
我一直认为,AGI的初步大概是三个主要能力:写代码、搜索、执行。
大语言模型具备代码能力,虽然还在不断进化,但是已经具备了条件1;
无论是Gemini Deep Research还是OpenAI的Deep Research,虽然因为计算量的不同在结果的完整度上差异明显,同时在有些细节上难免出现“幻觉”,但是这基本标志着搜索能力的大幅提升,基本具备了条件2;
第三个条件,执行,当然包含的内容可以很多,但是自从Anthropic推出Computer Use,尽管很初级,但也意味着模型开始往执行环节进发,这个过程中,Google也在Gemini模型框架下有序的推出一些尝试性的功能。
OpenAI自然不会落后,前段时间推出了Operator模块(跟sora类似,有独立二级域名operator.chatgpt.com的)。今天,当我终于可以完整尝试时,还是被惊喜到了。
过程是,我让operator读QWen刚推出的2.5多模态模型的论文并摘要。这项任务当然可以通过搜索完成,但如果模型可以模仿人类的操作,意义会远超过搜索。
如上图,Operator经过了好多次的努力,因为浏览器权限和它的虚拟机配置问题,一直无法完成pdf渲染,询问我两次“是否”继续后,终于加载成功,完成了主页浏览,生成了摘要。这个摘要当然有点简略,但这很可能只是因为底层的大语言(多模态)模型参数偏小能力有限的原因(节省运行时算力)。
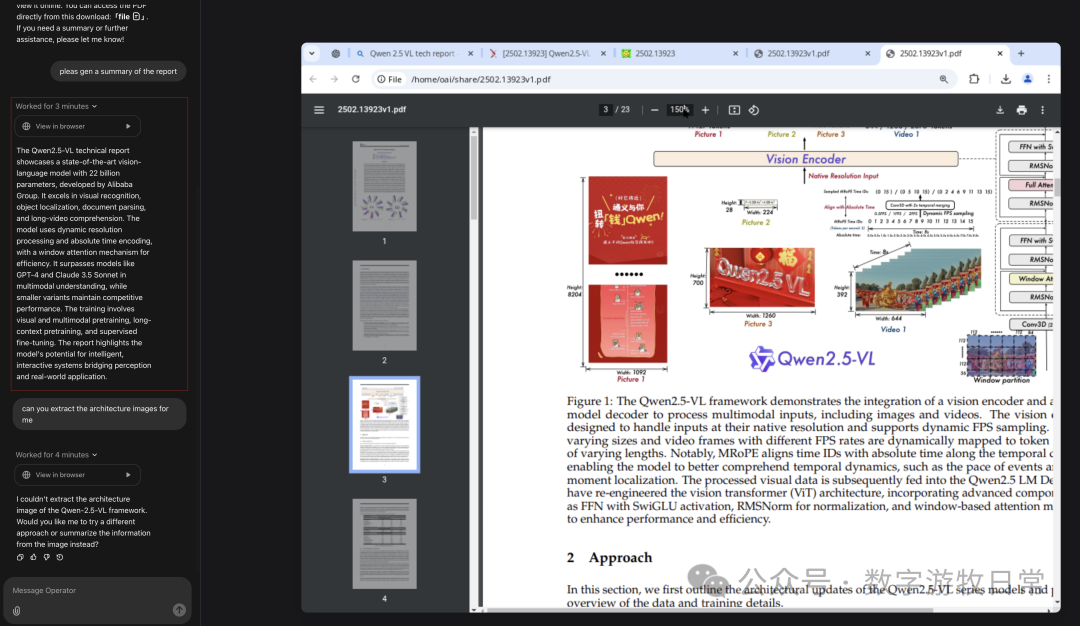
当然,我又提了新的问题,让他将模型的架构图“截取”下来。上一个问题里,它已经看到了论文最后一页,然后再一页页的回去找,终于在第二页,找到了架构图。因为缺乏工具,始终无法完成图像保存或者截屏操作。但这不是模型做不到,而是找不到工具。包括我“take control”进到虚拟机后,也找不到合适的工具去完成截图。
以我看到的过程而言,我认为模型都完成了“任务”,“执行”,即本文开头的条件3也存在了。
因为各种原因,operator的操作速度非常慢,下面的视频只是回放时对每一步的点击。
如果细看每一步思考的话,可以明显感觉到比Anthropic的computer use和rabbit的lam模型还是强很多。
如果一个模型能够根据任务选择合适的执行路径和工具,并根据环境(虚拟机环境,桌面内容)不断调整,直到完成任务。
那么,我们是否可以说,其实它已经开始接近AGI了?
我认为可以了。虽然还有持久记忆等问题依然横亘在前进的道路上,但可以有充分的理由相信,OpenAI内部很可能可以拿出比这个operator version强很多的版本(更大的算力支持下的更大的多模态模型,虚拟机里预装一堆工具)。
缺的只是算力,便宜的模型推理算力,和“学习”更多场景数据的算力。
也缺脱离“虚拟机”进入“real world”的环境。
当然可以有一个超级应用根据用户指令自动“操作”手机,但是能够将它做到最极致体验的只能是手机操作系统的开发商。
当然也可以把这个模型装入机器人中,让机器人具备更强的“执行力”,但是缺的同样是算力,更高的算力,但是更低的能耗。