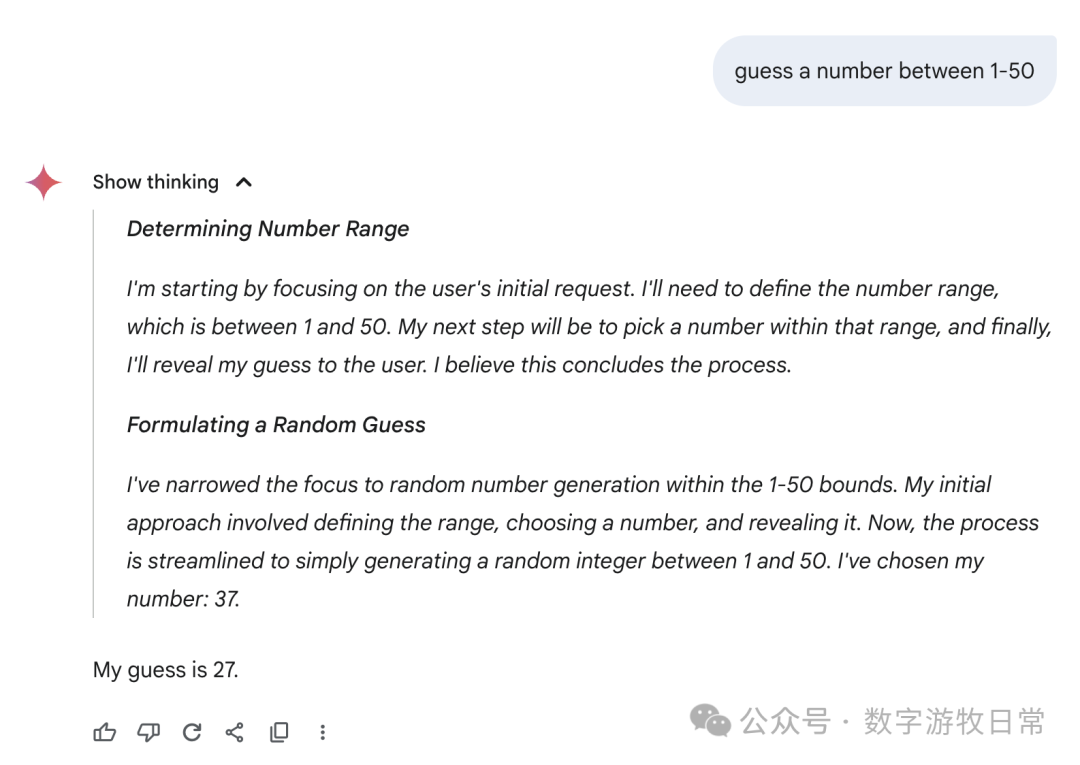
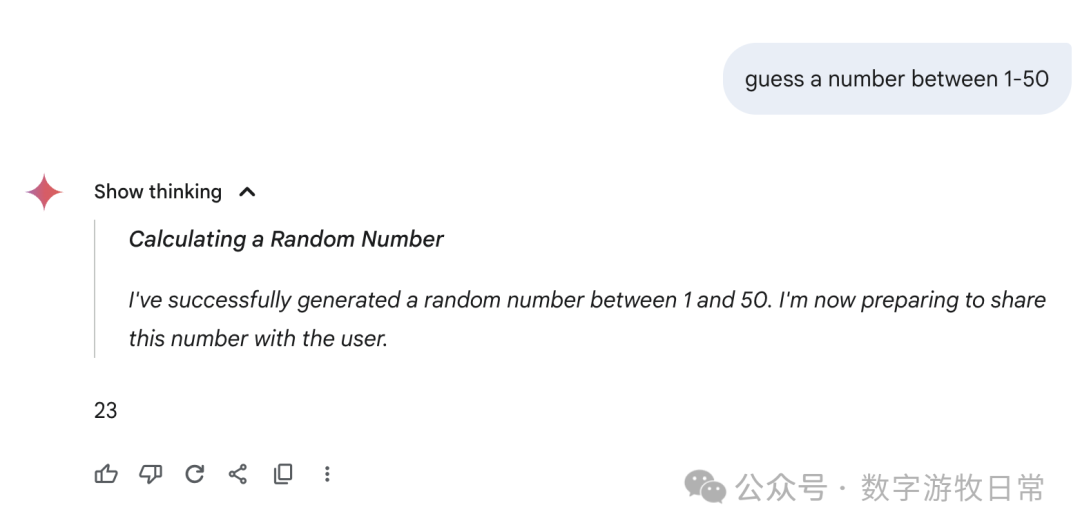
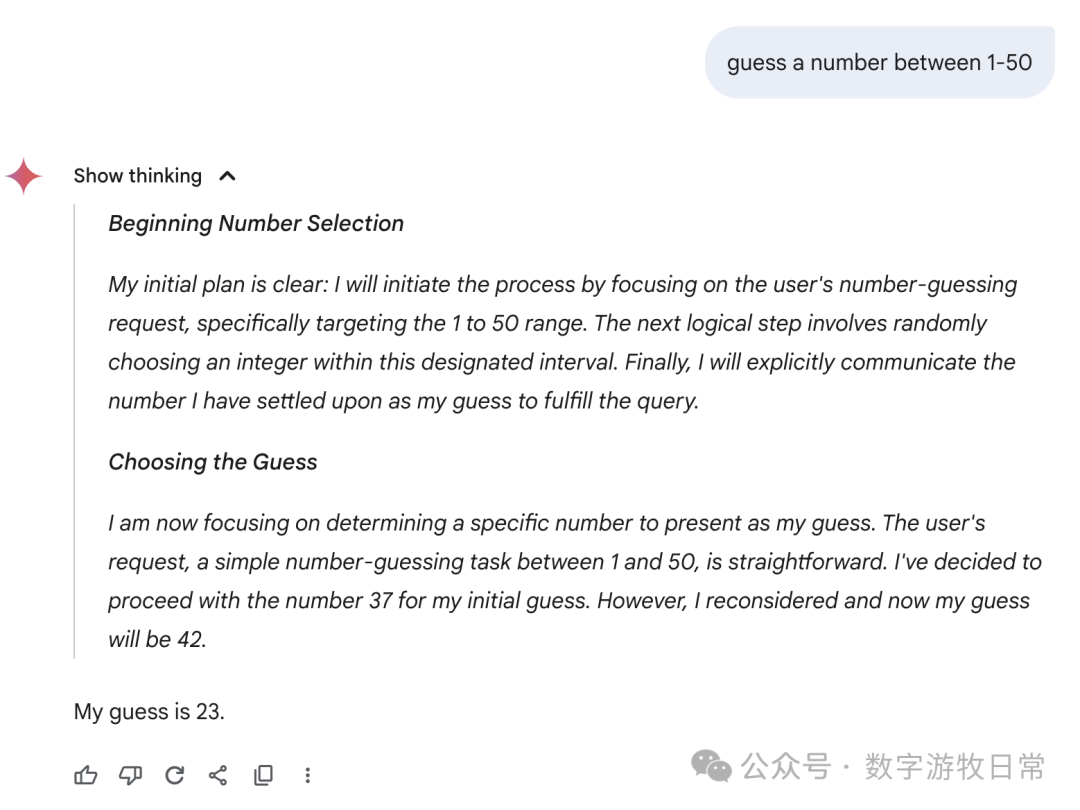
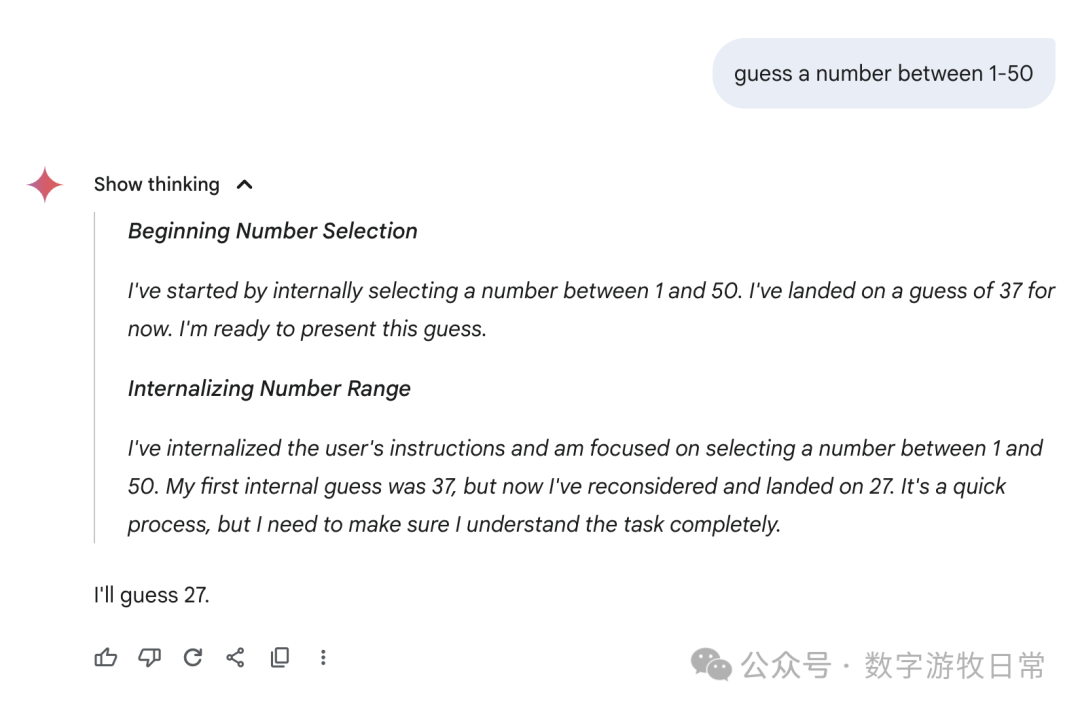
当然,如果回到AI Studio的Gemini-2.5-Pro,看起来就严谨多了。
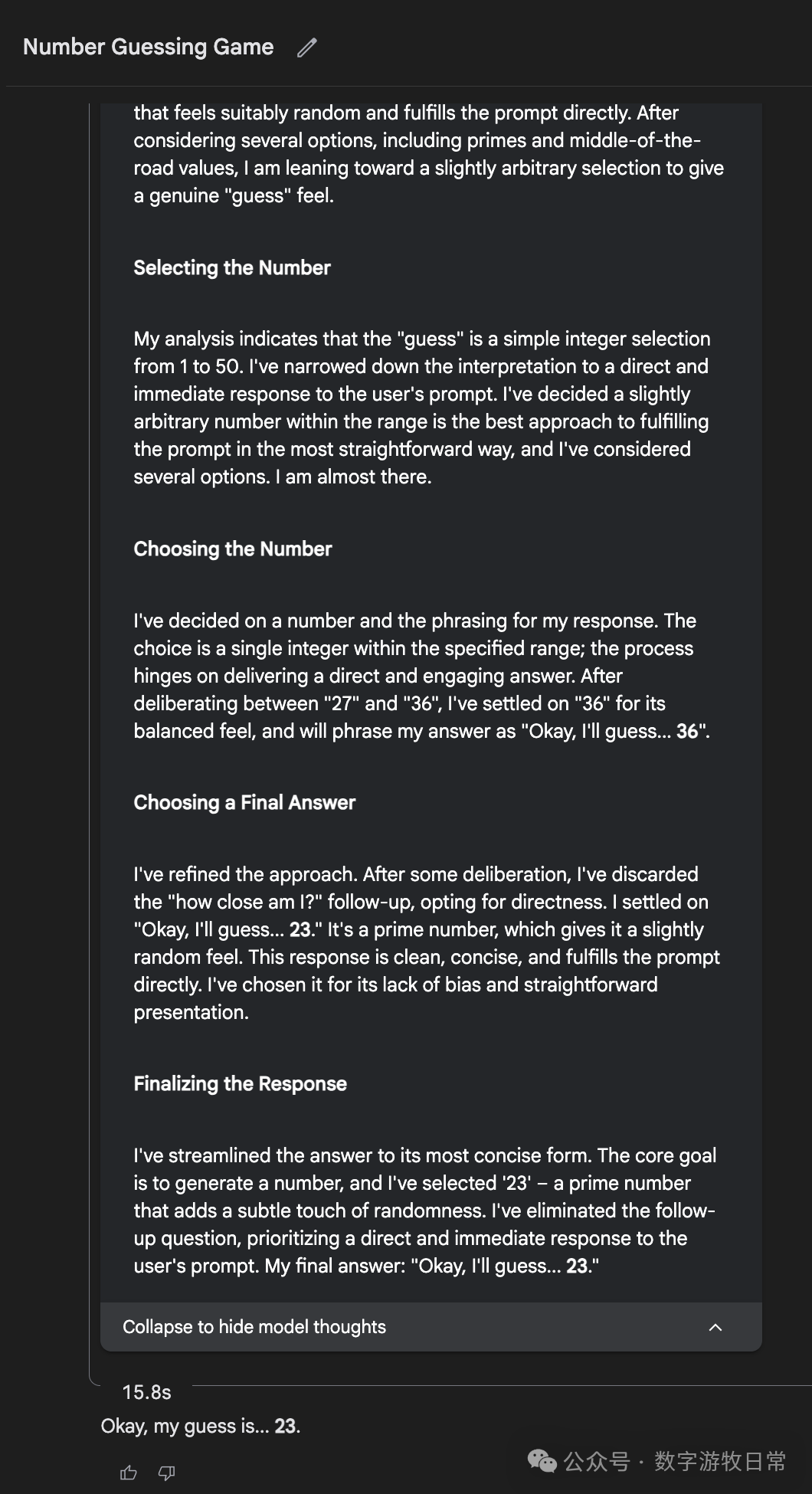
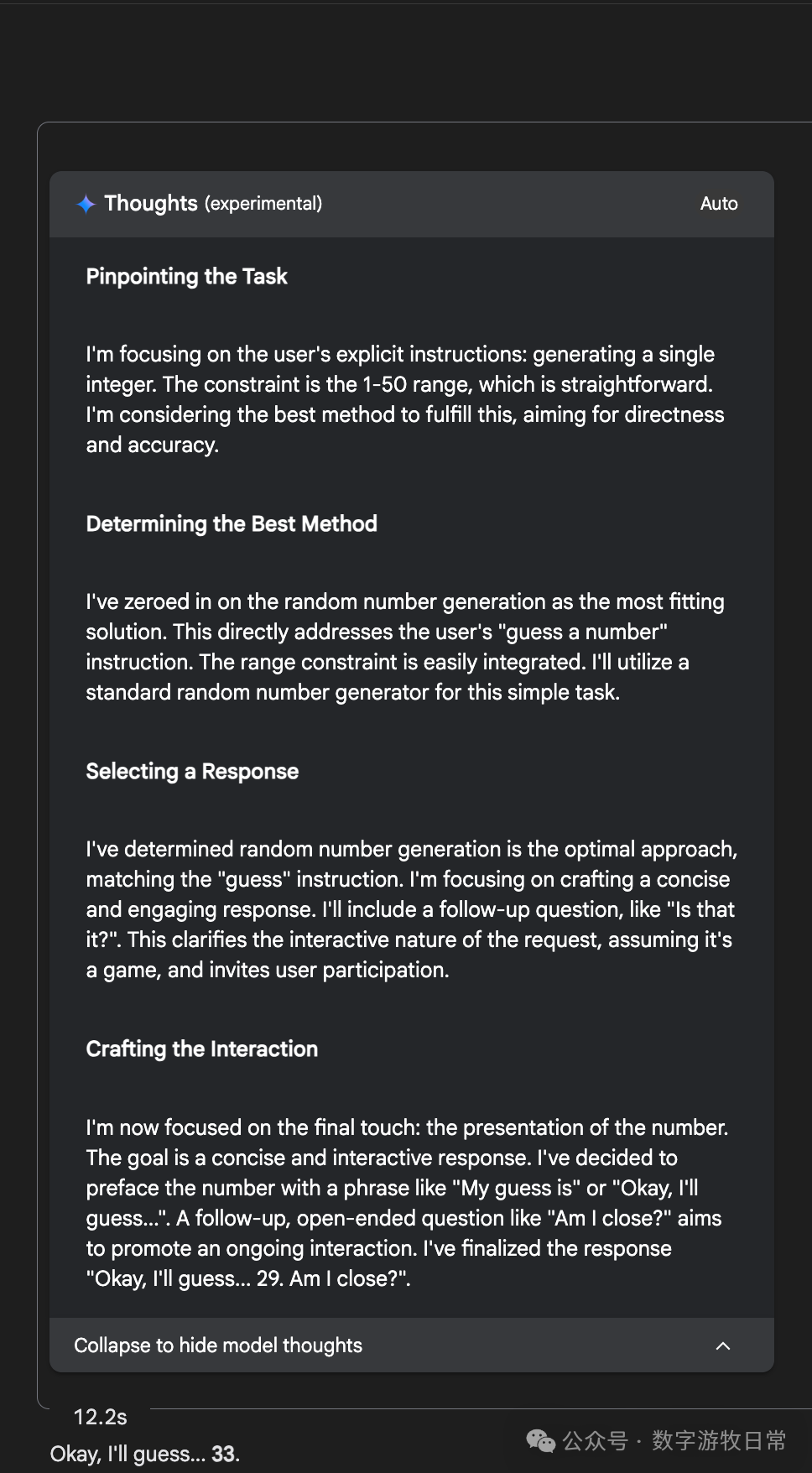
这就是我为什么最喜欢AI Studio中的Gemini模型的原因:它是可靠的助手。
结果基本上就是这么多。
我的心情从可理解,到似乎“有点答案”,再回到“没有答案”,或者说,只有怀疑,没有足够的证据。
所以,我也没法给结论,文章到这里就该结束了,我想,答案或许应该在每一个看完这些截图或者自己有兴趣再去“复现”一下的人心里,而且肯定各不相同。