
Since OpenAI pushed its "PhD Level" Deep Research, I have been curious about the level it can reach and how much it can help in actual work, and even more interested in its "flaws."
I am working on a complete test plan and need to establish a question bank. Of course, it's not just about testing; I also want to know where and how humans need to intervene when a model of this caliber is introduced.
Before this, coinciding with tech giants releasing their earnings reports, I asked a more practical question: Provide a deep analysis of MAG7 (the Magnificent Seven).
Of course, Deep Research always asks questions first, hoping to get user confirmation before proceeding. To be honest, its questions were quite good and served well as an outline, so I accepted them all without hesitation.

The research process took 16 minutes and cited 27 sources.
Looking at the model's first step, it seemed quite comprehensive, but why was it searching for reports from "2023"? What happened to the promised "past two years"?

Of course, there were subsequent "thoughts" and searches. Then came the full report, which was nearly 20,000 words long.

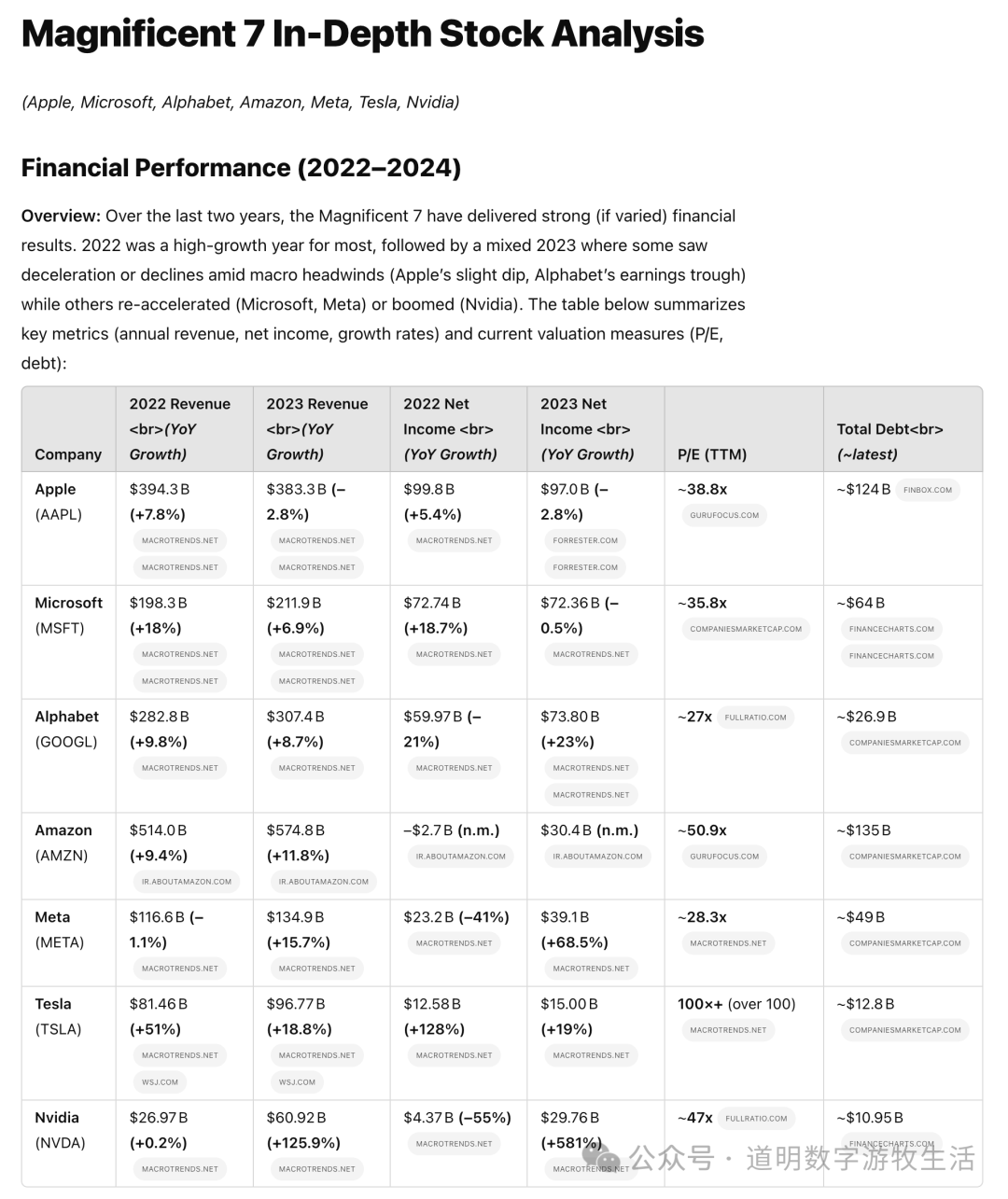
Due to length constraints, I'm only posting the initial part. However, as a research report, the data timeliness in the tables was problematic, making it a failure in that regard. Of course, the main figures were mostly correct.
In the full report, there are many detailed analyses; if you look at each detail, there are merits. But overall, compared to a qualified analyst (real-world level, not "stock report" level), the gap is still quite obvious.
However, for a report that can be produced in 16 minutes, the amount of time humans can save by editing on top of it is significant.
One detail in the reasoning process is worth mentioning: the model discovered data conflicts between different sources regarding Amazon's earnings.

It didn't mention which source it ended up using.
However, a decision-making process regarding a Microsoft data conflict appeared.

It was a bit of a leap, but this capability is commendable.
The generation of this report gave me several insights:
- It might be more important to explicitly specify timeframes and data sources to the model;
- Moderate intervention in the analytical framework might yield better results.
So, in a new attempt, I narrowed the questions and mandated the use of official website data.
For companies that had already released their latest earnings (Tesla was not included in my requirements, Amazon reports tomorrow, and Nvidia later), it accurately cited the latest data. Sources included official sites and authoritative ones like Reuters.
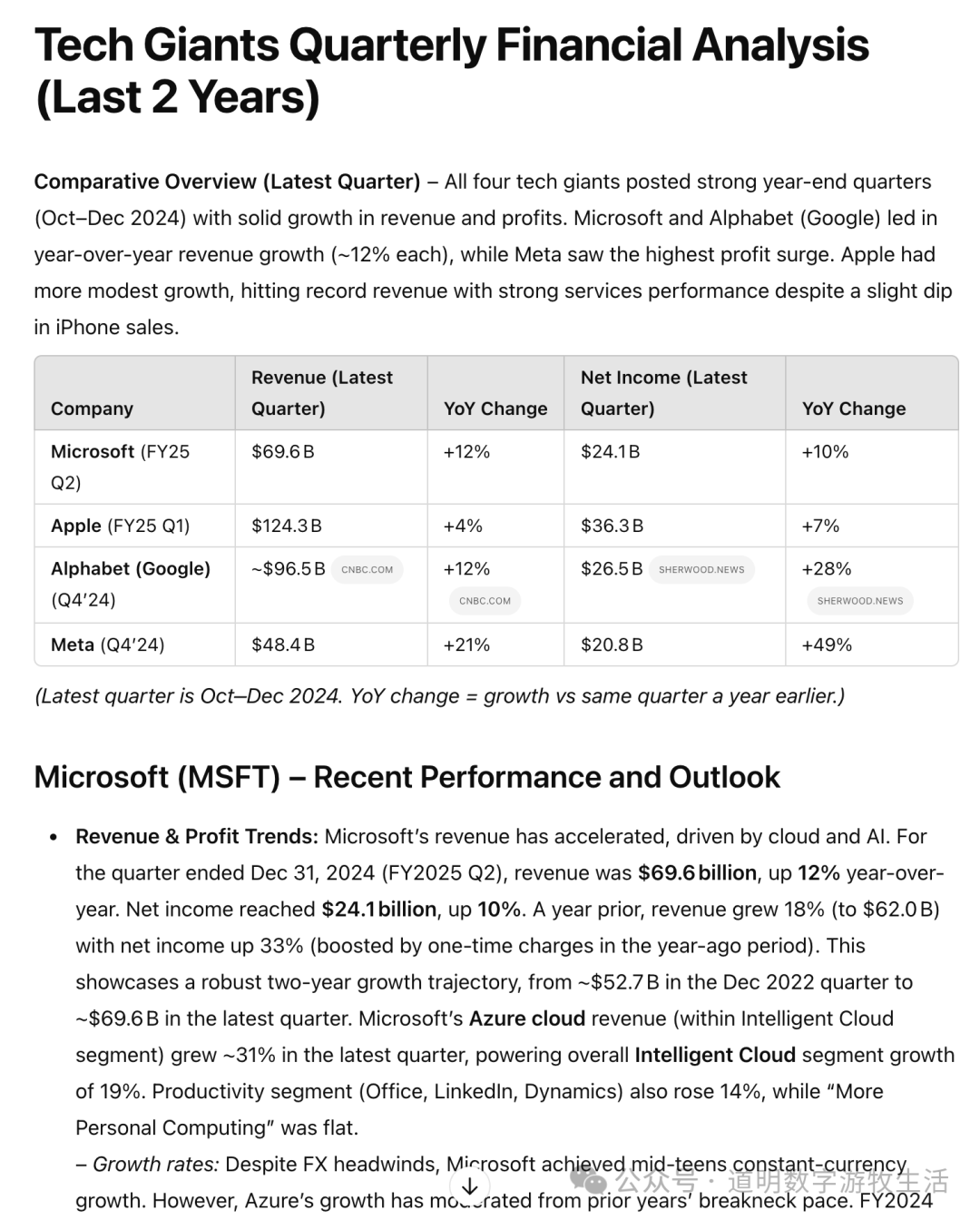
Yes, this was noticeably better and had at least two values:
- The structural framework was more reasonable, making manual adjustments easier;
- It eliminated a lot of manual work in data collection and comparison, especially for numbers.
Over the past year, I held the view that GPT-4o, as a "compressor," was good enough, especially in text, to be effectively called by other reinforcement learning models to complete vast amounts of work.
Now it seems I was only half right. It's well-trained, but for applications like Deep Research, GPT-4o is still far from good enough:
- Human research is often a long-term, sustainable, and incremental process. Current models use a full-refresh process; every prompt is essentially a rewrite. Even with methods for partial updates, global structural information is lost.
- The root cause is the lack of a "persistent memory mechanism." I previously thought memory could be solved via external plug-ins (giving memory as context), but recent "deep thinking" makes me doubt the feasibility of this approach.
- This doubt stems from an obvious "lack of judgment" in the model. The previous example showed the model can detect "conflicts" between sources—a huge step forward—but it cannot judge which is more accurate. For earnings, we can tell it to use official sites, but what about other scenarios? Humans make mistakes, but they have the ability to quickly verify or falsify hypotheses.
- This ability comes from systematic training and logical abstraction. Whether it's OpenAI's o1/o3 or DeepSeek's R1, they seem to aim for this "logical abstraction" via RL-based thinking, but the result feels more like prompt engineering. In fields where I am an expert, like code generation, GPT-4o with my optimized prompts is at least as good as o1/o3. In fields where I'm less professional, o1/o3's "thinking" output is better than raw GPT-4o.
- RL-trained "thinking models" are in very early stages with room for optimization, but I increasingly doubt how much better RL will be than a prompt-based Agent.
- Moreover, results from such "reinforcement learning" are very unstable.
- On a positive note, o1-pro, which consumes more compute and thinking time, seems more stable than o1. o3-mini-high is more stable than o3-mini, and Deep Research also feels a bit more stable.
- Does this mean more searching leads to better convergence? If so, why not add more data during pre-training to make the base model more stable?
- One more thing: in OpenAI's "marketing demos" for this model, the questions are very specific and narrow, where definitive sources can be found quickly. Humans don't need models that can only solve Math Olympiad problems.
Persistent memory, hypothesis testing, and output stability—we might really need more solutions at the pre-training stage.
Achieving stunning results with small fine-tuning datasets and short training times, as R1 did, proves the strength of the base model more than anything else.
It's similar to the progression of smart driving. Initially, adding a few rules to neural networks (mainly CNNs) allowed cars to drive. But the more they drove, the more problems they encountered, leading to an endless cycle of adding rules.
Then Tesla introduced FSD based entirely on end-to-end deep neural networks. It looks much better. While we don't know if it will fully conquer Level 5, it seems more promising with significantly less code. The rest is just having enough data.
However, autonomous driving is for "no humans," while LLMs are for "having humans." In the human world, we can't achieve "no humans"; focusing on "how to be useful to humans" might be more realistic and simpler.
From this perspective, Deep Research is more useful than previous models. But to make it even more useful, we might need a better base model (GPT-5? Or whatever mysterious name OpenAI chooses).
PS: After finishing the article, I needed a title, but I was completely out of ideas.
