
在OpenAI推送了“PhD Level”的Deep Research后,既好奇它能达到什么水平,对实际工作有多少帮助,也更感兴趣它的“缺陷”。
我正在做一个完整的测试计划,需要建立一套题库。当然不仅仅是测试,更是希望知道在这样级别的模型加入后,人需要在什么地方进行干预,如何进行干预?
在这之前,恰逢科技巨头纷纷出财报,我问了一个更有现实意义的问题:深度分析一下MAG7(七姐妹也好,七巨头也罢)。
当然,Deep Research总会先问一下问题,希望得到用户确认后,再进行。实话说,它的问题问的不错,作为大纲也挺好,我坦然的全盘接受。

研究过程16分钟,引用来源27个。
而看模型第一步的处理过程,看起来挺完整,但是为什么搜索的是“2023”年的报表?说好的过去两年呢?

当然,后面还有一系列的“思考”和搜索。然后是完整的报告。报告全文接近两万字。

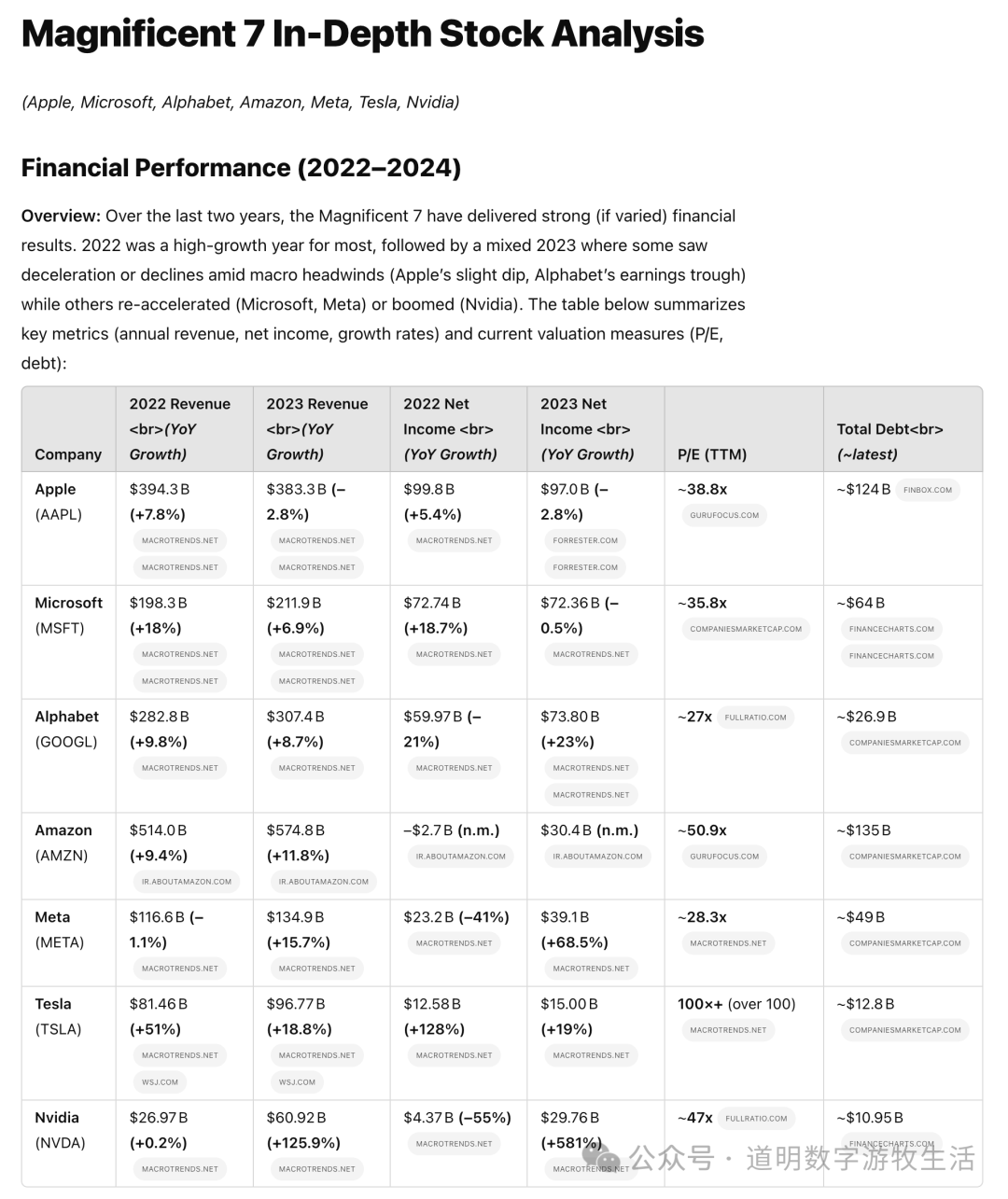
篇幅关系,只贴出前面的部分,但是作为一篇研究报告而言,表格的数据时效性就出问题了,自然是不及格的。当然,主要数字基本都是正确的。
在报告的全文里还是有不少的细节分析,如果去看每个细节的话,有可取之处,但是整体而言,跟合格的分析师相比(真实水平,而非“研报”水平),差距还是比较明显的。
但是一个16分钟就可以产出的报告,人在此基础上修改可以节省的时间其实是非常显著的。
有一个思考的细节值得提起,思考过程现实发现了不同来源间的数据冲突,来自亚马逊的财报。

后面没有再提及使用了哪一个来源。
然而,却出现了关于微软数据冲突的选择决策。

很跳跃,但是这个能力值得称赞。
这篇报告的生成给到我几个启示:
1、或许更明确的向模型指定时间和数据来源会更重要; 2、对于分析框架,可能适度的干预会更好。
所以,在新的尝试里,我把问题收敛,并制定使用官网的数据。
对于已经公布最新财报的几家公司而言(在我的问题要求里没有包含特斯拉,亚马逊财报将于北京时间明天公布,英伟达会在比较后的时间),准确引用了最新的数据。数据来源除了官网外,也会更多引用更权威的例如Reuters等。
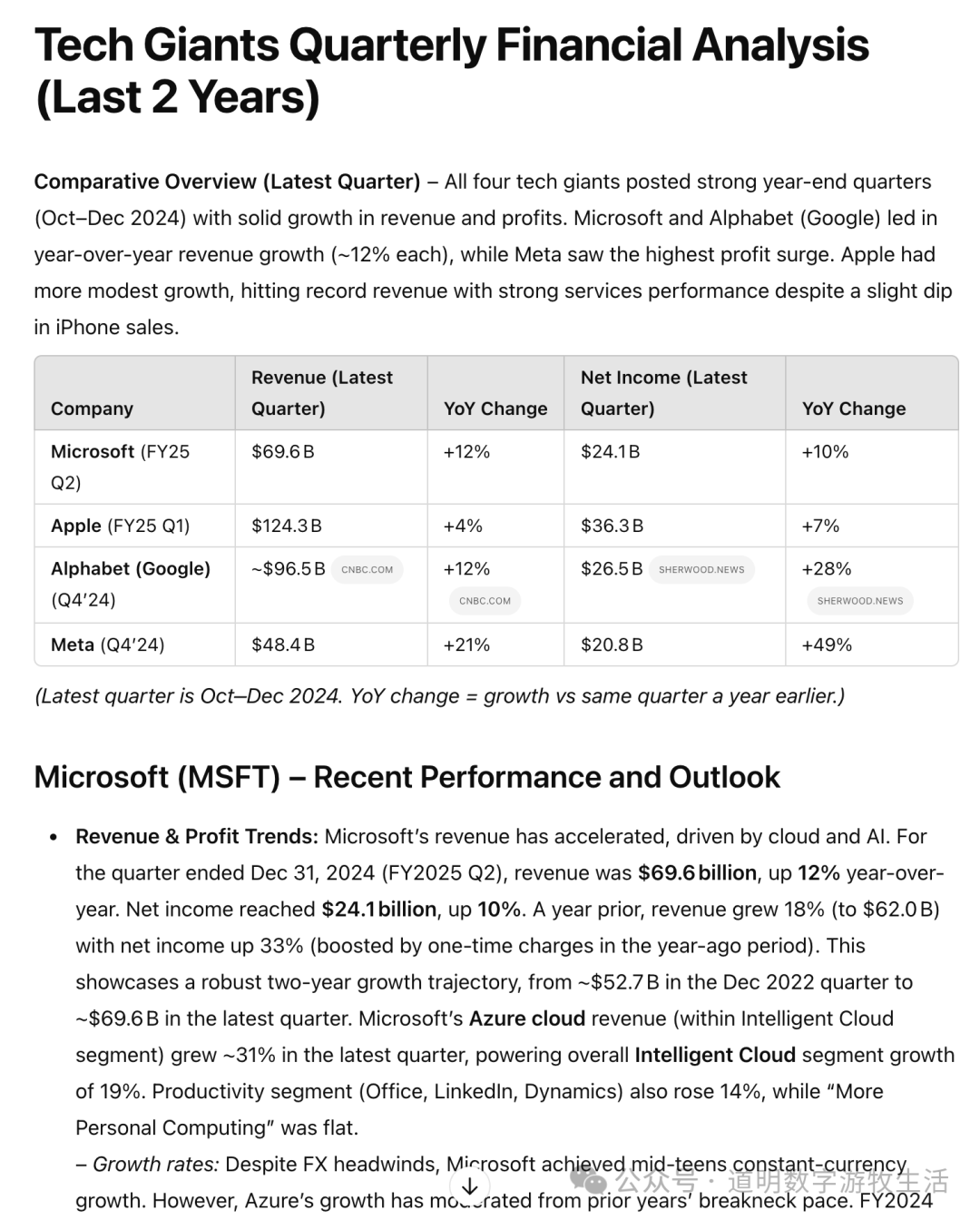
是的,明显好了很多,至少有两个价值:
1、结构框架更合理,人工调整修改更简单一点; 2、省去了许多人工查资料汇总比对的工作量,特别是数字部分;
过去一年,我一直持有这样的观点:GPT-4o作为一个“压缩器”,表现得已经足够好了,特别是在文本方面,已经足够足够被其他强化学习模型很好地调用,完成大量的工作了。
现在看来,大概最多只对了一半,训练得很好是事实,但至少放在Deep Research这样的应用里,GPT-4o还远远不够好:
1、人对一个问题的研究可能是长期的可持续过程,是个增量更新的过程,如今的模型,全是全量更新的过程,每一次提问,其实都是一次重写。即使可以有很多方法进行部分更新,但这又会失去整体结构的信息; 2、造成上述问题的根本原因是模型缺乏“持续记忆机制”。之前我认为GPT-4o已经足够的一个重要原因是我认为“记忆可以靠外挂方式”解决,每一次模型对话都把“记忆”作为上下文交给模型,但是这两天的“深度思考”,开始让我怀疑这种方式的可行性; 3、上面这种怀疑,来自于“显而易见”的“模型缺乏判断力”:是的,前面的例子已经表明了模型有能力发现不同来源之间的“冲突”,这是个非常大的进步,但是,模型却没有能力去判断哪一个更准确。当然,对于财报数字,我们可以通过“访问官方网站”或者其他权威站点“显示”地告诉模型该怎么做。但是,如果是其他一些场景呢?人当然也一直在犯错,但是人有各种快速证实证伪“假设”的能力; 4、以上的这种能力来自于系统的教育训练,根本来自于逻辑的抽象化。是的,无论OpenAI的o1/o3,还是DeepSeek的R1,似乎都希望通过基于强化学习的“思考”来获得这种“逻辑的抽象化”能力,但结果更像是一个提示词工程:我尝试了一些我有充分信心“自己非常专业”的领域的例子,比如“代码生成”,经我自己优化的提示词后基于GPT-4o的输出结果,至少跟o1/o3一样好。当然,在我不那么专业的领域,经过o1/o3“思考”后输出的结果,比直接用GPT-4o要好; 5、强化学习训练得出的“思考模型”当然只是非常初期的阶段,还有很大的优化空间,但是我越来越怀疑基于这种方式的强化学习最终会比提示词Agent优胜多少? 6、同时,这样的“强化学习”得到的结果,也是非常不稳定的; 7、当然,也有一个好消息:同样是o1,耗费更多算力和思考时间的o1-pro输出的结果看起来比o1要稳定,o3-mini-high也比o3-mini要稳定,Deep Research的初步感觉也会更稳定一些; 8、这是否意味着,搜索的足够多,结果的收敛性就会越强?但是,如果是这样的话,为什么不在预训练阶段加入更多数据,让基础模型更稳定呢? 9、补充一句,在OpenAI关于这个模型的“卖家秀”里,很多问题都很具体,也很收敛,通过搜索可以快速找到确定性强的来源。还是那句话,人类不需要只会做“奥数题”的模型。
持久记忆能力,假设检验能力,输出的稳定性。或许真的需要在预训练上想更多的办法了。
通过少量的精调数据集和很短的训练时间,得到让人惊叹的结果,R1更多证明的是基座模型的强大。
有点像智能驾驶从开始到现在的进程,在初步训练的神经网络模型(CNN为主)上,加入少量的规则,车就可以自己跑起来了。但是跑得越多,遇到的问题越多,加的规则也越多,规则加的越多,越望不到头。
这个时候,特斯拉重新拿出了一套完全基于深度神经网络的端到端训练的FSD,看起来确实好很多了,虽然还是不知道是不是可以完全攻克Level5,但是,看起来有希望多了,代码量也显著下降,剩下的,就是足够多的数据了。
只是,无人驾驶是真的为了“无人”,大模型,是为了“有人”。在人类世界里,我们也做不到“无人”,“怎么对人有用”,这个问题,可能会现实一点,也简单一点。
从这个角度说,Deep Research比过去的模型,对人更有用了。但是要让它更有用,或许需要的是更好的基础模型(GPT-5吗?还是谜一样的OpenAI会换个名字)。
PS:文章写到最后,要出标题,可是我实在没想法了。
