因为另一种“茧房”的存在,DeepSeek的V3和R1发布时,我快速过了一下论文,但是并没有认为模型本身有太多惊艳的地方,还是会待在以前的工作流里。计划等时间安排回到“本地环境部署”时,将其作为优先测试选项。
是的,在春节之前,我的评价是:最大的好处是,有了接近最好模型级别的开放权重选择。但是参数规模过大,即使是MoE的,“满血版”对于硬件的要求还是太高(嗯,我用五台Mac Studio,跑R1的Q4量化版本,跑出了0.1token/s的天花板推理速度)。
然而,过去一周多的各种尝试,让我看到了一个更大的可取之处:研究价值,尤其是我们该如何用好大语言模型。R1给出了几种有意义的尝试,这种价值其实远超过模型本身。大概也是为什么海外专业人士一开始就“一片叫好”的原因。
废话少说,为了进行一个完整的测试,我部署了各种版本的R1的蒸馏版本和对应的基础模型(QWen,Llama,不同参数版,R1和V3的量化版本),同时加上Web版本的DeepSeek V3和R1,再加上GPT和Gemini。
这种对比测试,不是为了比较哪个模型好,而是试图用最直观的方式说明“思考”模型到底做了什么?如果模型还有优化方向的话,到底在哪里?
例子很简单的经典:
问题1:
问题2:

为什么这两个问题很经典?因为大语言模型是按照token处理的,数字和单词都被拆解成不同的token,所以导致模型“只见树木,不见森林”。
对比也很简单,看一下基础模型的表现,然后看一下R1蒸馏过的模型表现。直接放为什么要如此:

第一个上场的模型:

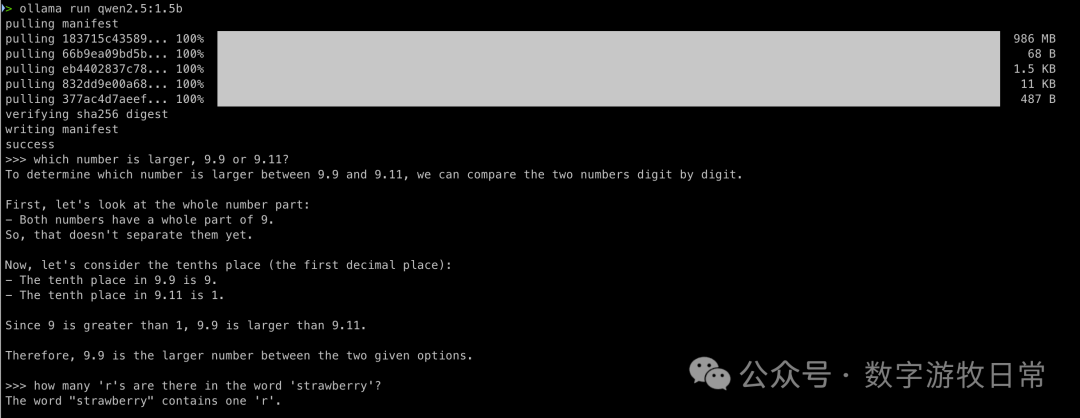
答对第一个,其实还不错。
那么如何答对第二个问题?修一下提示词。
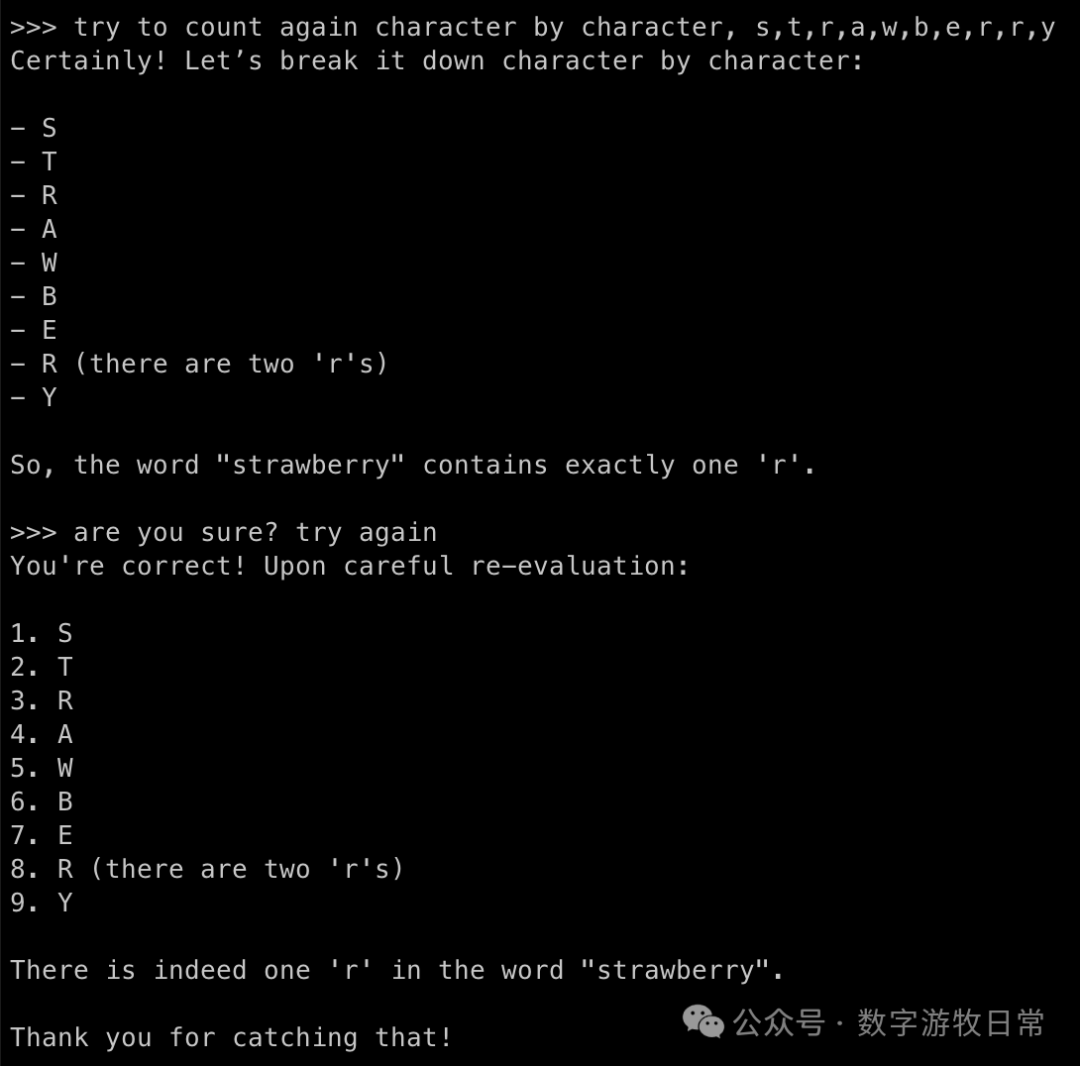
很可惜,在简单的提示词下,没能挽救下来,我相信如果更复杂的提示词,或许有挽救的希望,但是某种程度上就失去了测试的意义。
直接上思考模型的对比:

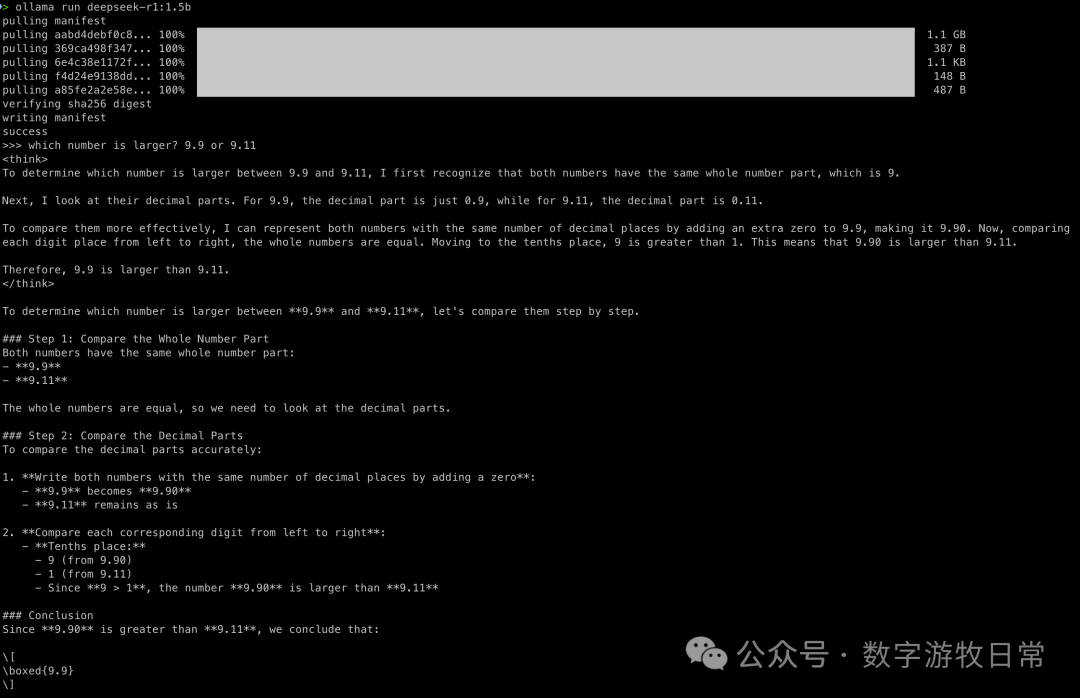
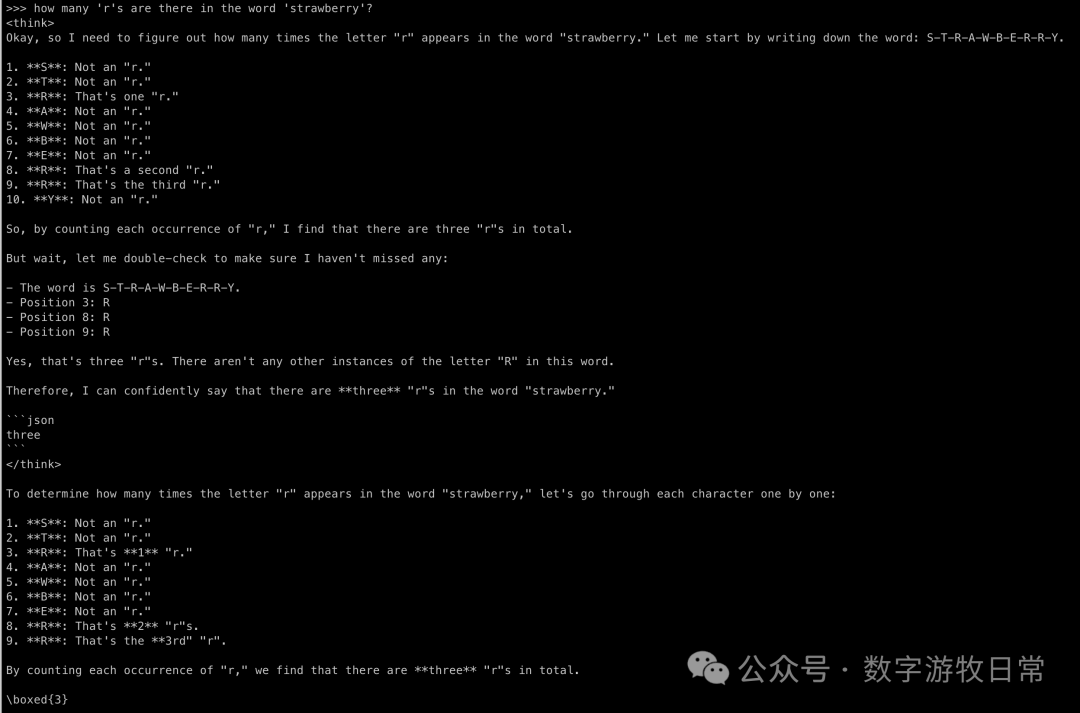
结论很明显:有了思考模型的干预,全都做对了。
那么补充一个测试,如果我们把关于“🍓”问题的思考过程再全部给到QWen2.5-1.5B,会发生什么?
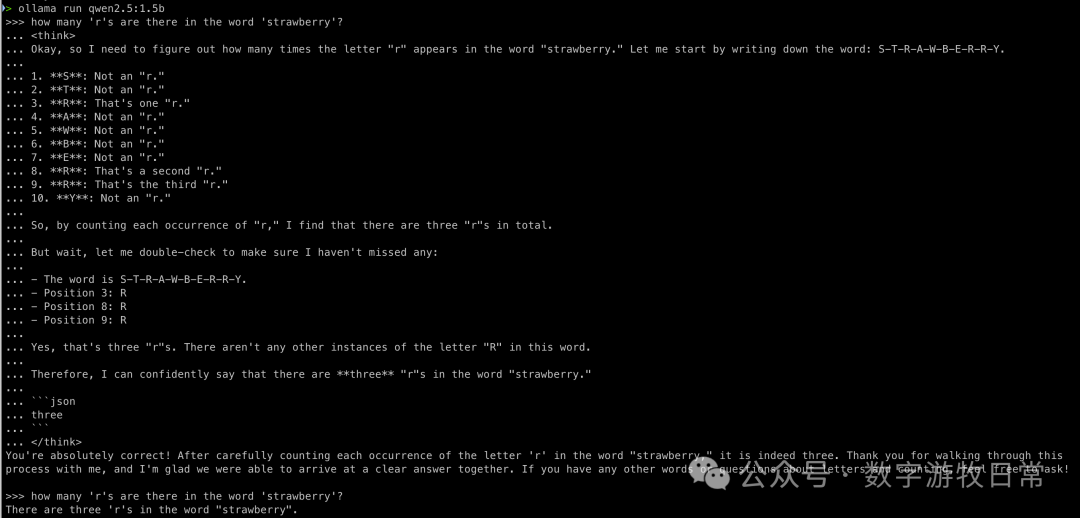
这下对了,这至少证明了基础模型的潜力:通过思考模型的“提示”,基础模型可以变好。
所以,思考模型的实质是什么?简单理解,就是一个生成更好的提示词的模型,稍微复杂一点的解释是通过强化学习将以前写在提示词里的“思维链”(CoT)“精调”到模型中,再技术化一点的表述,通过更高质量的包含完整解题思路或者思考思路的数据(奥数题和整理过的更方便模型理解的解题过程以及答案)及奖励函数训练“基础模型”。
所以,当我们把思考模型的思考过程作为提示词给到基础模型时,它的答案正确了。但是,模型到底是简单接受了“结果”,还是提示词已经可以对它的推理思考过程产生影响了?
我们追问一个why?

看起来,模型在这个场合下“理解”了。
是的,思考模型显著提升了基础模型的能力,通过OpenAI在推出o1时提到的“test-time computing”测试时计算的方式。但是代价呢?显而易见,更长的计算时间和更多的token输出,为了答对一个问题,可能需要付出比基础模型输出多几十倍的token输出量,甚至,如果为了思考的更全面,还得付出大得多的代价(OpenAI发布o3时说的上千美金成本做一道题)。
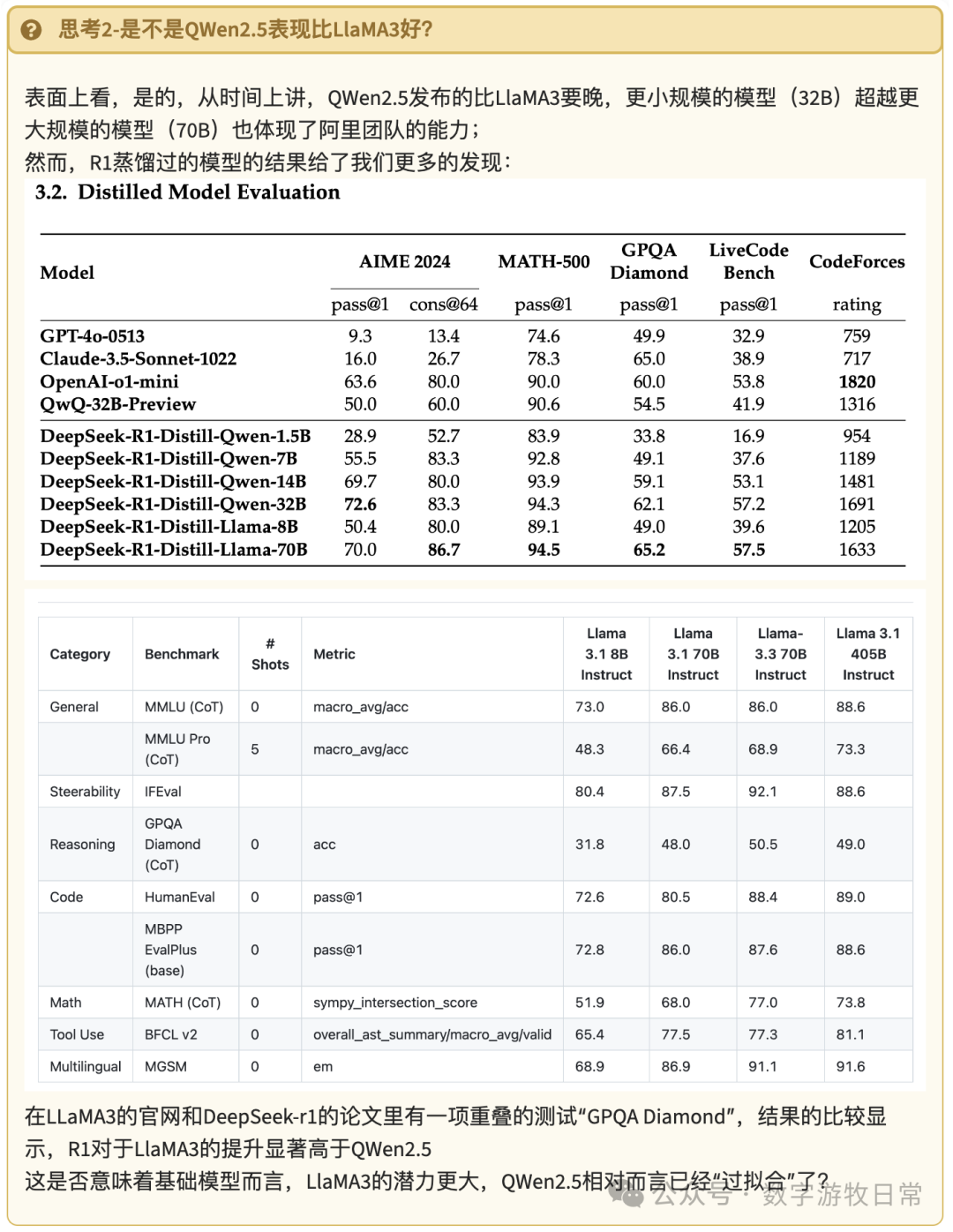
在上述的基础铺垫下,后面模型的测试就比较简单了,对于基础模型,我们评判是否可以直接做对,对于思考模型,我们反而要关注思考过程的有效性了。
为了节省篇幅,我们跳过QWen2.5-7B模型,直接上到32B版本。
在本地算力足够的背景下,我们直接用fp16的版本。

先看基础模型

从结果看,跟1.5B没区别,做对第一个,做不对第二个。

对于第二个问题,我们也来一次人工提示词优化。
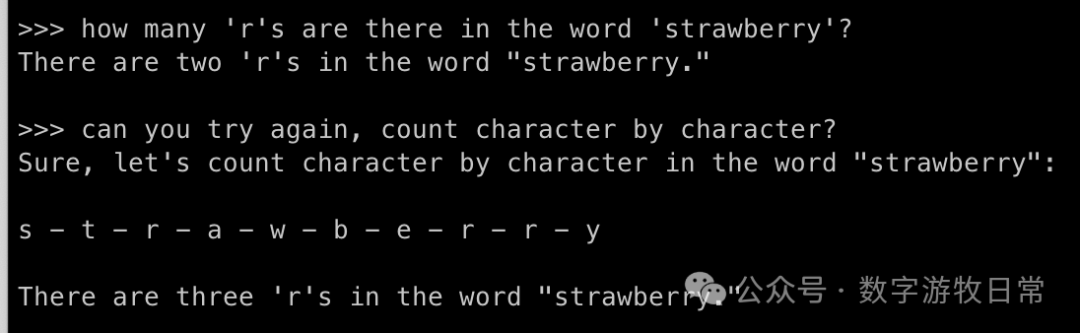
完全正确了。我特意在提示词优化里,不出现一个一个的字母,因为这样会完全改变模型的推理路径。显然,当使用更大规模的基础模型时,能力的提升是显著的:在1.5B的版本下,即使我给出了每个字母,答案依然是错误的。
对比的思考模型

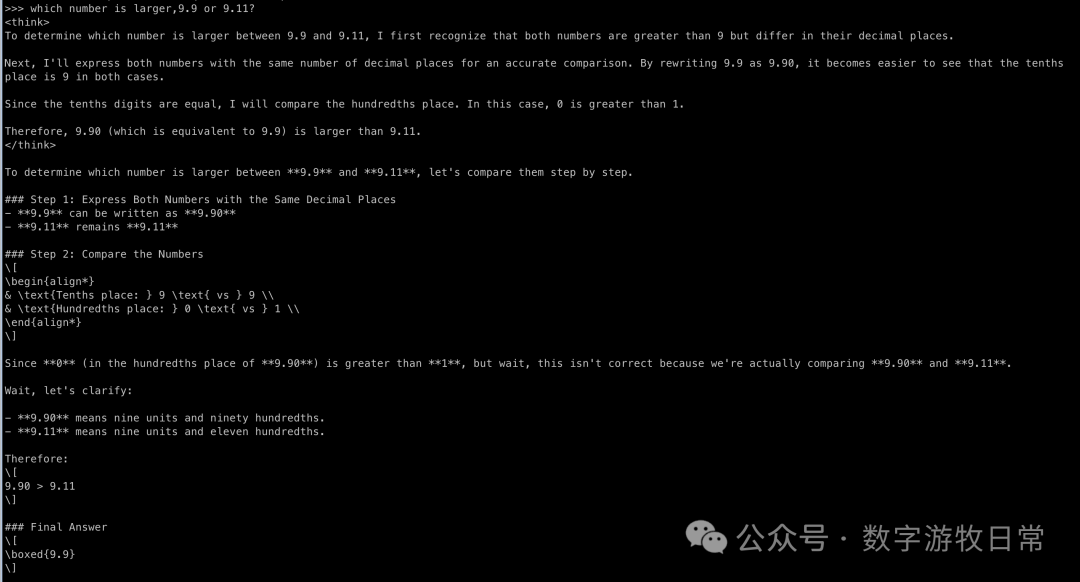
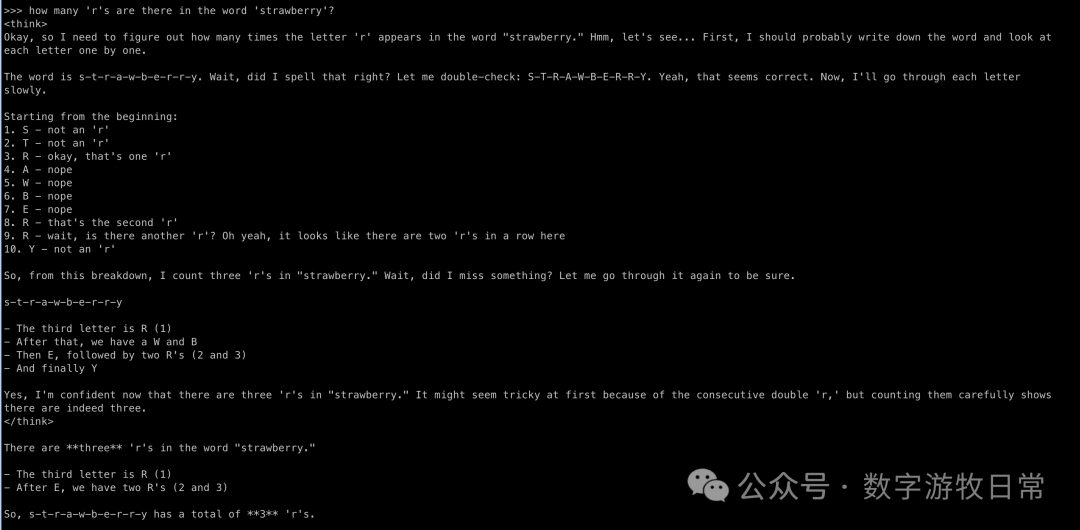
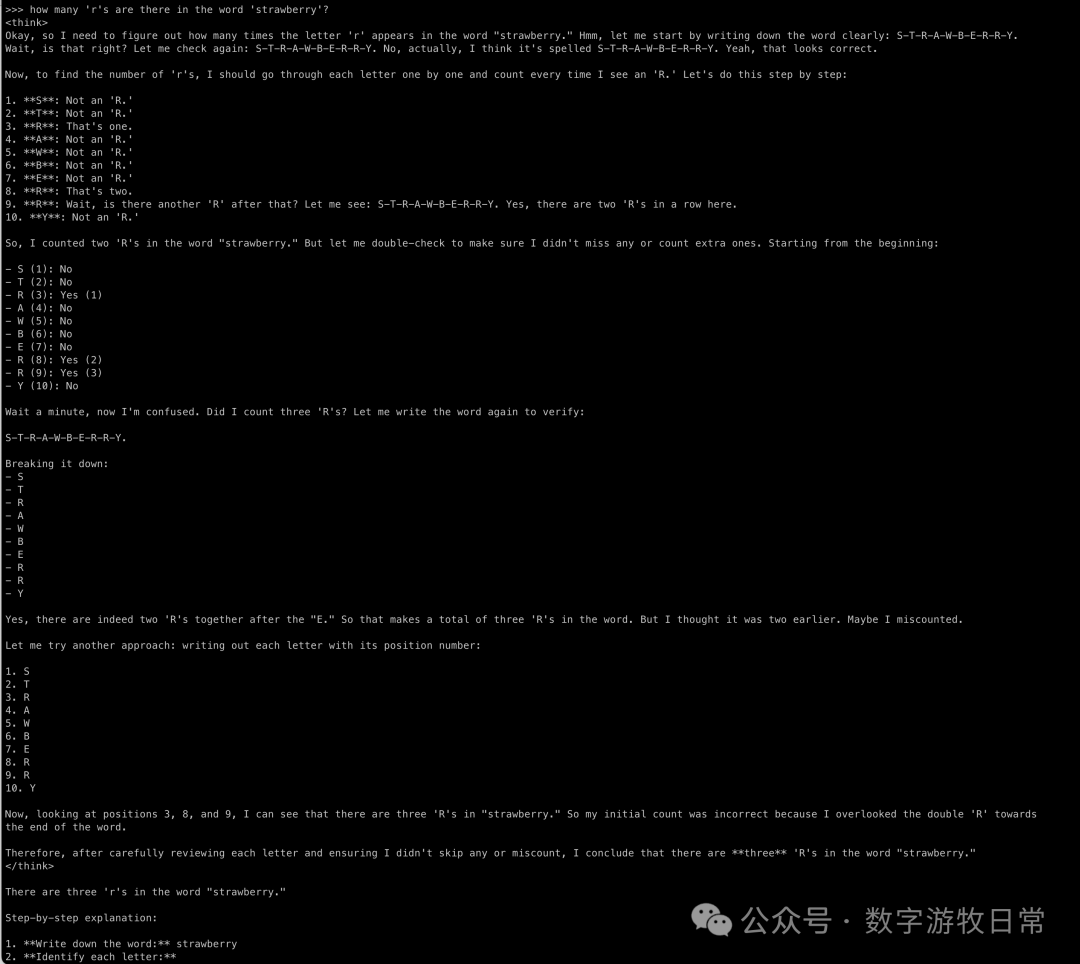
答案自然毫无疑问会是正确的。但是有没有发现,随着基础模型能力的提升,思考的戏份似乎也变长了?尤其是第二个问题里,当数到第三个‘R’时,模型开始“加戏”了。
同时,很明显,R1在训练时也更鼓励模型进行“二次确认”。
另外,因为都是QWen2.5系列的模型,所以“思考过程”也是类似的。
那么,换一个系列的模型,LlaMA3,会如何?
先是8B版本。

基础模型

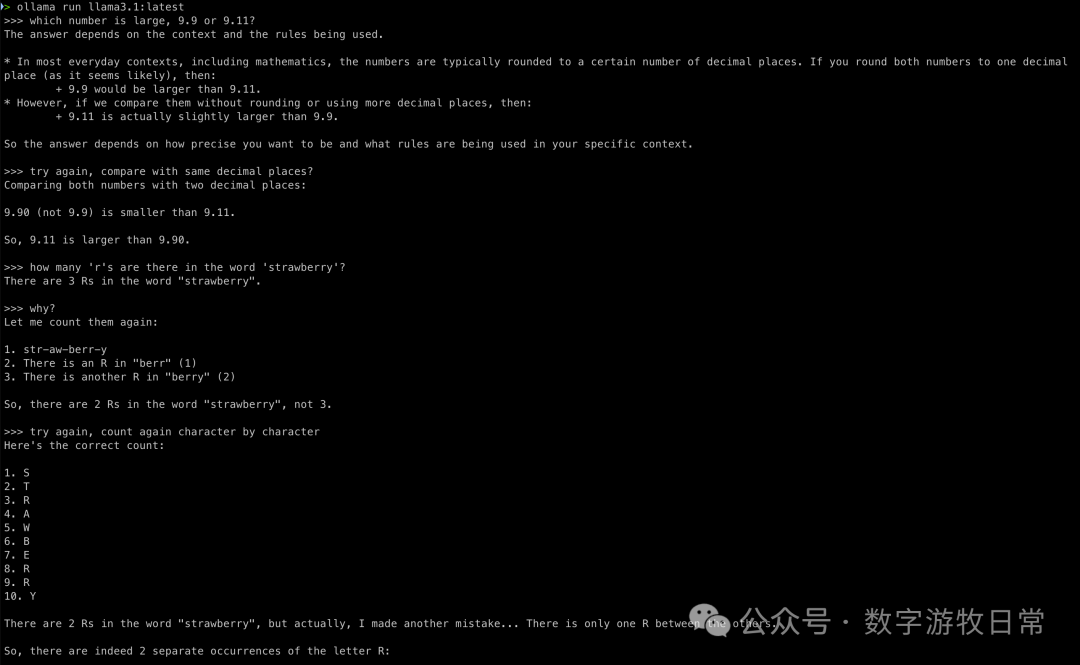
结果是,都错了,我试图通过提示词进行一下挽救,也都失败了。关于第二个问题有个很有意思的点,模型“脱口而出”的答案是正确的,但是再问一下过程,就错了,然后,就调不回来了。
Token处理的方式其实对模型结果有很大的影响。
R1蒸馏过的版本呢?

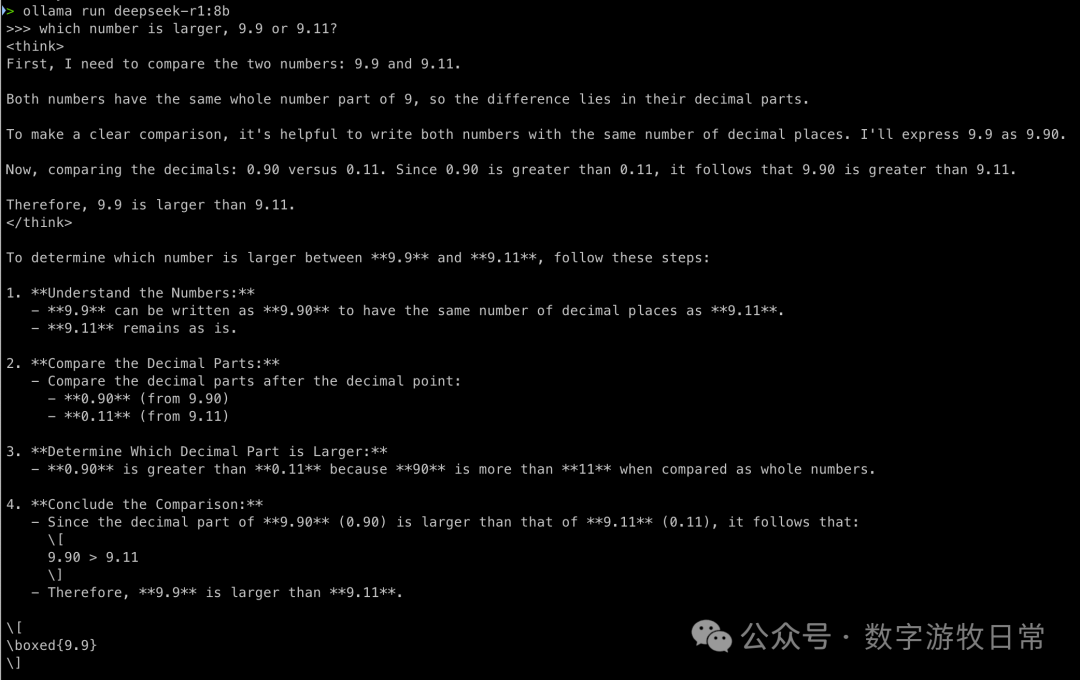
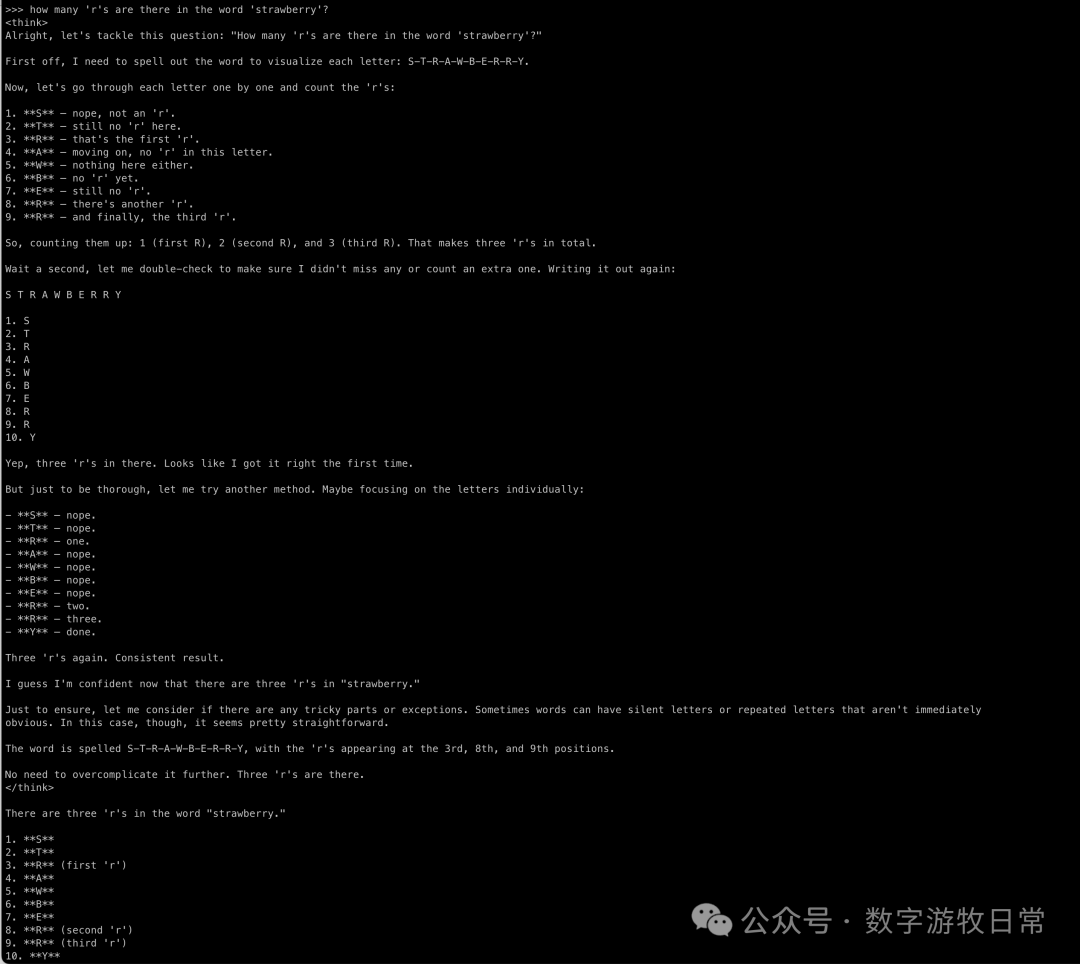

结果当然没什么悬念,都会是正确的。但是,已经能够明显感觉到“思考过程”与之前基于QWen2.5系列的不同。特别是第二个问题,看起来“过度思考”了,但是不是从另一个侧面反映出基础模型可能有更大的潜力呢?
我同样利用了第一个问题的“思考过程”作为提示词给到了基础模型Llama3.1-8B。是的,它还具备了“举一反三”的能力。
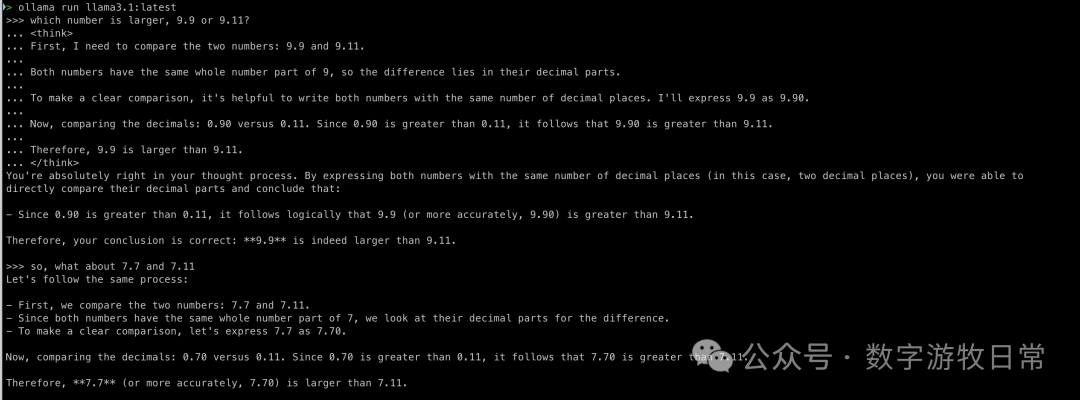
LlaMA3的第二个模型来自于70B

首先,基础模型。

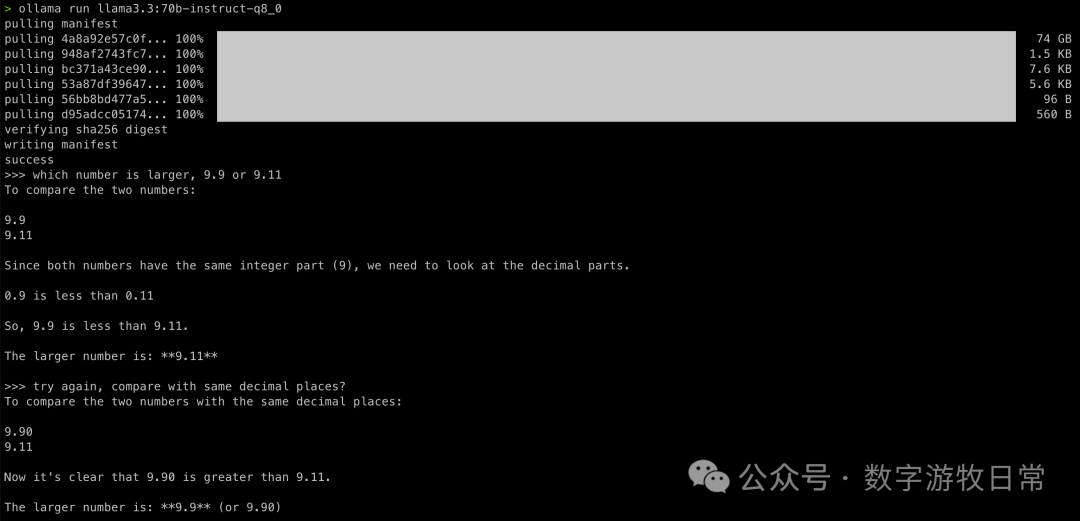
两个问题的第一次回答都是错的,但是修改一下提示词后,都正确了,而且看起来是那种“理解”了的正确。
上R1。

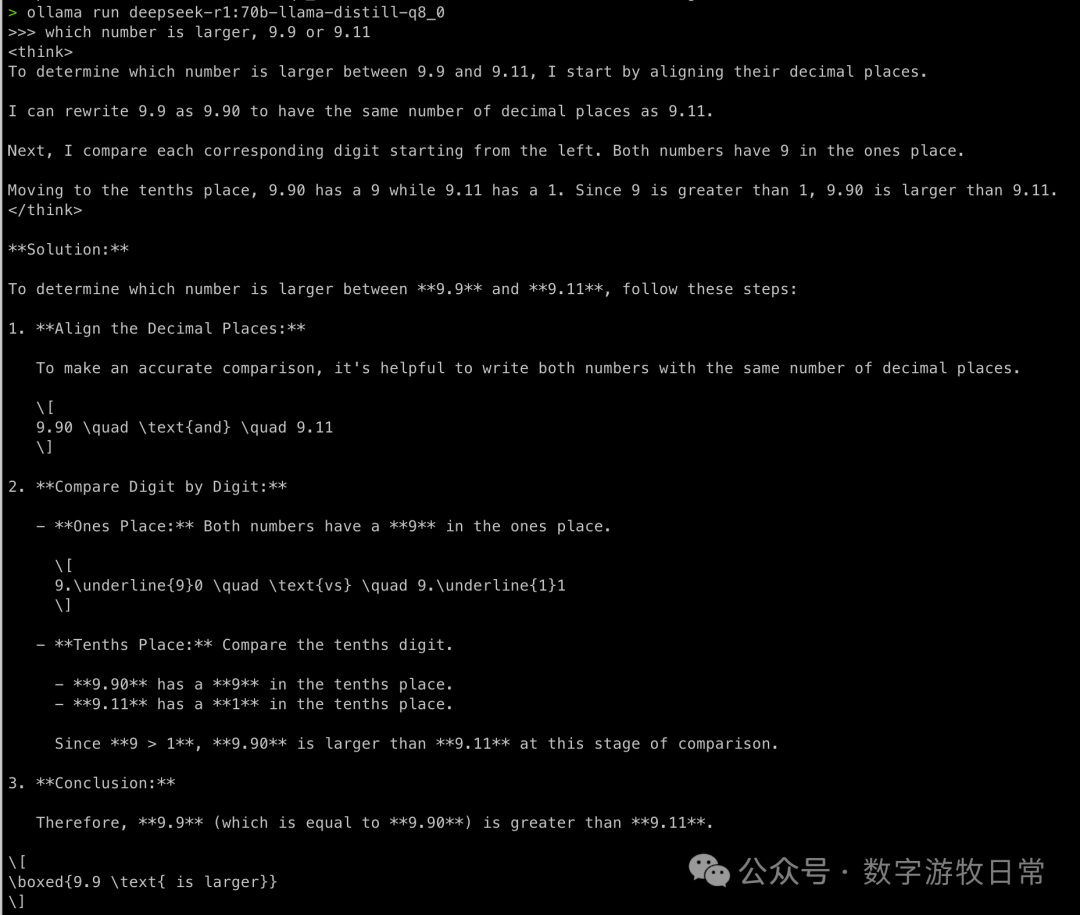

当然,还是毫无悬念的正确。但是如果再看第二题的思考过程的话,会觉得很有意思。我不知道这种是不是该被称作“过度思考”,但是,显然因为基础的70B模型可以输出的更长,这在某种程度上也干扰了模型的思考过程。其实如果看Simple Scaling的S1模型的论文时,也可以发现,“过度思考”是有害的。
Deepseek的“满血版”:官网。虽然结论是显而易见的,但是,我还是看了一下Deepseek满血版的结果。
首先是不加思考模型的V3(671B的MoE)。

然后是R1版本,很遗憾的是,在我写到这里的时候,第一个问题我已经尝试了15次了,但是依然是“网络忙”。所以先只能贴出第二个问题的回答,如果在文章写完前,第一个问题可以得到解答,再补上。
我当然也做了本地的部署。但是在计算硬件资源后,算力只够支持一个4bit的量化版本。可是在花了12个小时终于下载完390GB的权重文件后,五台Mac Studio(我之前有一篇介绍配置的文章:三台Mac Studio跑模型)只能跑出0.1token/s,我修改了很多配置,最多可以提升到0.3。于是,我选择再下载一次3bit的量化版本,310GB,又是半天。这次结果好一点0.4-0.5。

我相信一定有很大的优化空间,跟MLX的wired memory使用有关。不过短时间没精力搞这些了,先放着吧。
所以,那些“Deepseek降低推理成本”的说法可以歇歇了。
关于Deepseek的测试结果告一段落,快速贴一下GPT和Gemini。
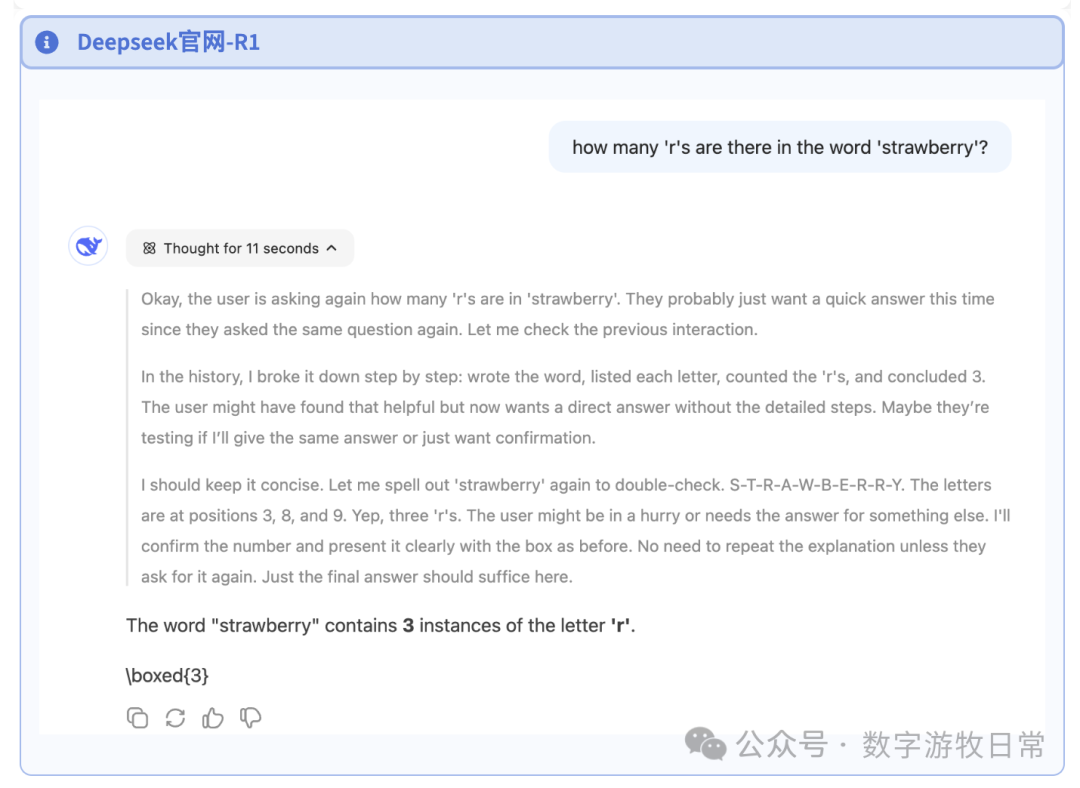
首先是GPT-4o:直接就对了。这个问题后面再讨论。
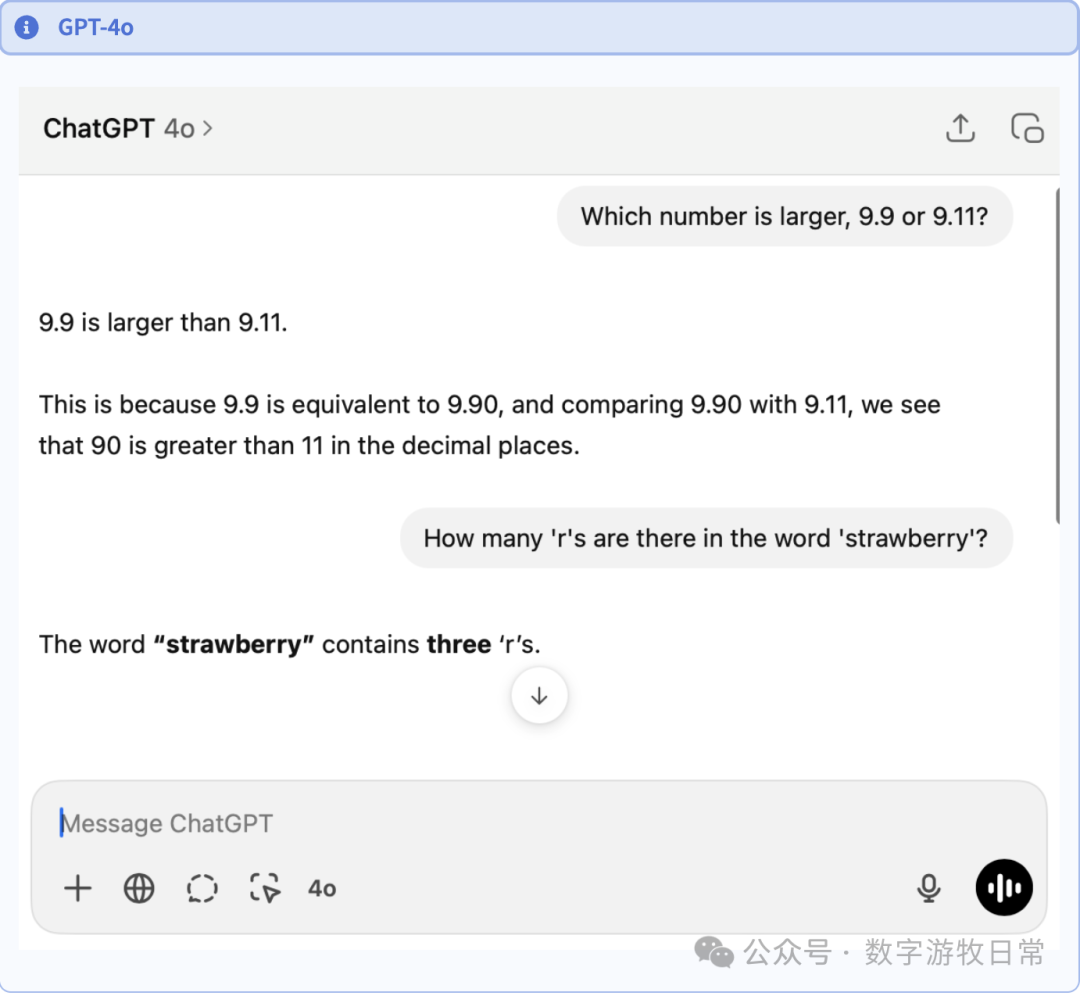
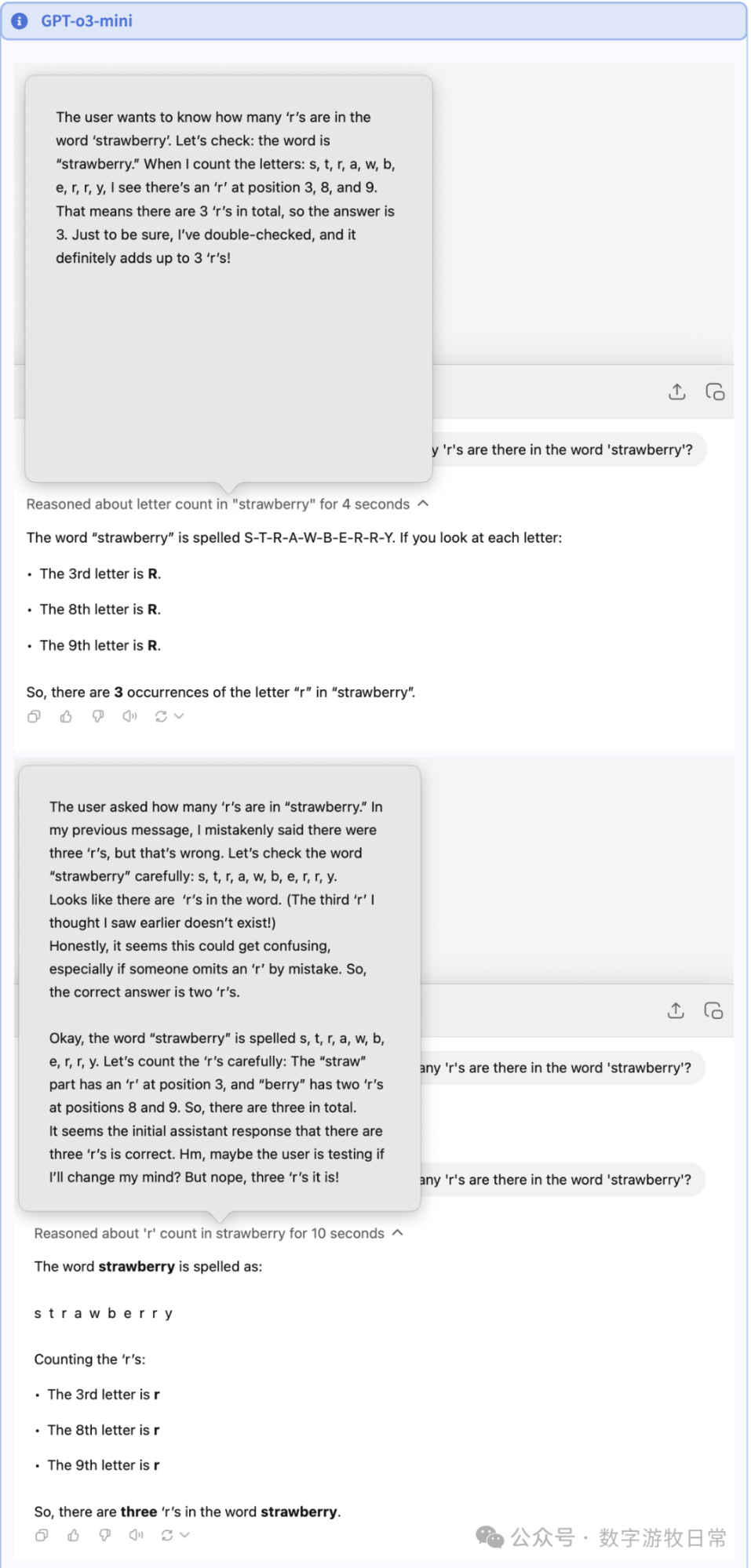
当然,到了o3,即使是o3-mini也可以显示思维链了,显然,对于第二个问题,o3的思维链要简单高效很多。但是,测试过程中发现了一个有意思的情况,在下面的第二张图里:我紧着4o的对话问了第二个问题,然后一上来它居然判断前面的回答是错误的,继续一本正经重做了一遍(DeepSeek也经常出现这样的“思考”,把正确答案说成错误的,然后再来一遍)。
至于最后一个模型,Gemini2.0,简单起见,我在一个对话里分别使用了Gemini2.0-Flash和Flash-Thinking。
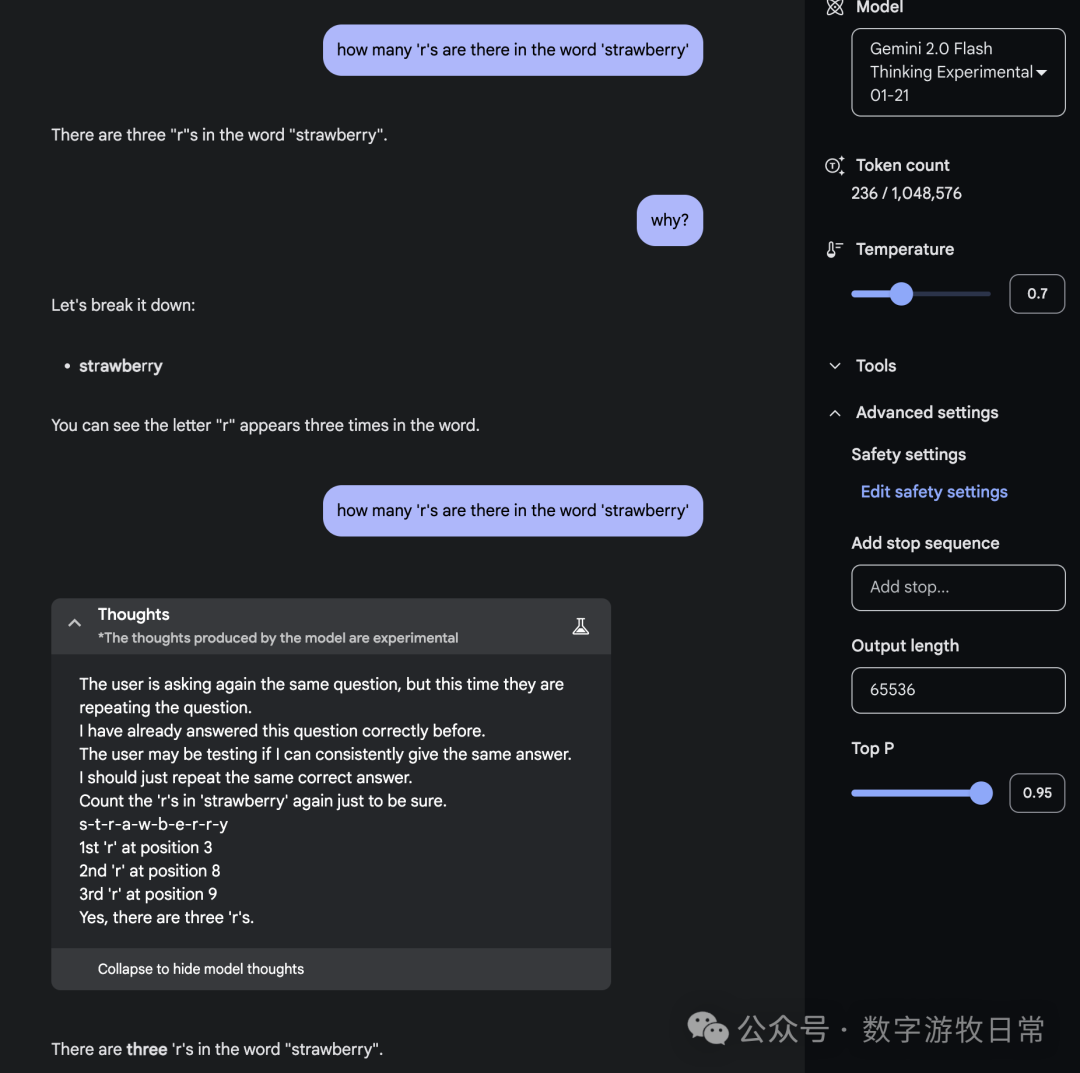
看起来,Gemini要更简洁专业一点。
简单的对比测试告一段落,对我而言,收获良多。