
Claude-4 has been released. Let's start with some off-topic remarks.
Just as I was one Q&A away from completing my initial comparison experience of Claude-4, I was "rate-limited."
In fact, after the $100/month Max subscription was launched, I used it for a month to test Claude's Deep Research capabilities. The results were exceptionally disappointing, so I returned to the Pro subscription and opted for annual billing (pay for 10 months, get 2 free?).
Launched alongside the new model is a so-called gift: four months of Max subscription for sharing (note: this is a lottery after meeting conditions. I was planning to share my link, but after seeing the terms, I decided against it—it's embarrassing).
None of these are good experiences. Ever since the model's code generation became vastly superior and the Artifacts feature was introduced, I've actually liked Claude's "uniqueness." Whether it's the app's UI design or the generated visualization effects, there's a sense of "sophistication."
But at this moment, there's an indescribable feeling:
It's not just the Claude-4 model being limited; 3.7 is also limited. In the past half-hour, I only had four conversations. Since 3.7 was released, even on a Pro subscription, "rate limiting" had never occurred.
To push the $100 Max subscription, it would be understandable if the product were excellent. But Deep Research was so poor I was too embarrassed to talk about it before unsubscribing. Now, resorting to these tactics—I don't know how to evaluate it.
The conclusion of these digressions is that the experience is poor and lackluster. Coincidentally, a friend messaged me: it feels like Anthropic's survival space is being heavily squeezed. I agree. Does this also indicate that this startup is facing significant revenue pressure?
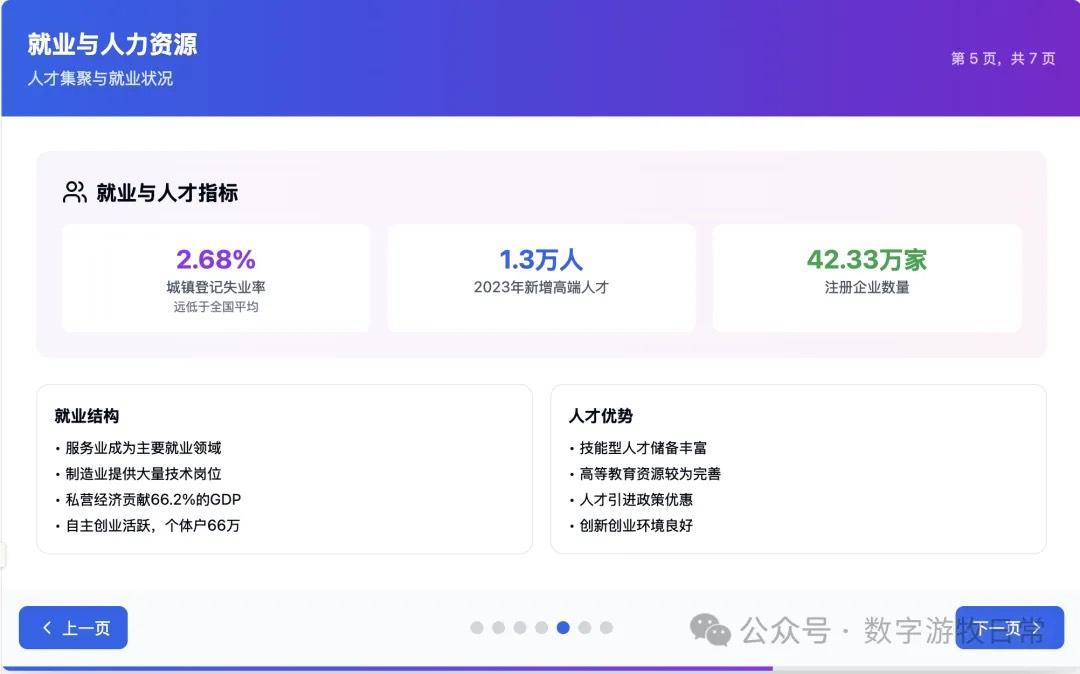
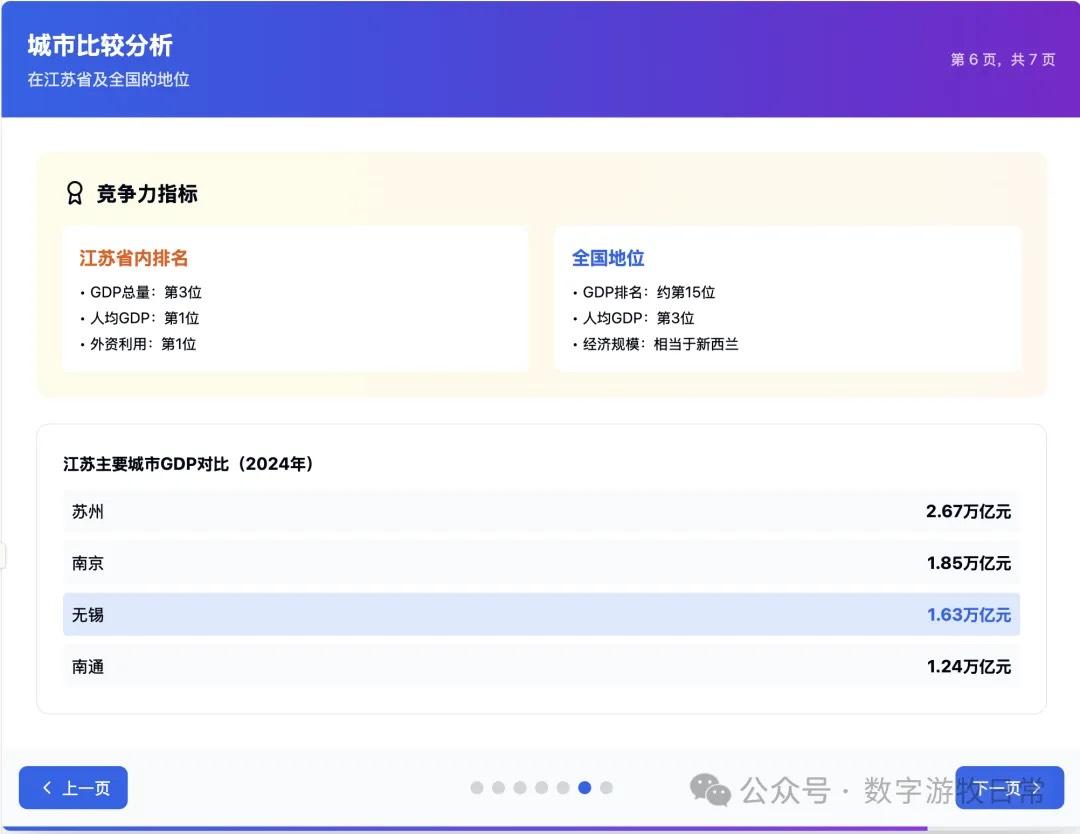
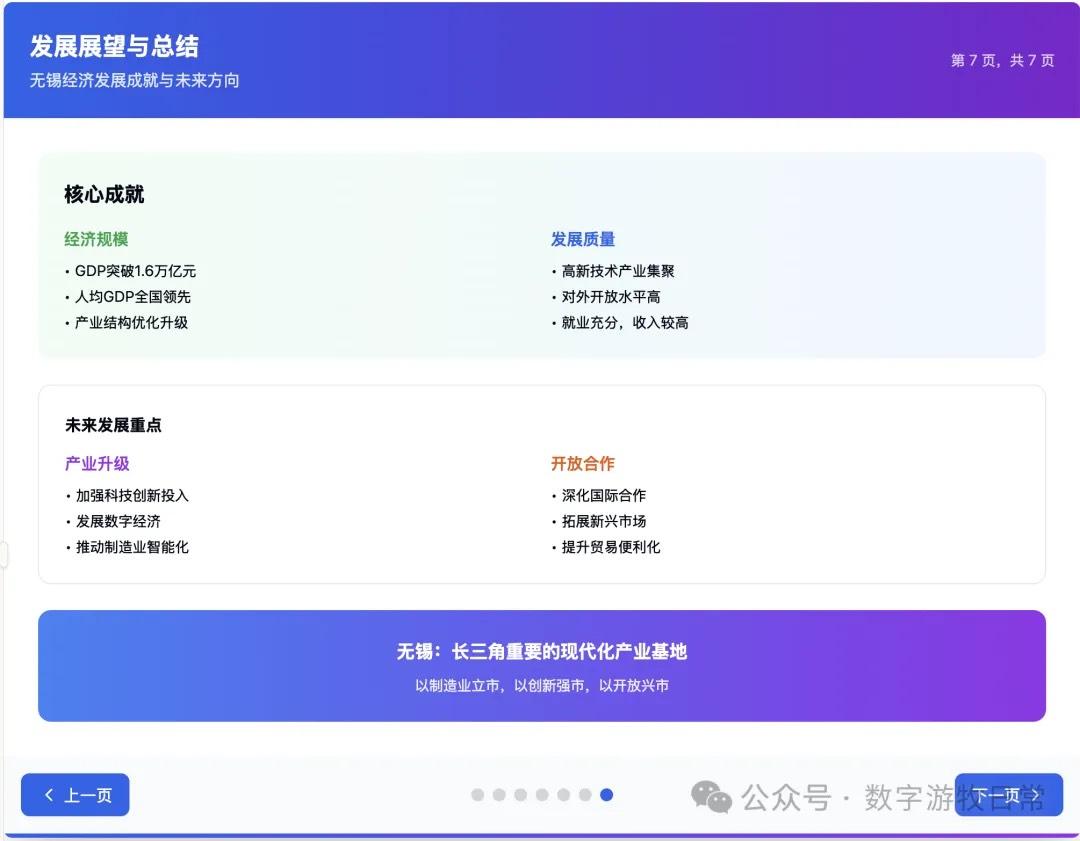
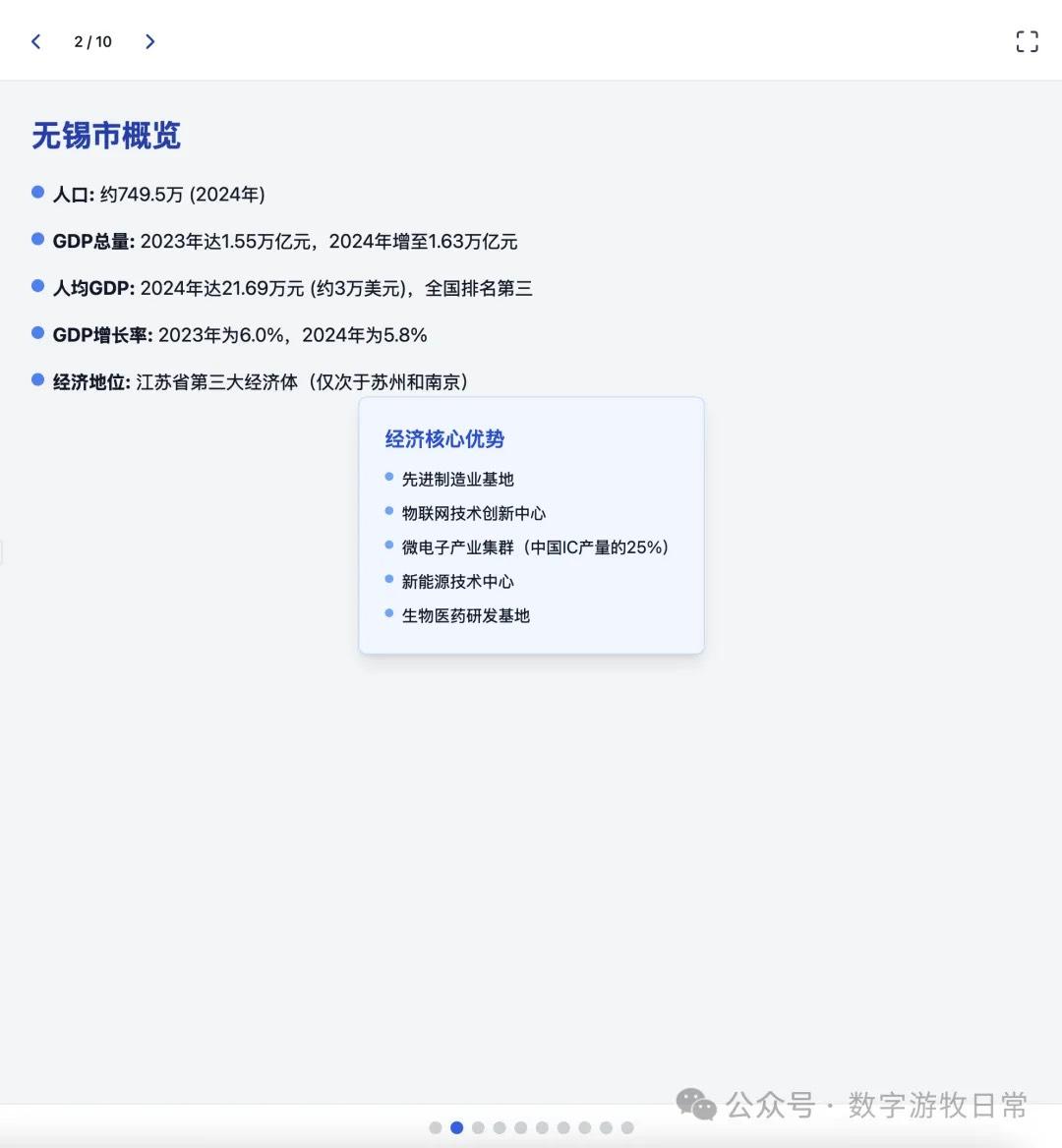
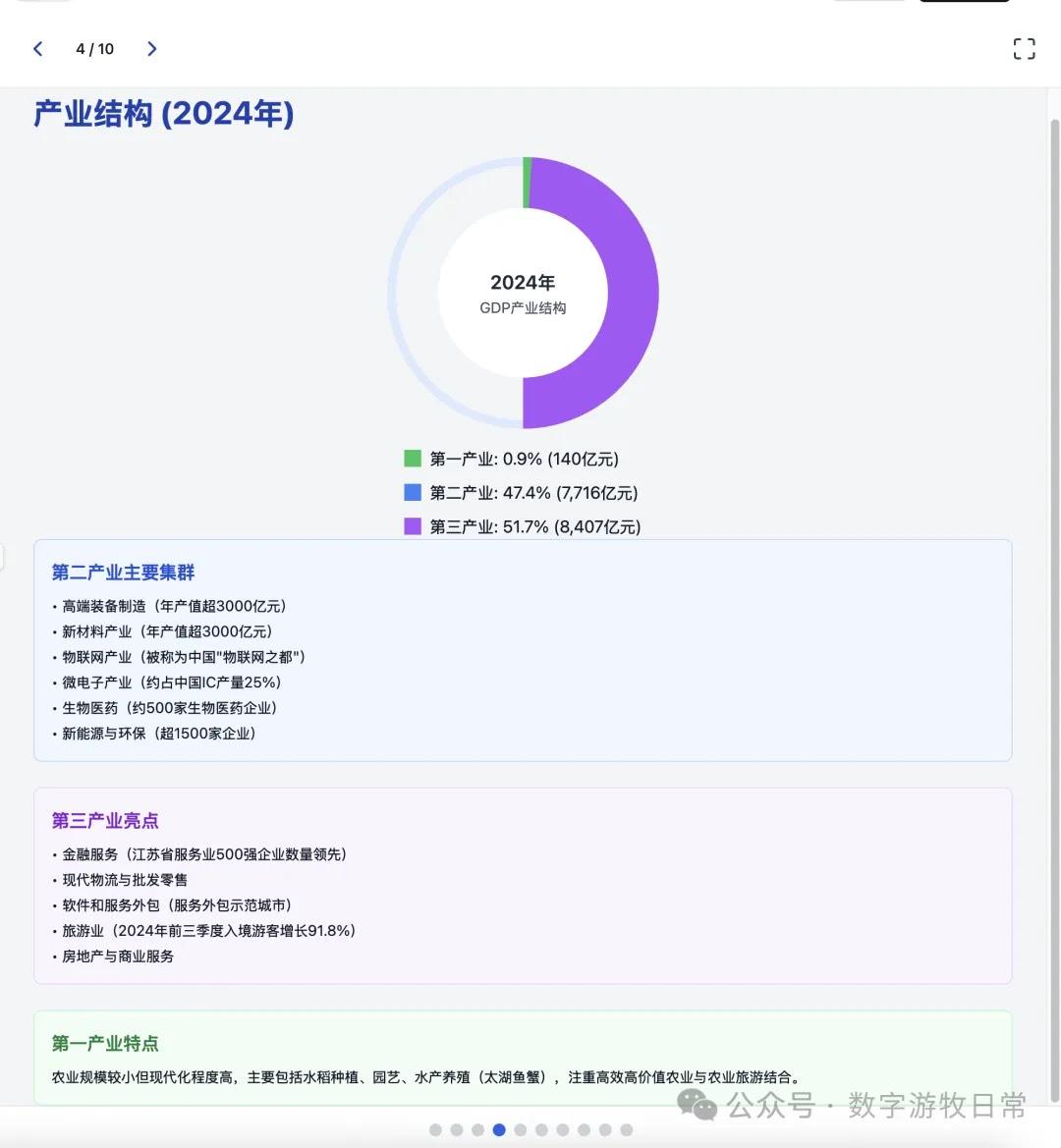
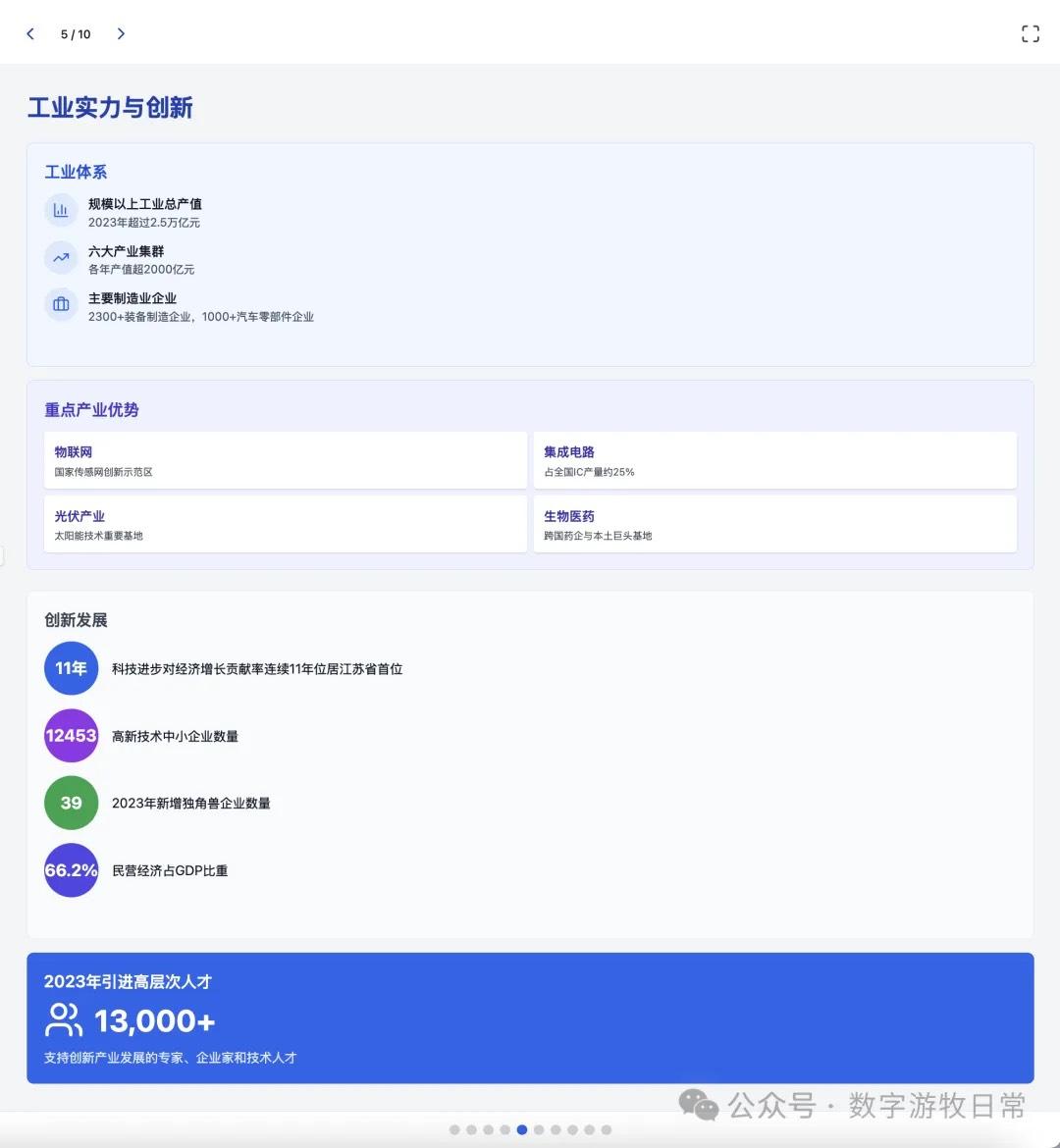
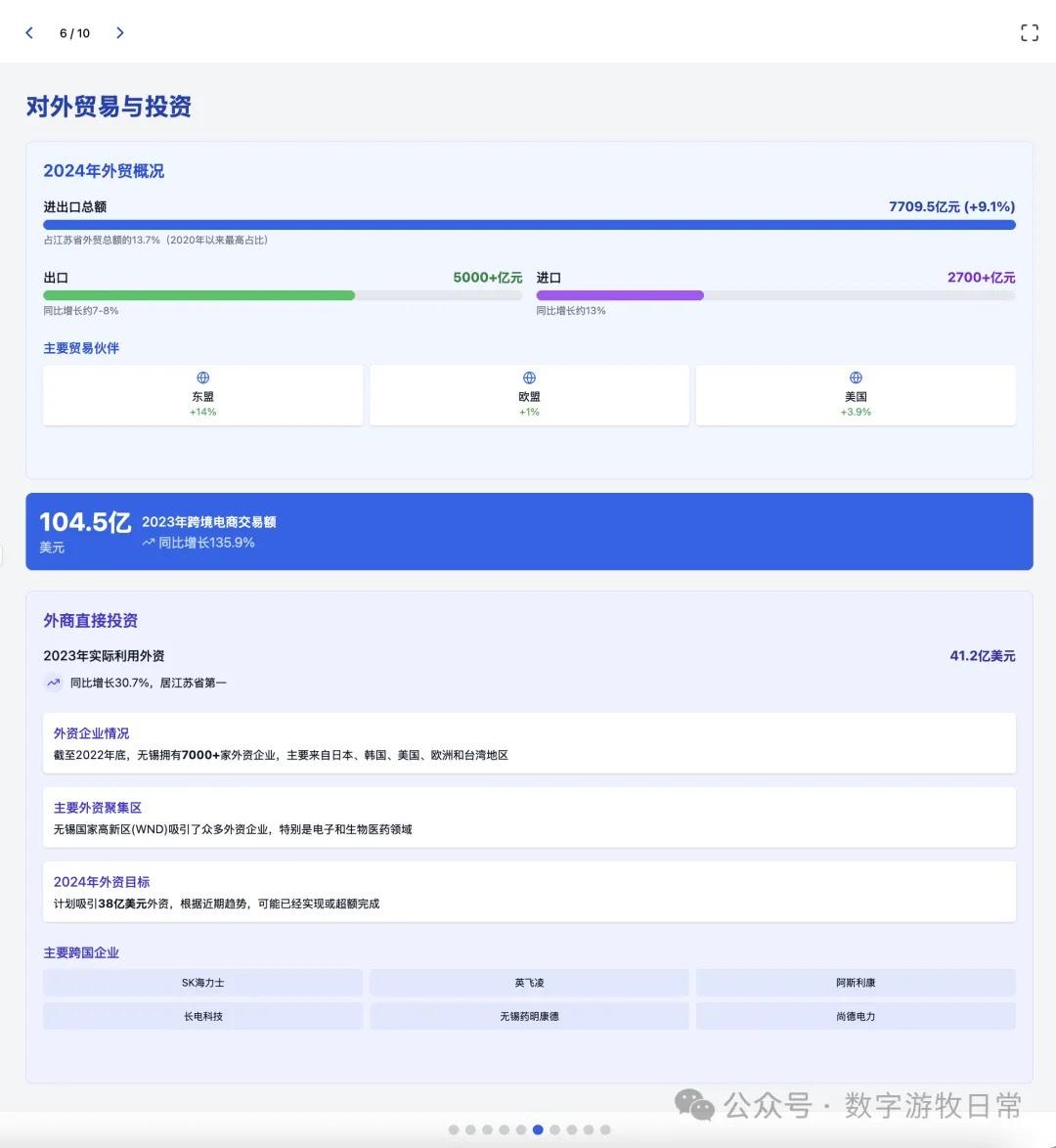
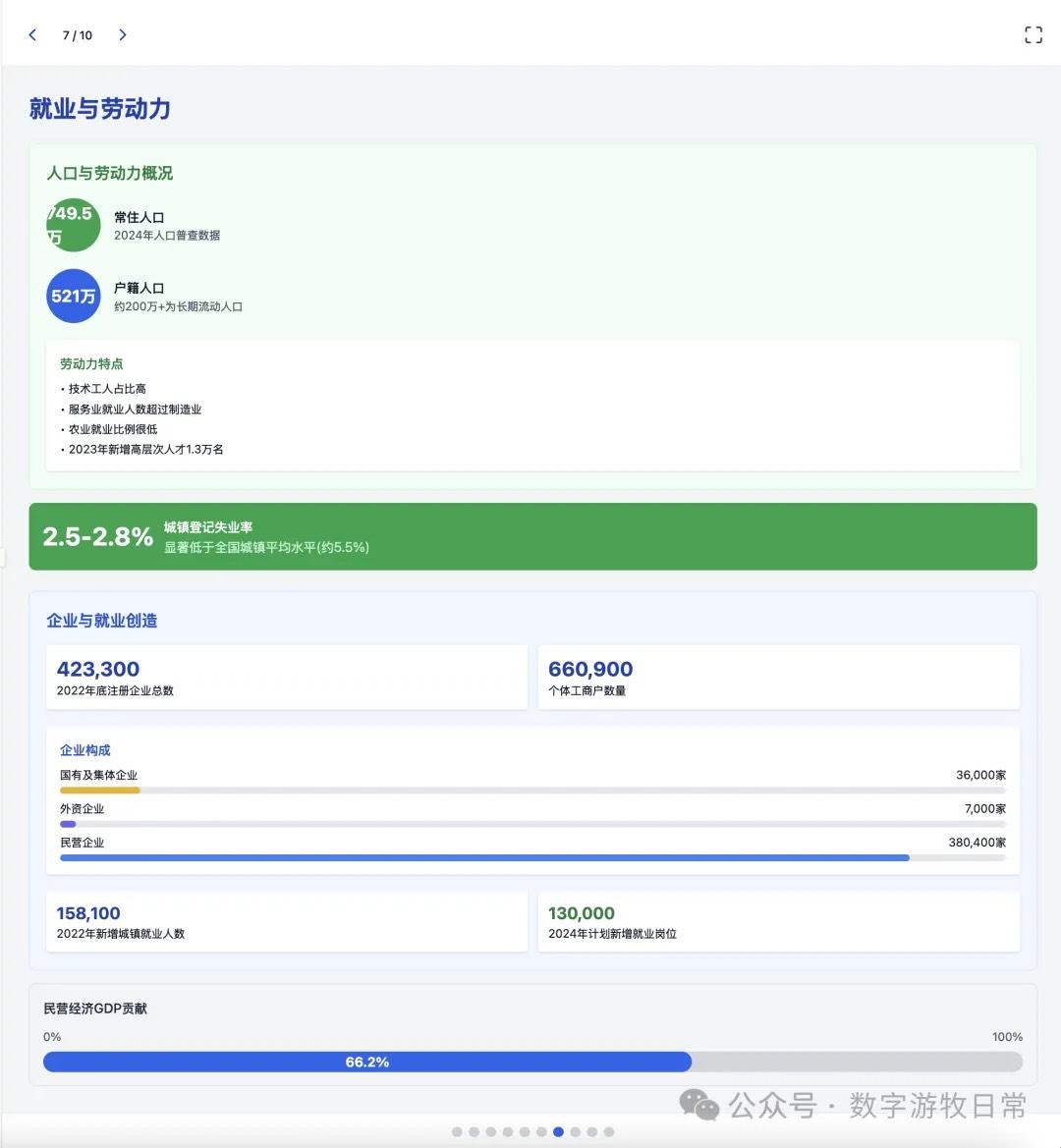
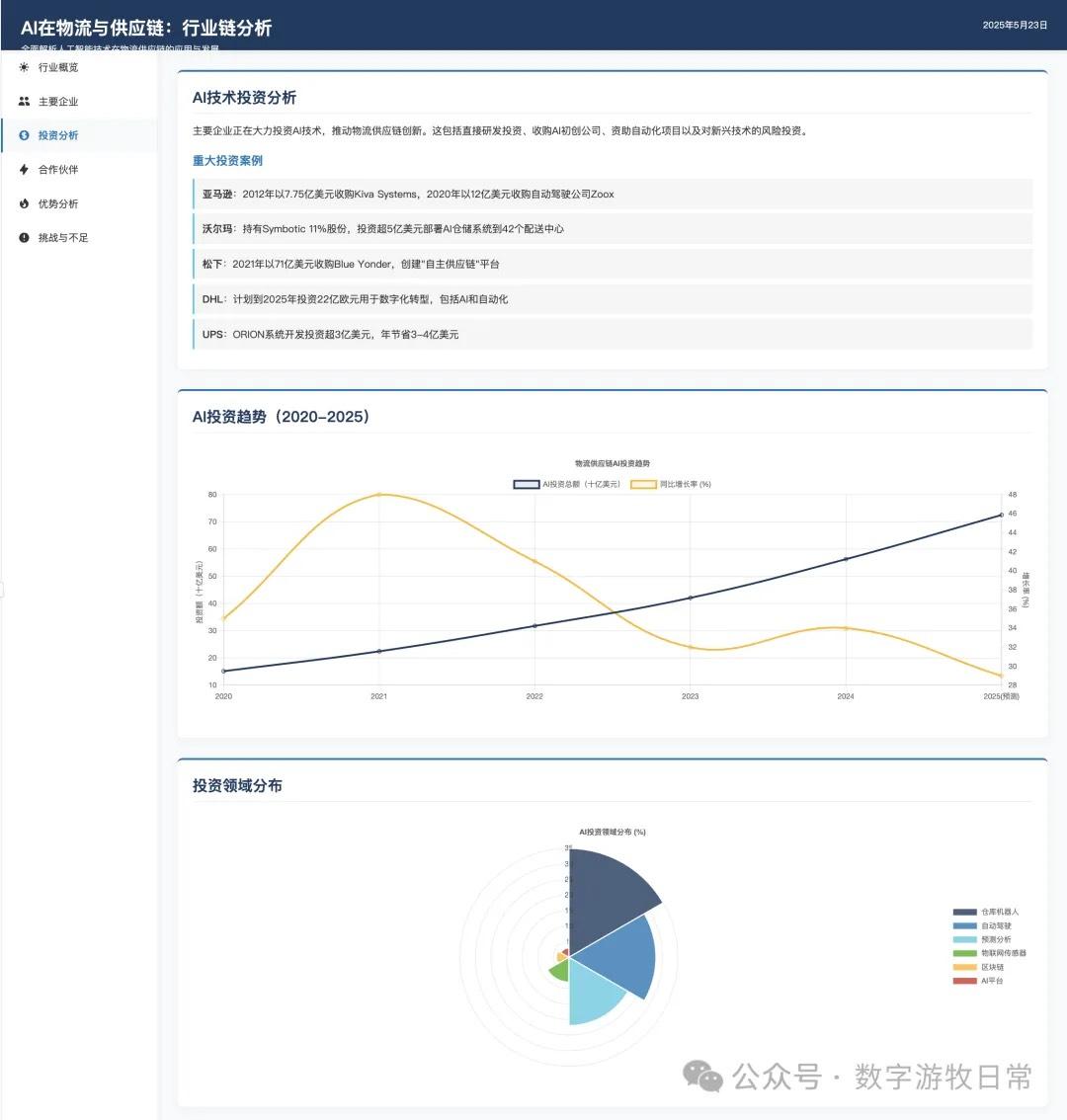
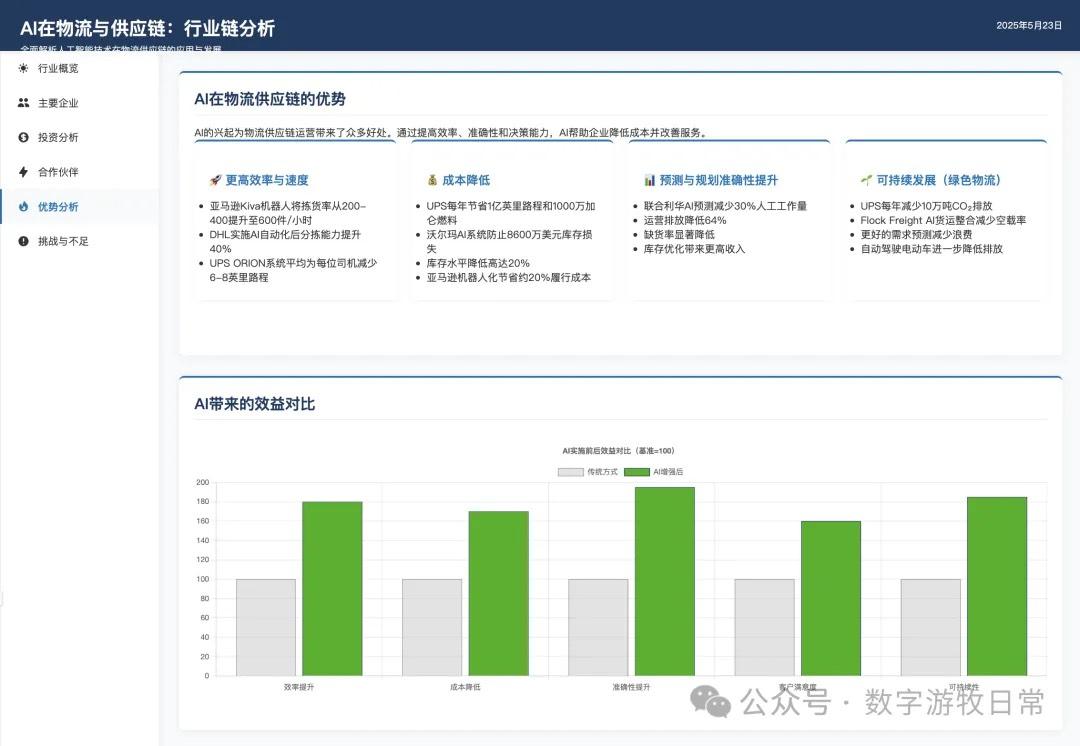
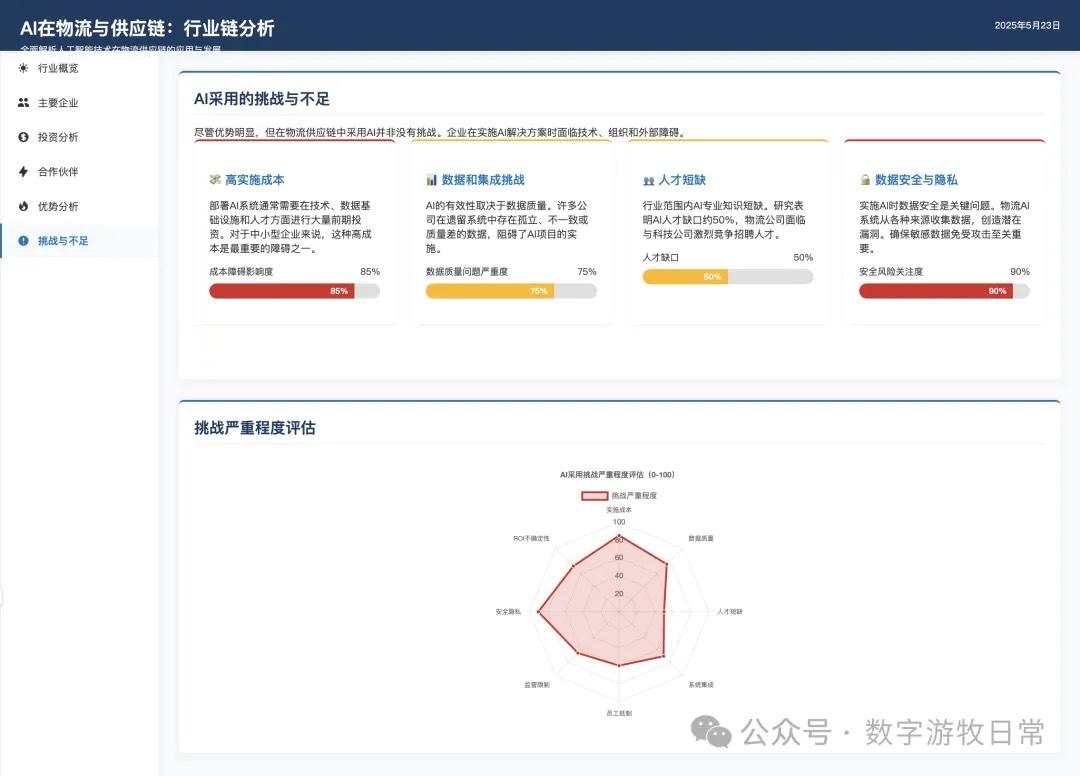
Returning to the model, I tested two cases, both based on generating slides from deep reports. For one new case, I completed tests on three models (Claude-4 Opus, Claude-4 Sonnet, Claude-3.7 Sonnet). For an older case from Claude-3.7 Sonnet, I could only complete the Claude-4 Opus test and was unable to finish Claude-4 Sonnet due to limits.
Detailed screenshots of the two cases follow, but first, the conclusion: Claude-4 may be better than Claude-3.7 in fundamental coding abilities, but it is noticeably weaker in outputting detail. This is based on an incomplete experience across two cases, so the conclusions are all "possible." I need to use the model in Cursor for a longer period to give a more objective evaluation.
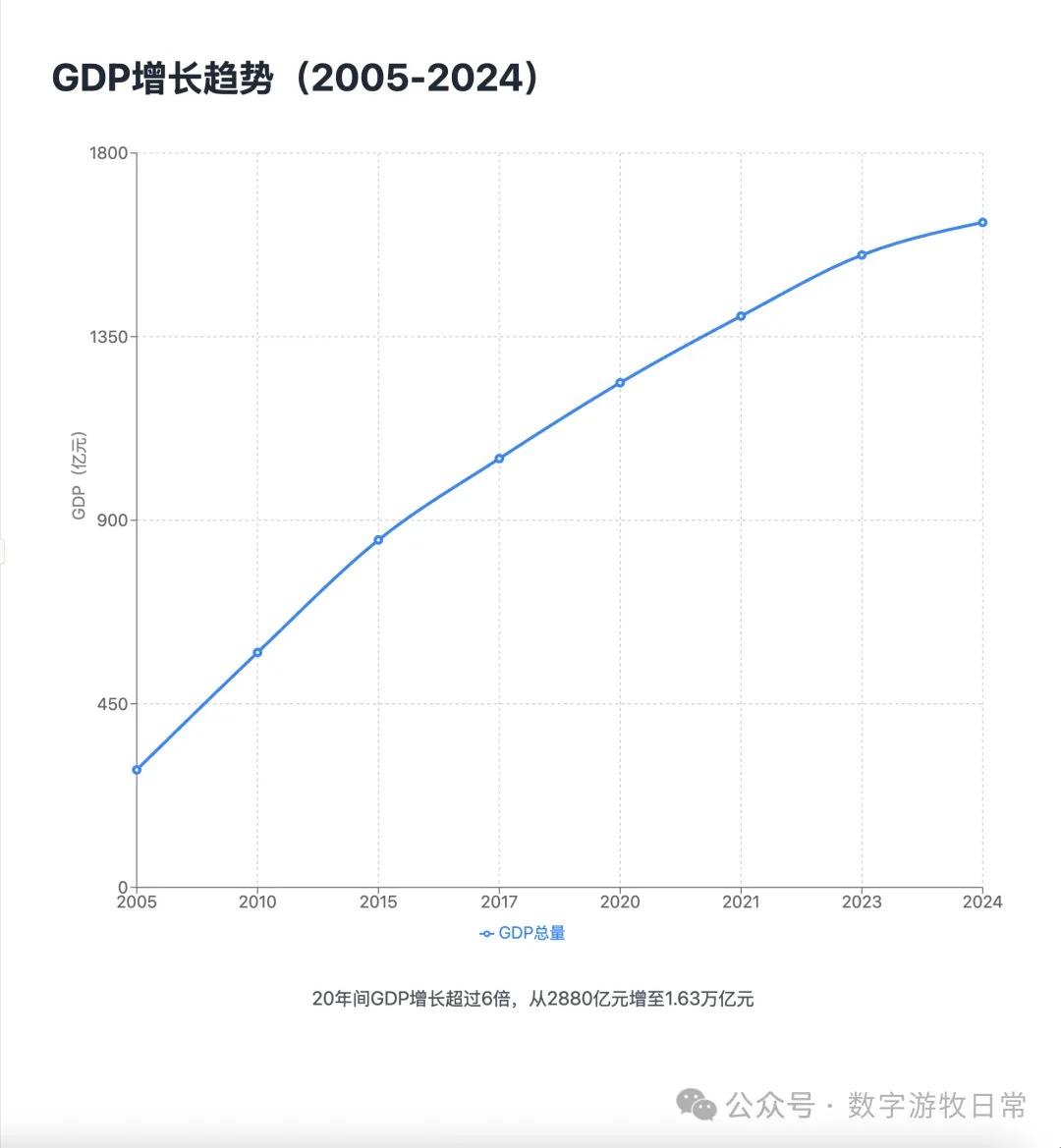
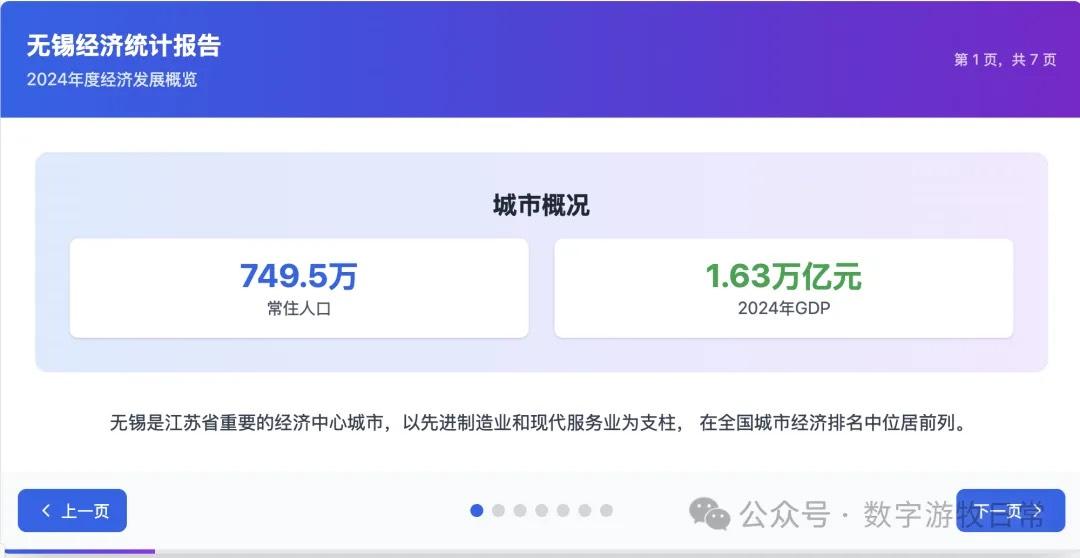
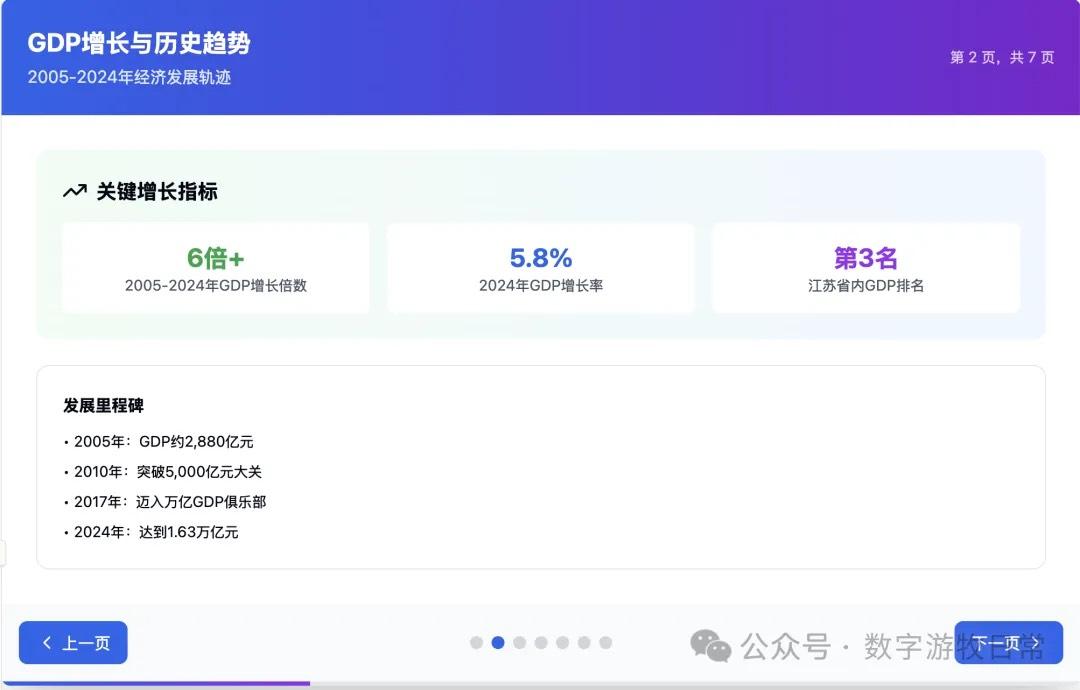
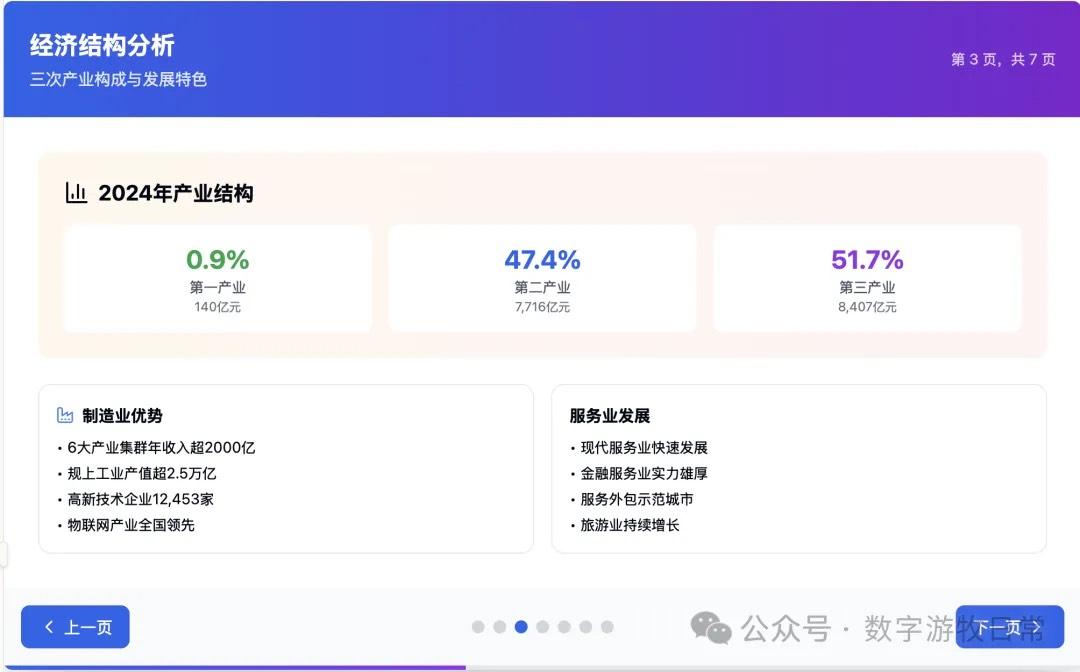
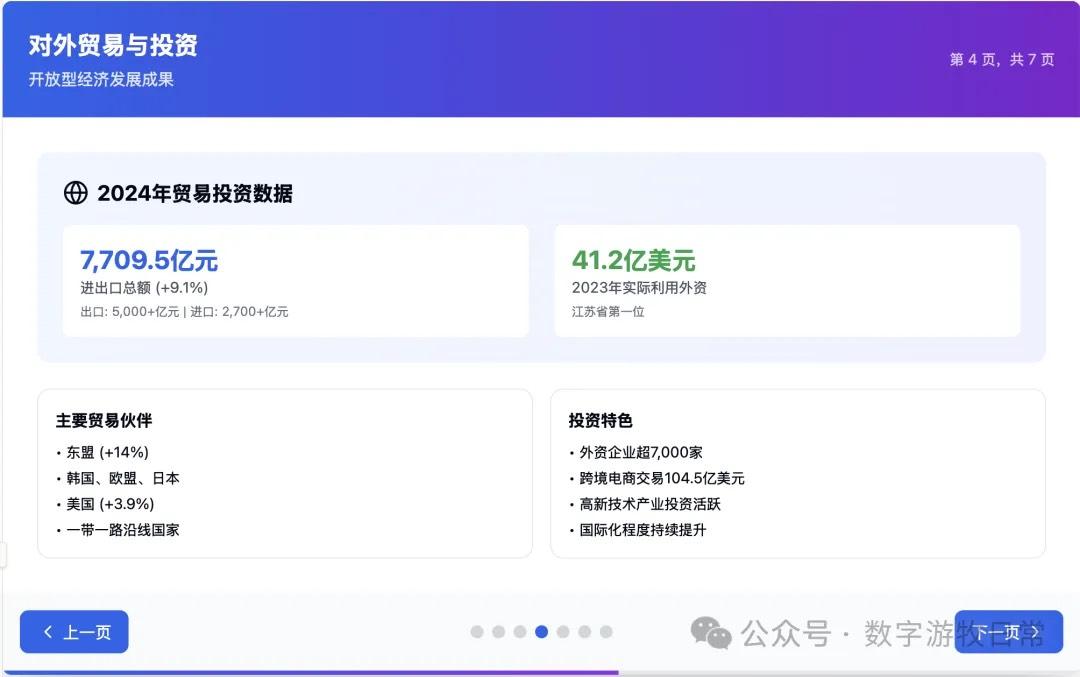
Case 1: I am organizing economic data for my hometown, Wuxi, which naturally involves Deep Research. I used an OpenAI Deep Research report as input to have the model generate an interactive PPT (a workflow I do almost daily and am very familiar with).
First, screenshots of the Claude-4 Opus results: Not impressive at all. It completely fails to deliver the experience expected of a version "4," let alone Opus.

(There is a visible display bug on the page above)

Claude-4 Opus's results are somewhat disappointing. Claude-4 Sonnet is naturally a more simplified version.
I don't quite know how to evaluate the results above. But as they stand, they are definitely below expectations. Fearing my case might be criticized as unrepresentative, I had Claude-3.7 Sonnet complete it as well.


(There is also a clear error on the page above where the display is abnormal)
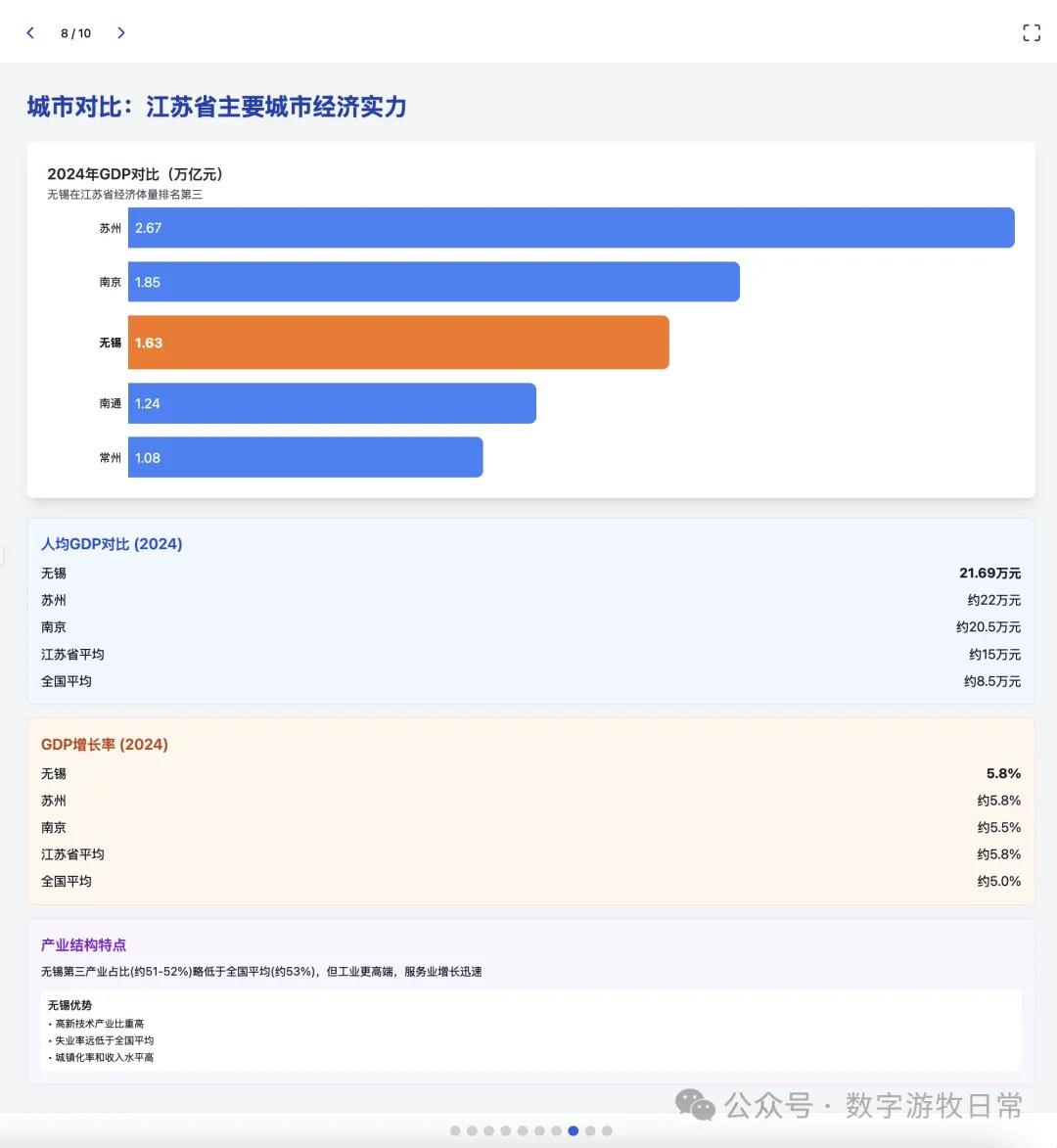

Actually, the result is distinguishable at a glance: Claude-3.7 Sonnet is better in both visual effects and richness of detail.
Of course, in this case, I wondered if it was because my prompt was too simple to reflect the hidden richness of Claude-4 (after all, I've been criticizing over-thinking; is it possible Claude-4 achieved a different kind of balance?).
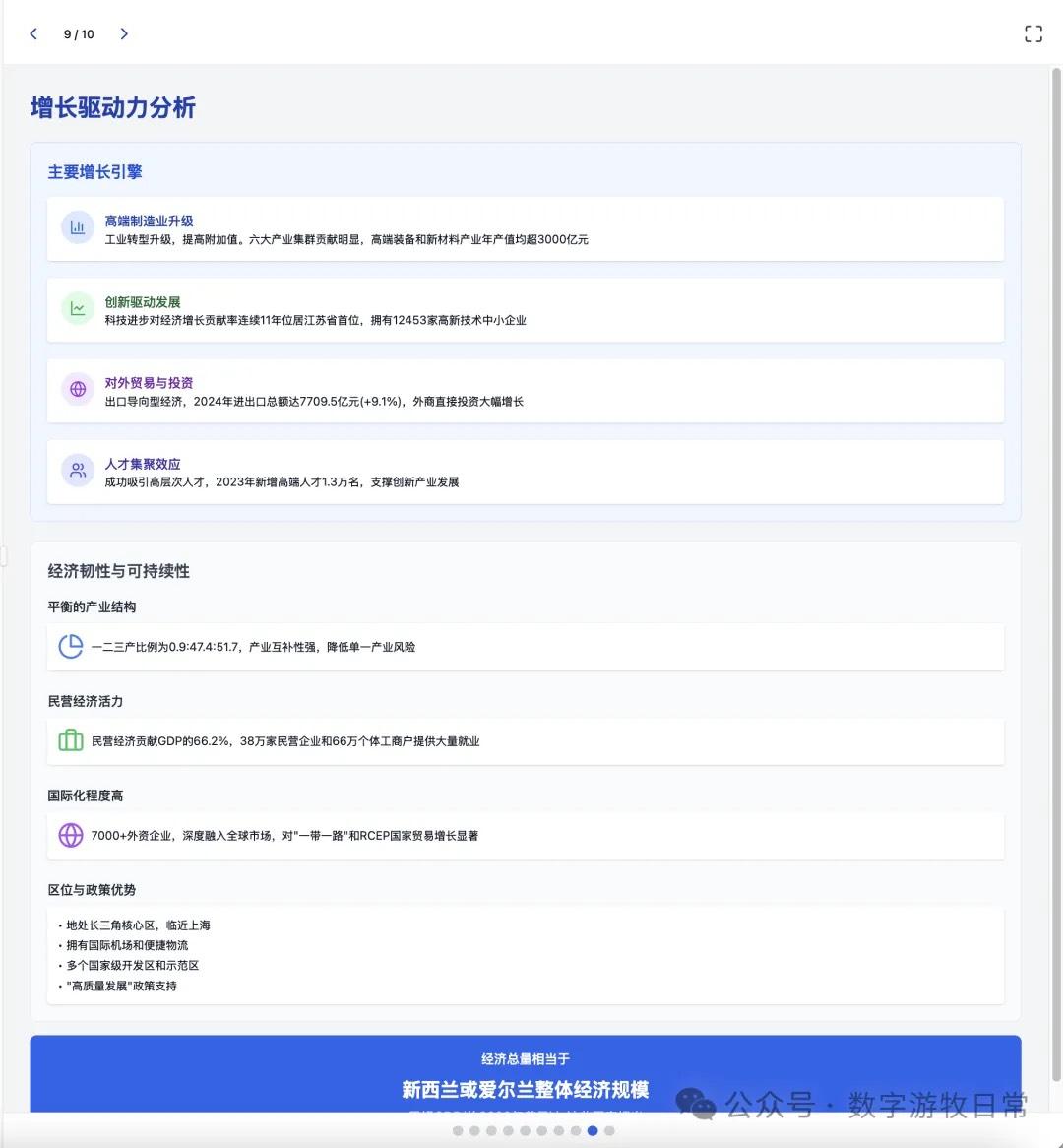
So I switched to a case Claude-3.7 has been working on: using my full version prompt (including layout, color scheme, chart styles, detail arrangement, etc.) to visualize a past Deep Research report.
Claude-4 Opus version results are as follows:

For comparison, here is the version from Claude-3.7 a month ago:
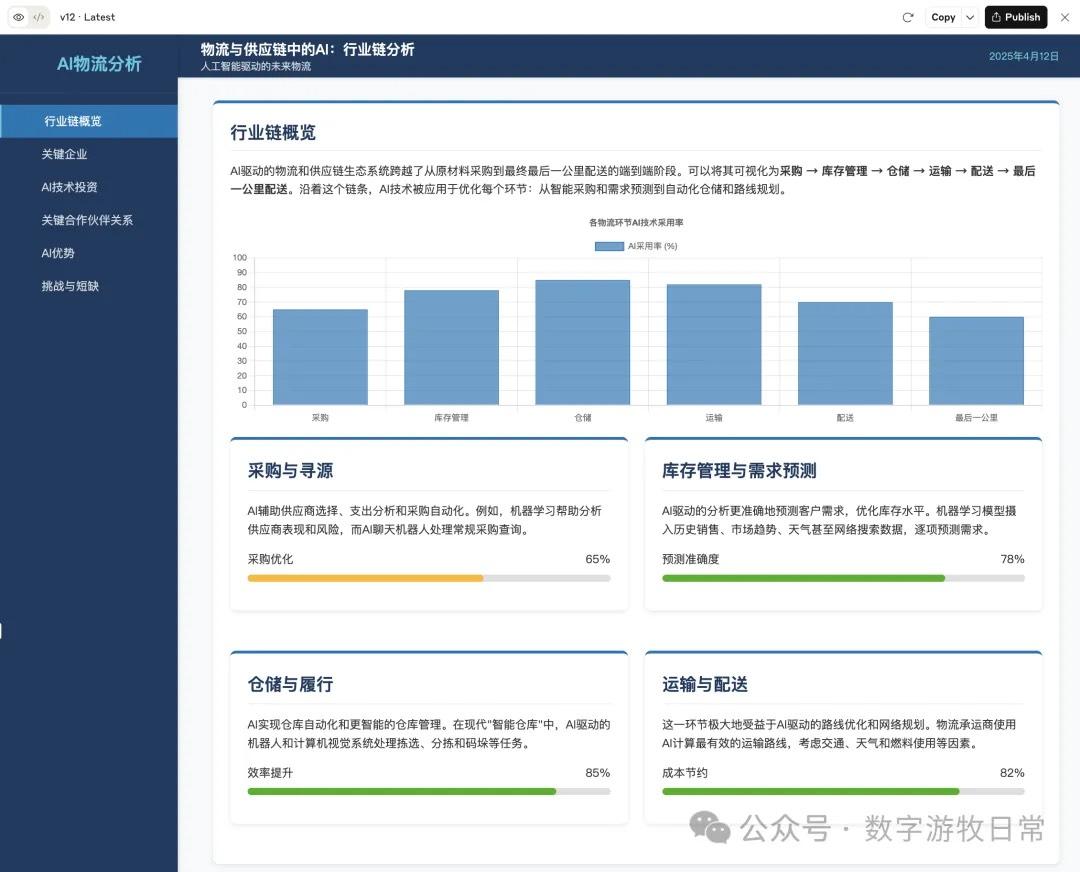
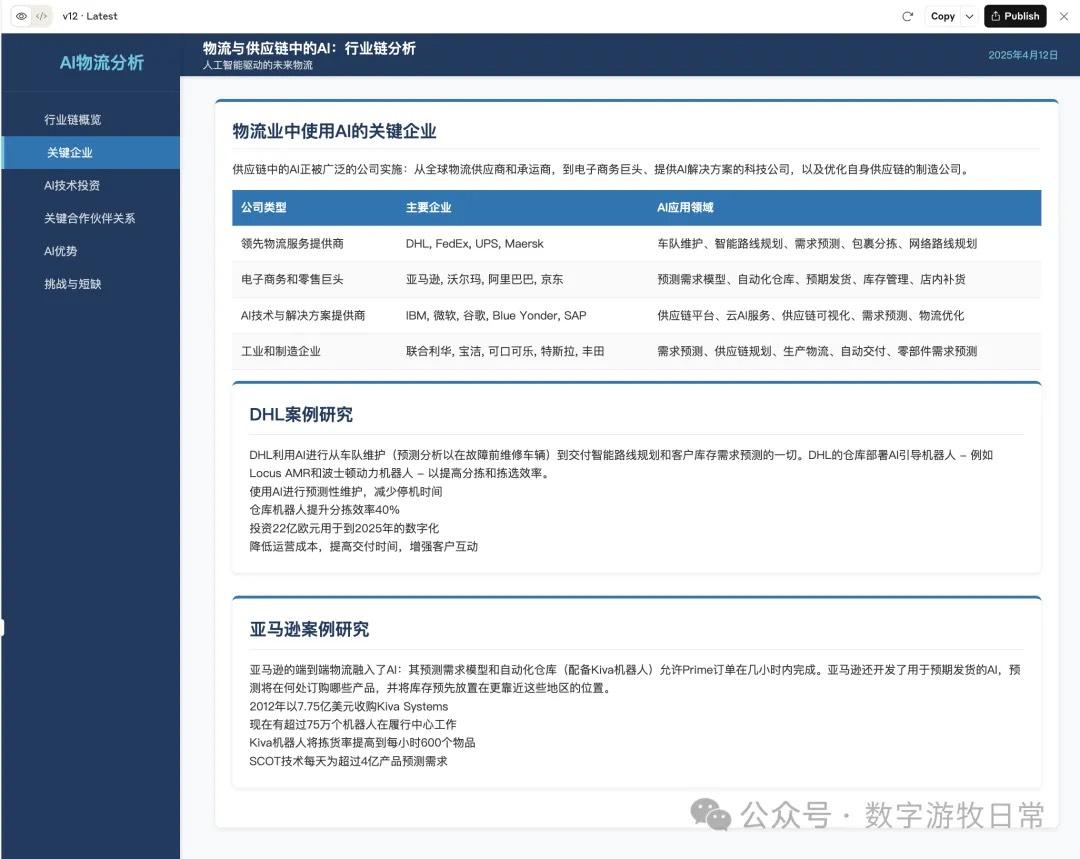
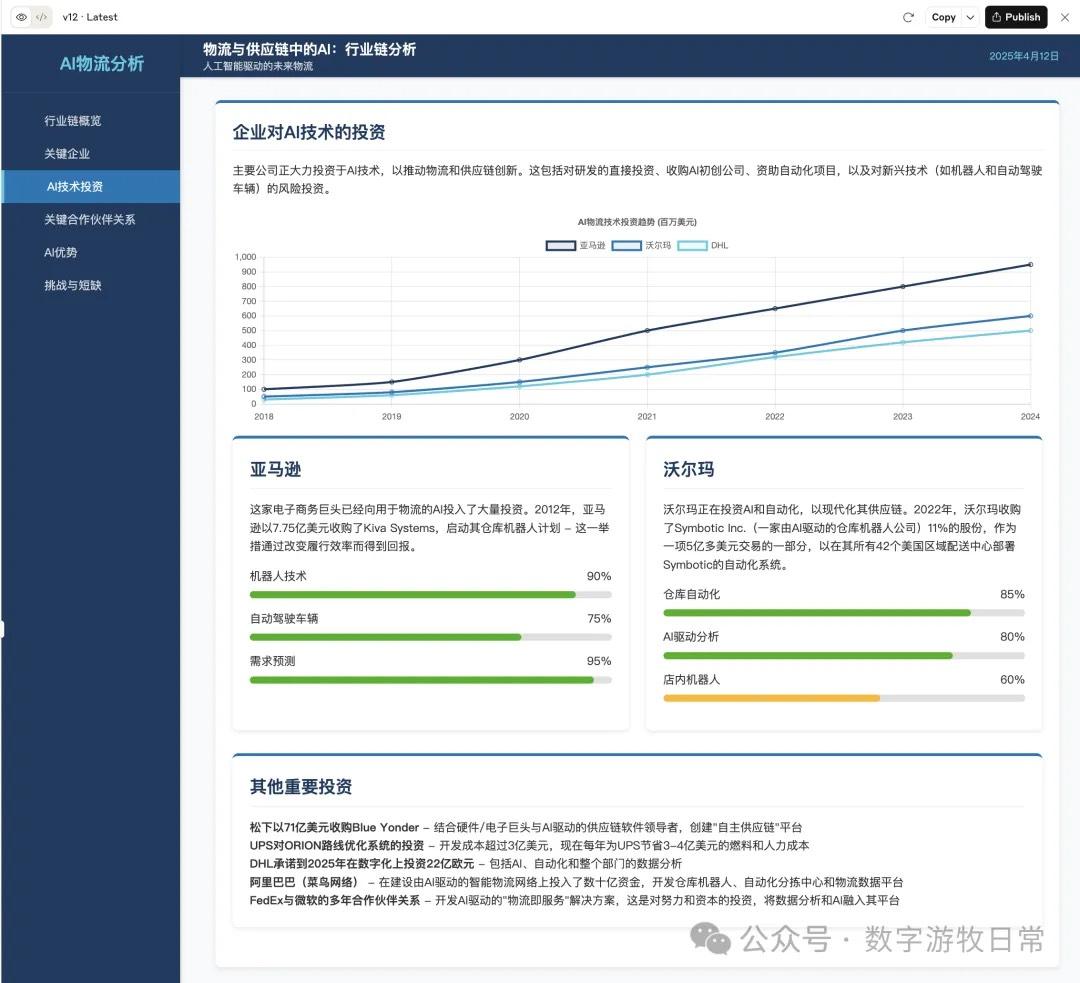



Comparing them this way, Claude-3.7 clearly remains the better result—winning on the single point of having more detail.
However, if we consider another dimension: this Claude-3.7 version was obtained after 11 self-revisions by the model (see the "v12" in the top-left corner; every step had code errors, and the model fixed its own code, requiring manual clicks).
In contrast, the Claude-4 Opus version was generated in one shot.
This is actually a huge difference. I believe it will bring a significant improvement to the "Vibe Coding" experience in Cursor. However, this needs a longer trial period to reach a conclusion.
Cursor has already added support for Claude-4, but only Sonnet is included in the subscriber selection range. Opus requires enabling the "pay-as-you-go" Max mode.
Final conclusions:
Objectively speaking, compared to before, this Anthropic release feels a bit too simplistic—just a single page, a three-minute video, and some basic scoring information. This isn't Anthropic's usual style. Previously, model releases included massive detail in a Model Card. Even though that information has been "shrinking," for a major version like "4," I couldn't even find a Model Card (I found a System Card).
I understand Anthropic is pushing "Code" applications and Max subscriptions. The former can significantly increase API call volume, and the latter increases revenue from $21.8/month to $100/month. But based on the product capabilities shown, it's far from worth that price. Anthropic might not just be "flinching," but under pressure, their approach has become somewhat ungraceful.
Regarding the model itself, Claude-4 may once again prove the fact that models have "hit a wall," at least in single-modality.
Yes, as mentioned in the message from my friend: "Anthropic's survival space is being heavily squeezed."
Google, with its deep pockets, is showing more possibilities through Gemini-2.5 and its ecosystem capabilities. OpenAI's ChatGPT, with its massive first-mover advantage, is still seeing rapid growth in active users.
Furthermore, through AI-Studio, Gemini-2.5 still provides a considerable "free quota" every day. While OpenAI's Deep Research is noticeably inferior to Gemini-2.5 in terms of data freshness and search capability, it is more stable and comprehensive. After Gemini-2.5 significantly improved its coding abilities, it is gradually eroding the demand for Claude's API calls.
The probability of Anthropic falling behind has perhaps increased significantly compared to my prediction at the beginning of the year.
Of course, in the 2025 AI world, it's still "the model that determines everything." The stage (the examination hall) is now handed over to OpenAI.