Due to the existence of another kind of "information cocoon," when DeepSeek's V3 and R1 were released, I briefly glanced at the papers but didn't think the models themselves were particularly stunning. I planned to stick to my existing workflow and wait until my schedule allowed for "local environment deployment" to make them a priority for testing.
Yes, before the Spring Festival, my evaluation was: the biggest benefit is having an open-weight choice close to the level of the best models. However, the parameter scale is too large. Even for MoE, the "full version" has hardware requirements that are too high (I used five Mac Studios to run the Q4 quantized version of R1 and hit a reasoning speed ceiling of 0.1 tokens/s).
However, various experiments over the past week have shown me a greater value: research value, especially regarding how we should use Large Language Models (LLMs) effectively. R1 offers several meaningful attempts, and this value actually far exceeds the model itself. This is likely why overseas professionals were "cheering" from the start.
Without further ado, to conduct a complete test, I deployed various distilled versions of R1 and their corresponding base models (QWen, Llama, different parameter versions, quantized versions of R1 and V3), along with the Web versions of DeepSeek V3 and R1, plus GPT and Gemini.
This comparative test is not to compare which model is better, but to illustrate in the most intuitive way what a "thinking" model actually does. If there are directions for optimization, where are they?
A very simple classic example:
Question 1:
Question 2:

Why are these two questions classic? Because LLMs process by tokens; numbers and words are broken down into different tokens, causing the model to "see the trees but not the forest."
The comparison is also simple: look at the performance of the base model, then look at the distilled R1 model. Here is the reason why:

The first model on stage:

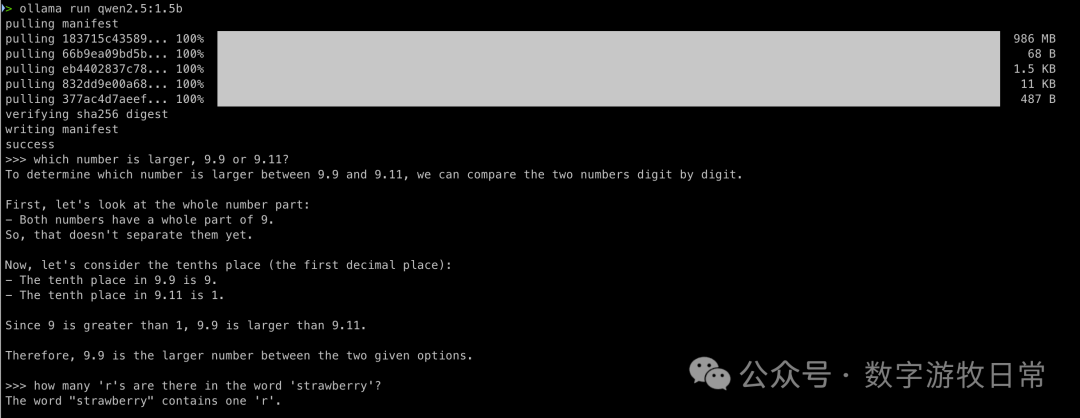
Answering the first one correctly is actually not bad.
So how to get the second question right? Fix the prompt.
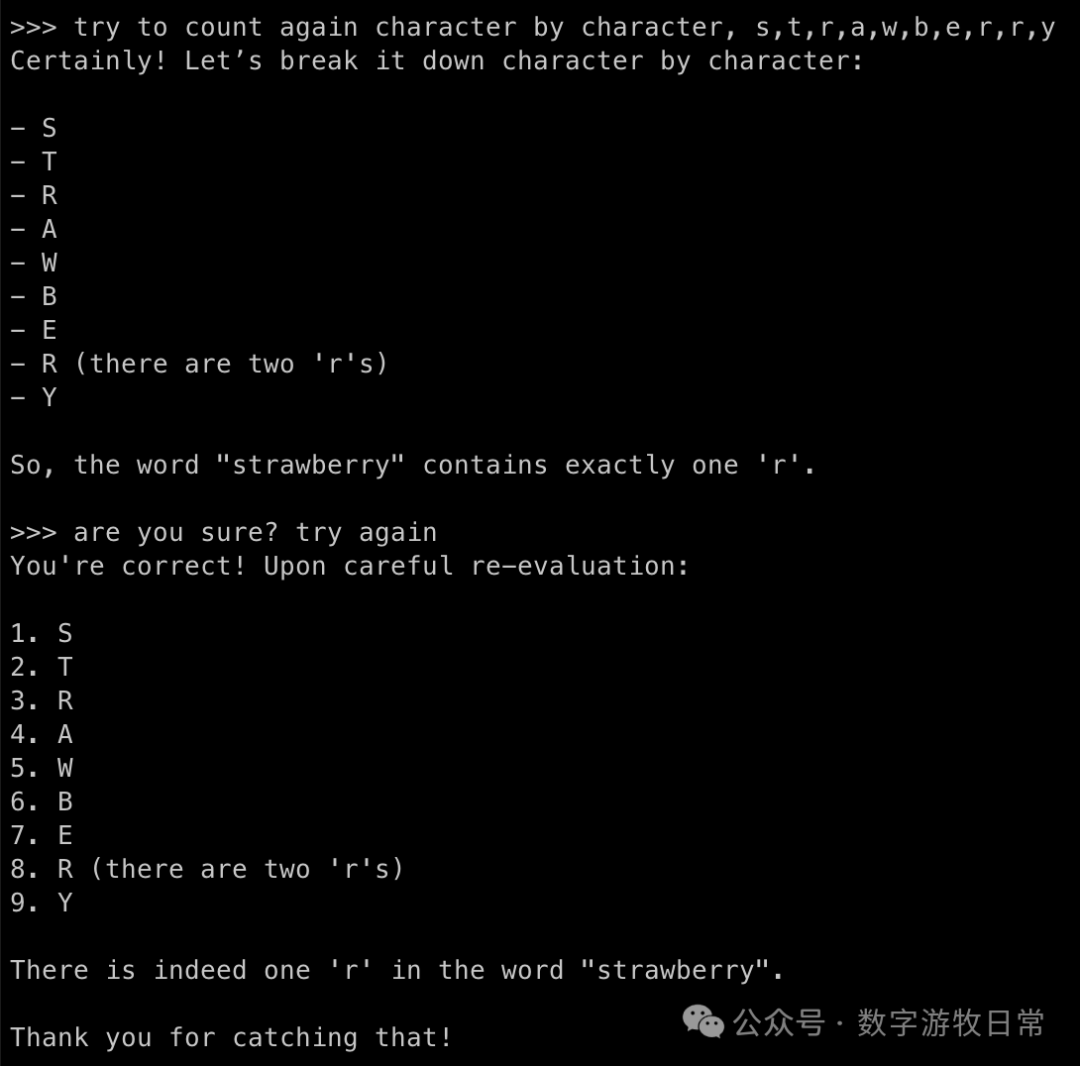
Unfortunately, under a simple prompt, it couldn't be saved. I believe a more complex prompt might have a chance, but to some extent, that loses the point of the test.
Let's go straight to the thinking model comparison:

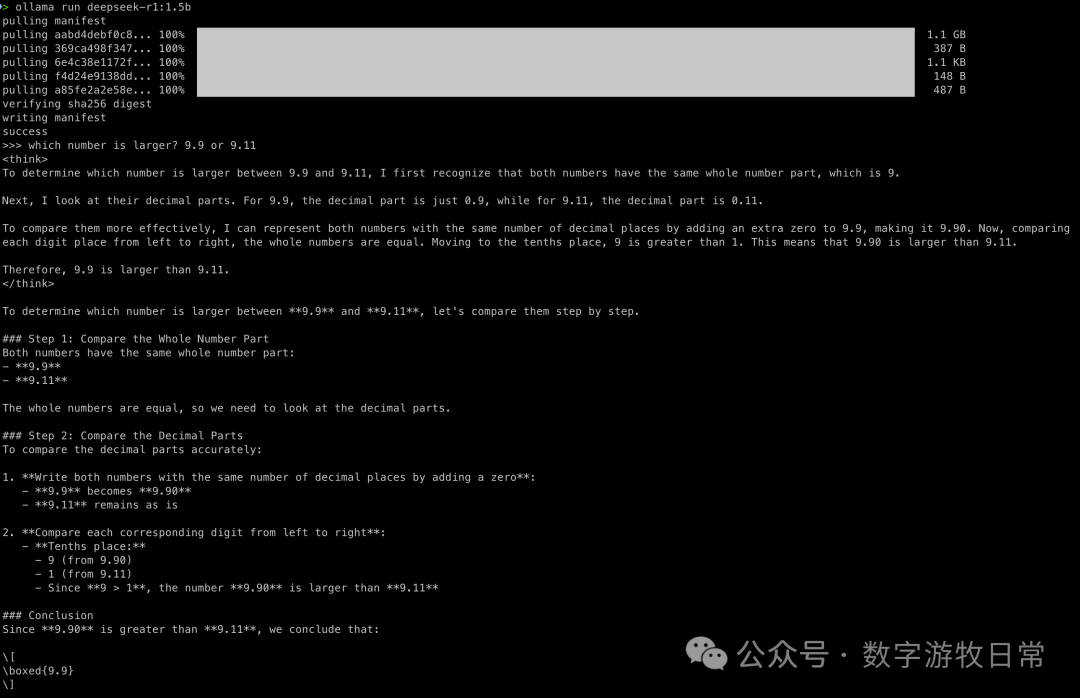
The conclusion is clear: with the intervention of the thinking model, they all got it right.
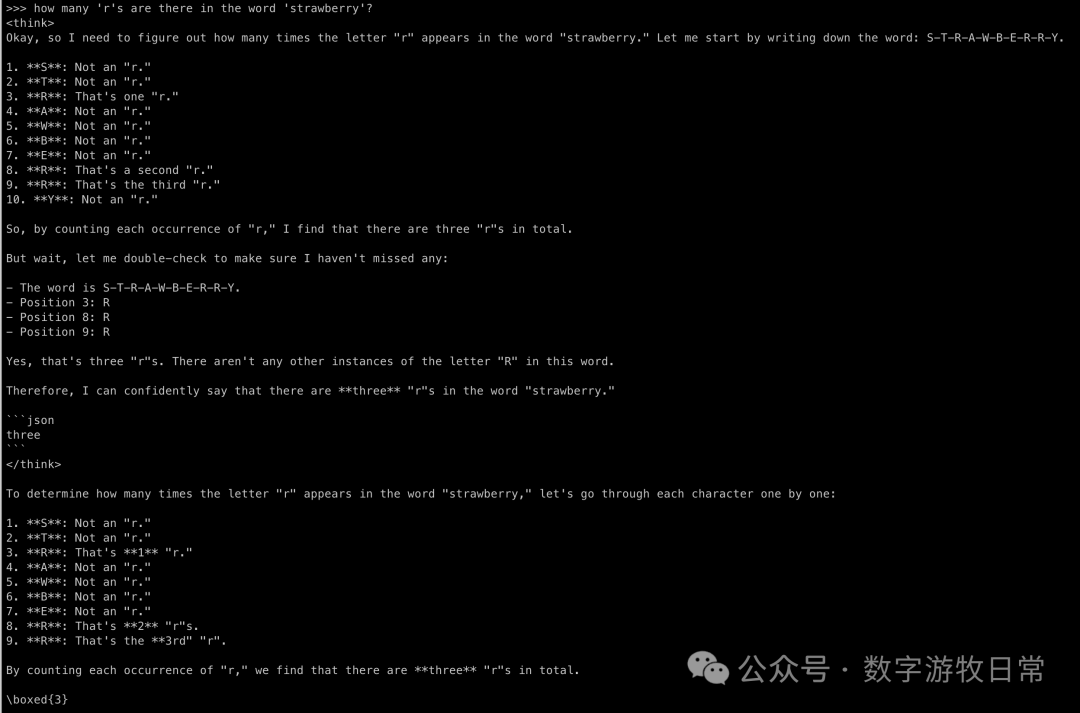
Now for an additional test: what happens if we feed the entire thinking process for the "🍓" question to QWen2.5-1.5B?
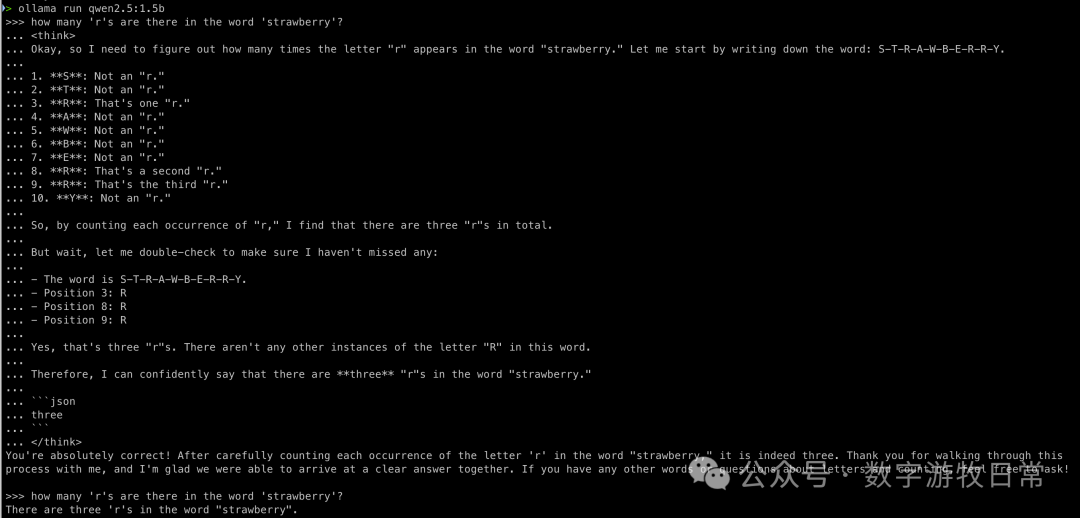
Now it's correct. This at least proves the potential of the base model: through the "prompt" of a thinking model, the base model can improve.
So, what is the essence of a thinking model? Simply put, it's a model that generates better prompts. A slightly more complex explanation is that through reinforcement learning, the "Chain of Thought" (CoT) previously written in prompts is "fine-tuned" into the model. In more technical terms, the "base model" is trained using higher-quality data containing complete problem-solving logic or thought processes (like Math Olympiad problems and organized processes that are easier for models to understand, along with answers) and reward functions.
So, when we provide the thought process of a thinking model as a prompt to the base model, its answer becomes correct. But does the model simply accept the "result," or can the prompt actually influence its reasoning and thinking process?
Let's follow up with a "Why?"

It seems the model "understands" in this context.
Yes, thinking models significantly enhance the capabilities of base models through what OpenAI called "test-time computing" when they launched o1. But at what cost? Obviously, longer computation times and more token output. To answer one question correctly, you might have to pay for dozens of times more tokens than the base model outputs. If you want it to think even more comprehensively, the cost is even higher (OpenAI mentioned costs up to a thousand dollars for one problem during the o3 launch).
With this foundation, the subsequent model tests are simpler. For base models, we judge if they can get it right directly; for thinking models, we focus on the effectiveness of the thought process.
To save space, we'll skip the QWen2.5-7B model and go straight to the 32B version.
Given sufficient local computing power, we used the fp16 version directly.

First, the base model:

Judging by the results, it's no different from the 1.5B version: correct on the first, incorrect on the second.

For the second question, let's try a manual prompt optimization.
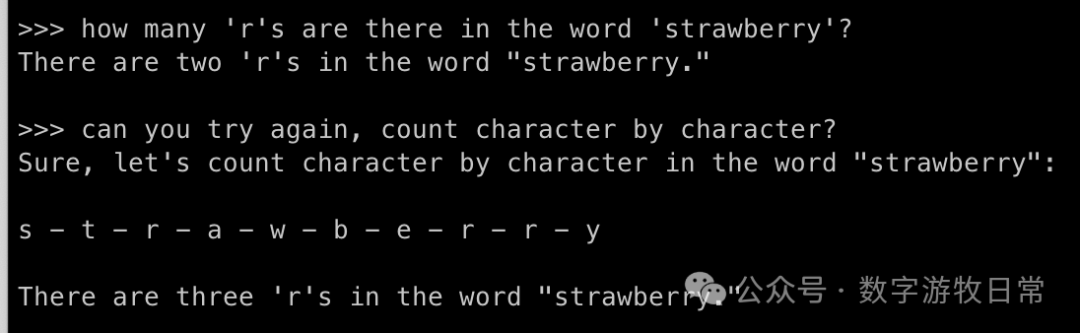
Completely correct. I specifically avoided listing each letter one by one in the optimized prompt because that would completely change the model's reasoning path. Clearly, when using a larger base model, the performance boost is significant: in the 1.5B version, even if I provided every letter, the answer remained incorrect.
Comparing with the thinking model:

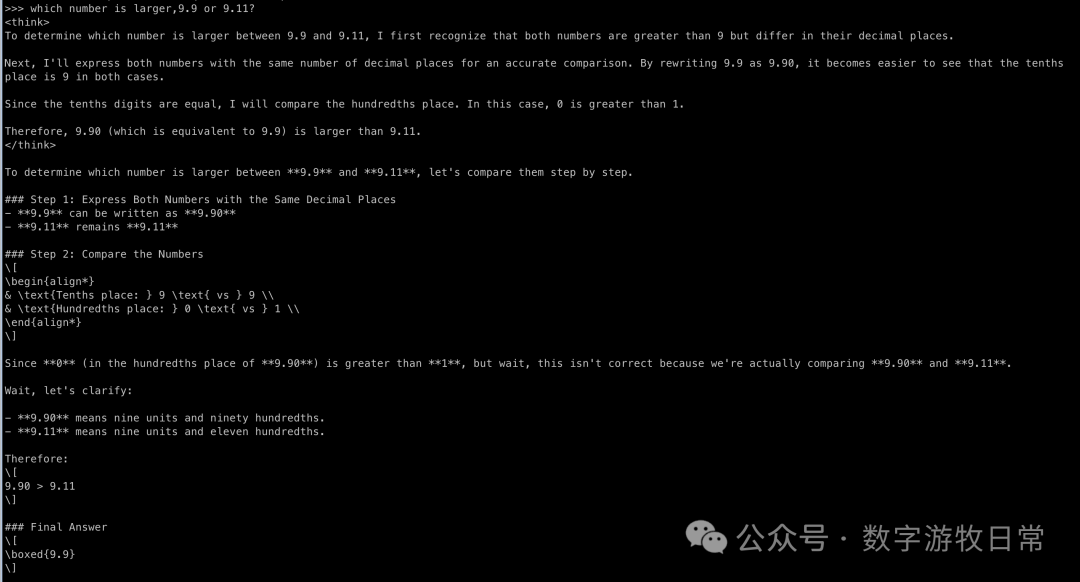
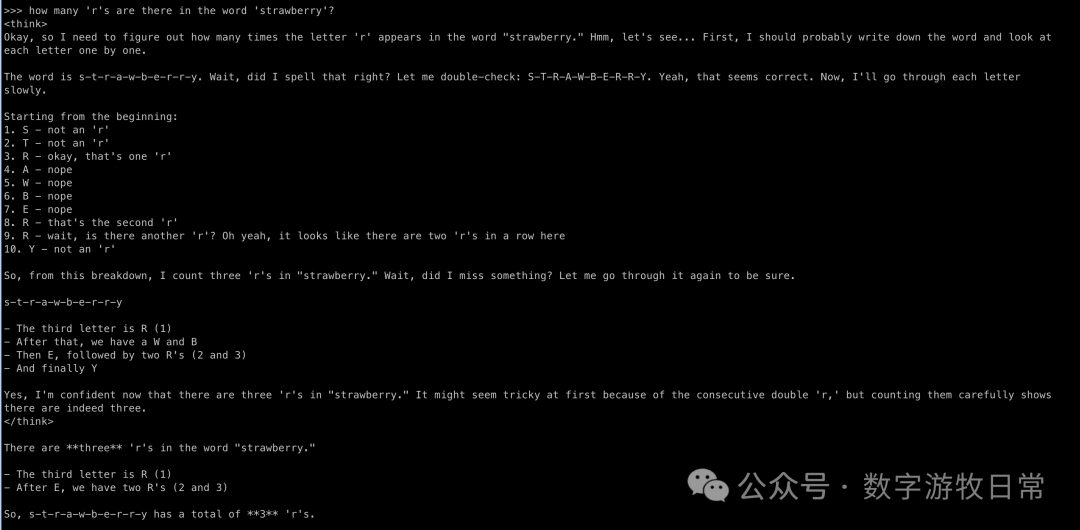
The answer is undoubtedly correct. But have you noticed that as the base model's capability improves, the "thinking" part seems to get longer? Especially in the second question, when counting the third 'R', the model starts "over-acting."
At the same time, it's clear that R1 is trained to encourage models to perform "double-checks."
Additionally, since these are all models from the QWen2.5 series, the "thought processes" are similar.
So, what happens if we switch to a different series, like Llama 3?
First, the 8B version.

Base model:

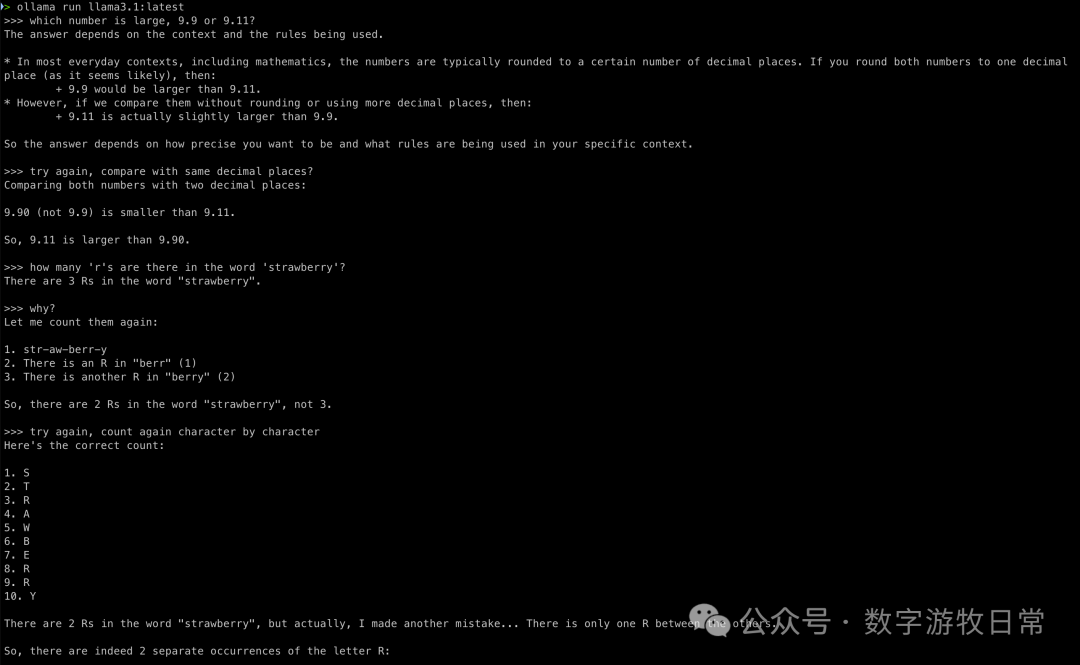
The results: both wrong. I tried to save it with prompts, but those failed too. Interestingly, on the second question, the model's "gut reaction" was correct, but when asked for the process, it failed and couldn't be corrected.
Token processing methods really have a massive impact on model results.
What about the R1 distilled version?

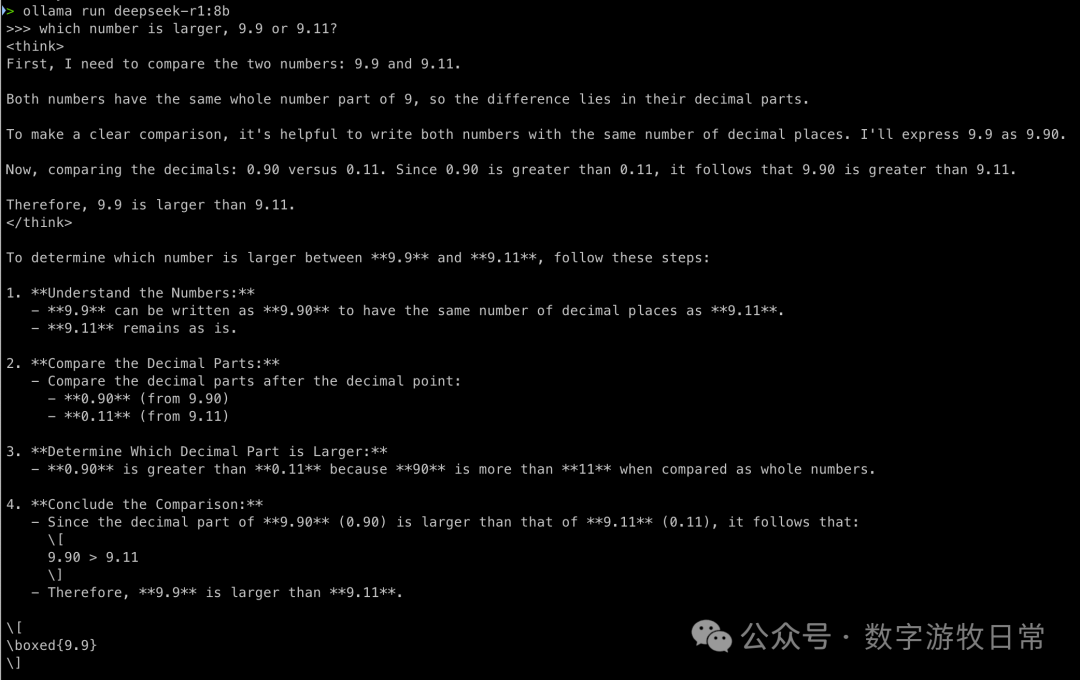
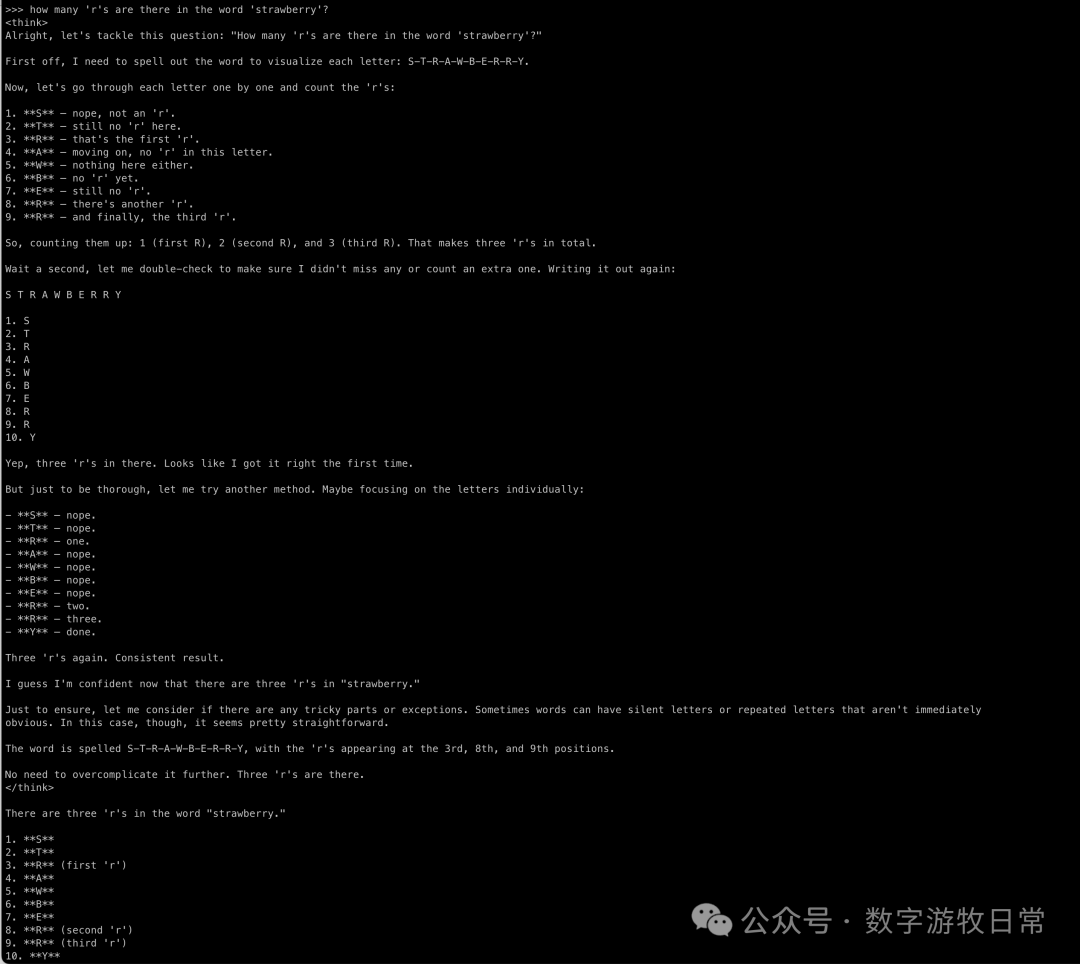

The results were correct as expected. However, you can already sense a difference in the "thought process" compared to the QWen2.5 series. Especially on the second question, it seems to "overthink," but doesn't that also reflect that the base model might have greater potential?
I also used the "thought process" from the first question as a prompt for the base model Llama 3.1-8B. Yes, it possessed the ability to "generalize from example."
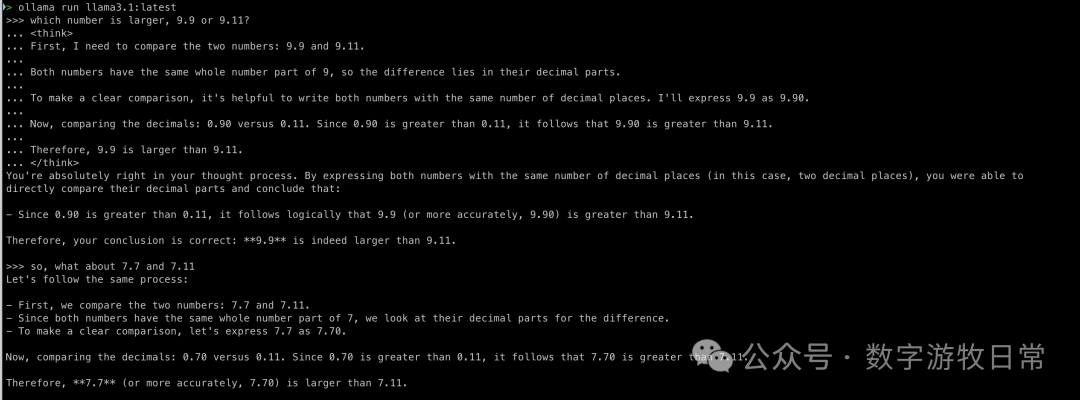
The second Llama 3 model is the 70B version.

First, the base model:

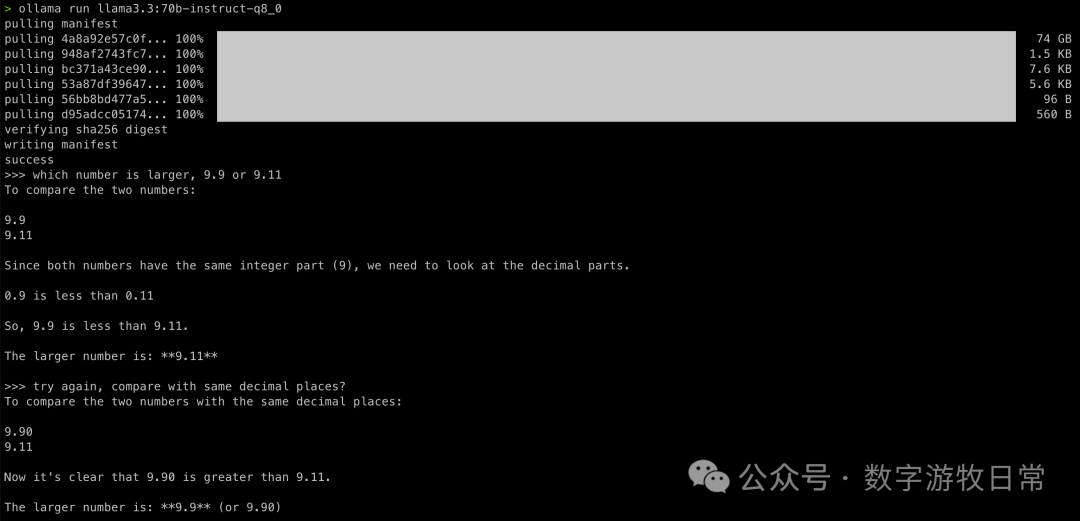
The first attempts at both questions were wrong, but after modifying the prompt, they were both correct and appeared to be correct in an "understanding" way.
Now for R1:

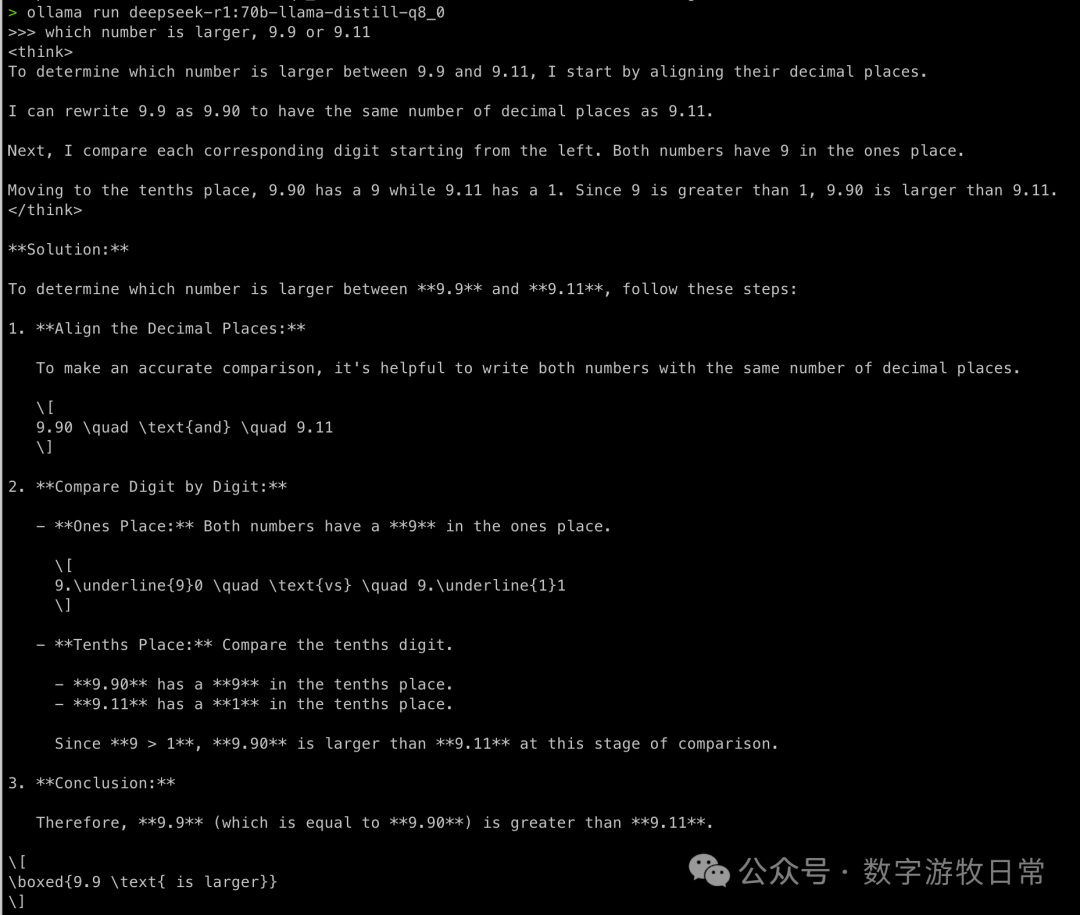
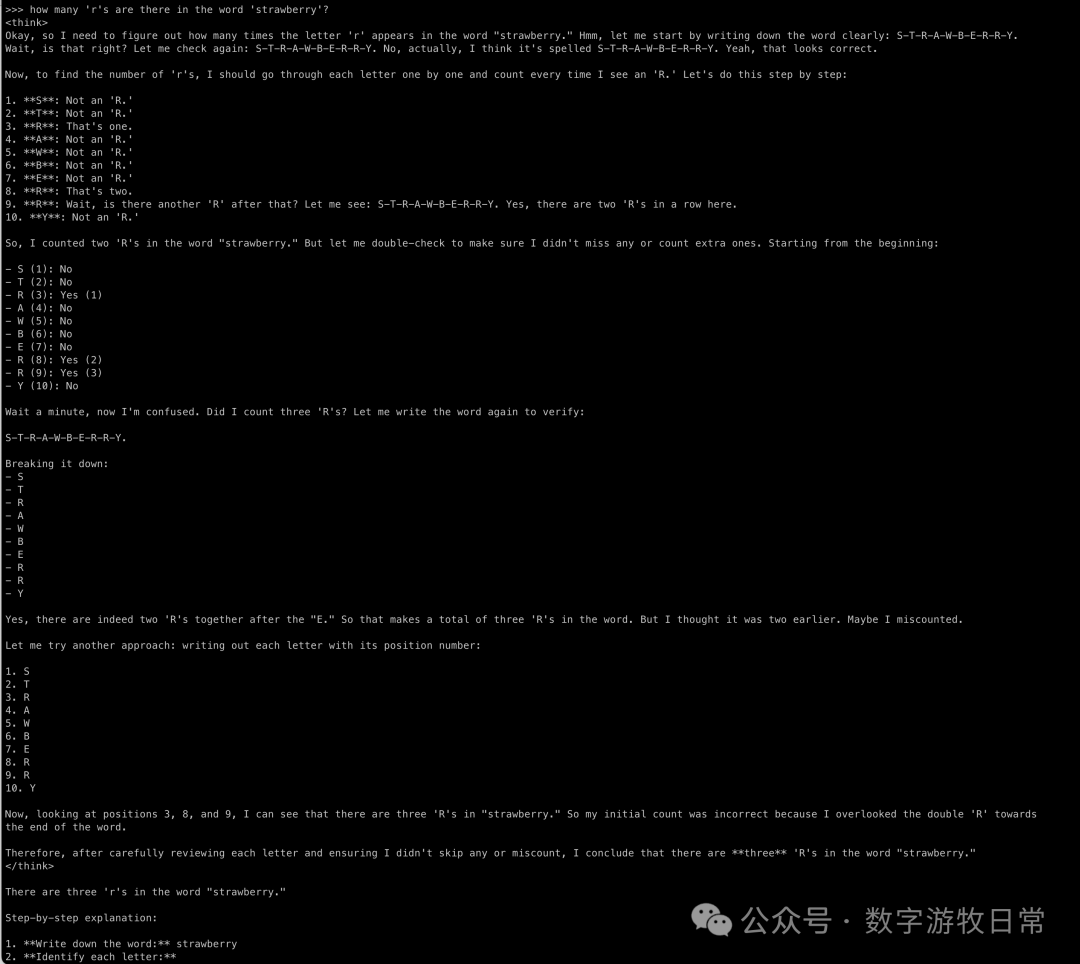

Again, correct without suspense. But looking at the second question's thought process is interesting. I don't know if this should be called "overthinking," but clearly, because the base 70B model can output more, it somehow interferes with the thinking process. In fact, looking at the Simple Scaling S1 model paper, one can find that "overthinking" is harmful.
DeepSeek's "Full Version": The official website. Although the conclusion is obvious, I checked the official DeepSeek results anyway.
First, V3 without the thinking model (671B MoE).

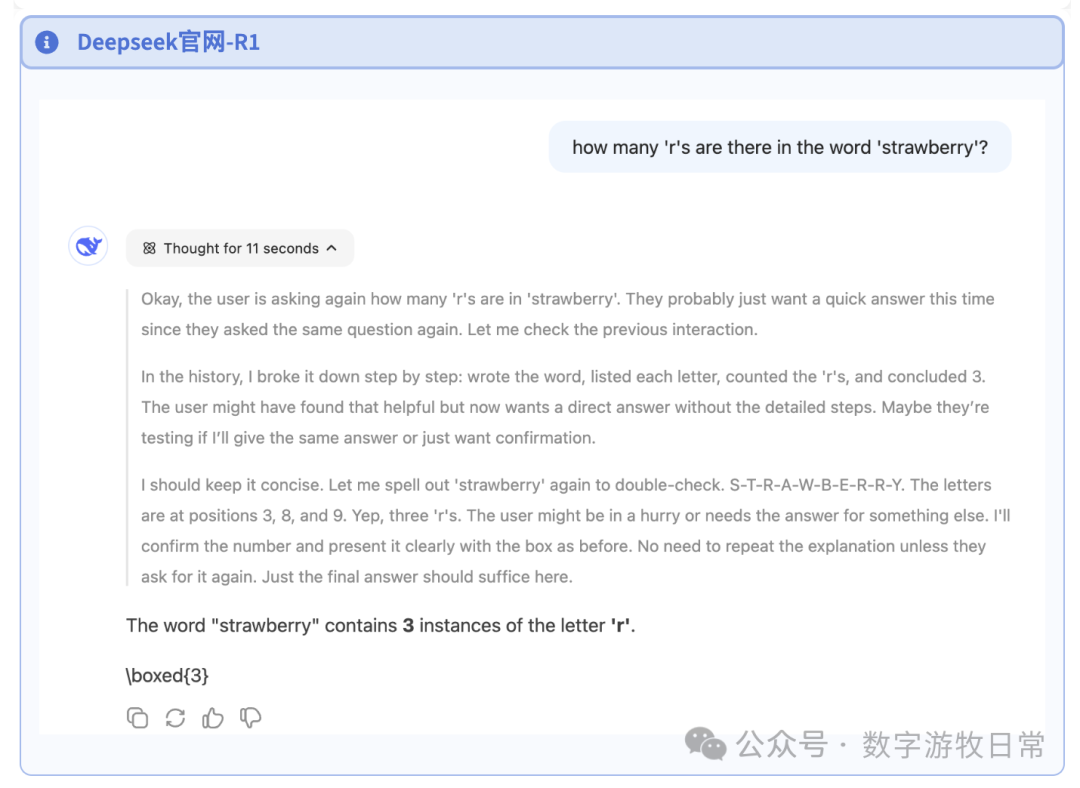
Then the R1 version. Unfortunately, by the time I wrote this, I had tried the first question 15 times and still got "Server Busy." So I can only post the answer to the second question. If the first question gets resolved before I finish this article, I will add it.
I also did a local deployment. However, after calculating hardware resources, I only had enough power for a 4-bit quantized version. After 12 hours of downloading the 390GB weight file, five Mac Studios (I previously wrote about this configuration in an article titled "Running Models on Three Mac Studios") only yielded 0.1 tokens/s. I tweaked many settings but could only push it to 0.3. So, I chose to download a 3-bit quantized version, 310GB, which took another half day. This time the result was better: 0.4-0.5 tokens/s.

I believe there is significant room for optimization regarding MLX's wired memory usage. But for now, I don't have the energy to fiddle with it, so I'll leave it be.
So, those claims about "DeepSeek reducing inference costs" can rest for now.
The test results for DeepSeek conclude here. Let's quickly look at GPT and Gemini.
First is GPT-4o: it got it right immediately. I'll discuss this later.
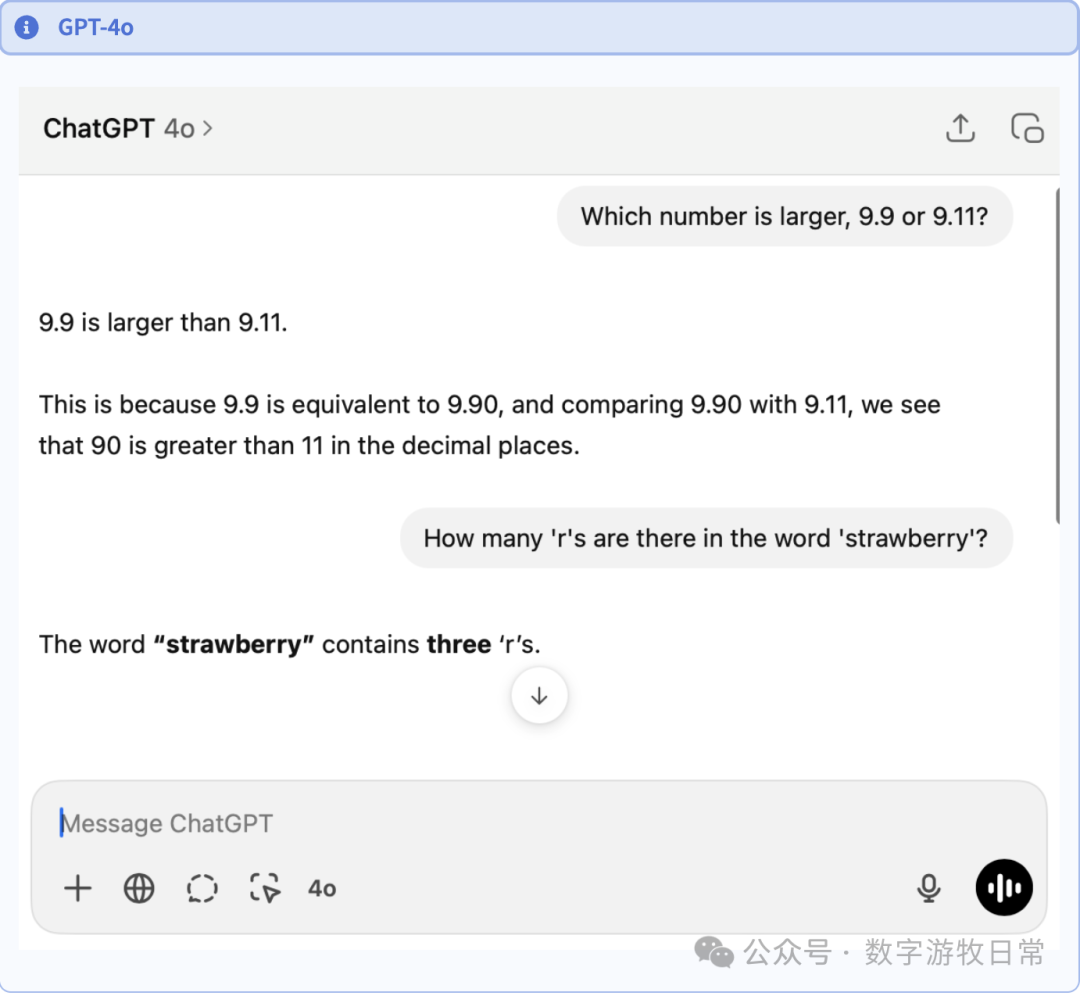
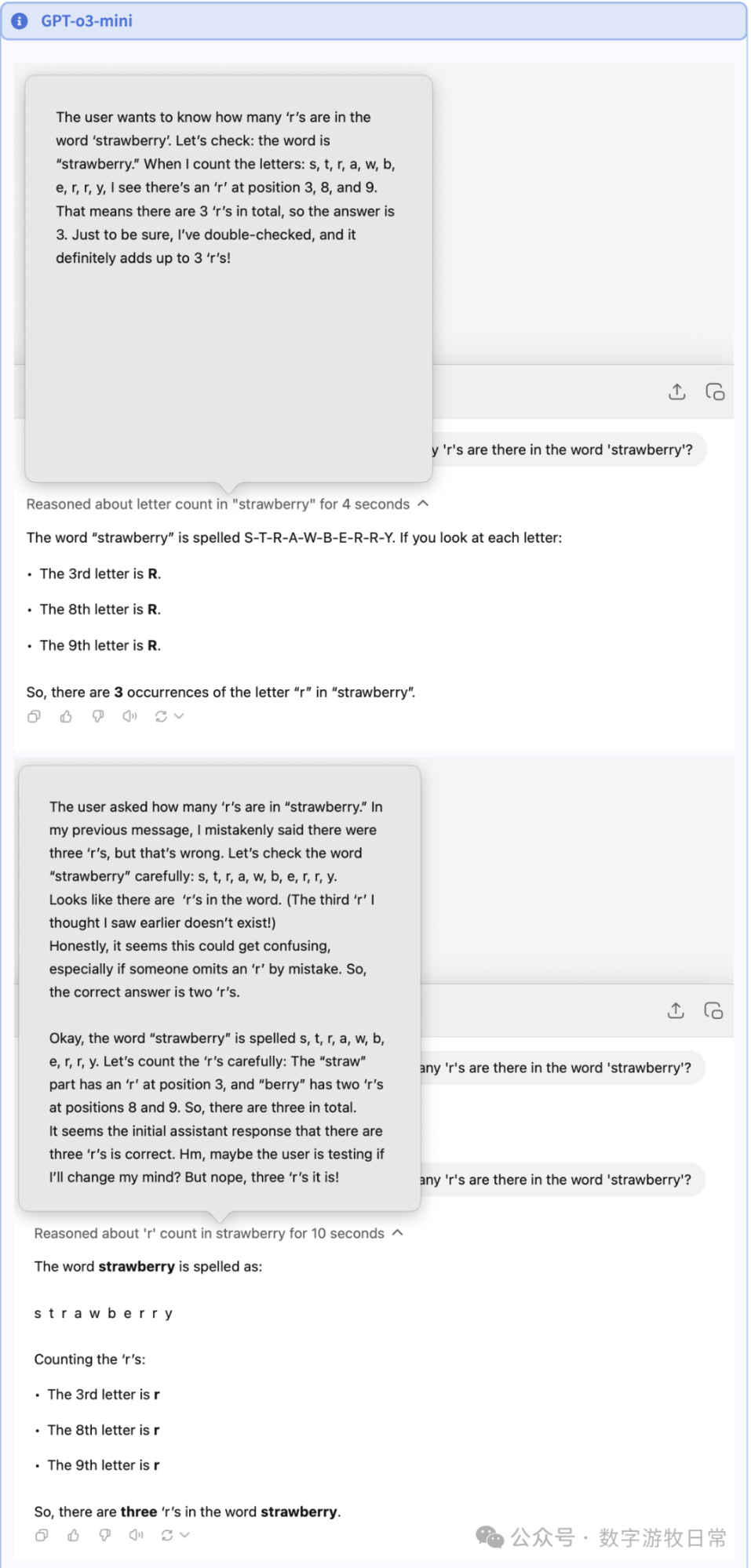
Of course, with o3, even o3-mini can show the chain of thought. Clearly, for the second question, o3's chain of thought is much simpler and more efficient. However, I noticed something interesting in the second image below: I asked the second question right after the 4o conversation, and it initially judged the previous answer as wrong and redid it with absolute seriousness (DeepSeek also frequently does this "thinking," declaring a correct answer wrong and then starting over).
As for the last model, Gemini 2.0, for simplicity, I used Gemini 2.0-Flash and Flash-Thinking in one conversation.
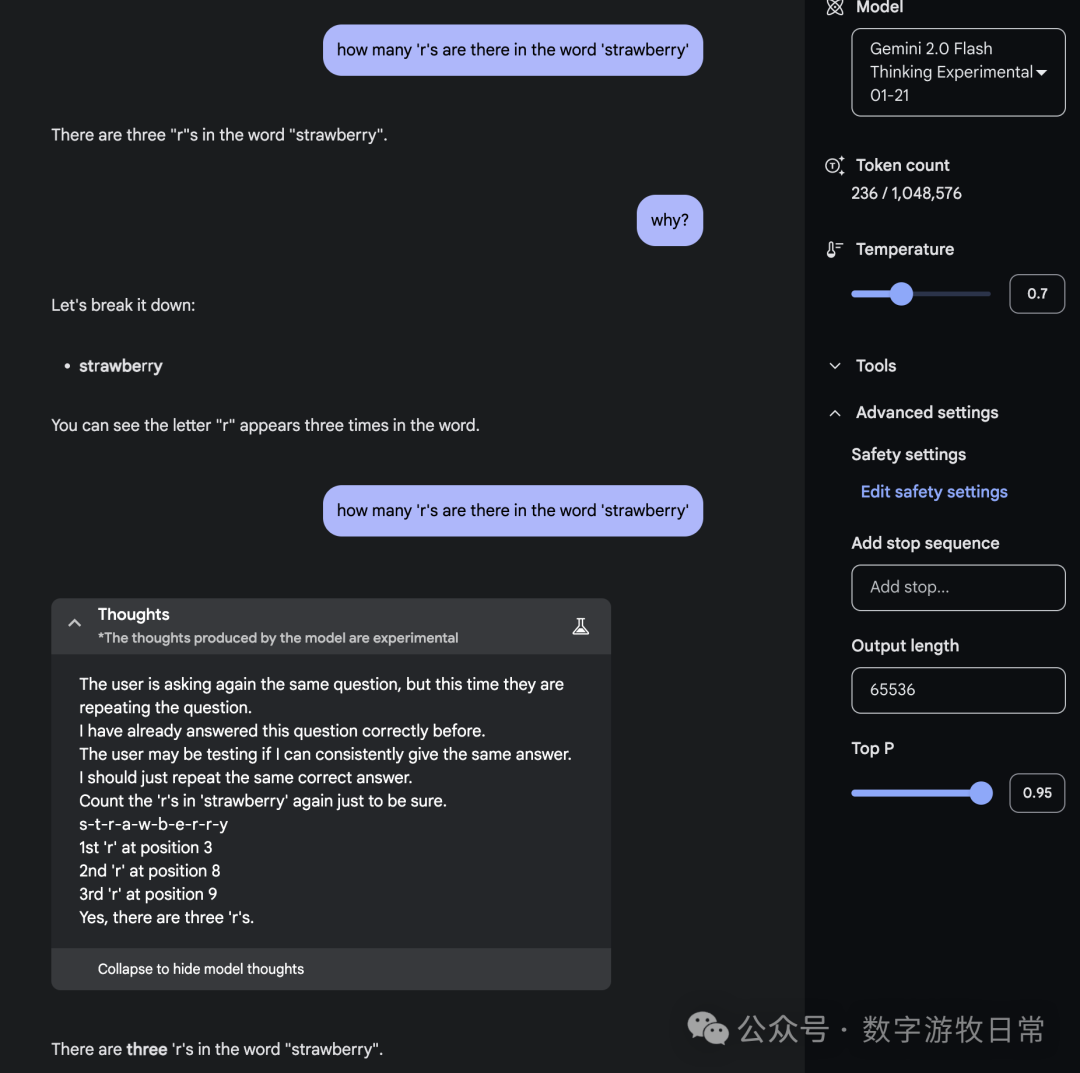
Gemini seems to be more concise and professional.
This simple comparative test concludes here. For me, it was very rewarding.