哪些大语言模型能分清“9.9”和“9.11”的大小?
请问,哪些大语言模型可以回答对“9.9更大,还是9.11更大”这个问题?
答案是:o1推出以后的GPT-4o,Gemini-Thinking推出后的Gemini,Deepseek-V3和R1,Qwen2.5,可能还有一些其它的。
哪些模型回答错误?
去年上半年的GPT-4o和Gemini,Llama-3,还有最新推出的“地表最强”:Grok-3,可能还有一些其它的。
那么换一个问题:“9.90更大,还是9.11更大?”。上面提到的模型基本都能回答正确了。
原因在哪里?
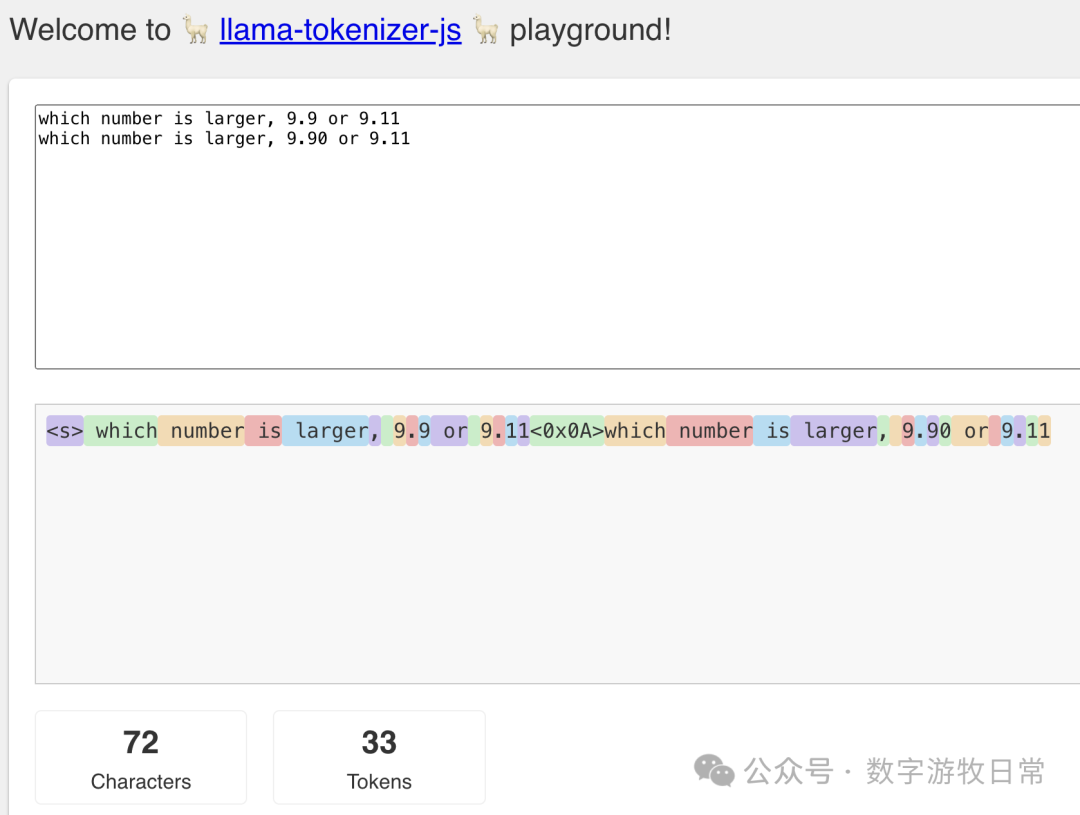
大语言模型的基本原理就是预测下一词(token)。通过tokenizer的可视化结果,我们可以清晰地看到:每个数字和字符都占据一个token,所以9.9是三个token:‘9’,‘.’,‘9’。
虽然“9.11”变成了四个token,但是目前的预训练使得模型在‘.’的前后进行了截断。模型将问题“理解”成了分别比较‘.’前的‘9’和‘9’以及‘.’后的‘9’和‘11’,所以如果不加纠正,结果就是“9.11 > 9.9”。至于只是“概率”的模型为什么知道要比较整数和小数,为什么知道小数部分的两个‘1’要合起来,这就是多头机制——当你匹配了问题里“number”,“larger”以及数字后,用来训练的数据的概率分布结果就让你吐出的下一个token都只想比较大小。
本来这个问题在2023年ChatGPT刚出来时其实就很清楚了。但是“碾压”GPT的DeepSeek横空出世,又让人怀疑这个问题了。
其实,要解决这个问题也挺简单。正如我开头说的,让模型去比较“9.90”和“9.11”,或者通过提示词让模型先把小数部分的数字对齐到同样的“百分位”。(参考之前的文章:DeepSeek的深度研究(1):经典案例测试说明"砸基础模型更重要")
所以,提示词的目的就是让模型结果的分布对用户想要的结果“有利”。
当然,除了通过提示词,还可以通过RLHF(人类反馈强化学习),如今还可以通过类似R1的“强化学习 + SFT”得到的“思考能力”来“规范”大语言模型的输出,做对类似于上面的问题。
深度解析模型表现差异:
- 为什么GPT-4o之前错了? 因为没有对类似问题进行强化训练;
- 为什么o1对了? 因为o1训练过程中“教会”了模型分布计算,“对齐到百分位”;
- 为什么现在GPT-4o又对了? 因为在o1出来之后,会不断用基于o1模型的输出结果作为数据再去“强化”GPT-4o;
- 为什么Grok-3错了? 与之前的4o同一个道理;
- 为什么没有思考模型的V3和Qwen也正确? 跟现在的4o一个道理;
- 为什么R1是对的?为什么Llama原来错,经过R1蒸馏后就对了? 跟o1同样的道理。
据说,Grok-3的思考模型(Reasoning model)的表现是正确的。
关于“大模型边界”的争论
过去二十四个小时,最多的评论是两条:
- 多几百倍成本,提高了30%;
- 大模型边界到了。
显然,都不对。
在一门考试中,考前突击一下可能能得到80分,但是要拿95+,也许需要花费几十倍的时间,但没有人会说“才多考了20%”。Grok-3充其量是摸到了现有文本数据的边界。
“AI”可能是最近这些年最具误导性的词。一说“智能”,就让我们对模型充满了各种不切实际的想象。事实上,Transformer就是一个压缩器,无论模态是文本、图像、声音还是视频。在当前阶段,算法优化的核心就是如何更高效、更准确地压缩和还原模型被训练到的数据(知识)。
提示词、RLHF、甚至“思考模型”研究的都是如何让压缩器沿着某条有效的路径(一个一个token输出),最终得到我们要的答案。
至于模型真的“理解”它的输出吗?按照我们人类对“理解”的定义,答案通常是“否”。我们可以将模型的输出错误都认为是某种“幻觉”。产生幻觉的主要原因是:1. 没训练过相关知识;2. 训练数据有误;3. 干扰项太多,概率接近的选项太多。
从文本到多模态
模型一次能够处理的信息量有限,超出这个限度,犯错的概率就大幅增加。文字信息的“幻觉”不容易被发现,而图像和视频的“幻觉”几乎一眼就能看出来。对于Sora这样的视频工具,通过给予更多细节可以显著降低“幻觉”。但Sora预训练时既不可能穷尽现有视频,也不可能存储每个像素,因此在大场景下的细节和物体运动中自然会产生“幻觉”。
解决运动物体的“幻觉”可能需要其他方法,但对于细节,投喂更多数据、提高预训练分辨率是确定的解决方案。
结论: 大模型的方向是多模态。即使“纯语言”可能碰到边界了,图像、视频、音频、空间数据还远未到极限。此外,模型真的耗尽数据了吗?
DeepSeek-V3的技术报告显示,它用到了大量基于V2-R1模型思考过程的数据进行训练。同时,V3和R1的训练还大量用到了数学、物理、程序方面的高质量“生成”数据。就算是本文开篇的问题,也是靠这种“生成”数据的加成才回答正确的。甚至可以说,思维链(CoT)数据通过激发基础模型中已经“压缩”的庞大知识潜力,发挥了巨大作用。
所有的评分榜都只能作为参考,没有一个榜单可以完整评价模型能力。Grok-3的表现一点都不代表Scaling Law(规模法则)的失效。我们对xAI的数据中心使用情况、Grok-3的具体模型架构(Dense还是MoE)等知之甚少。
我想,人类的进步就是一步又一步沿着Scaling Law走过来的。在证明“超越人类智能的模型永远不会出现”之前,数据和算力永远都不会“够”。
参考资料:
- 辛顿的观点(公众号:道明实验室)
- AI之父辛顿最新演讲:数字智能将战胜生物智能