
过去两年里,我最重要的工作平台就是:Obsidian和excalidraw for obsidian插件。尽管在插件里,已经可以加入AI功能,但是解决方案依然比较复杂。
我不是没考虑过基于Obsidian写一套更适合自己使用的插件,但是在我如今的数据量下,Obsidian基本达到了性能的极限。
其实主要的问题还是来自于:Obsidian是基于文件系统的,闭环系统虽然可以自行开发插件,但是对后端的改造难度还是很大的。
半年前我把目光转向了两套开源替代方案:tldraw和Blocksuite。然而在改写的过程中,tldraw后端功能偏弱,虽然潜力巨大,但开发量也很大;Blocksuite的文档结构比较复杂,同时受到商业版本Affine的影响,每次更新的代码变化都比较剧烈。
我一直相信,随着模型能力的不断提升,很多复杂的开发架构是可以被优化的,当下的“痛点”可能很快就会因为模型能力增强而被解决。所以,整整半年多的时间一直在这样一种内耗中:当下考虑的这种解决方案是不是值得花费时间去实现,还是等别人来实现。
然后,就在年尾,“幸福”来了:tldraw computer。
AI时代,我们所需要的就是一张空白的Canvas。这个观点正在得到越来越多人的认可,越来越多的产品也正在向这个方向靠拢。
可是,毫无疑问,是在Gemini 2.0推出后,这个“可能”才真正落地下来了:
1、我们需要一个模型可以真正处理各种模态,完成各种不同的任务; 2、我们需要在这样的模型后台的基础上,把交互做的简单、漂亮、高性能;
第一项,输入Google DeepMind的功劳,第二项,属于tldraw团队的功劳。
一个简单的例子截图如下:
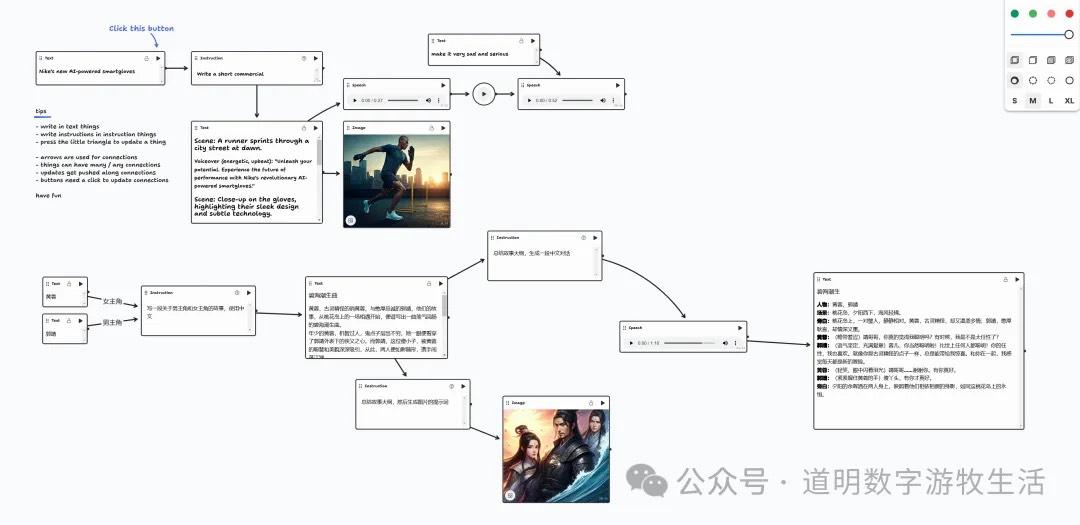
故事生成-->图片生成-->音频解说-->音频文字稿。
自从去年的ComfyUI开始,我用过很多低代码AI工具,但是没有任何一个可以做到如今的tldraw computer一样,既强大,又简单。
1、如上所述,各种模态都有; 2、模型不需要任何配置,直接使用; 3、所有的组件都不需要调整参数; 4、组件类型很简单,五种:提示词、文本、图像、音频,以及流程控制;
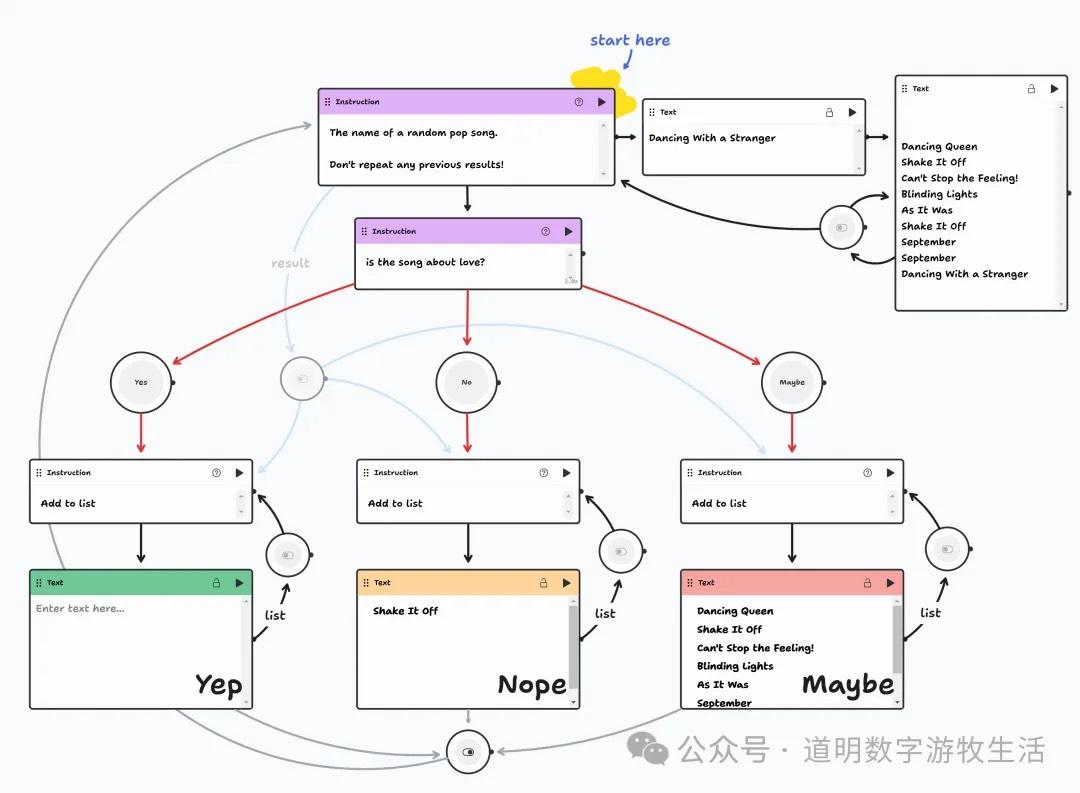
对于这样的循环+分支流程也能完美解决。
还有,Claude3.5最强的功能:Artifacts。
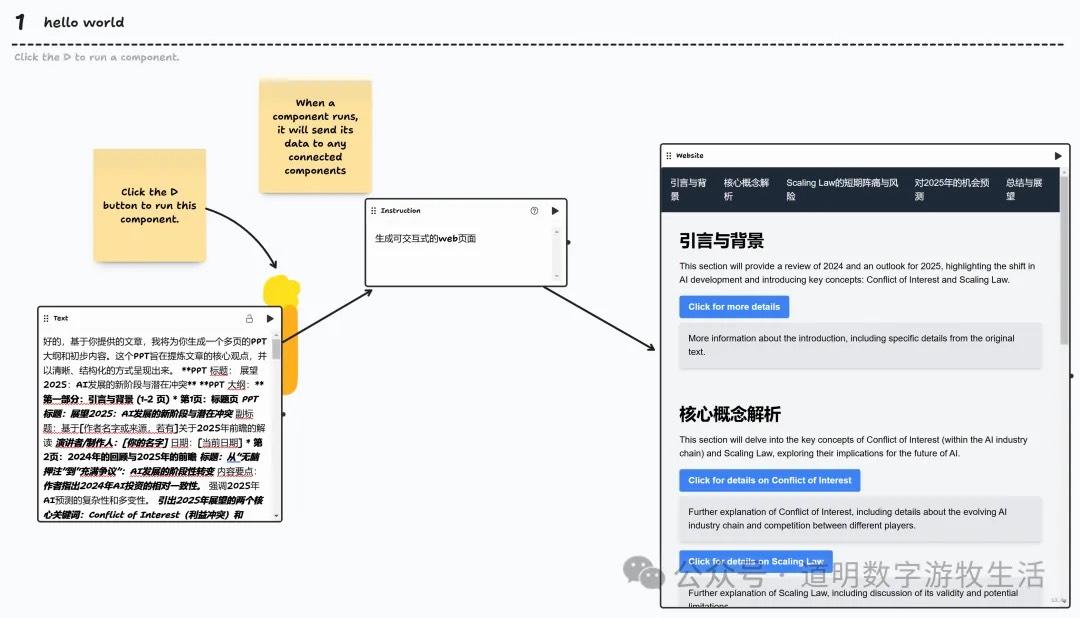
上图右边是直接生成的网页式的ppt:Gemini 2.0负责了代码。
好了,我要去试试让模型跟模型下棋了。
这是,目前为止,在我的应用领域,最完美匹配的AI工具。
我也相信后面会有很多令人兴奋的更新:
1、代码开源:tldraw本身就是开源的,我相信当这个实验性的工具开始成熟后,开源代码是大概率事件; 2、支持跟embed的交互:tldraw支持一系列embed,打通之间的数据流,就“完美”了;

3、语音或者对话框交互:如果连手动画组件和拖拽的步骤都少了,通过对话,直接生成复杂流程,那就“超神”了。
上面的,不难。
感谢Google DeepMind的Gemini 2.0,不仅仅是模型能力,各种模态API都开放,而且,还免费。