
CES开幕在即,2025年AI的序幕也当然需要由英伟达开启,由老黄的演讲拉开。
关于英伟达软件平台和生态的部分,一直是讲不太清楚的:非常好的设计,但是说不清楚的用户体验。
所以,就集中在两个新硬件上:基于Blackwell架构的消费级显卡50系列,这是现货;以及一个期货,AIPC概念的Project DIGITS。
50系列显卡与AI推理需求
首先是,50系列显卡,在英伟达产品线定位里一直属于游戏业务。但是自从2023年AI大火之后,开始有了大量的本地推理的需求。当时作为和H100同代架构(Ada Lovelace)的40系列显卡,就成为了最高性能的选择。
其实光从GPU本身能力而言,40系列的最高端卡4090还强于H100,只是因为使用的DDR6X内存带宽不如HBM,所以,综合推理性能会差一点。两者相比较,40系列的优势是可以作为游戏、图像视频和3D渲染,是正宗的显卡,弱势是显存容量最高24GB,不能加载较大规模的模型,同时没有NVLink,不支持卡间高速互联;H100的优势自然是80GB的HBM内存,NVLink支持大集群互联,弱势就是不能作为显卡。
另外,40系列可以配到高级的台式机,功耗、散热、噪音方面的控制相对容易,H100至少是高级工作站和服务器,对机房环境等等要求都更高。
所以,H100只能是AI,40系列显卡是游戏、图像视频处理、3D渲染方面的最顶级选择,同时可以兼顾一般AI应用。当然,刀法精准的英伟达还有另一条产品线RTX A系列,其中后缀Ada的产品与40系列同架构,例如,RTX6000 Ada就是Ada Lovelace架构。显存配置到48GB,是4090的两倍,但是内存带宽略低一些。无论是渲染速度还是AI推理性能,都稍低于4090(实测差距一定在10%以内),但是单卡功耗更低,体积更小,显存更大。其实是高端个人或者工作室介于H100和40系列之间的最佳选择。
以上为一些基本信息的铺垫,进入主角,基于Blackwell架构的50系列显卡登场。因为只是点评,所以只针对最高端的产品:5090。
自从英伟达去年年初发布Blackwell架构之后,其实很多人对50系列显卡是有期待的,特别是在AI能力方面。
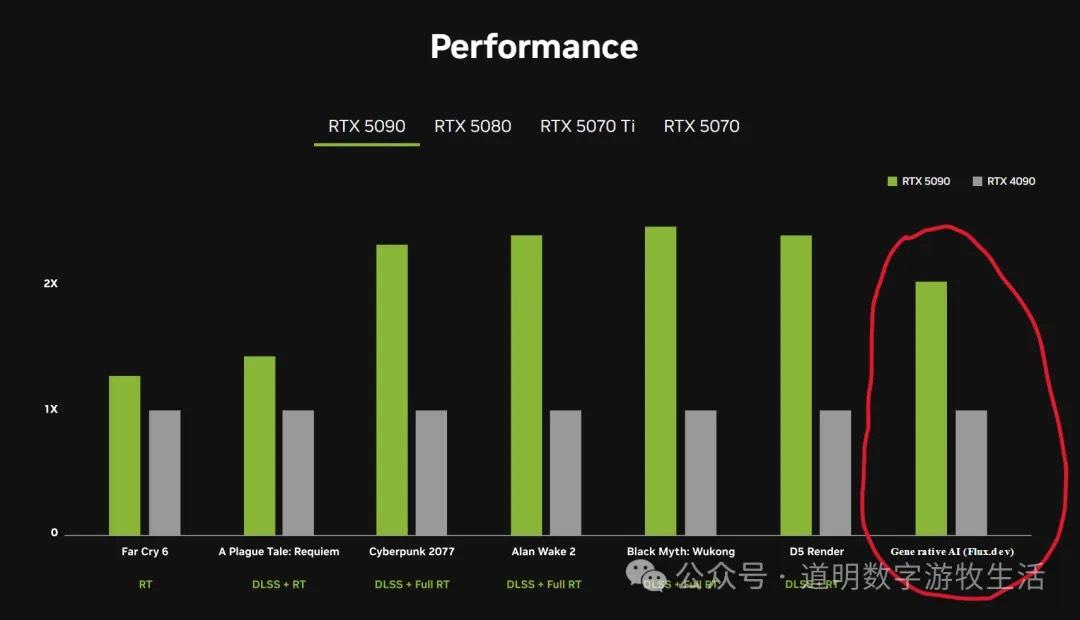
因此,在性能的对比里加入了Flux.1模型图像生成能力的对比。发布会也专门介绍了时间对比:基于4090卡,生成一张图需要15S,基于5090,同样的提示词和参数大小(严谨起见,不能说同样的图),只需要5S多。
如果看上面的性能对比,特别是把游戏和图像生成结合起来看,似乎这个性能提升是非常可观的。不过,尽管游戏性能评价是我的“盲区”,但是在对比测视的软硬件环境里标注了:40系列卡使用的是DLSS FG(Frame Generation),50系列卡使用了DLSS MFG(Multiple Frames Generation),看起来,更多是在算法层面的提升,而不是硬件能力的提升。
所以这张性能对比图里,左边两个项目或许更能反映硬件的实际性能提升:约20%,不到30%。
这跟去年发布Blackwell架构时的认知是一致的:按单Die计算,Blackwell想不Hopper的提升就是约25%,这还是因为Die Size增加了。
那么图像生成是怎么回事?测试条件里写的很清楚(虽然新闻稿很含糊,性能测试图里的条件的字体也是尽可能地小):40系列用的是FP8,50系列使用的FP4。所以,生成速度对比如果是15S比6S,是2.5X,把精度拉成一致,还是1.25X,25%的性能提升。
20%-30%,这就是Blackwell架构真正的硬件能力的提升幅度。
是的,其实在去年Blackwell架构发布的时候,包括我在内,有不少人YY过如果50系列卡也像B200一样,两个Die Size,会很“爆”。事实是,这种YY并没有发生。
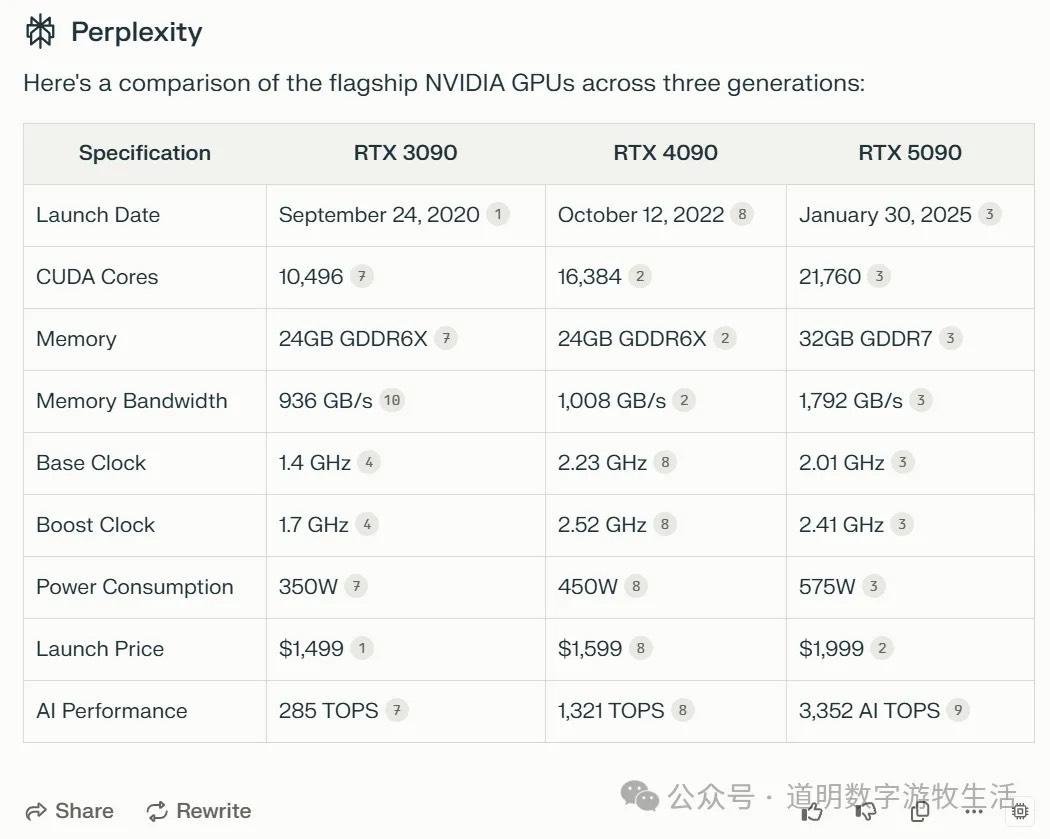
如果我们再结合从30系列开始的三代产品看的话,或许会有更有意思的发现:性能提升最明显的是30系列到40系列。因为各种原因,4090卡在国内的价格一直在涨。
英伟达不再在Spec里公布不同精度下的FLOPS性能,而是换了一个AI TOPS的概念:用FP4的3352TOPS对比4090卡在FP8下的1321TOPS,如果换算回FP8精度,就是1676TOPS比1321TOPS,不到27%的提升。
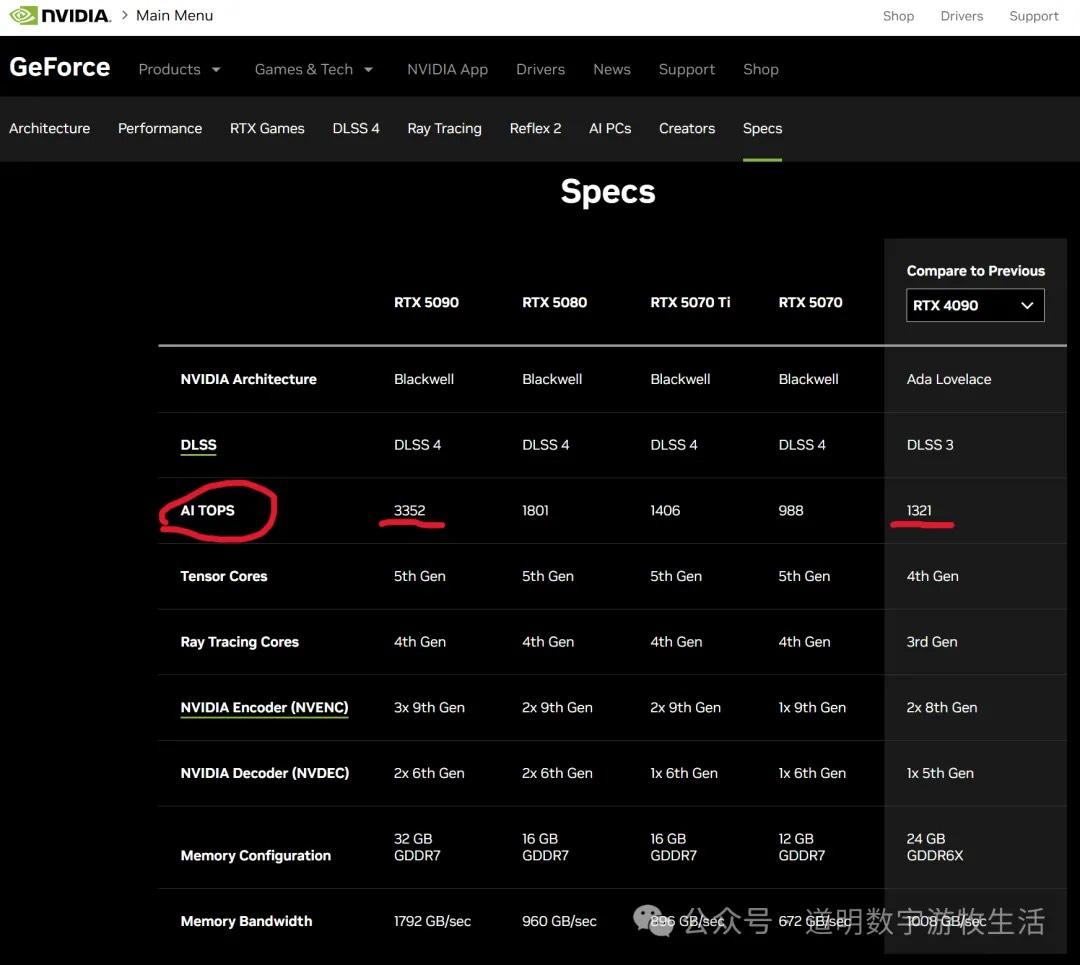
如果我们再较真一下发布时间,也会发现从40系列到50系列的发布时间,相比从40系列到30系列的发布时间,大约延长了两个月左右。是的,漂亮外衣包裹下的真相是:没有黑科技。如果我们再去看功耗:575W比450W,超过了27%。
市场有很多聪明人,发布会后英伟达的股价走势大概说明了一切吧。当然,50系列有它很好的“卖点”:如果你需要DLSS 4和FP4,因为40系列都没有。
通俗一点说,就是如果4090下的游戏体验不能得到满足,那么5090是必然选择;如果AI模型推理,FP4精度的效果已经能够满足要求,那么5090大概可以比4090节省一半的使用费用。
第二个硬件发布:Project DIGITS

这是一个意外的惊喜,全市场都知道英伟达和联发科在搞SoC。苹果新一代的Mac Mini发布后,让越来越多人意识到桌面小型的AIPC的巨大需求和市场潜力。所以,体积和外形上,这个产品很可以。

性能上,FP4下的1PetaFLOPs,虽然不到5090的三分之一,但是如果综合考虑体积和功耗,其实,很好了。当然,硬件上最大的亮点其实是ConnectX芯片。因为毕竟是期货,英伟达没有公布实际的网络性能,但是理论上是可以达到400Gbps的机器间互联带宽的。

对标苹果M4 Max能够支持的最大128GB一体化内存。纸面上更强一点的CPU和GPU性能(CPU是联发科的,20核心,超过M4 Max的16核,但初步预测打不过M4 Max。苹果不公布GPU的算力,但是就内存带宽和平时使用对比而言,M4 Max应该不如英伟达这颗GB10)。
所以,GPU性能,互联带宽方面,英伟达的DIGITS可能都会强于M4,内存容量持平,带宽上可能DIGITS更高。性价比上,DIGITS更高,但是,如果就综合应用的生态而言,苹果会强很多。
目前对基于ARM架构的SoC芯片支持最好的系统,只有苹果自家的MacOS。无论Linux还是Windows,对ARM的支持都很差。桌面系统是讲生态支持的,愿意折腾底层的用户全球算下来不会超过500万。即使英伟达通过Orin系列产品已经提供了Linux系统下很好的生态支持,但是要搞定系统部署尤其是错误修复,依然需要较为丰富的Linux系统下的开发经验的。
另外,DIGITS真正的发货时间至少会在5月份以后,而这个夏天,苹果的M5要来了。所以,这个产品是我期待的,但市场空间,我并不看好,更何况,还是期货。
对了,很多公开的较为可靠的信息源已经在说:苹果在重新设计SoC芯片,也在重新设计机器间互联能力,这条路已经很清晰的放在苹果面前。是的,Project DIGITS也没有任何黑科技。
总结
去年初发布的Blackwell架构最大的价值是两个Die的互联,以及GPU间互联的能力。去掉这两项,持续了好几年的摩尔定律逐渐失效的残酷现实就又会摆在我们面前,更可怕的是单芯片而言,纯硬件层面的性价比都没有提升。
2025年开始,对英伟达最大的两个期待是基于Blackwell的大集群(比如那个三万张卡,或者传说中的十万张卡)的真正落地,和已经有些确切信息的下一代Rubin架构。然而,AI应用落地讨论的越多,我们或许会发现,其他基础设施和系统生态等“软实力”方面的约束就越清晰的显露出来。