
Claude-4发布了,先说些题外话。
在我还差一个问答就要完成对Claude-4的初步对比体验后,我被“限流”了。
事实上,在每月100美金的Max订阅发布后, I用过一个月的时间,为了看Claude的Deep Research能力,但是结果异常失望,所以就回到了Pro订阅,并且选择了年付(订十个月送两个月?)。
与新模型发布同时推出的是所谓的礼物:分享送四个月Max订阅(注意,这还是满足条件后抽签才能获得,我本来还准备分享自己的链接,但是看到条款后还是算了,丢人)。
这些都不是好的体验。自从模型的代码生成能力断档领先和Artifacts功能推出后,我其实一直很喜欢Claude的“独特”,无论是APP的UI设计,还是生成的可视化效果,都有一种“高级感”。
但是,此时此刻,却有一种说不出的感觉:
1、被限制的不仅仅是Claude-4模型,3.7也被限制了,但是在过去的半个多小时里,我只进行了四次对话,而在3.7出来后,即使Pro订阅,也从未发生过“限流”情况;
2、为了推100美金的Max订阅,产品做的好还情有可原,明明是Deep Research差到我一直不好意思说后退订的,现在玩这些手段,不知道该如何评价;
以上题外话的结论是体验很差,如同嚼蜡。恰好朋友发来信息:感觉Anthropic的生存空间被大幅挤压了。我认为是这样的。同时,是否也表明,这家初创企业正在面临巨大的收入压力?
回到模型,我测试了两个案例,其实都是基于深度报告的可视化幻灯片生成的。其中一个新案例我完成了三个模型的测试(Claude-4 Opus,Claude-4 Sonnet,Claude-3.7 Sonnet),还有一个以前Claude-3.7 Sonnet的案例我只能完成Claude-4 Opus的测试,无法完成Claude-4 Sonnet。
后面会有两个案例的详细截图,先说结论:Claude-4可能在基础的代码能力上比Claude-3.7更好,但是在输出细节能力上明显弱了。这是基于两个案例的不完整体验,所以结论都是“可能”。模型真正的能力我需要在Cursor中更长时间的使用才好给出更客观的评价。
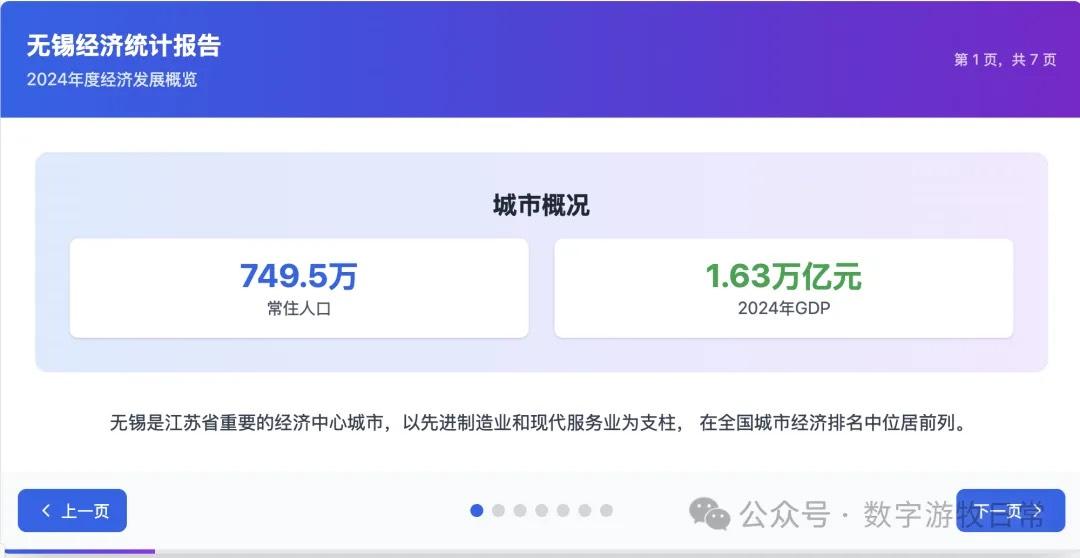
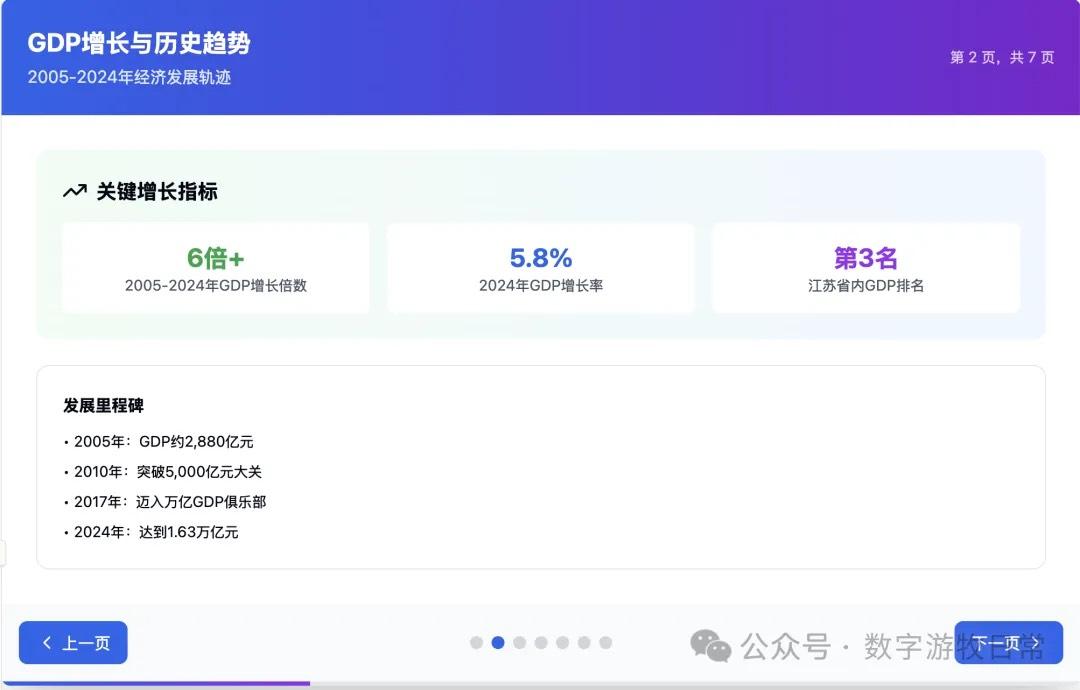
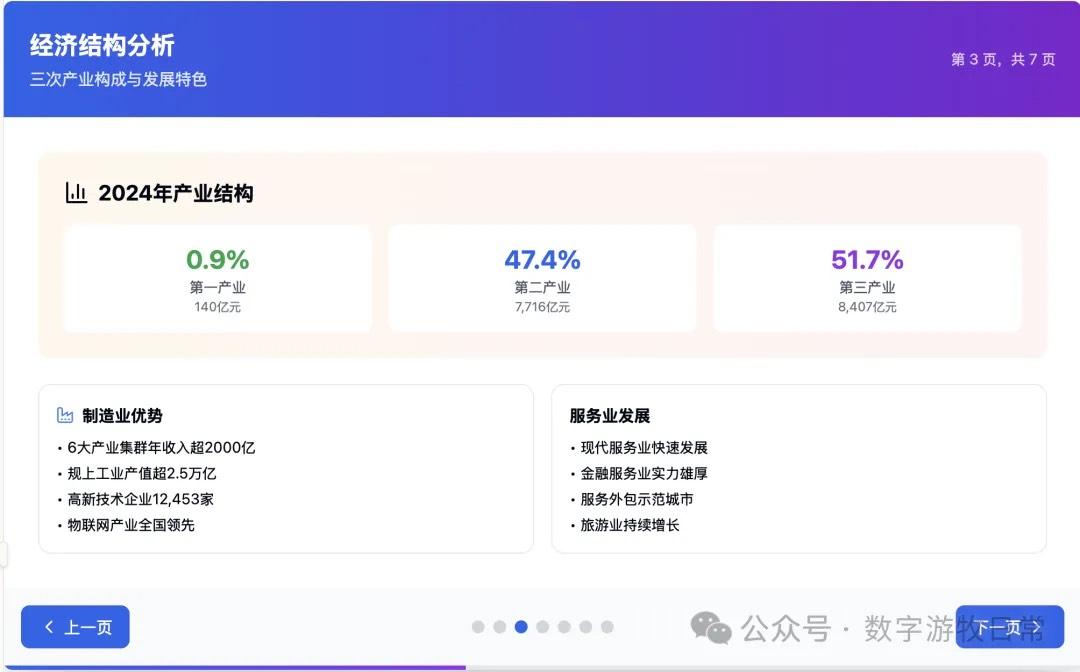
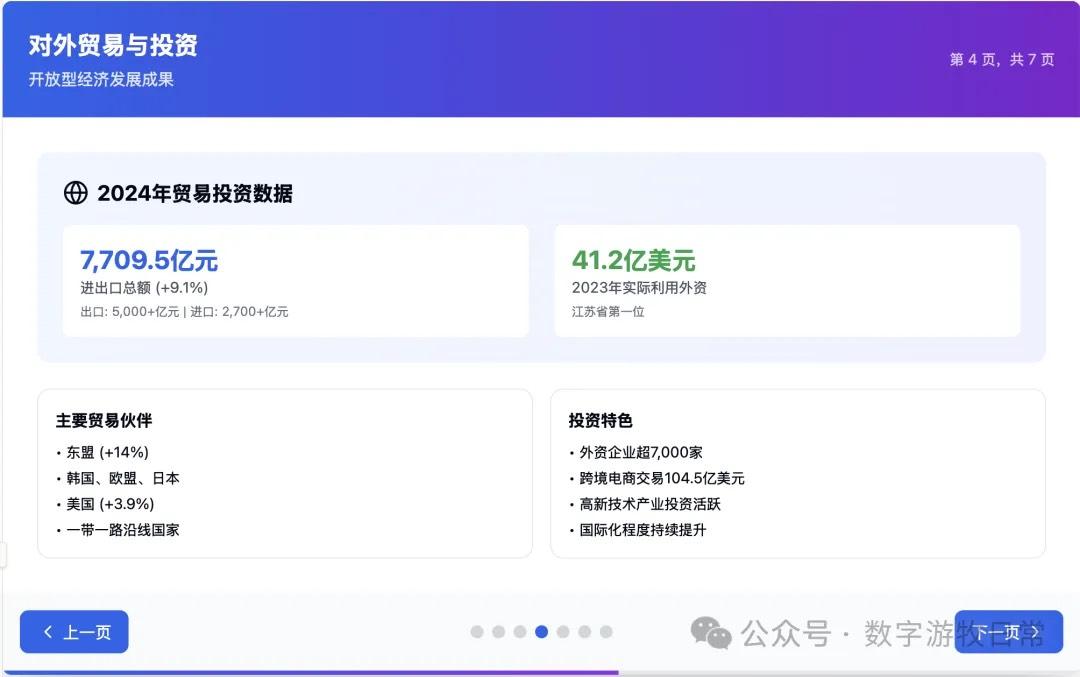
案例一,我正在整理关于家乡无锡的经济方面的数据,当然也少不了Deep Research的参与。所以就以OpenAI的Deep Research报告作为输入,让模型生成交互式的PPT(这项流程几乎天天要干,驾轻就熟)。
首先是Claude-4 Opus生成结果的截图:一点点都不惊艳,完全达不到4该有的体验,更何况是Opus。
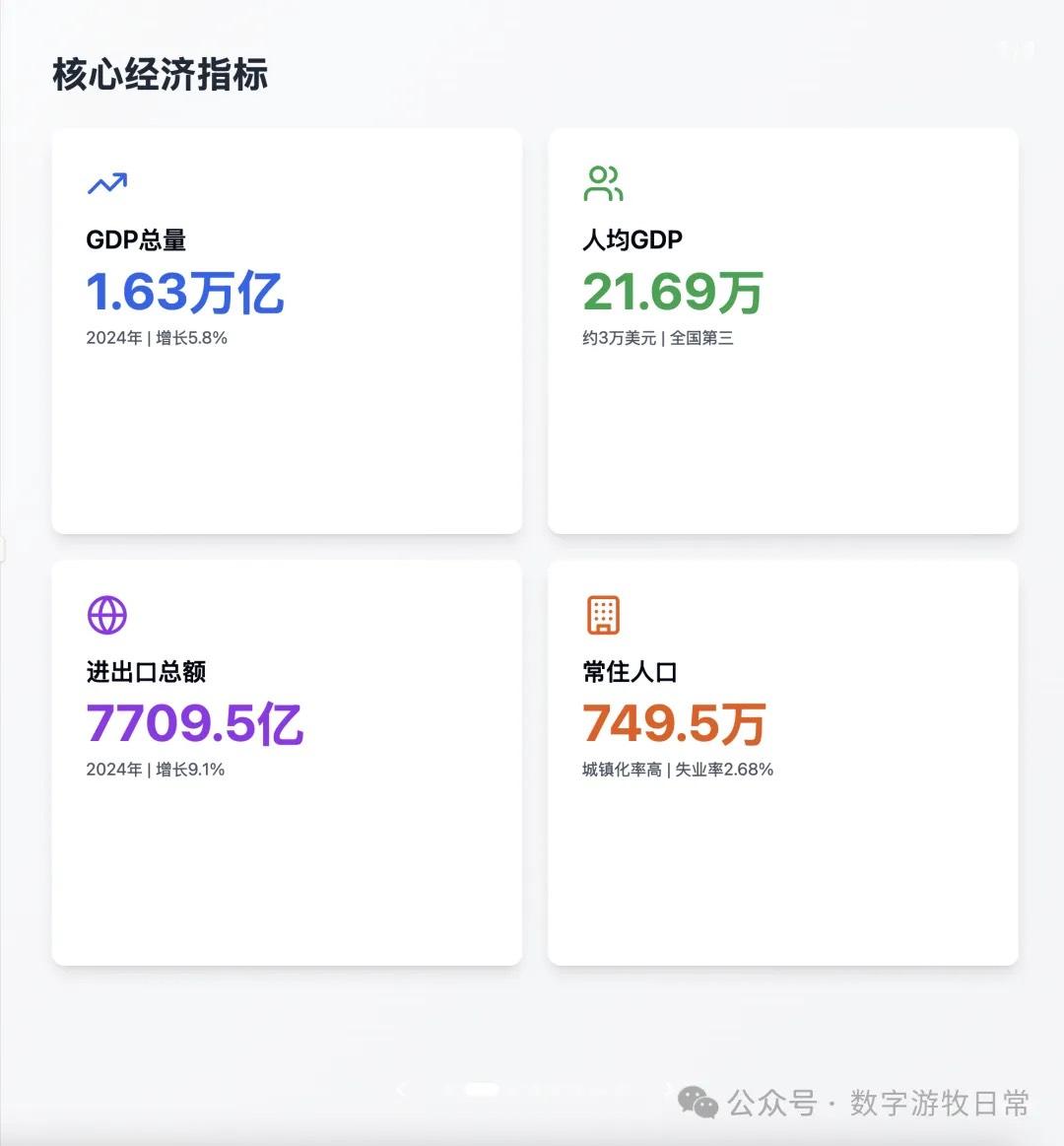
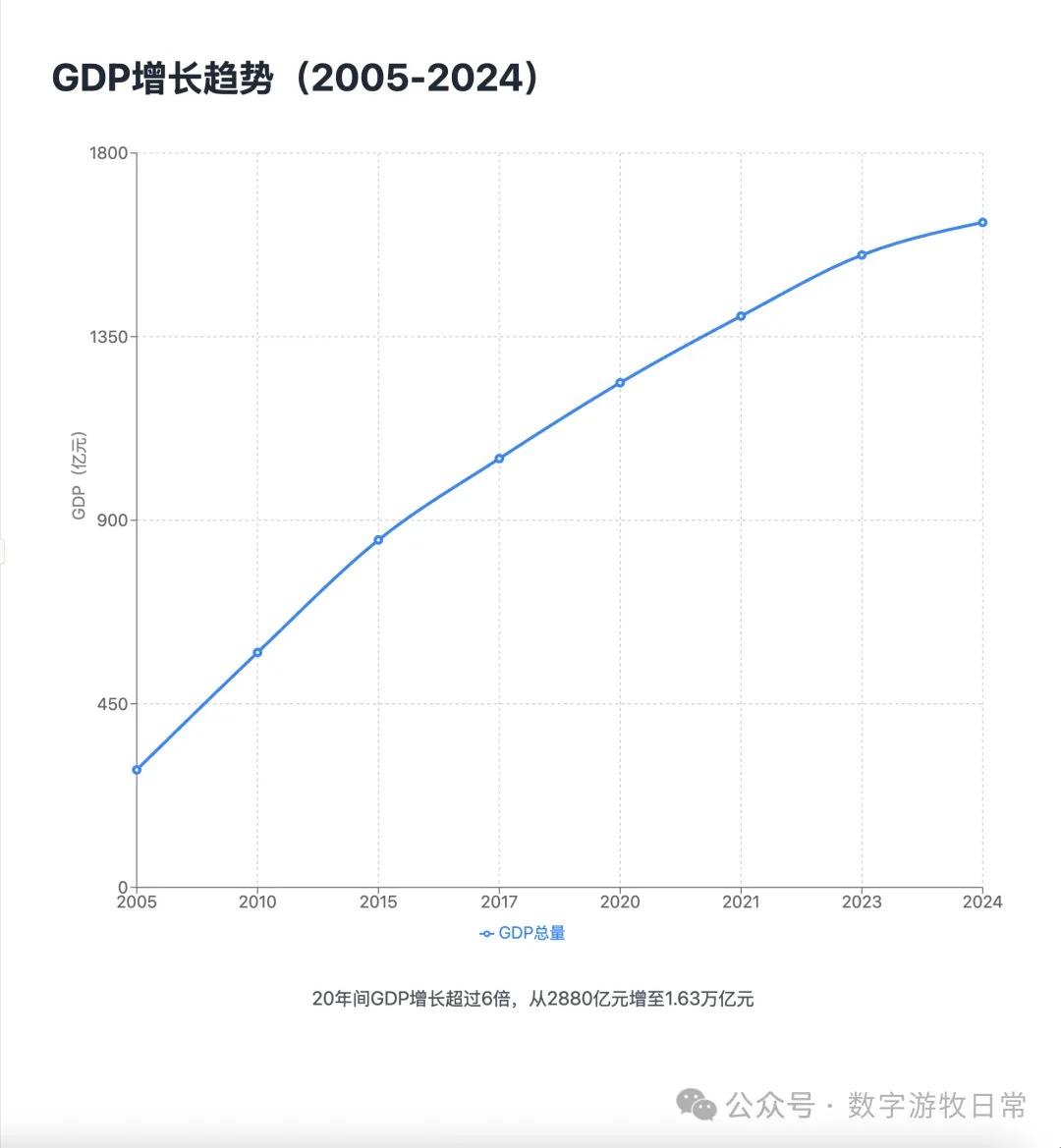
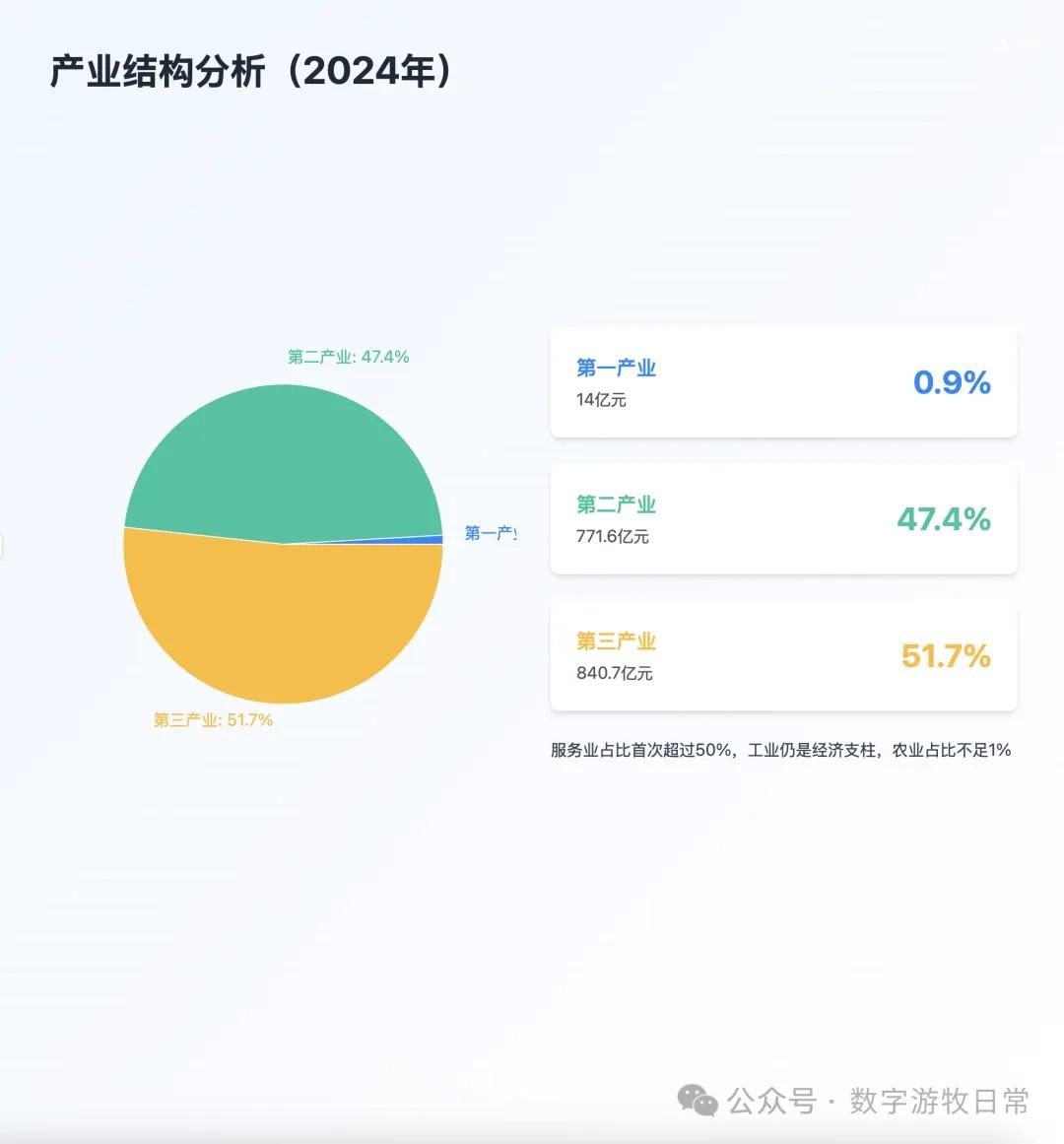

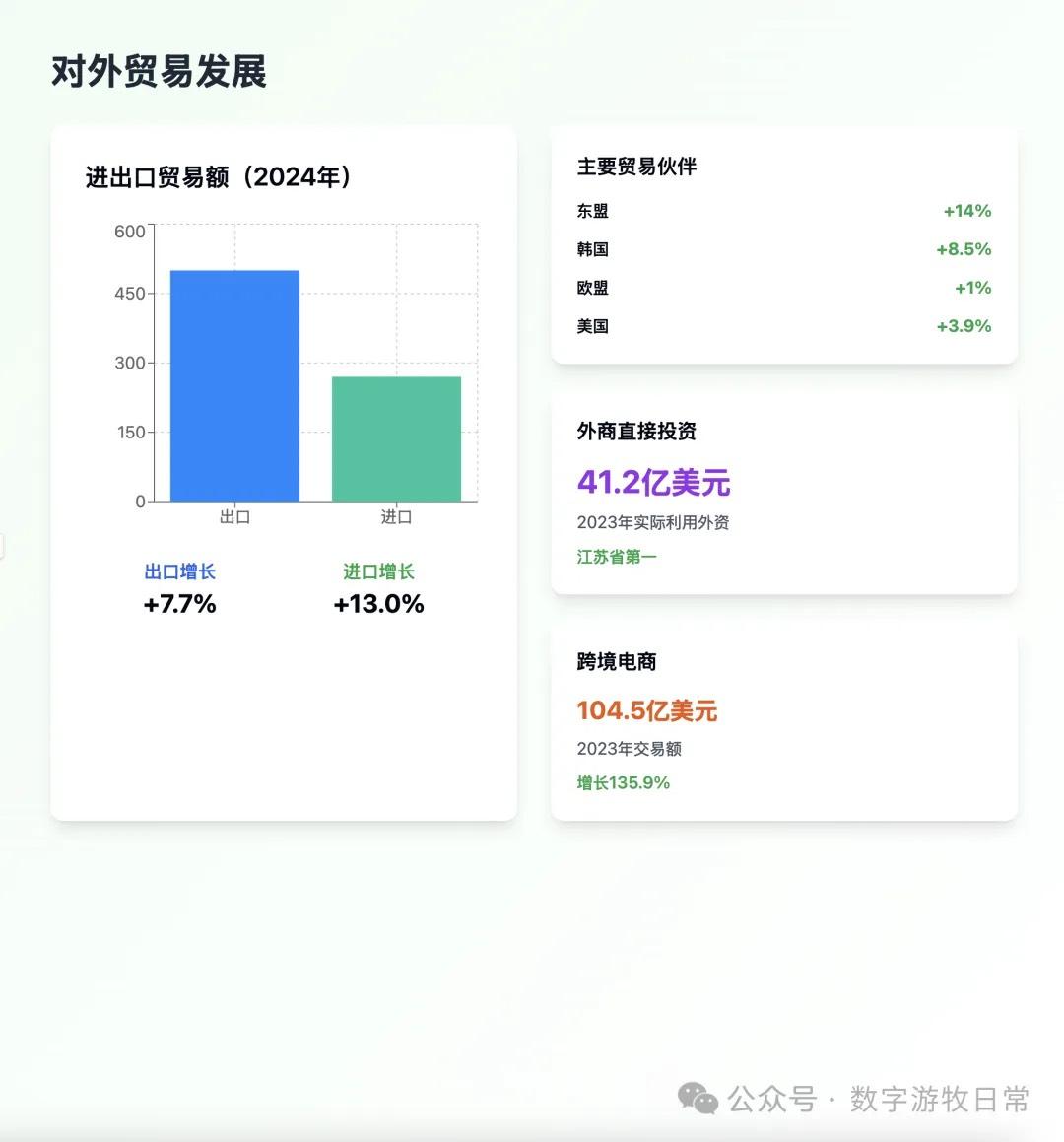
(上页有明显的显示bug)

Claude-4 Opus的结果有些失望的。Claude-4 Sonnet自然是个更简化的版本。
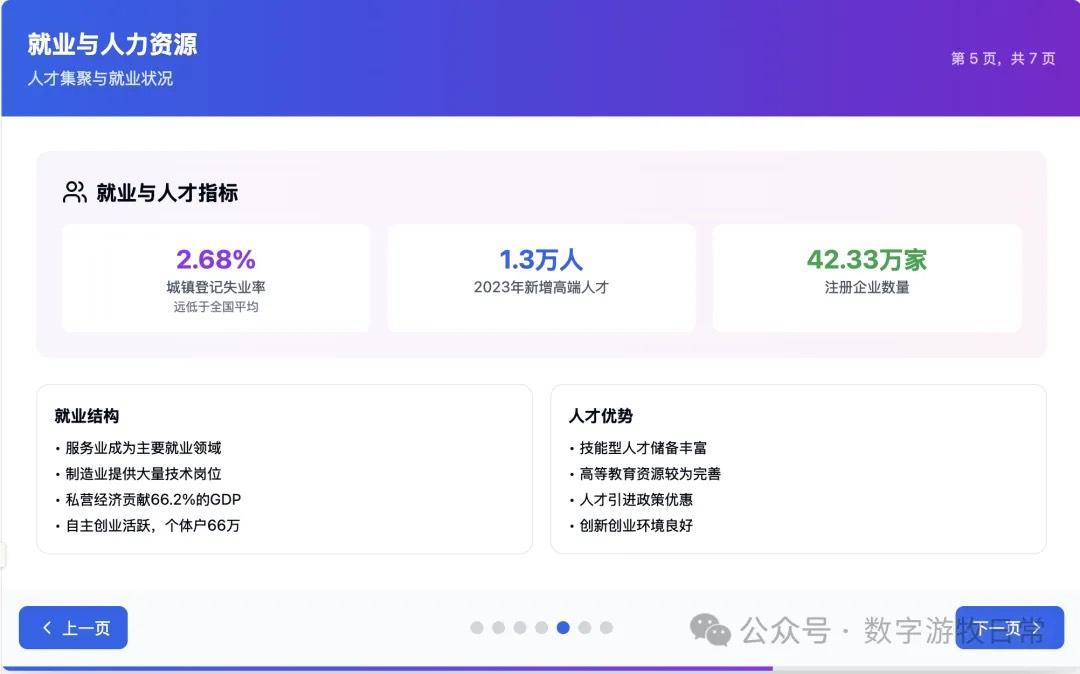
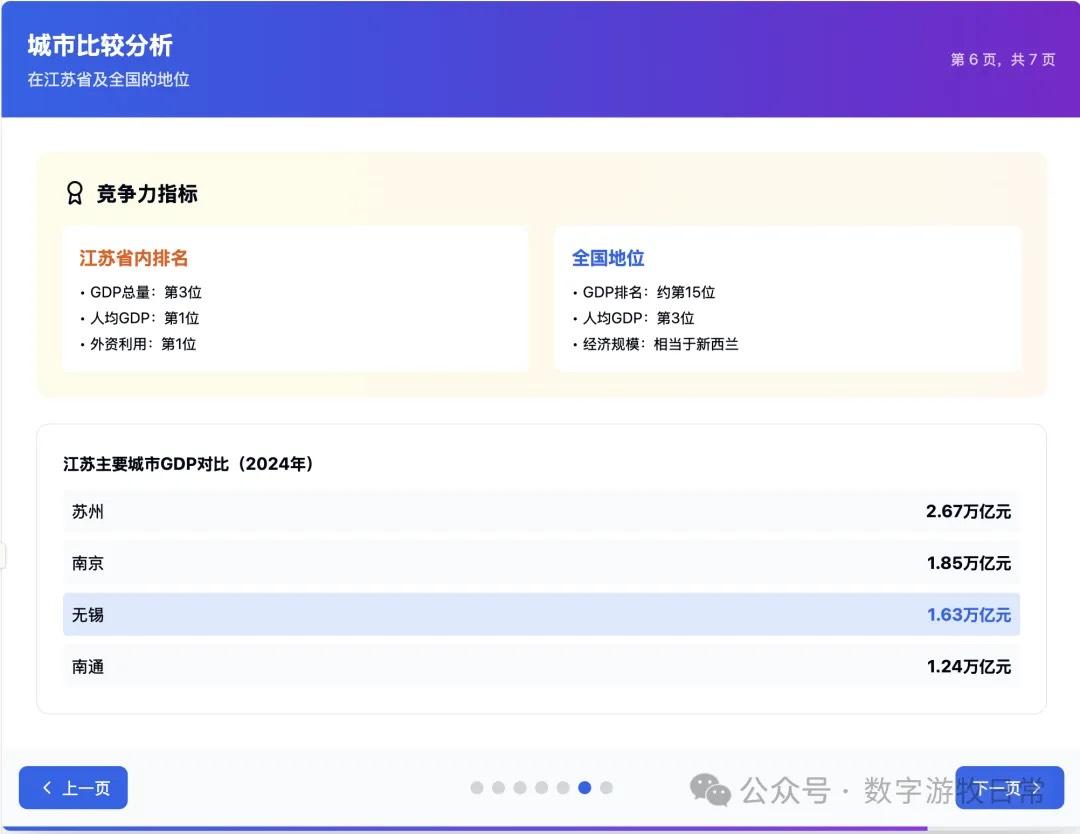
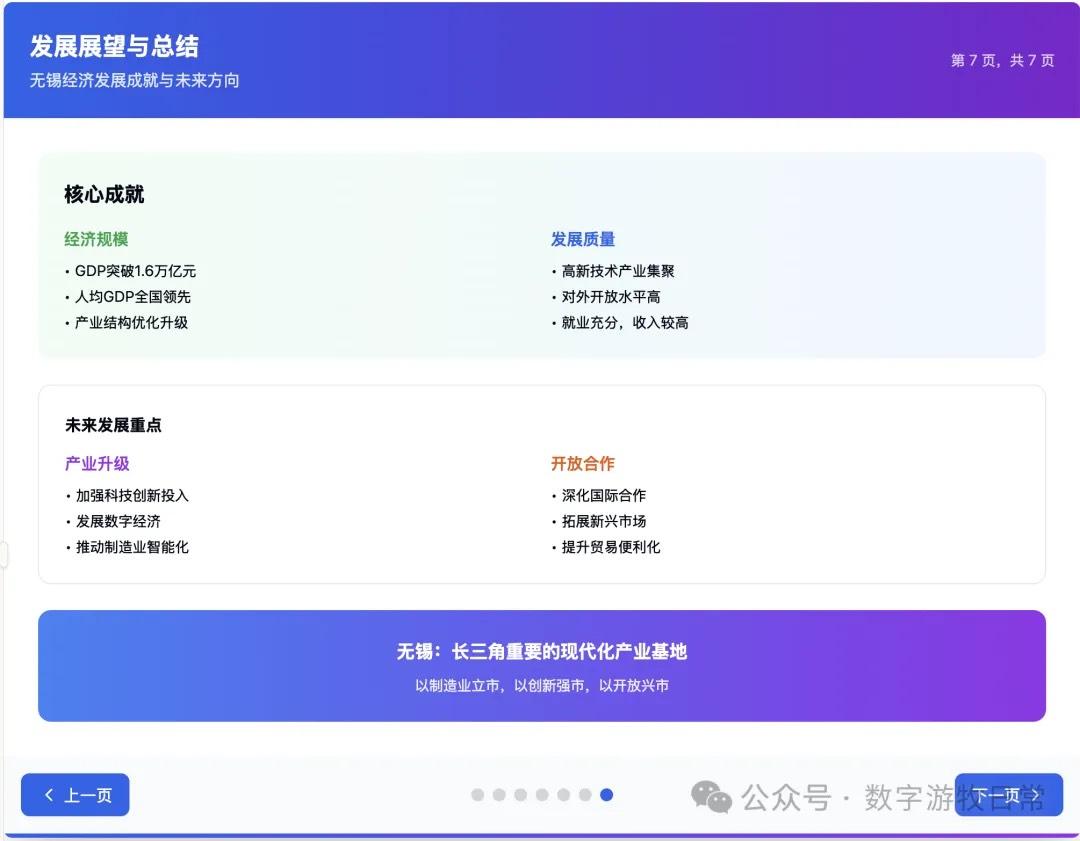
上述的结果,其实我不知道该如何去评价。但是就结果而言,一定是低于预期的,我怕自己的案例被批评没有代表性,就又让Claude-3.7 Sonnet完成了一下。

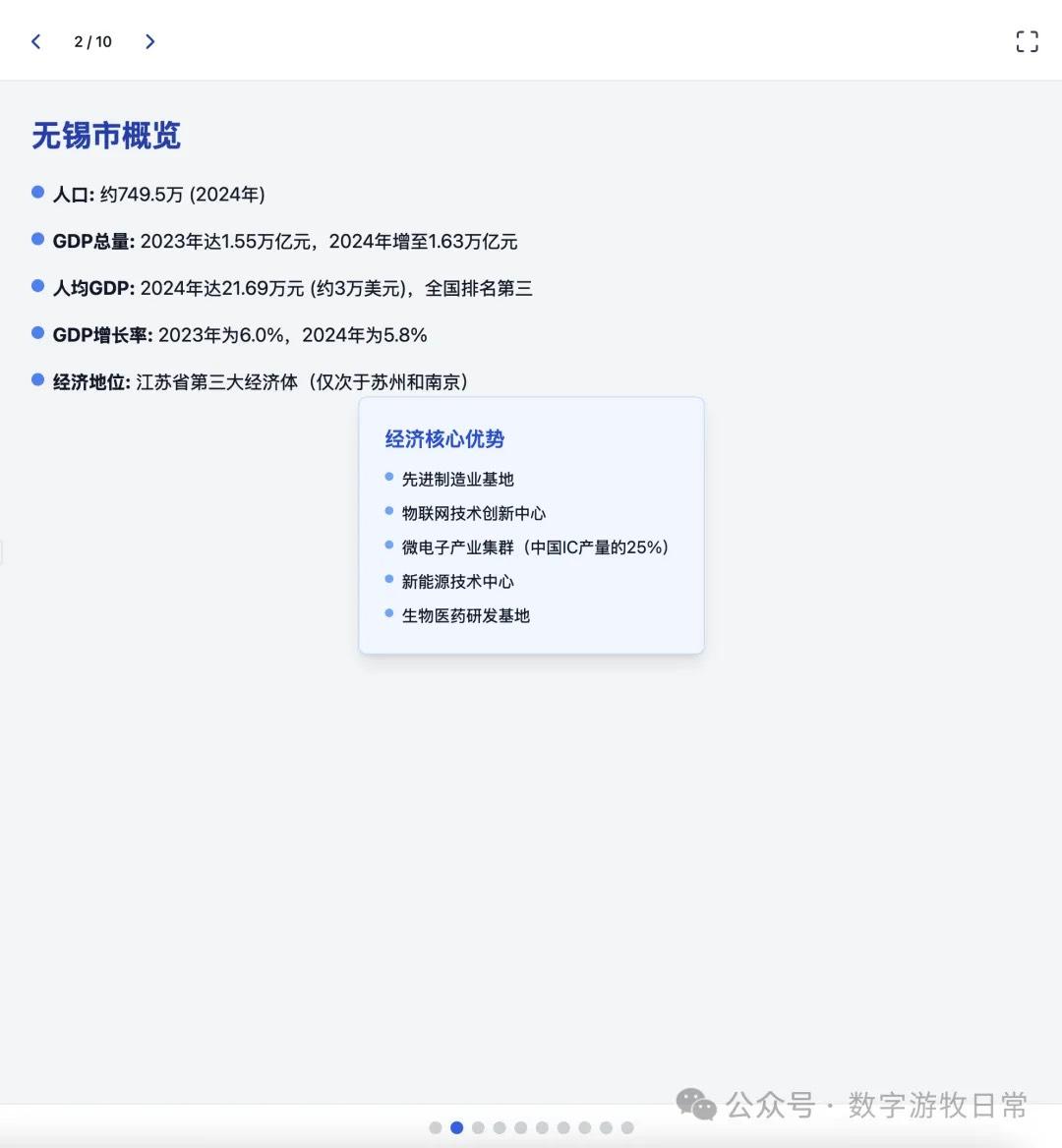

(上页也有一个明显的显示不正常的错误)
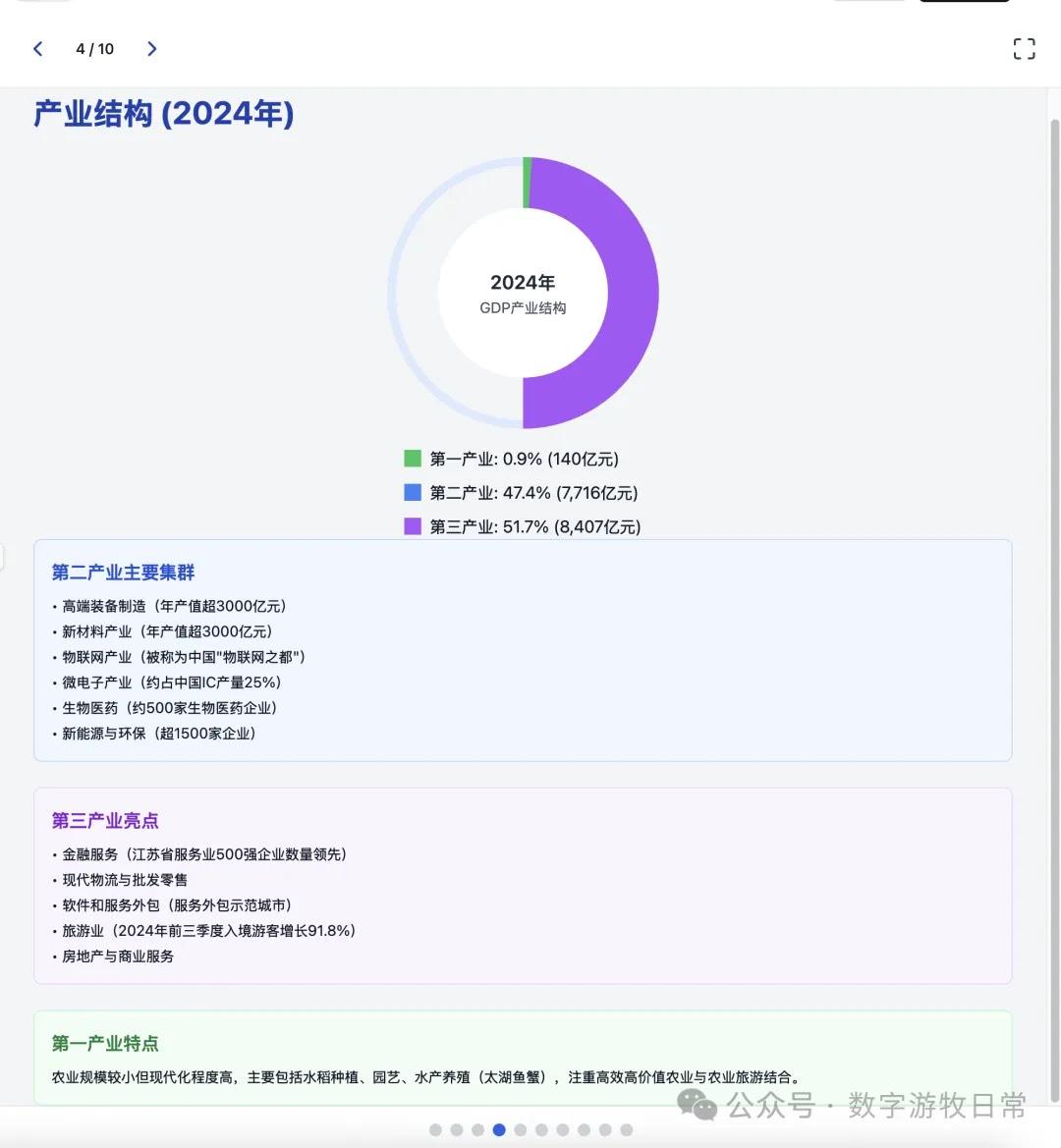
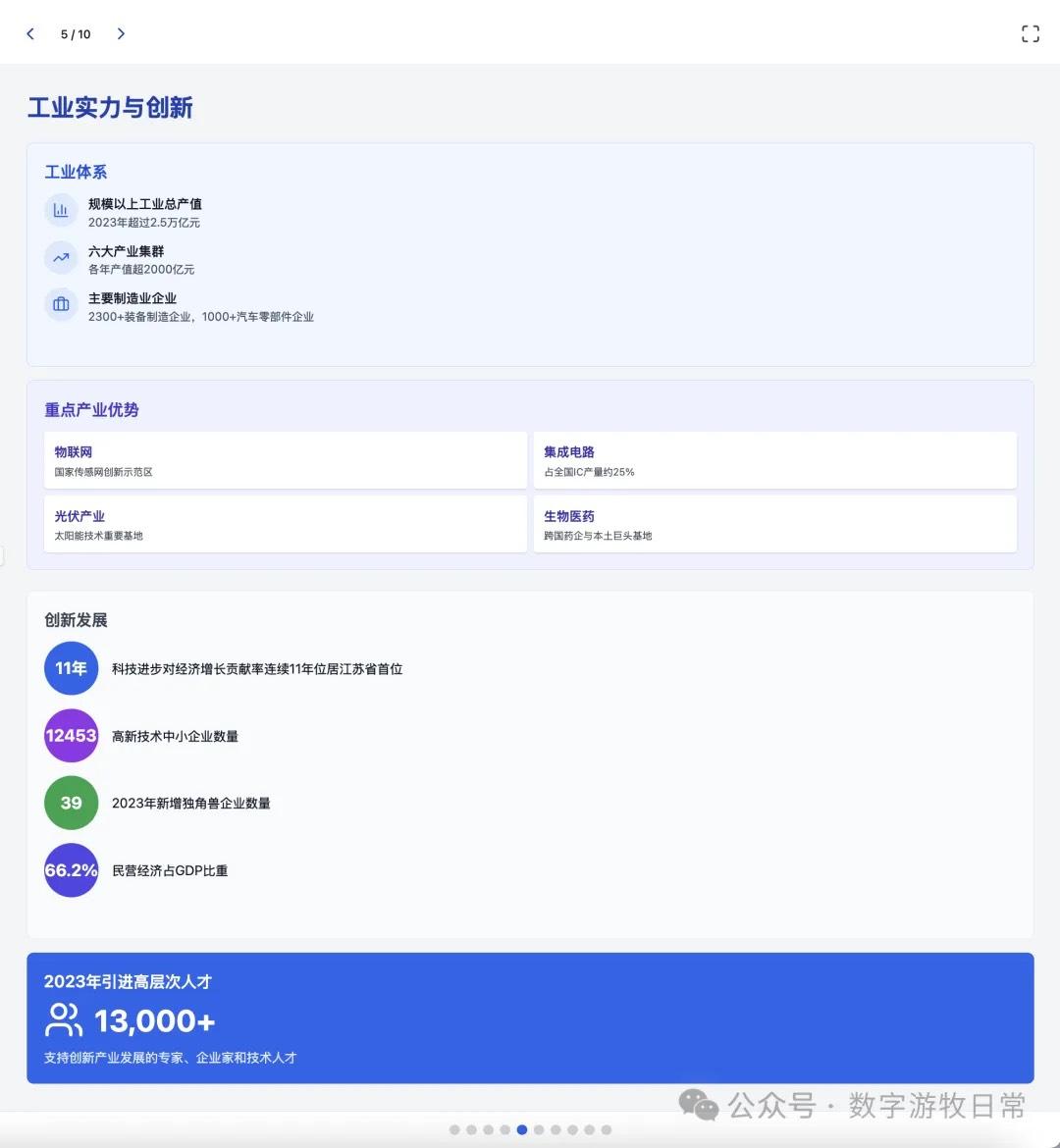
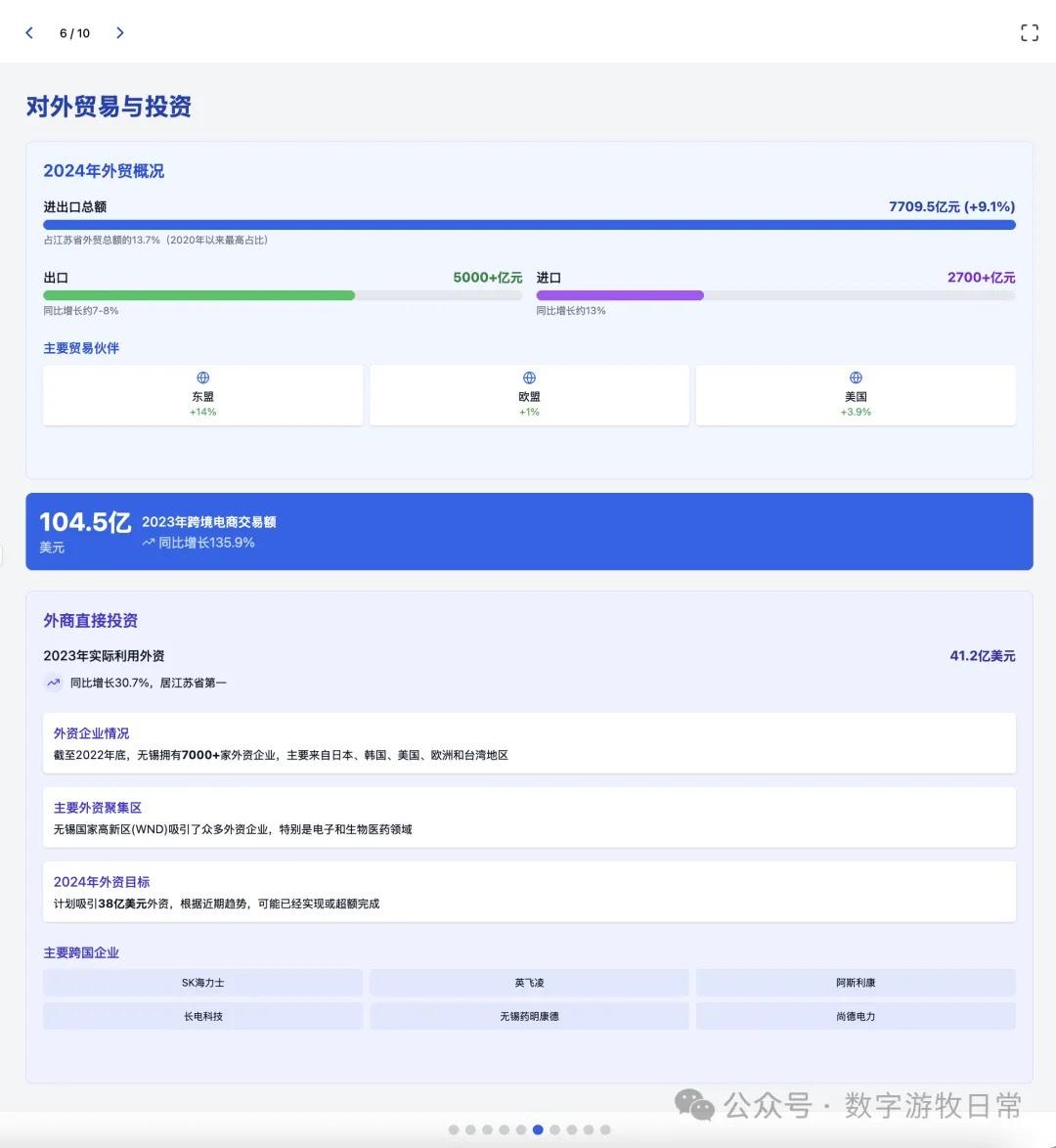
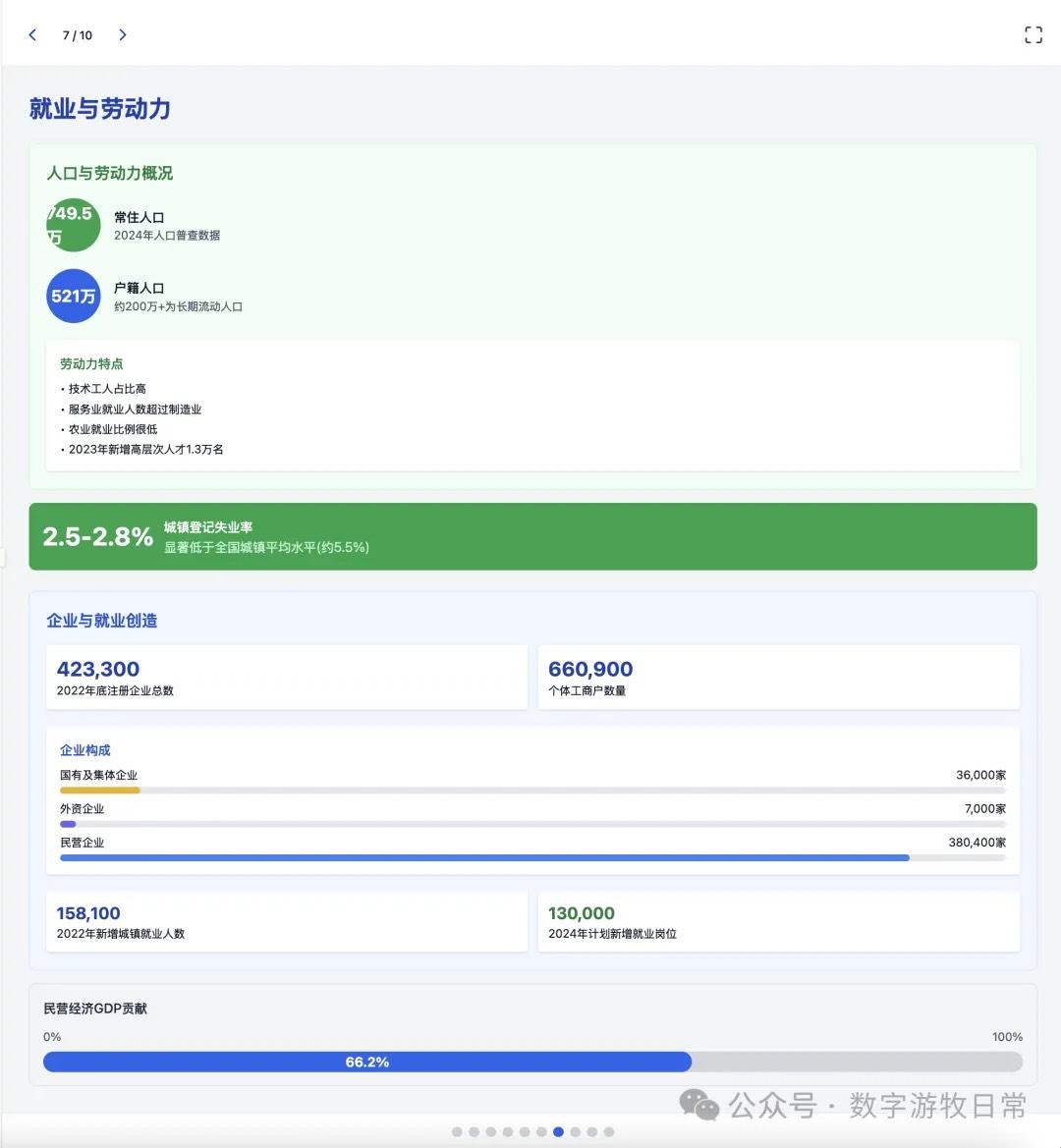
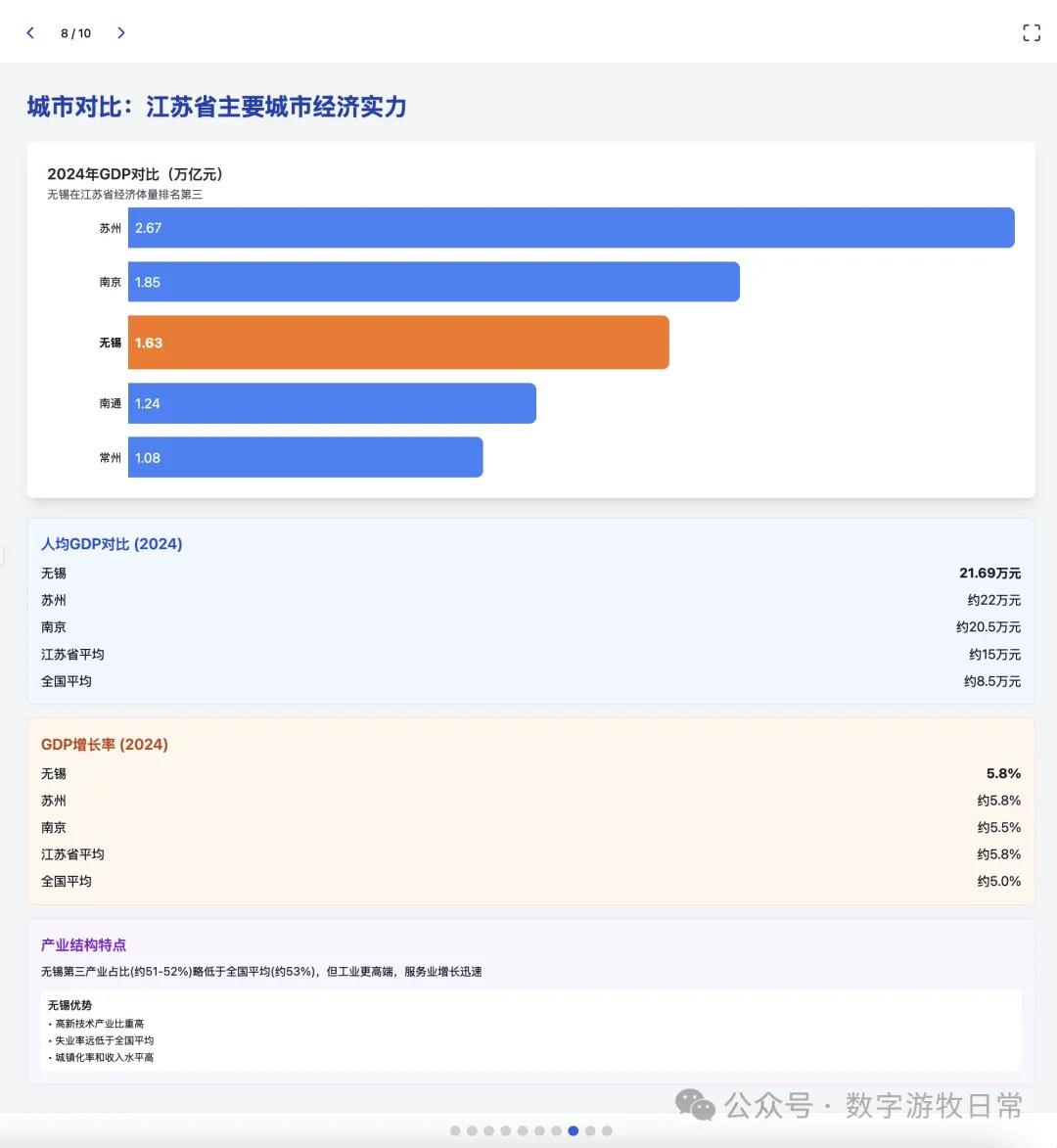
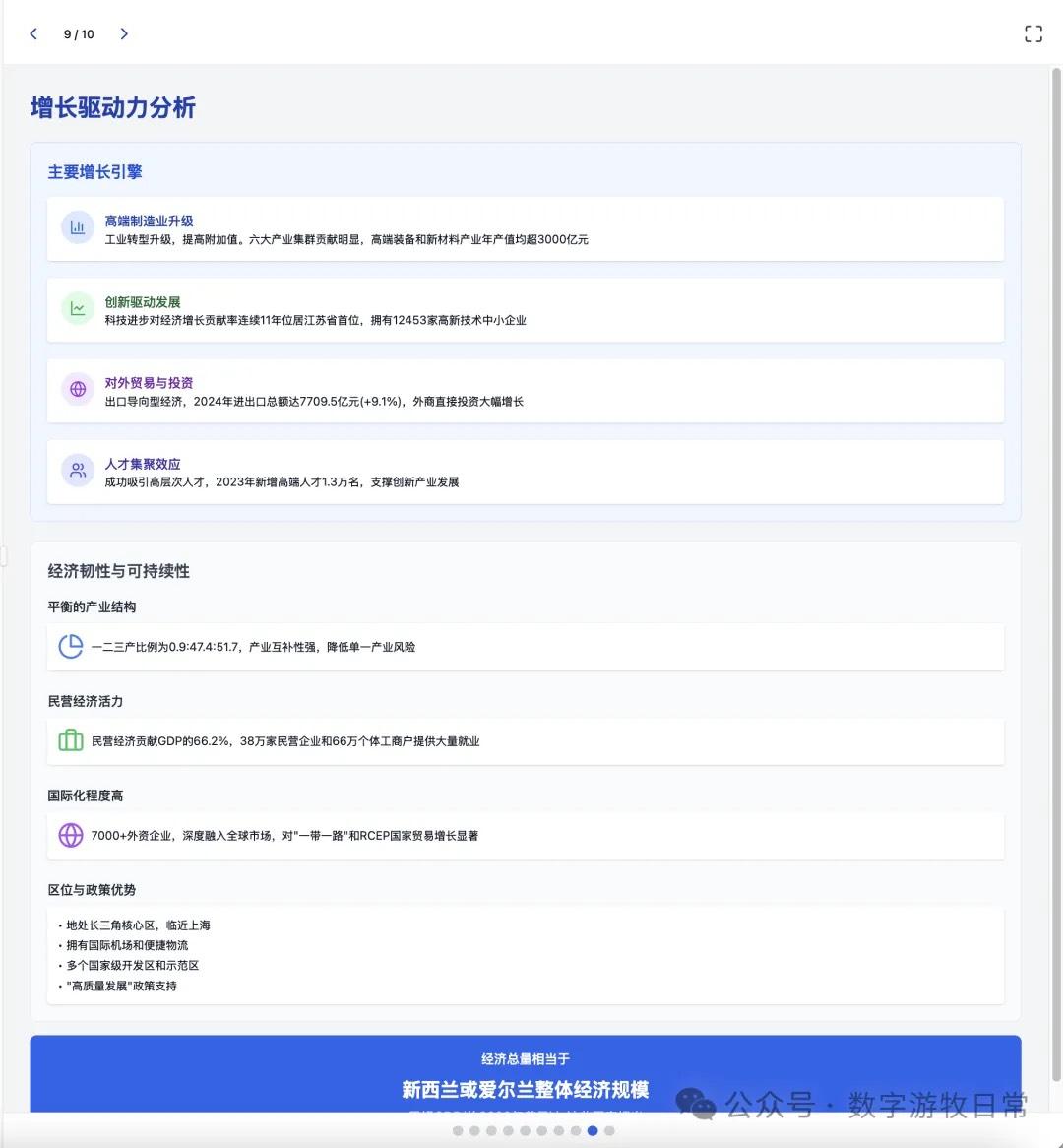

其实结果是一眼就能分辨出来的:无论是显示效果,还是细节丰富度,都是Claude-3.7 Sonnet更好。
当然,这个案例下,我反思是不是因为自己提示词给的太简单,无法体现Claude-4实际暗藏的丰富细节(毕竟我一直在批评过度思考,有没有可能Claude-4就是进行了另一种平衡?)。
所以换一个Claude-3.7一直在进行的工作案例:使用我完整版本的提示词(包括布局,配色,图表样式,细节的排布等等),对一篇过往的Deep Research报告进行可视化。
Claude-4 Opus版本结果如下:
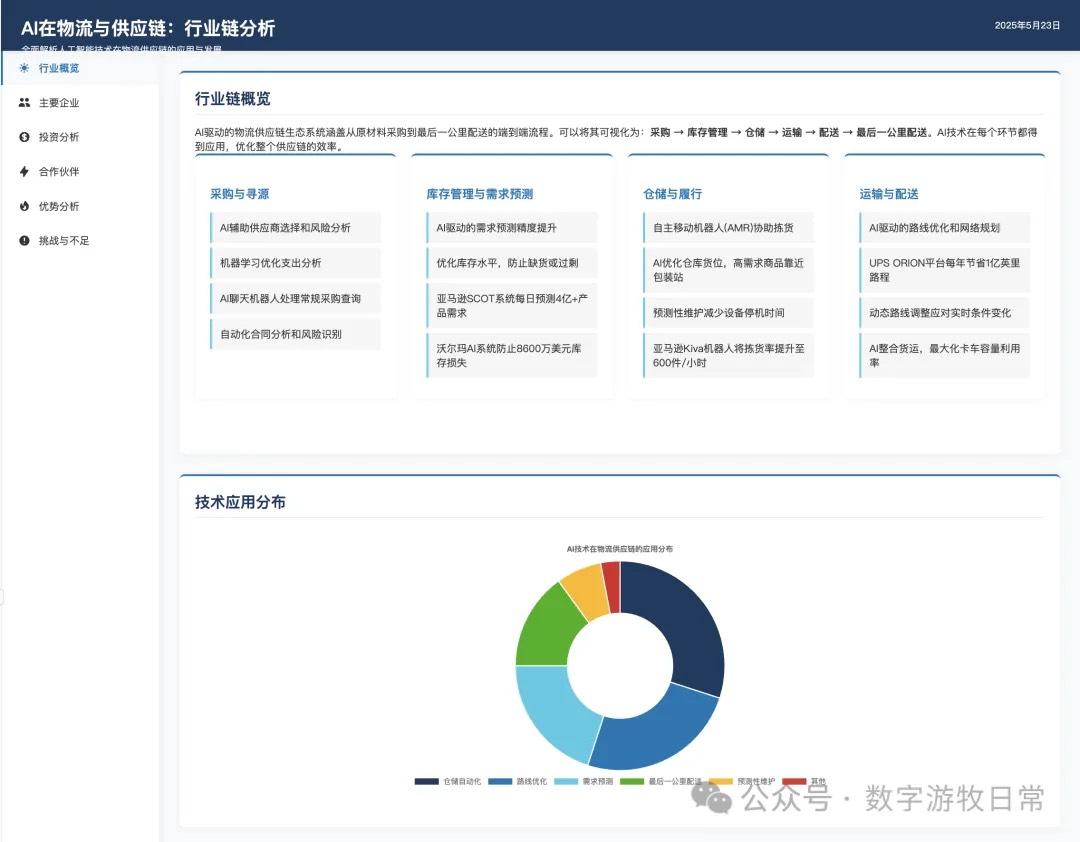
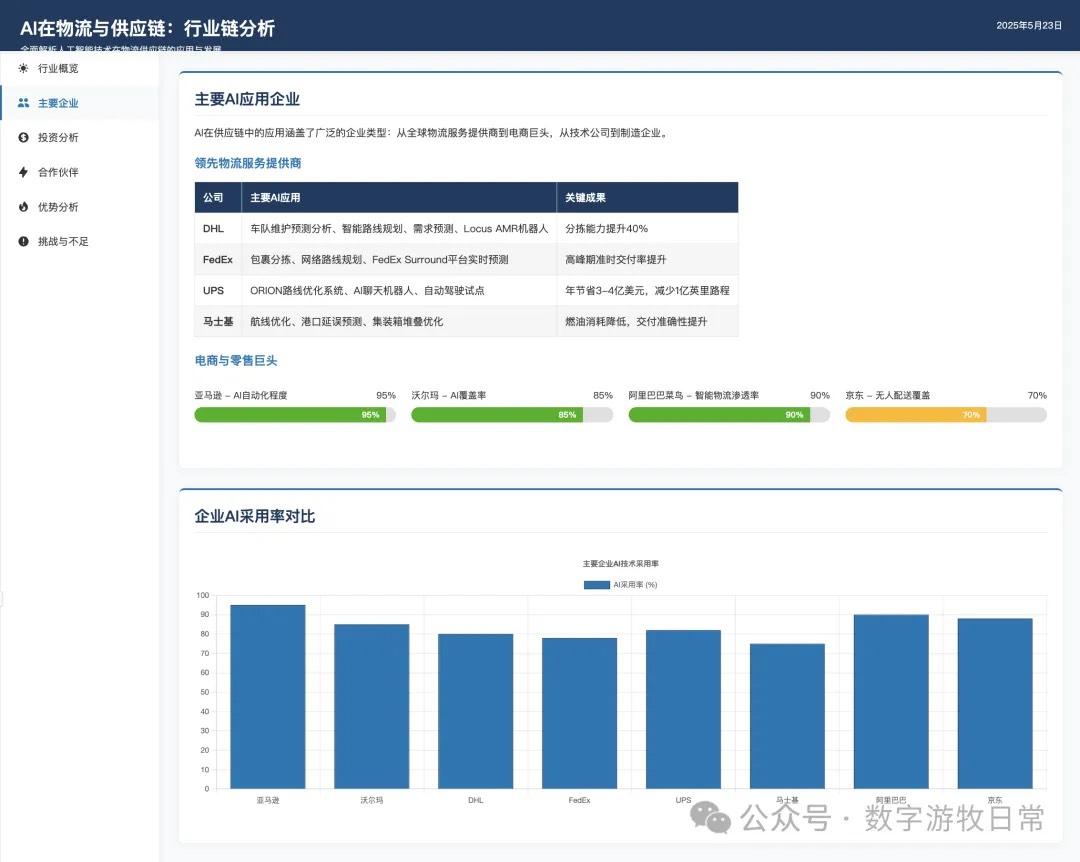
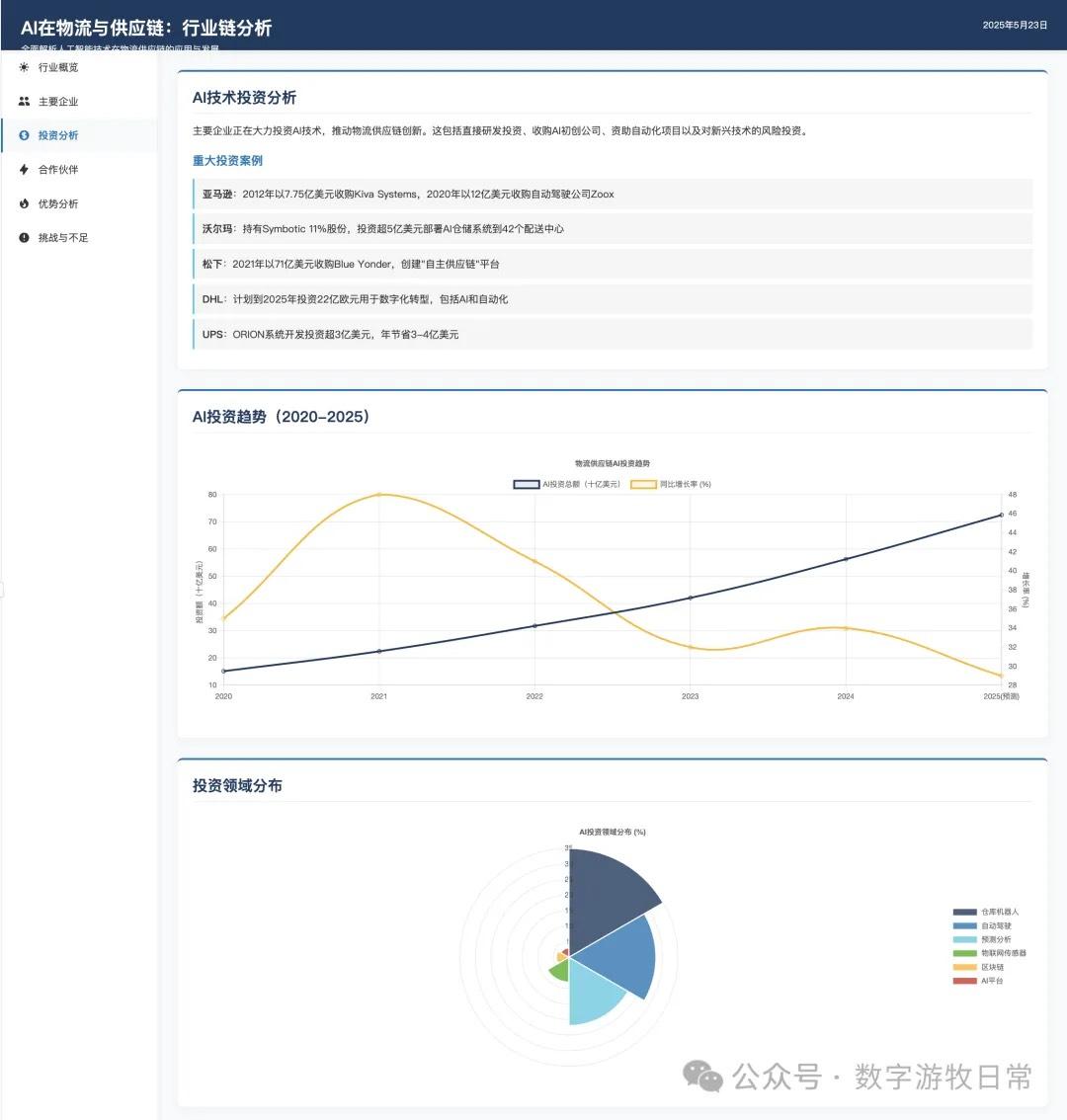

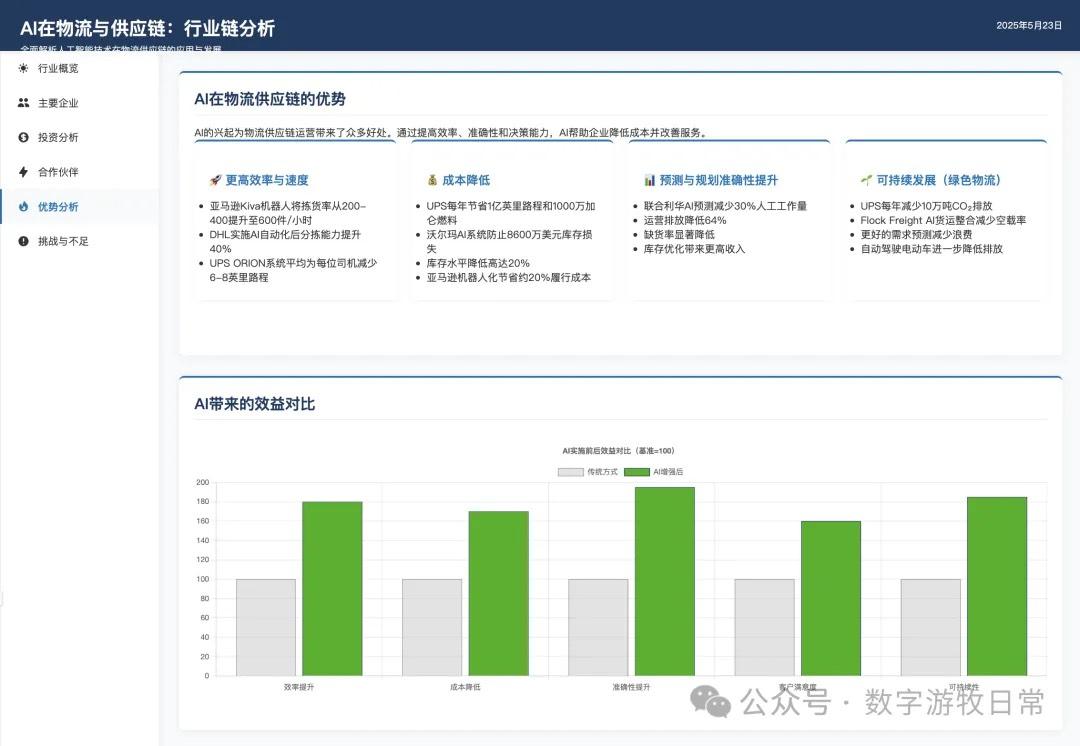
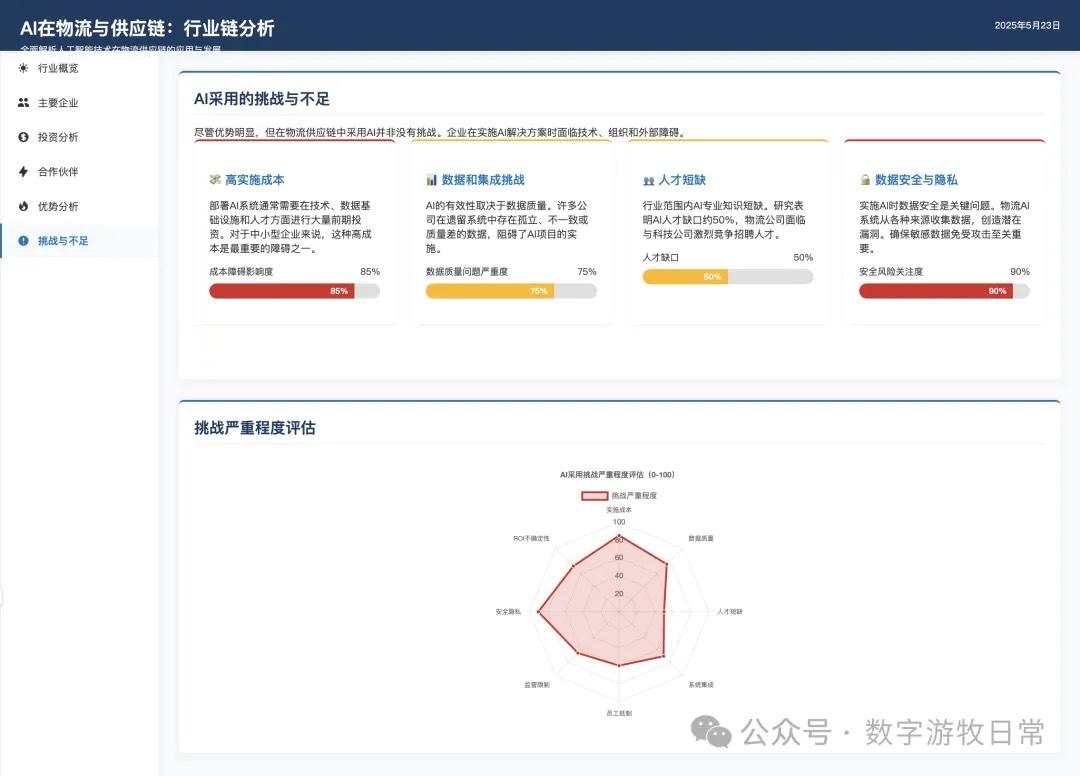
作为比较,下面是一个多月前的Claude-3.7的版本:
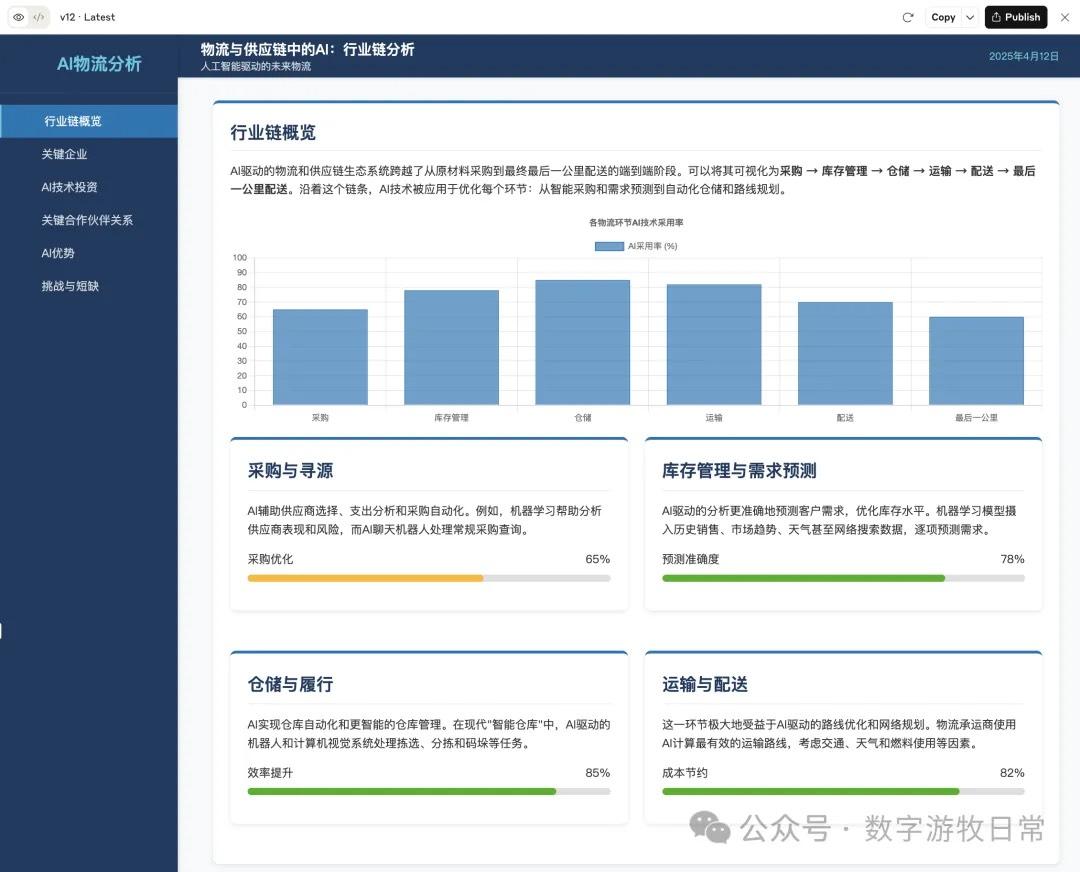
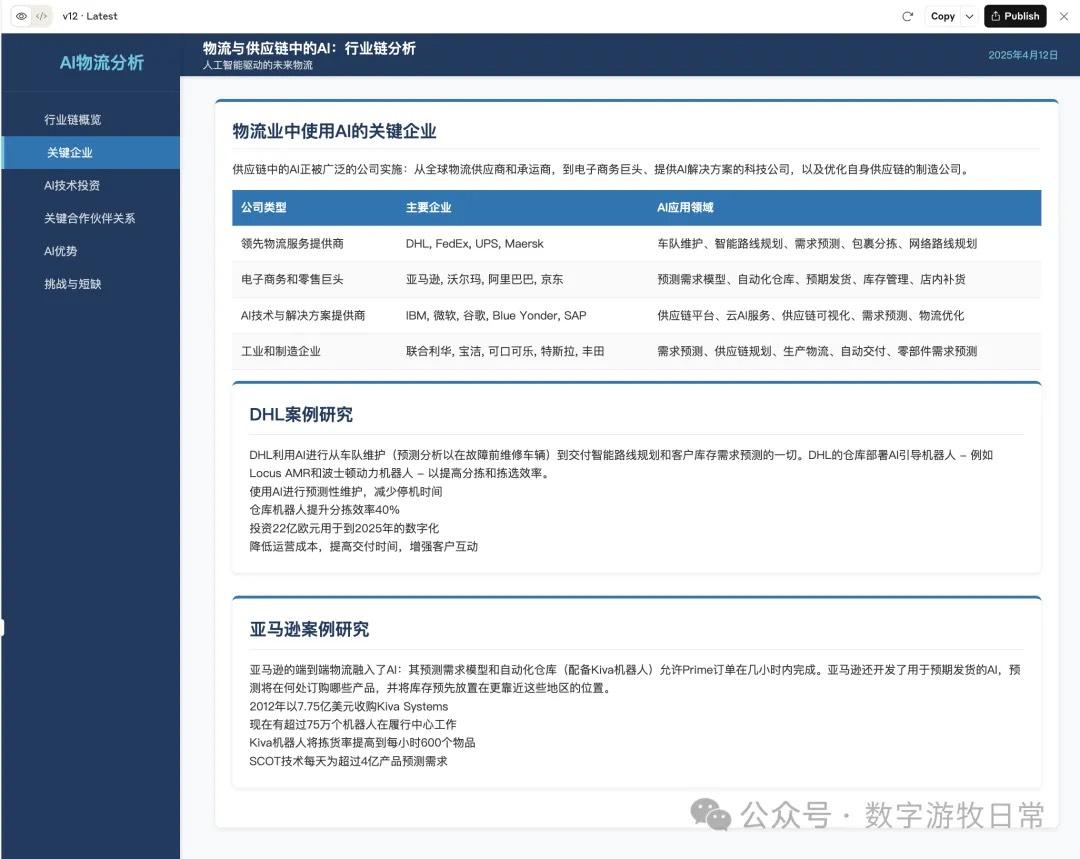
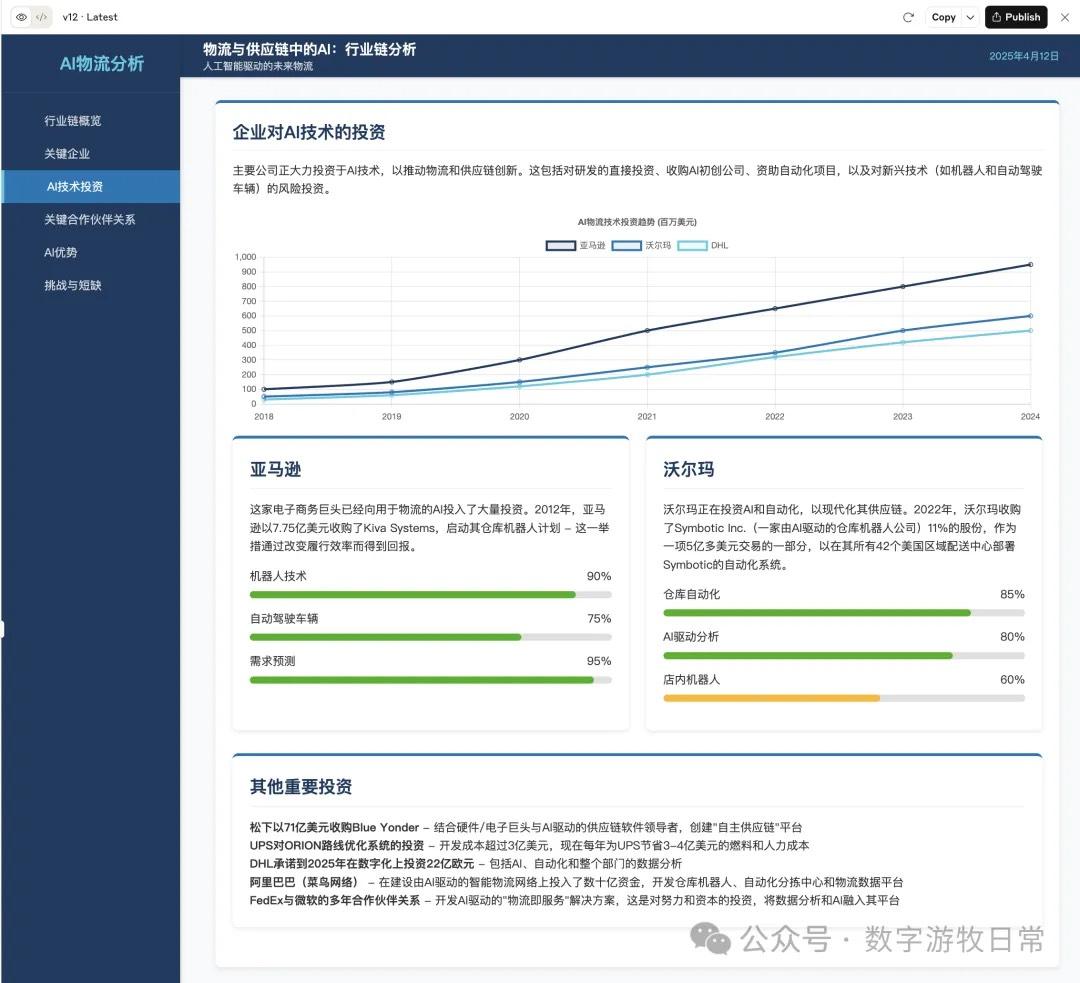



如果就这么比较的话,显然,Claude-3.7依然是更好的结果,仅仅更多细节这一条就赢了。
但是,如果我们考虑另一个维度:Claude-3.7这个版本是在模型自我进行了11次修改后得到的(请看截图左上角的“v12”字样,每一次过程中都有代码错误,然后模型会自己改代码,当然需要手动点击一下)。
而Claude-4 Opus的版本是一次生成的。
其实,这是一个巨大的区别,我相信这会对在Cursor中的Vibe Coding体验带来较大的提升。不过,这需要更长时间的体验才能得到结论。
Cursor已经加入了对Claude-4的支持,但是只有Sonnet包含在订阅用户的选择范围中,Opus需要开启“按量付费”的Max模式。
开始结论了:
1、客观而言,相比之前,Anthropic的这次发布总觉得过于简单了一些,仅仅一个页面,一段三分多钟的视频,然后有一些基本的评分信息。这不是Anthropic惯有的风格,毕竟以前模型发布时,Model Card里都会有海量的细节信息,即使这些信息不断在“缩水”,但是这一次,对于“4”这样一个重要的版本号,我没找到Model Card(我找到System Card了);
2、我理解Anthropic在力推“Code”应用,力推Max订阅,前者是可以大幅提升API调用量的,后者当然是可以从21.8美金/月提升到100美金/月。但是就这样拿出的产品能力而言,远不值这个价。Anthropic可能不仅仅是“露怯”,而是迫于压力“吃香变得难看了”;
3、从模型本身而言,Claude-4可能再次证明了一个事实:模型“撞墙”了,至少是在单一模态下;
是的,确实如前文提到的朋友发来的信息所言“Anthropic的生存空间被大幅挤压了”。
“财大气粗”的Google借助Gemini-2.5和生态能力正在展现出更多的可能性,先发优势巨大的OpenAI的ChatGPT活跃用户数还在快速增长。
更何况,通过AI-Studio,Gemini-2.5每天依然可以提供可观的“免费额度”;OpenAI的Deep Research虽然在数据及时性和搜索能力方面明显不如Gemini-2.5,但是稳定性和全面性更胜一筹;Gemini-2.5在大幅提升代码能力后,也在逐渐侵蚀Claude的API调用需求……
Anthropic掉队的概率也许比我年初的预测大幅提升了。
当然,2025年AI的世界,依然是“模型决定一切”,下面的舞台(考场),交给OpenAI了。