Comparing AI Models' Analysis of NVIDIA's Earnings: Why I Prefer Gemini 2.5 and Claude 3.7
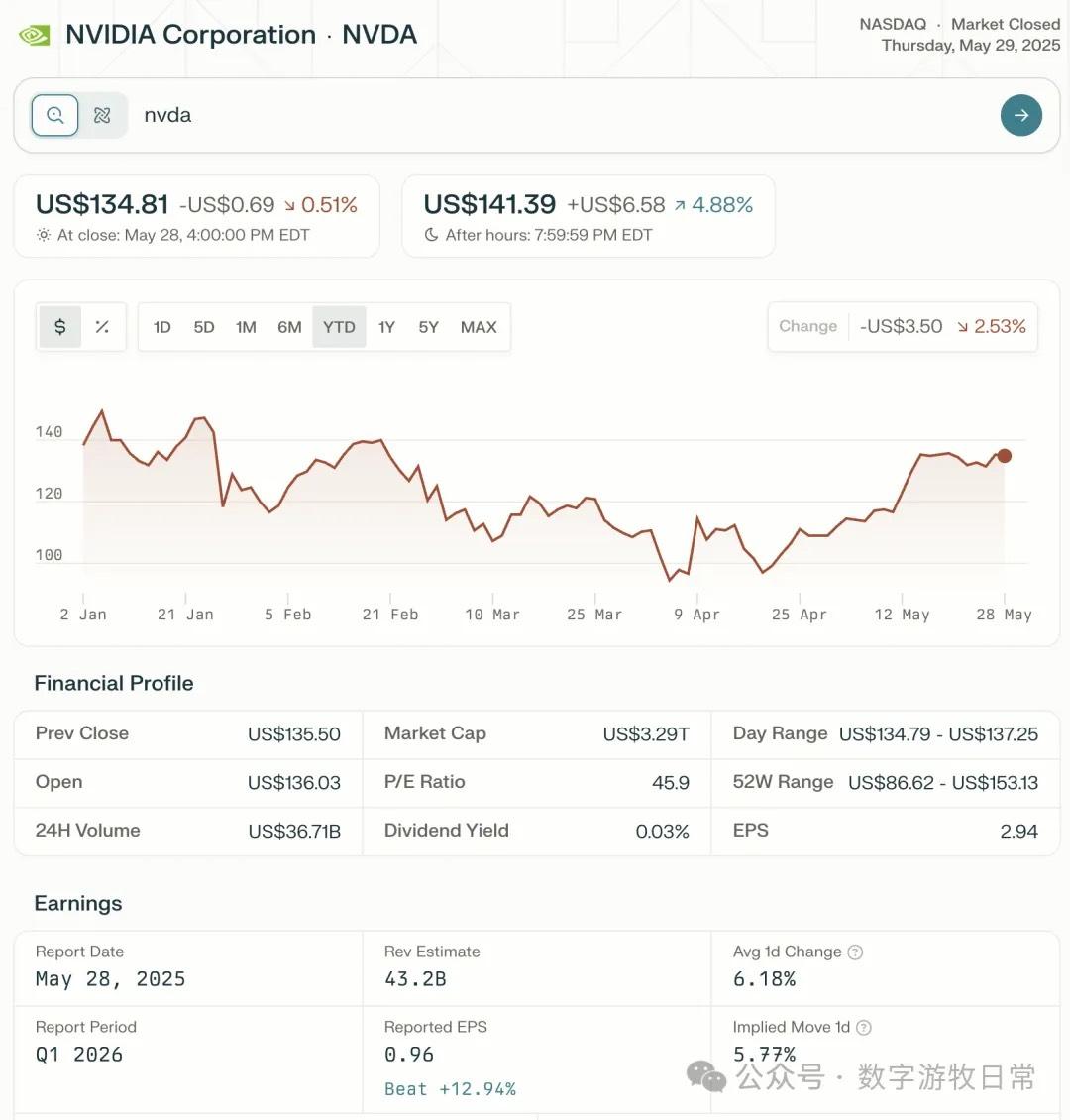
The most important earnings report in the market, NVIDIA FY26Q1, has finally been released.
Despite the impact of H20 inventory impairment, NVIDIA's performance continued to exceed expectations under its superb inventory and expectation management. That's the market for you—the same "beating expectations" and "optimistic guidance" are sometimes believed and sometimes not; it's all about "sentiment."
At this point in time, in an environment of information overload, various earnings analyses are already everywhere. Analysts will always emphasize that results "exceeded market expectations but were perfectly in line with our expectations."
Conducting subjective investment analysis on public accounts always carries a suspicion of "non-compliance." Since I have been comparing Claude-4 with other models (to be honest, I always feel Claude-4 is a somewhat strange model), I decided to leave the financial analysis to these models instead.
I used the same prompt to compare Claude-4-Opus, Claude-4-Sonnet, Claude-3.7-Sonnet, Gemini-2.5-Pro, and GPT-o3.
The prompt was very simple: based on NVIDIA's official news (https://nvidianews.nvidia.com/news/nvidia-announces-financial-results-for-first-quarter-fiscal-2026), generate a detailed, interactive Chinese slide deck. (There will likely be voices in the comments saying that evaluating slide generation ability is a generalization of the model's capabilities. Perhaps so, but the process of generating slides tests the model's thinking ability, hallucination rate, and of course, its coding ability—most importantly, it's directly usable. Do we really dare to let models handle all backend code? The most important foundation of AI code changing software engineering isn't surpassing how many programmers, but its entry into various industries' production—especially knowledge production—in a "disposable" way. By the way, AGI and current generative AI are two different things; perhaps generative AI isn't even a necessary condition for AGI. So, don't underestimate, and certainly don't mythologize, today's models).
First, let's look at the screenshot results of Claude-4-Opus (for certain reasons, I have removed some sensitive content and, for "compliance" reasons, removed the ratings from the investment advice).


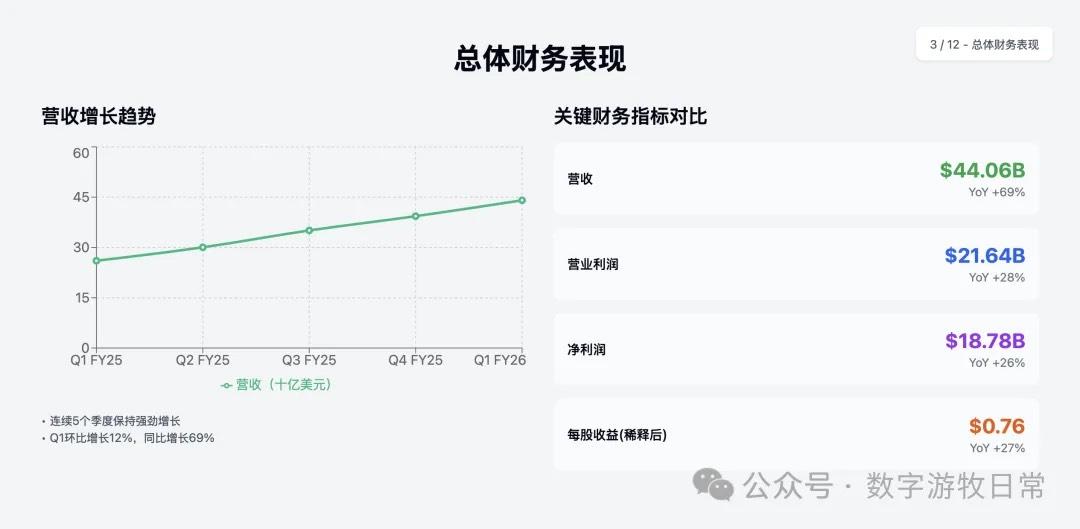
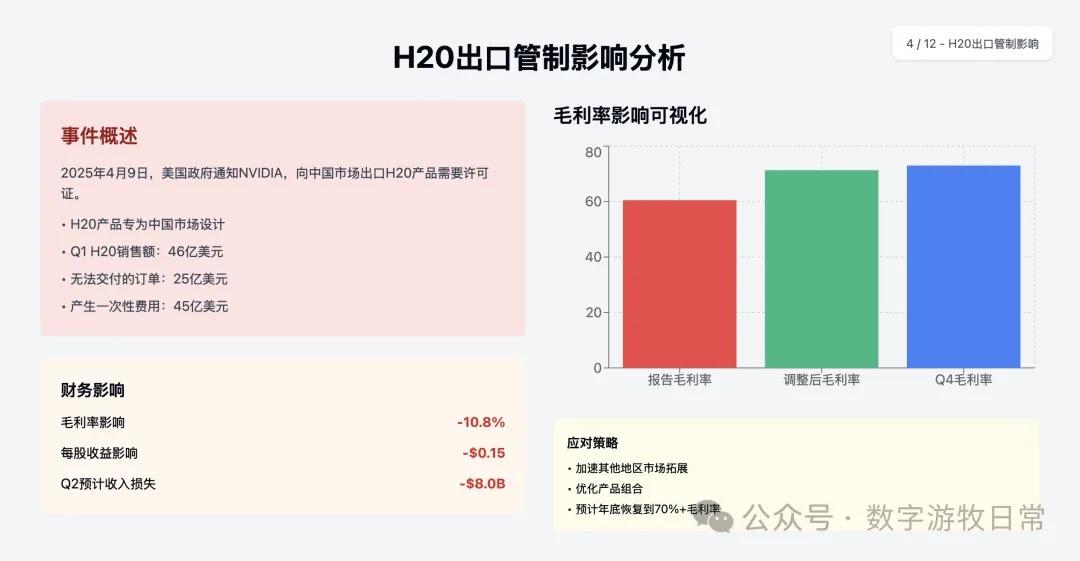
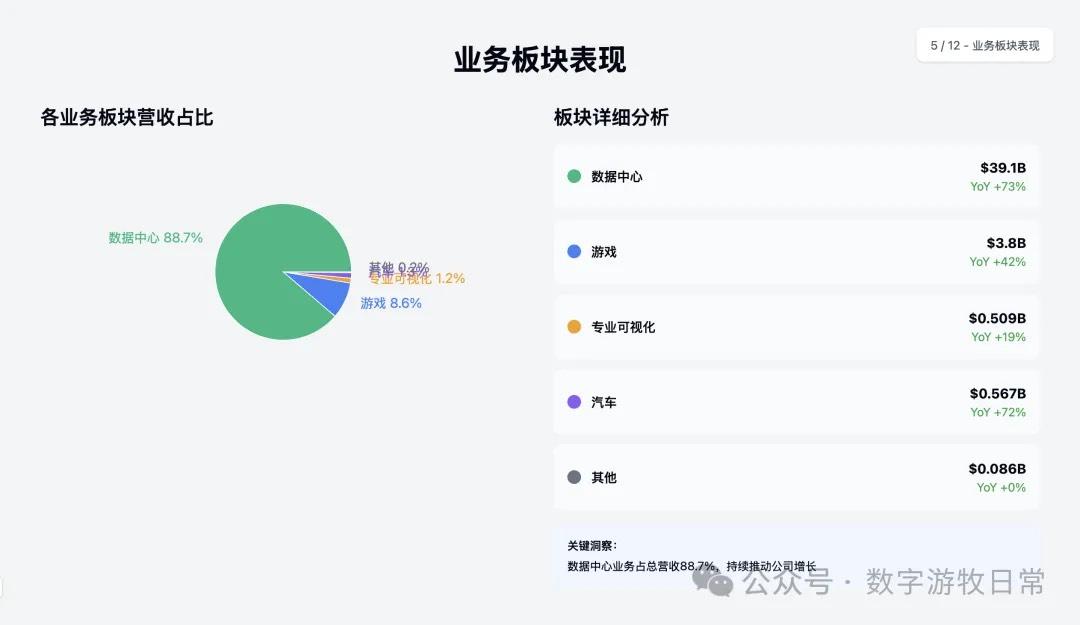





Next are the results for Claude-4-Sonnet (similarly, I have removed the specific investment advice section).





The third model is Claude-3.7-Sonnet (with one sensitive content removed).
Comparing the three models in the Claude series: Claude-4-Sonnet, as a "low-end version" of Claude-4-Opus, is clearly "consistent in style but with fewer details."
The key comparison is between Claude-4-Opus and Claude-3.7-Sonnet:
From the perspective of the instruction to create slides, Claude-4-Opus is a better fit: its size, content, and layout conform better to PPT requirements, whereas Claude-3.7-Sonnet feels more like a webpage. In some offline discussions, friends mentioned that content generated by Claude-3.7-Sonnet is hard to see when projected. Thus, in terms of UI/UX, Claude-4 is indeed better.
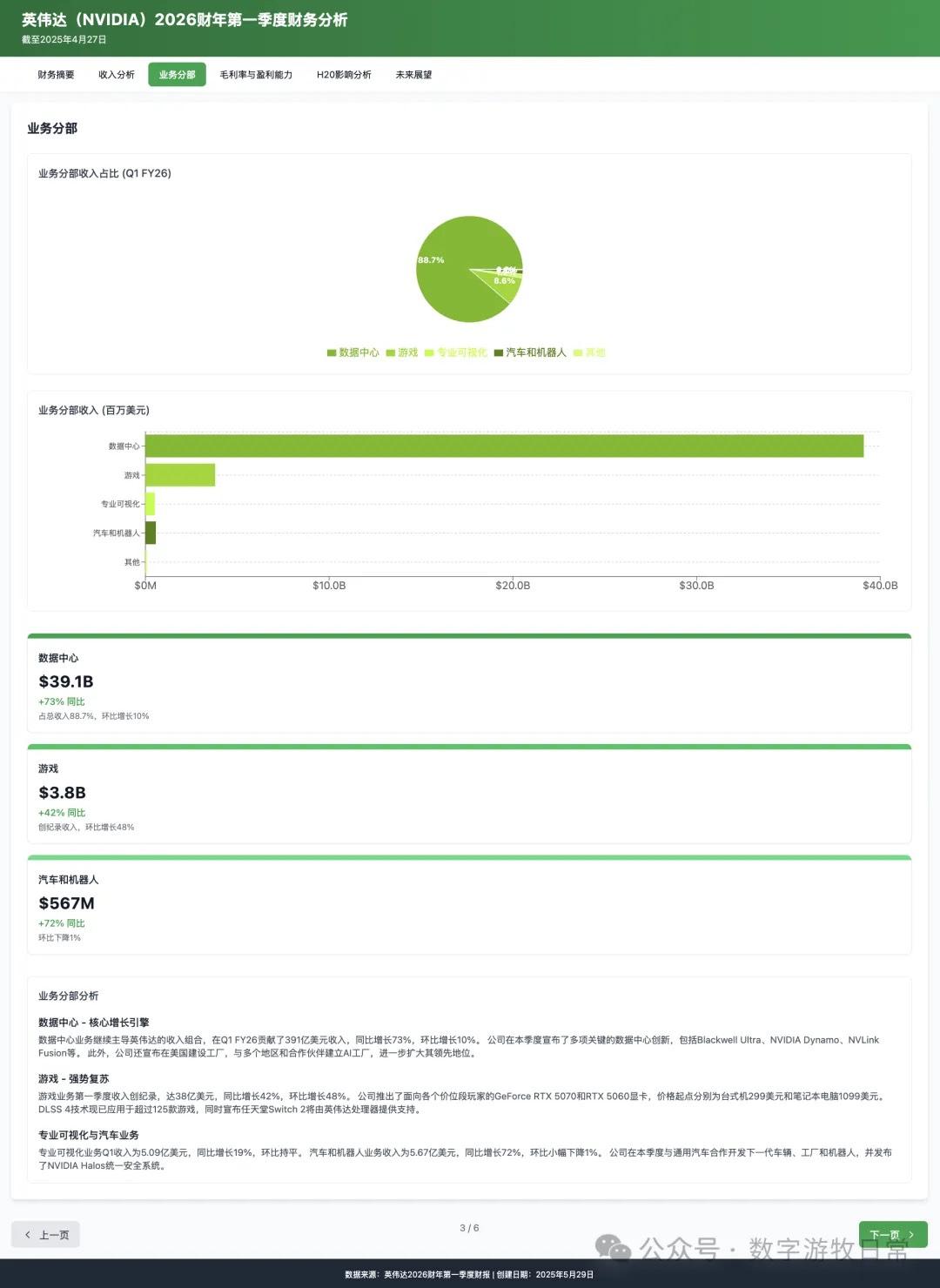
However, in terms of content, Claude-3.7-Sonnet clearly contains more information and is more faithful to the source material.
In this example, I did not like that Claude-4 provided investment advice at the end. Yes, it shows the model is "smart," since the main purpose of financial analysis is to produce investment recommendations. But if Claude-4 is "restrained" in its slide layout, this extra investment advice is "unrestrained."
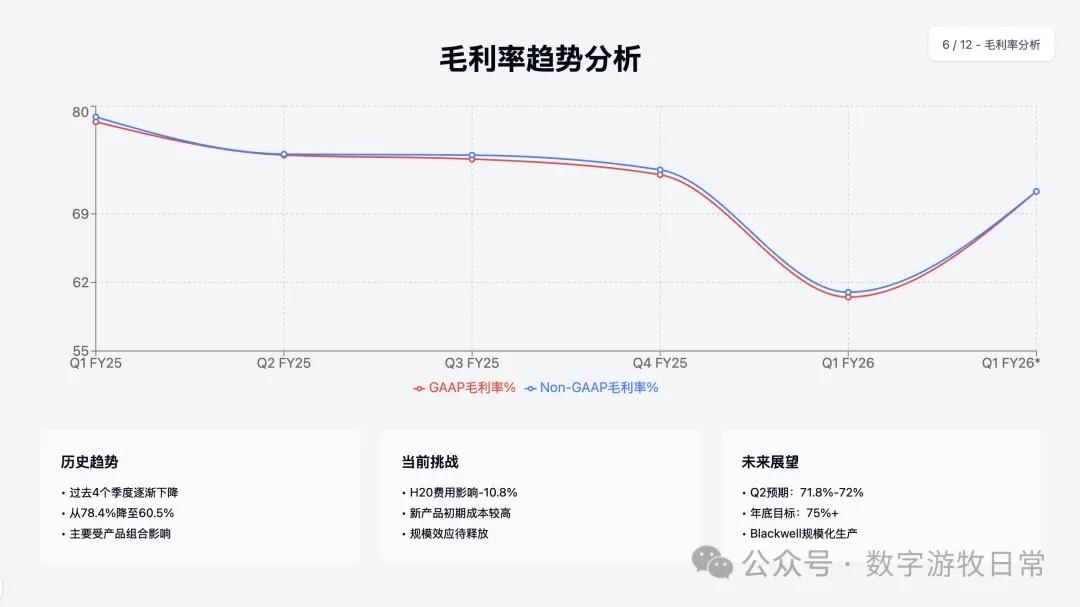
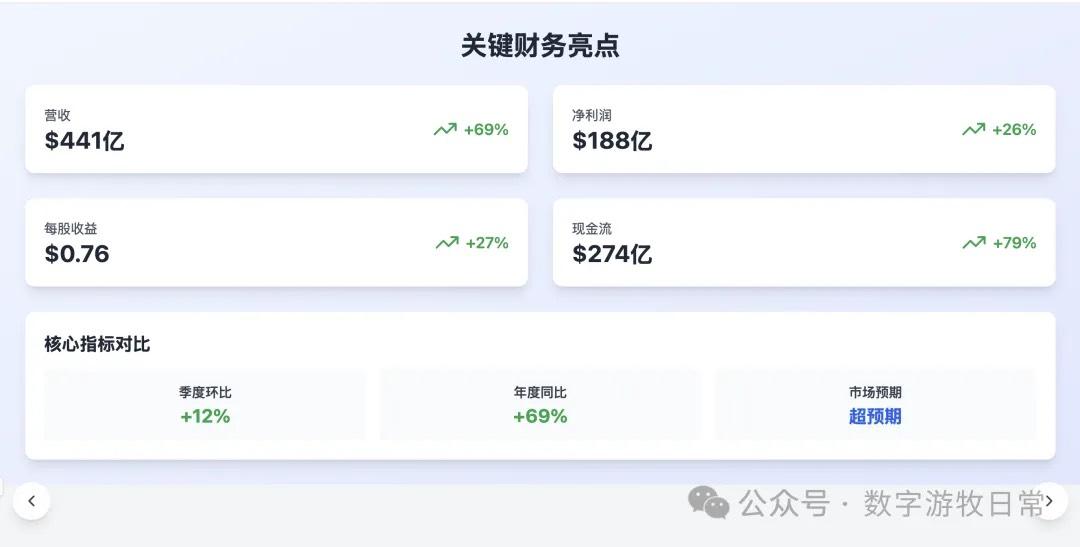
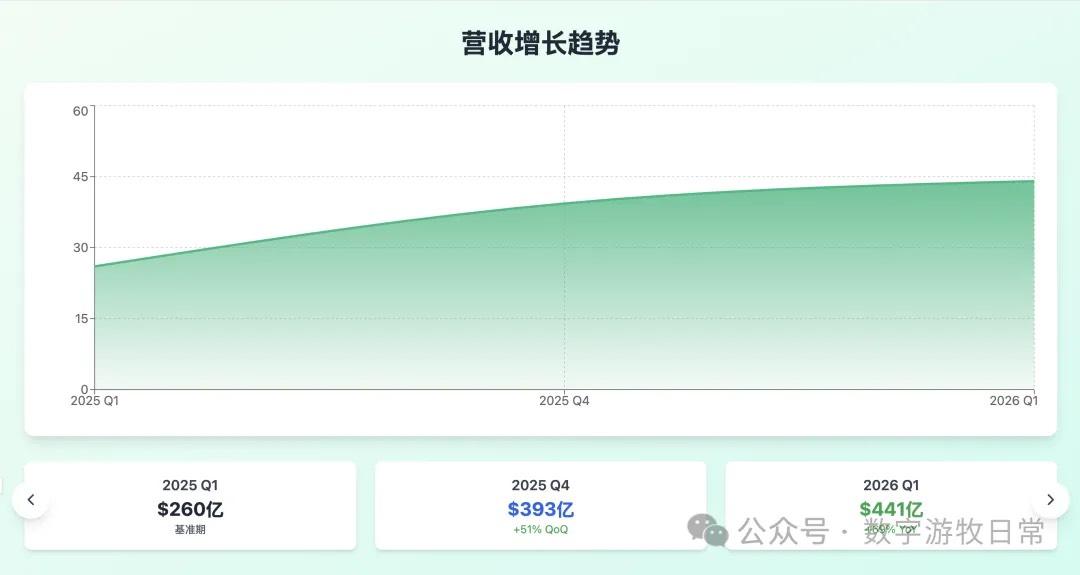
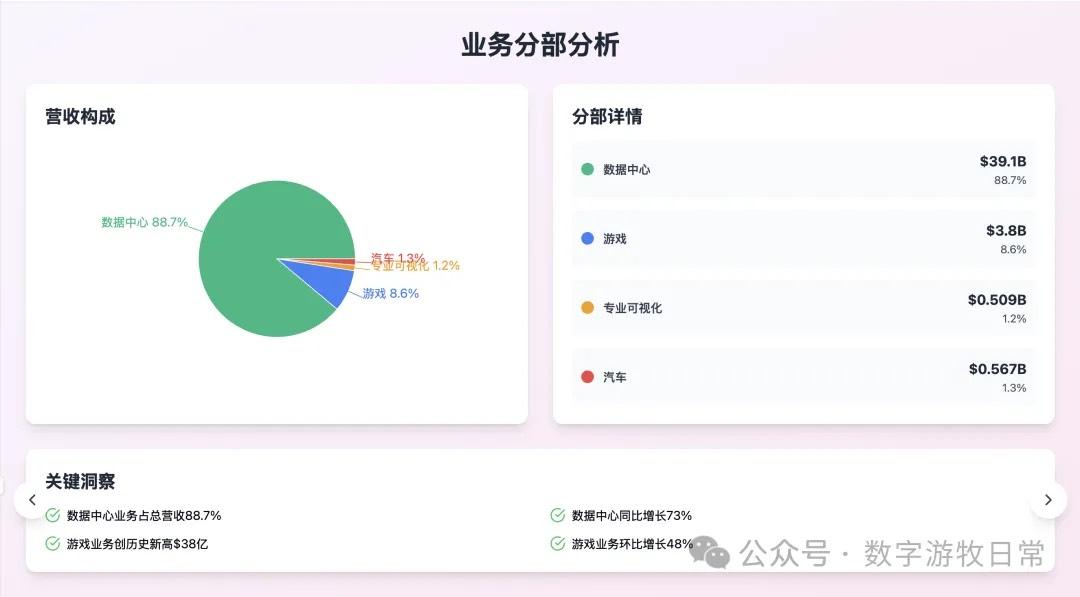
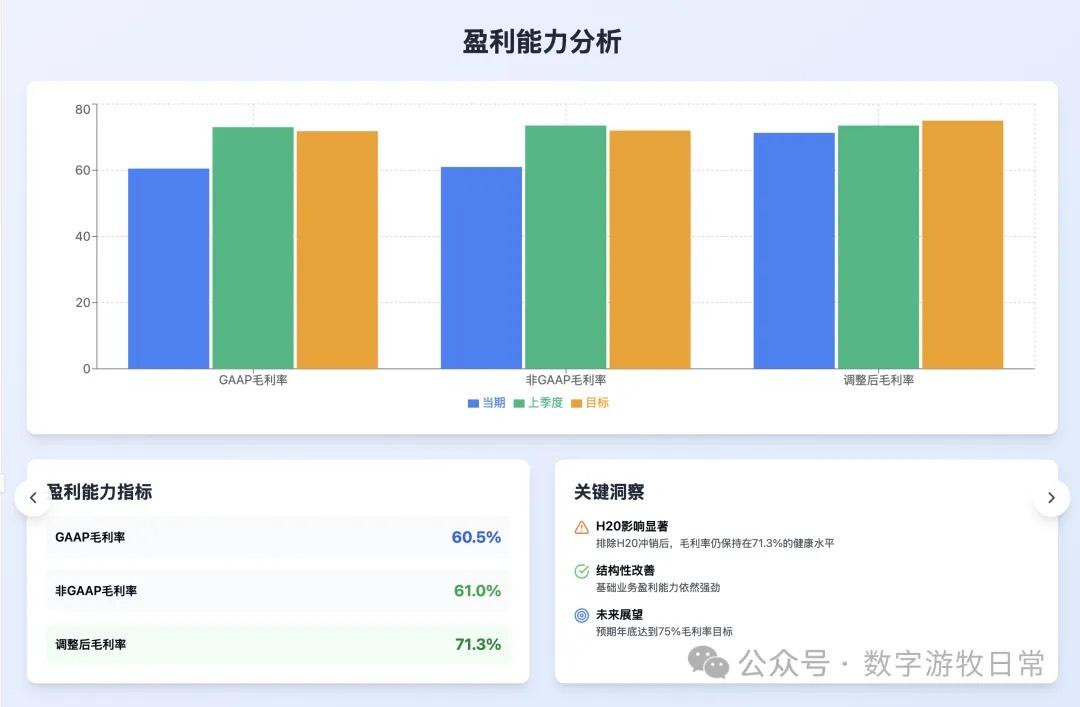
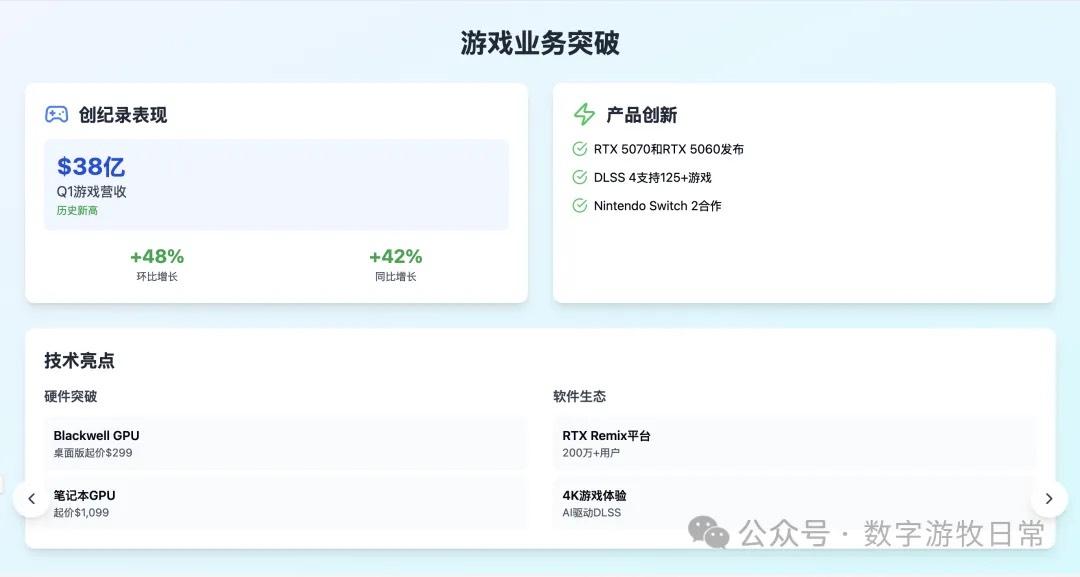
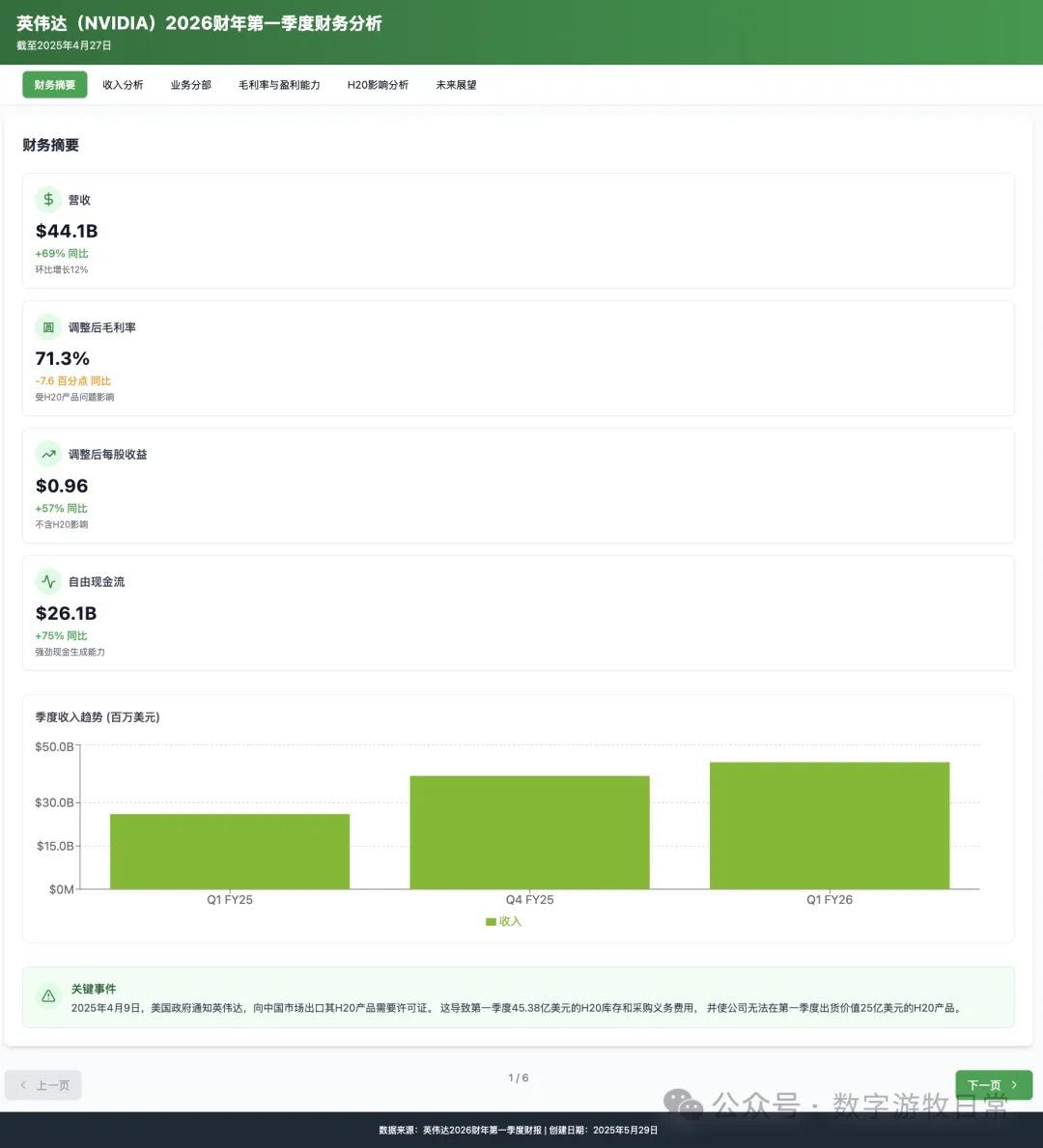
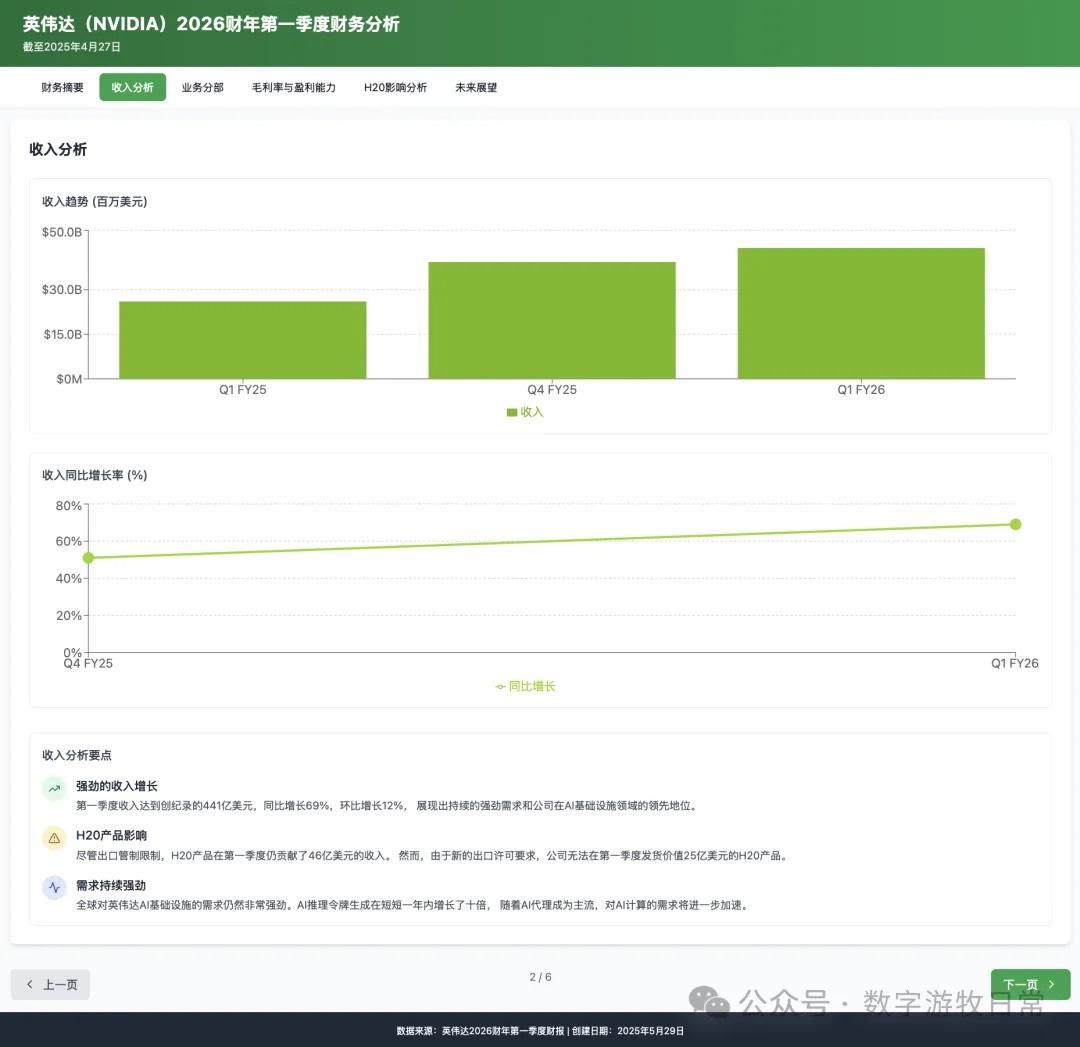
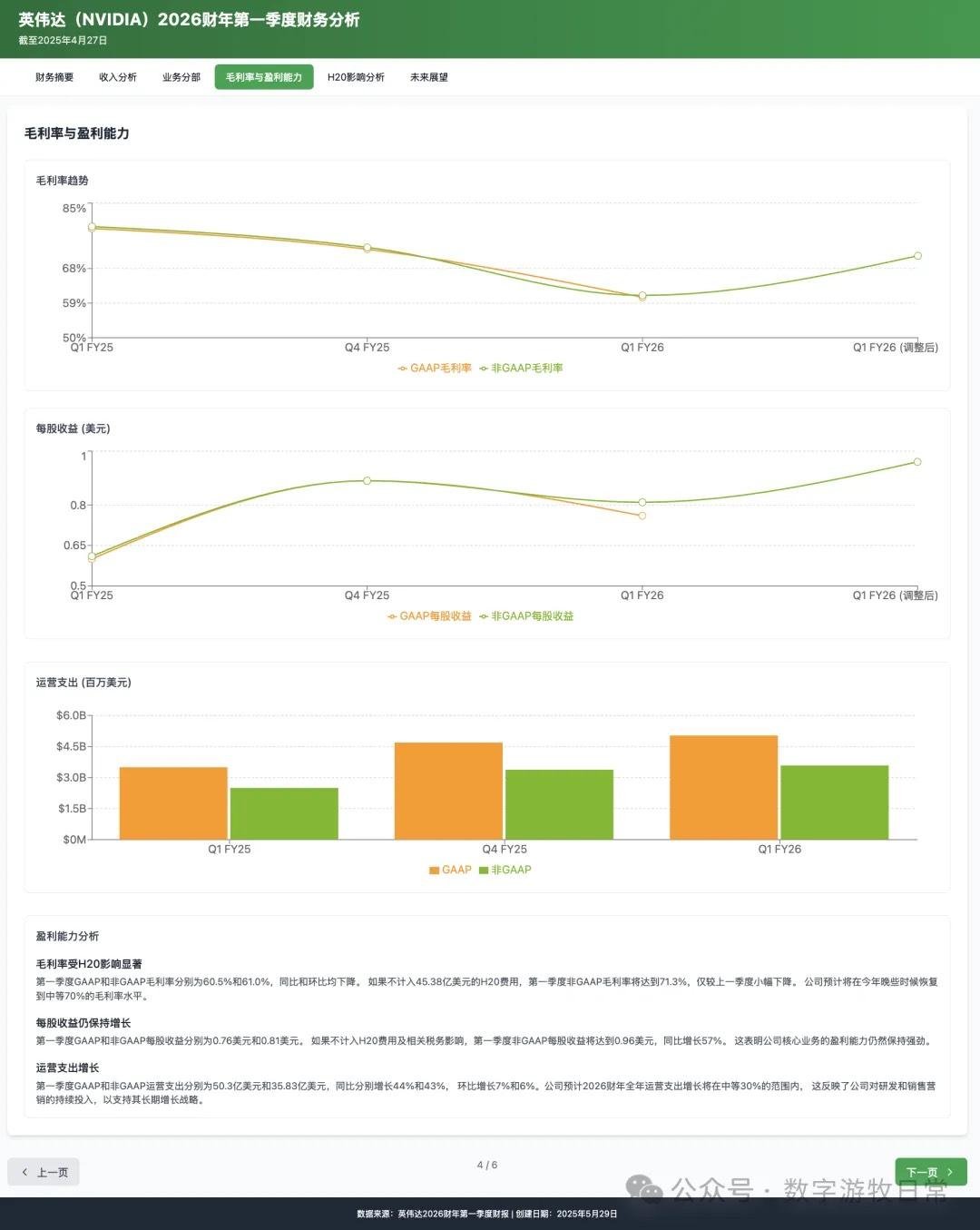
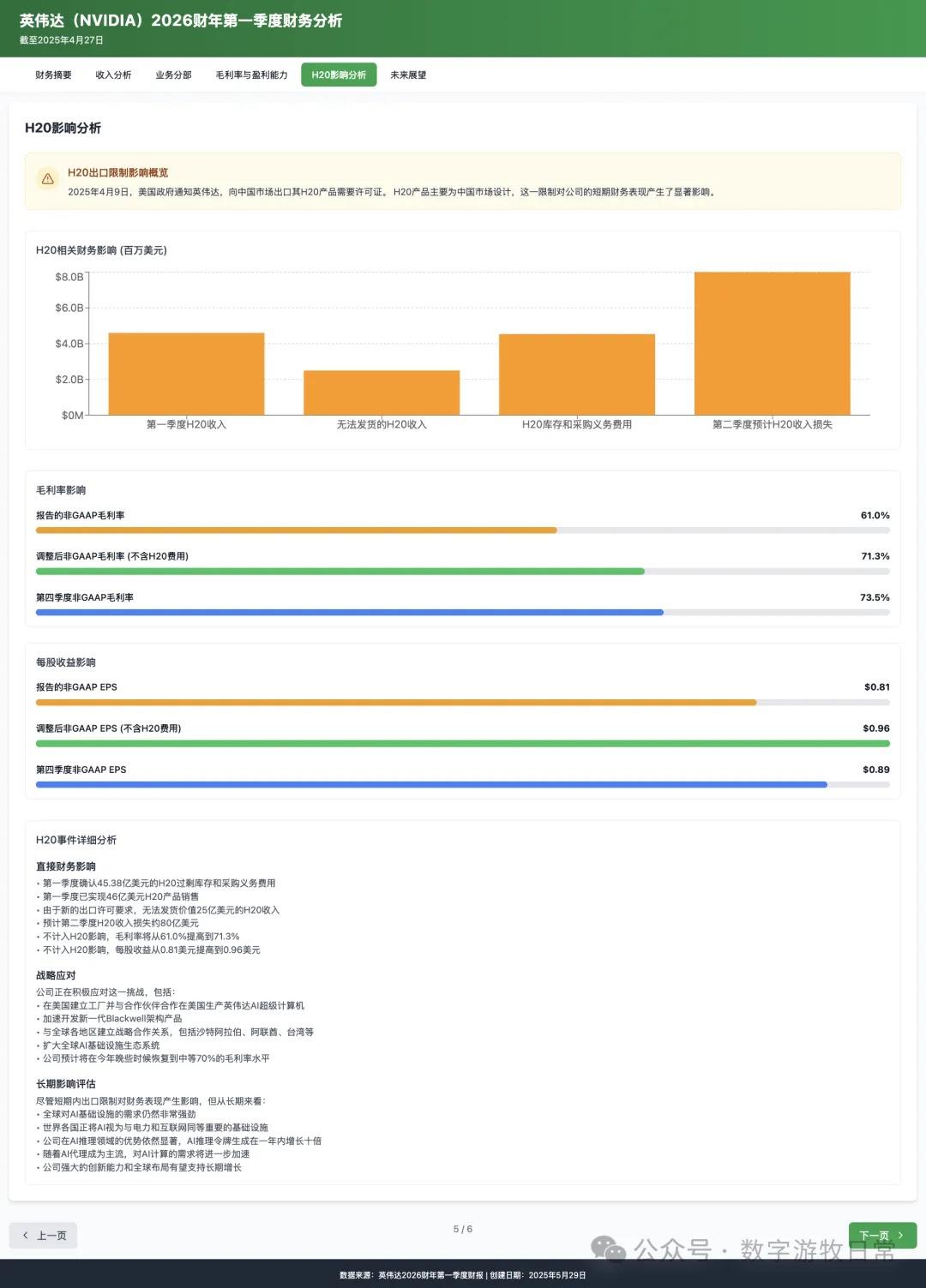
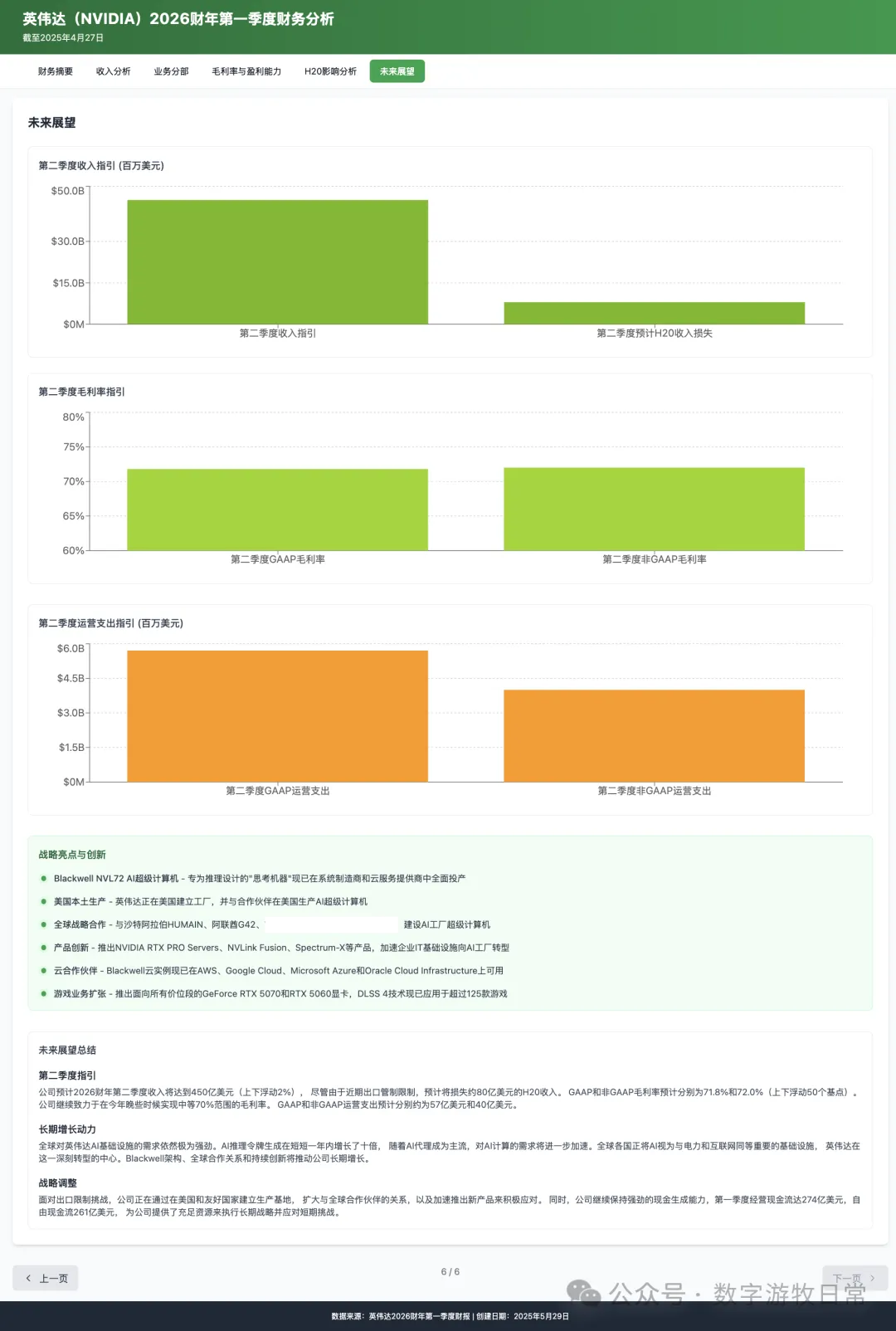
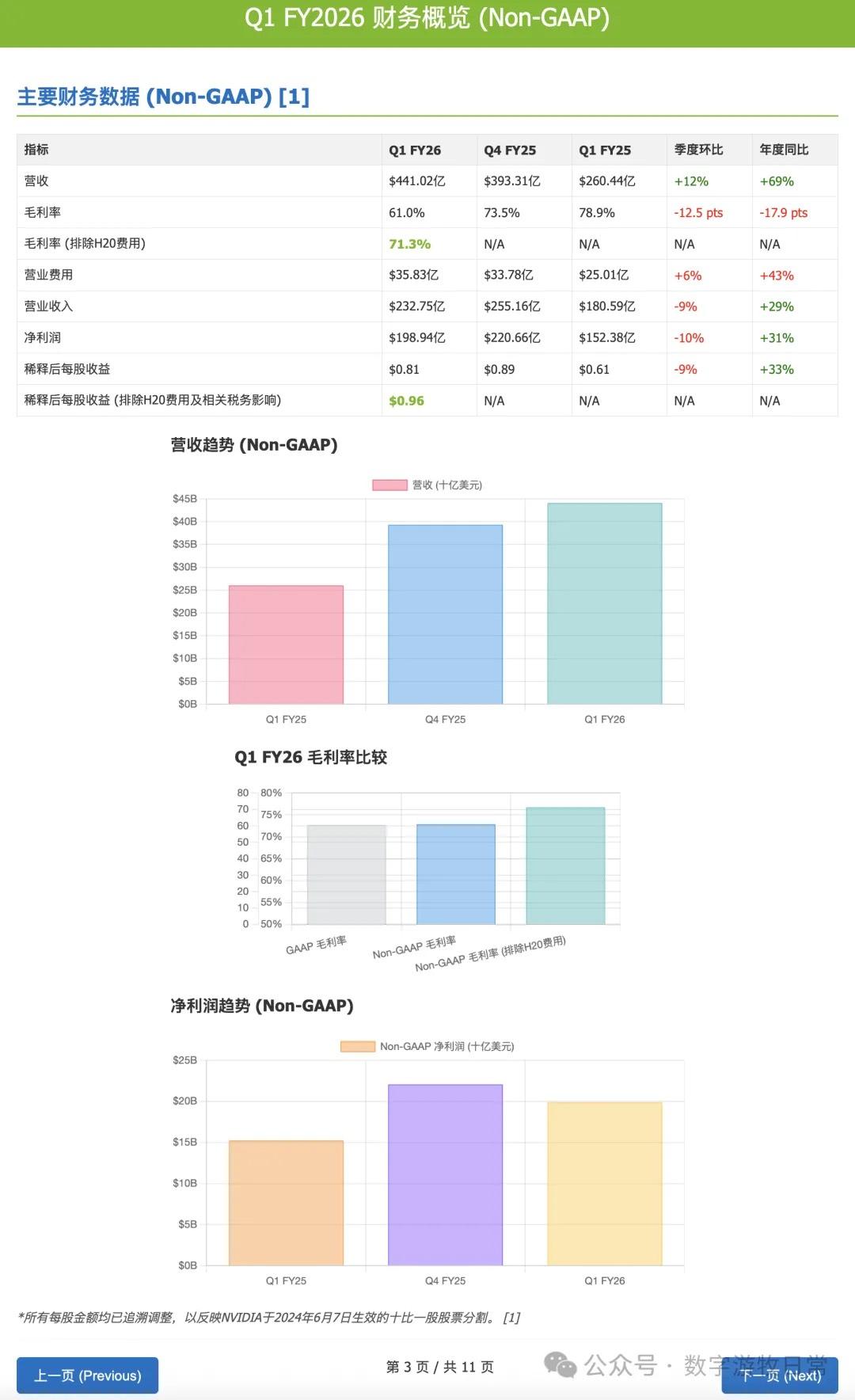
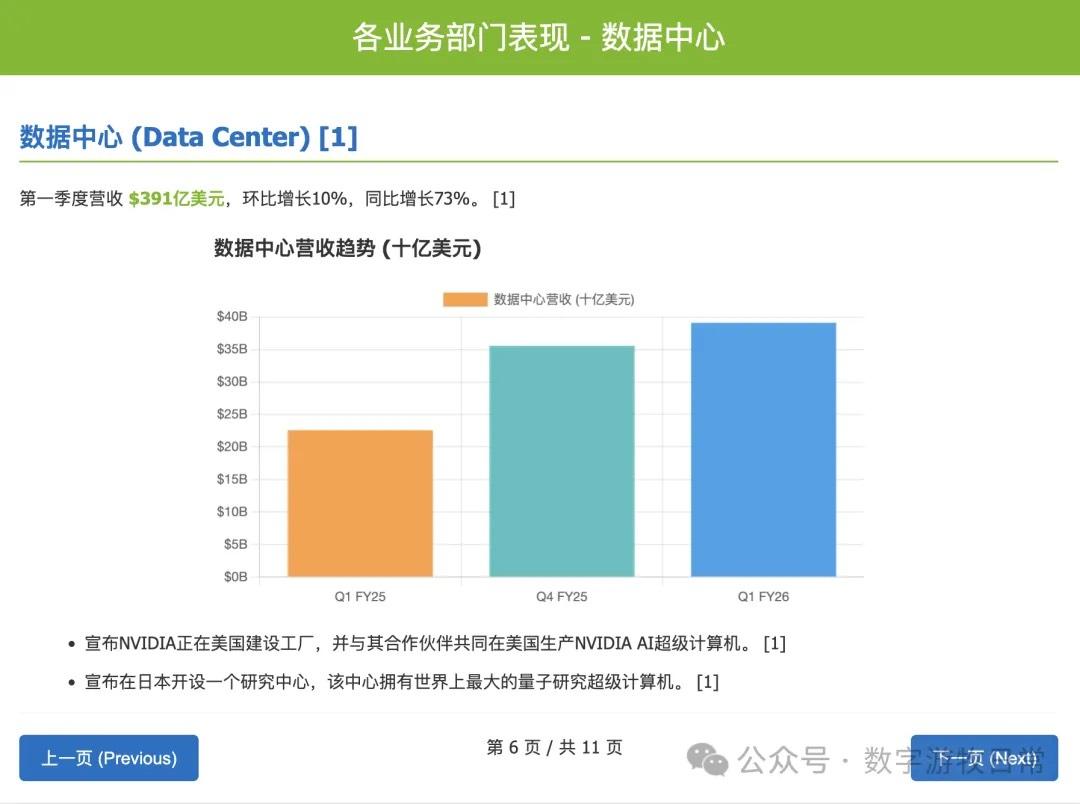
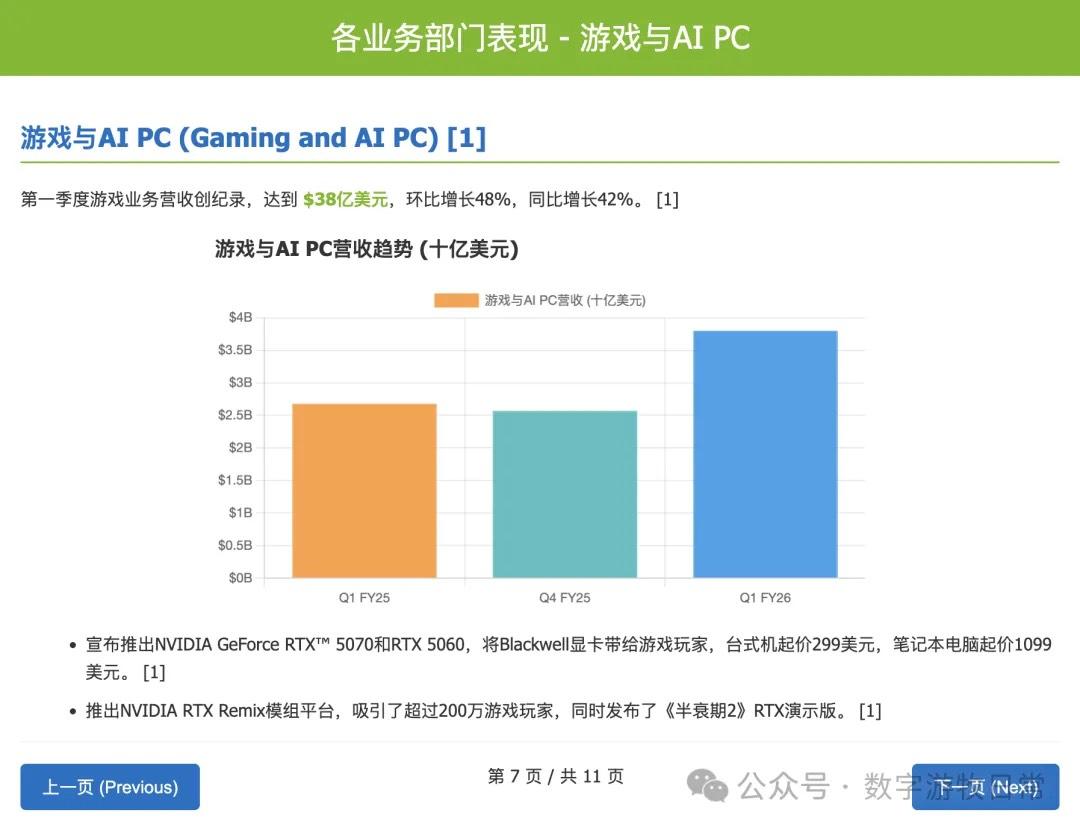
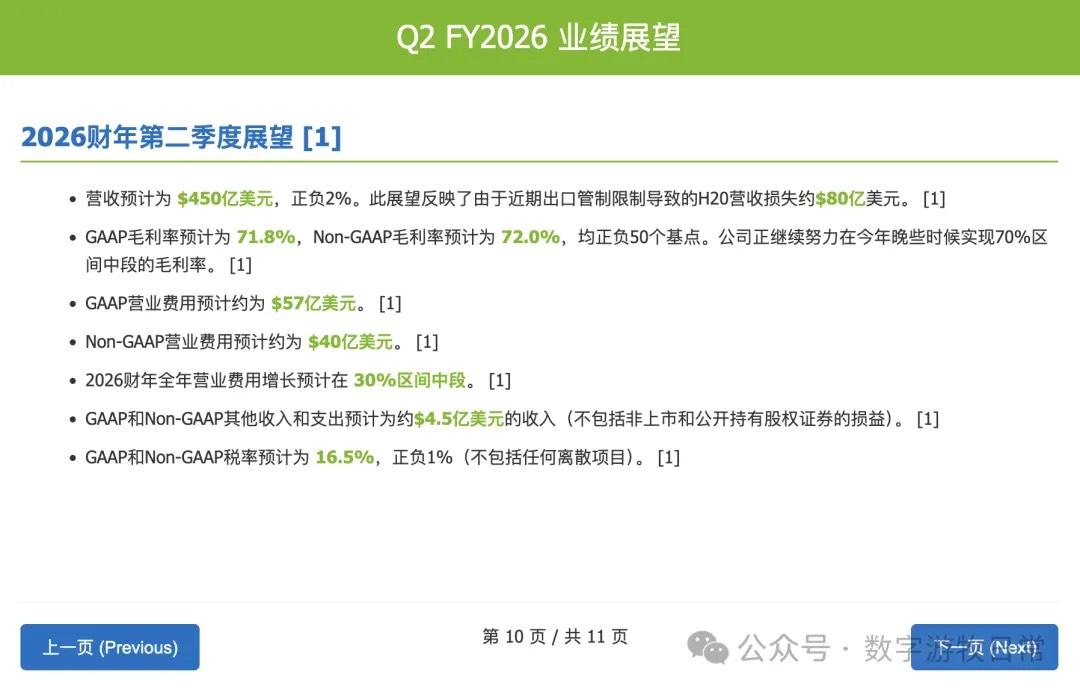
Looking at the specific content, only Claude-3.7-Sonnet clearly analyzed the impact brought by H20: especially the EPS impact. In NVIDIA's official info, three EPS figures were given: GAAP at 0.76, Non-GAAP at 0.81, and Non-GAAP excluding H20 impact at 0.96. As one of the most important discussion factors in the earnings report, only Claude-3.7 strictly distinguished and explained them.
Of course, I planned to give Claude-4 another chance to see if "extended thinking" influenced the model's tendency (actually, Claude-3.7-Sonnet also had extended thinking enabled). I tried to turn off this option and run it again, but unfortunately, I hit the limit again. I've only opened three conversations from yesterday to today—the three above. Perhaps Anthropic's limit is based on token count?

This kind of experience won't make me return to a Max subscription; rather, it prompts me to end my Pro subscription.
I'll leave more subjective conclusions for the end of the article. Let's quickly go through the results of the other two models, starting with Gemini-2.5-Pro.




Then OpenAI's GPT-o3.
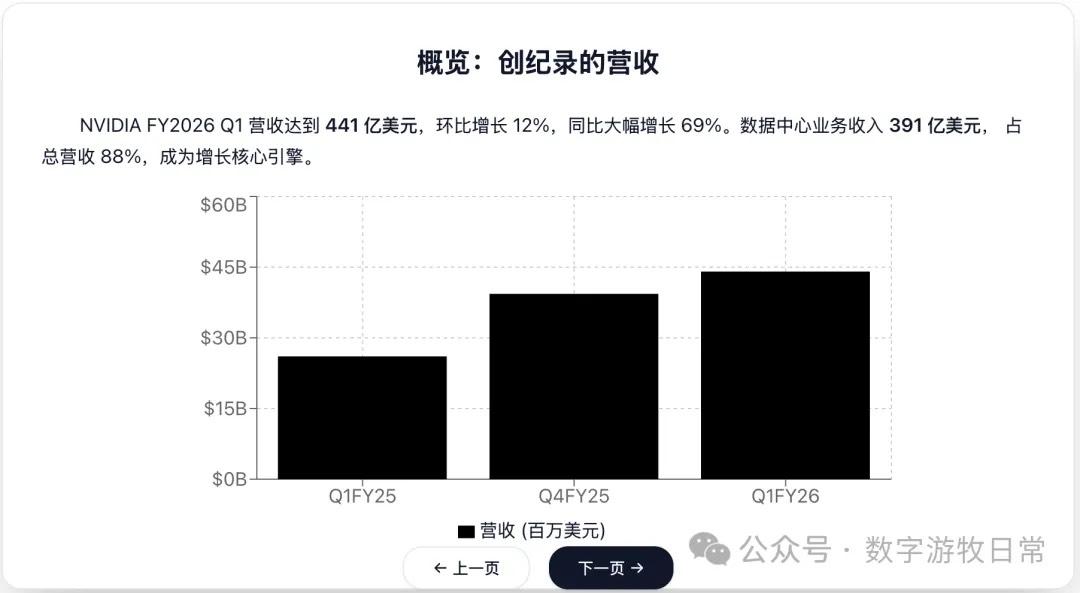
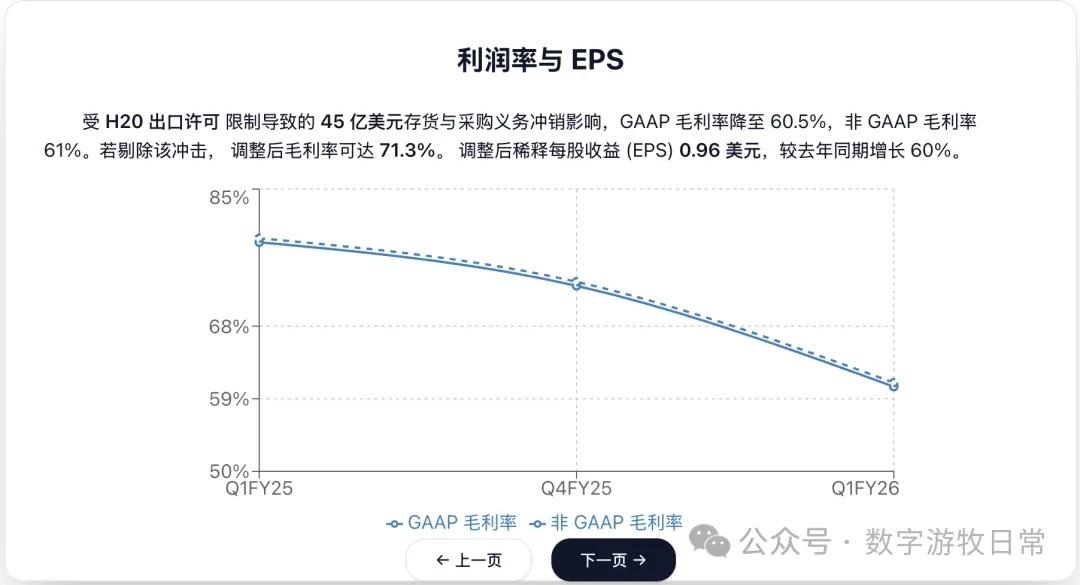
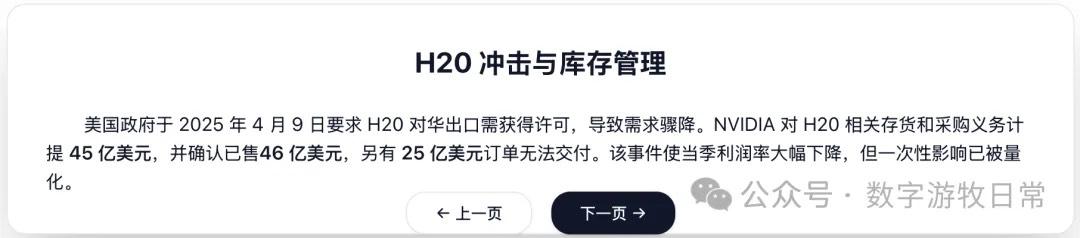



Well, that's it. There's a lingering sense of it being a "knock-off."
The above are the outputs from the five models. Yes, generating slides is only a small test, but as I said before, it actually examines multiple aspects of a model's capabilities and is very "practical." Of course, the "knock-off feel" might come more from different models' settings regarding information density preferences; at the very least, it shouldn't be the most important judging metric.
Now for my subjective impressions.
In terms of personal preference, I still prefer Gemini-2.5-Pro's output, followed by Claude-3.7-Sonnet. Gemini-2.5-Pro output a table, even though this table was actually in the official release. But it is precisely this point that further demonstrates Gemini-2.5-Pro's "faithfulness" to the "background material" provided by the user.
Gemini-2.5-Pro controlled the "degree" of output very well: thinking is for better understanding the user's input, not for letting itself give too many subjective judgments. While this remains a matter of opinion, I want to say that Claude-4, to me, "crossed the line" (we can start another article to discuss the degree of thinking).
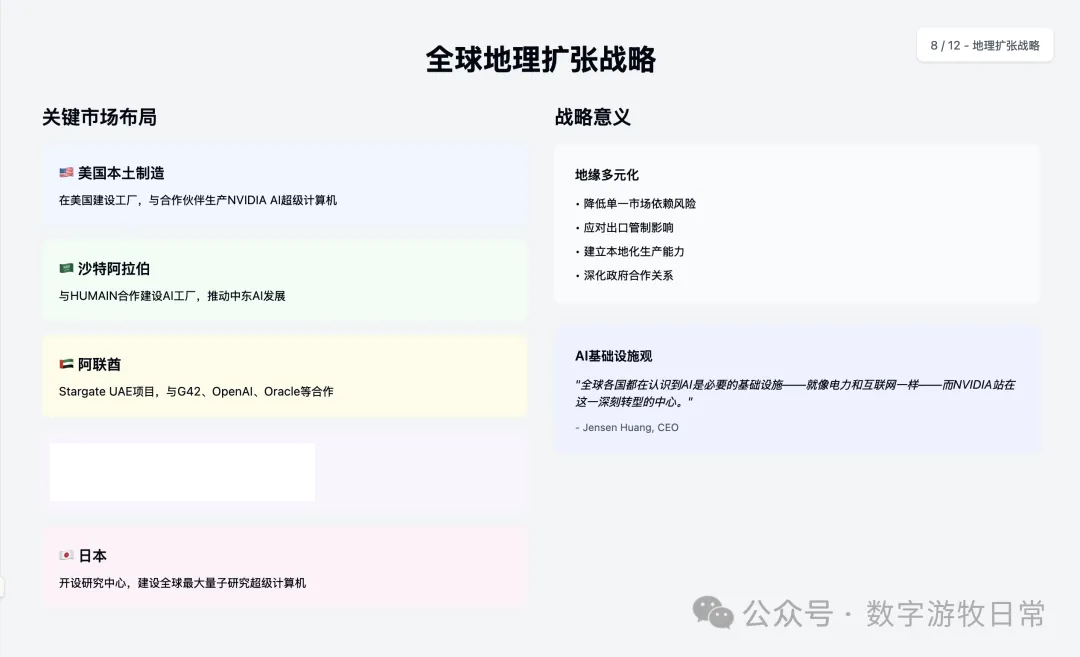
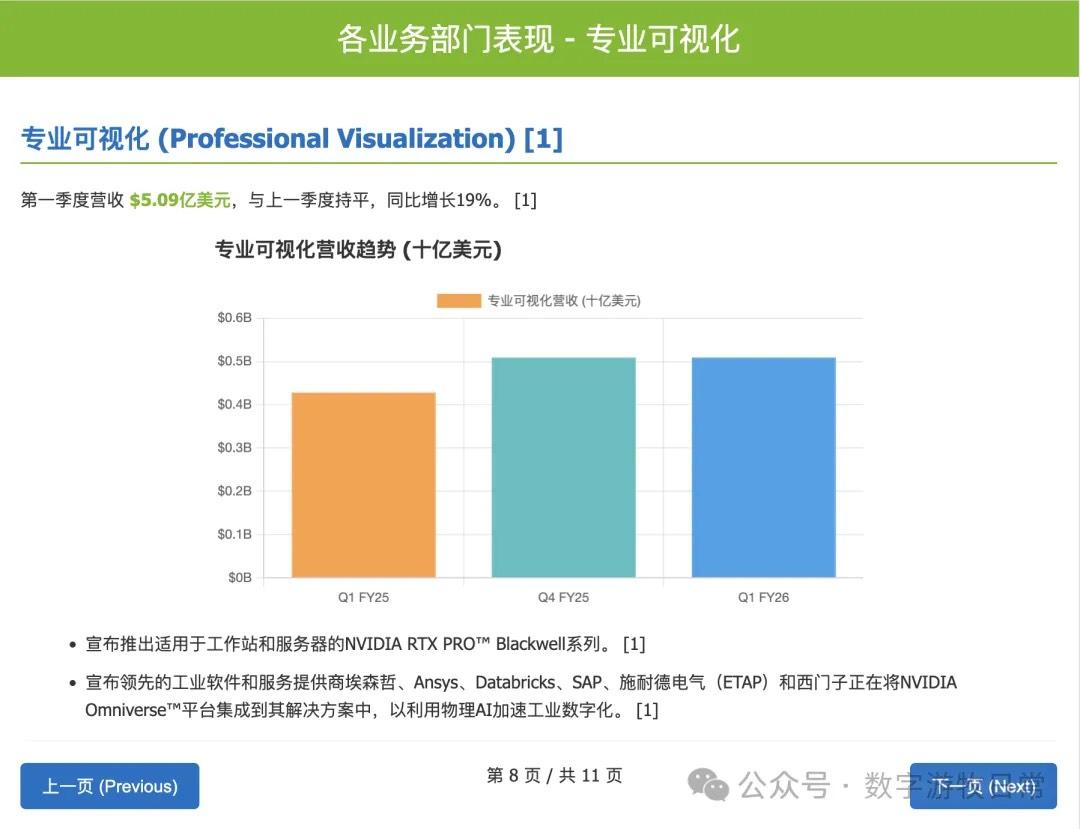
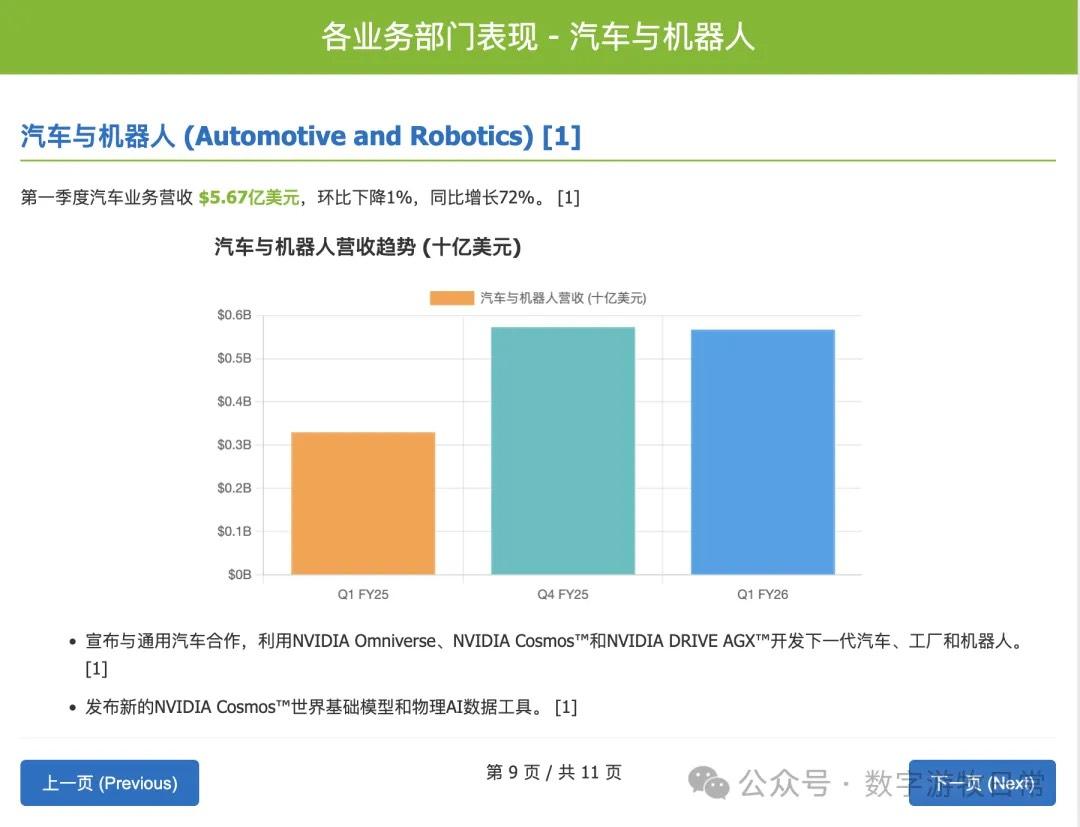
Claude-3.7-Sonnet also controlled the "degree" well. In fact, except for not outputting a table, it contained more informational details from the "background material" than Gemini, such as certain strategic partnerships.
By contrast, the only remaining value OpenAI has for me at the moment is Deep Research. Compared to Gemini's Deep Research, OpenAI's results currently have slightly better stability.
The results of these models are basically consistent with my experience trying to adapt to the Claude-4 model: in some places, Claude-4-Sonnet indeed shows higher accuracy in one-shot code generation, but compared to Claude-3.7-Sonnet, there's an indescribable "clunkiness." Perhaps it lies in the boundaries.
Finally, I know for sure many will criticize: making a PPT doesn't reflect model capability at all; Claude-4 is clearly superior in coding.
First, let's exclude the results of "armchair theorizing" influenced by leaderboards.
Second, we might need to think about a question: PPT generation can be used in actual practice, directly in front-line business segments. How much other code generation can directly produce results needed for front-line business? If the answer is "reinventing the wheel" for front-line business needs, then in the AI era, how many "reinventing the wheel" scenarios do we actually need?
Productivity (in all probability) can change production relations.