In fact, I have been preparing the outlook for 2025 since the beginning of November.
Unlike the situation in 2024, which involved almost mindless betting, predictions for 2025 will be highly controversial, regardless of the specific point being discussed.
To expand on this, I believe the structure will not be parallel as before, but hierarchical. When I look back at the various points I've written down over the past two months, two keywords first come to mind.
Conflict of Interest, and, Scaling Law.
The first term may cause some confusion, while the second seems to have been discussed quite a bit recently, along with much controversy.
So, let's first explain the first keyword: Conflict of Interest.
When ChatGPT was released, or during the "brute force" pre-training stage, the market found an industry chain opportunity: NVIDIA supplies GPUs, model developers like OpenAI provide model services (whether applications or APIs), and Microsoft, through its "forward-looking" stake in OpenAI, took advantage of its proximity to launch services like Copilot. Subsequently, chip foundries, HBM memory, optical communication, and servers—a whole series of industry chain companies—benefited. This was the story throughout 2023, with high prosperity continuing for some companies in 2024.
Although more and more people question whether NVIDIA has captured over 90% of the "AI-driven revenue," no one can deny that the number of companies "benefiting from AI" remains vast; this is the universal benefit of the industrial chain.
The most important reason behind this is that in the first phase, the vast majority of AI investment was in hardware, where a clear industry chain could be identified and benefits distributed across it.
However, by 2024, or more accurately starting from the second half of 2024, as the focus of AI shifted from hardware to software and from computing power to model implementation, conflicts began to surface (though the icebergs below the surface had long existed).
- We see large cloud providers snatching up NVIDIA GPUs while simultaneously supporting AMD and, more importantly, intensifying efforts to develop in-house chips (which is why we believed Broadcom would continue to benefit since mid-year). Conversely, NVIDIA is also revealing its "ambition" to enter cloud services.
- OpenAI is constantly releasing new features. Even though ChatGPT is already one of the top eight super-apps globally in terms of user count, it still needs to expand into areas like search (SearchGPT) and productivity (the goal of Canvas). These are areas where Microsoft originally hoped GPT models would "empower" its own products. In turn, Microsoft is strengthening its own model development (e.g., the open-source Phi) and independent products (Copilot, Github Copilot—while they use the latest GPT models, switching to whatever model is best isn't difficult), aiming to consolidate its "productivity tool" territory. The market is smart; since 2024, among the "Magnificent Seven" (excluding NVIDIA and Tesla), Microsoft's stock performance has been the weakest, failing to sustain its 2023 momentum.
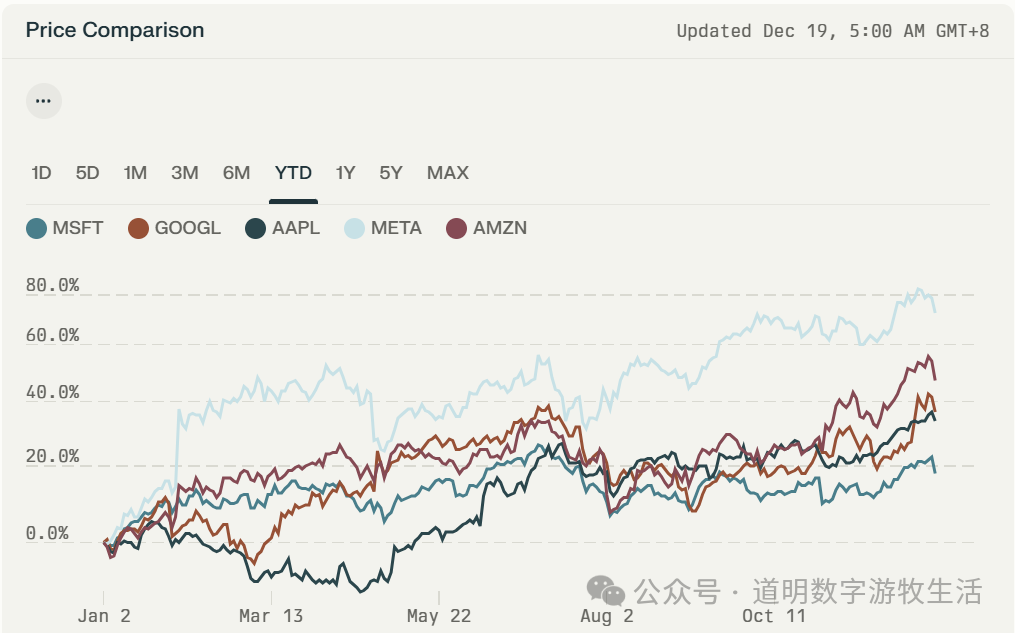
This may not represent the market fully pricing in the Conflict of Interest, but the somewhat lackluster performance of Microsoft's products is certainly influenced by it.
- Cloud providers vs. SaaS companies. Those familiar with my work know that throughout 2024, I have been more optimistic about the performance of cloud providers and SaaS companies. I summarized that for AI implementation, the domestic focus is hardware, while the overseas focus is software. Since Q3, SaaS companies have delivered "stellar" financial reports. The AI transformation of enterprises is a long-term trend, and both cloud and SaaS will benefit in the long run. From a trend perspective, this is just the beginning. However, from the perspective of technical evolution and changes in industry landscape: AI models provide a great opportunity to unify software stacks. Furthermore, if the most critical driver of the software industry is "AI as a Service," then cost will be the most important consideration for enterprises. In such an environment, intensified competition and concentration at the top are almost inevitable: Salesforce is transforming into AgentForce, refusing to be limited to CRM; it is not difficult for Snowflake and Databricks to penetrate from data mid-platforms to the front end; Cloudflare’s Workers can theoretically do much more than system deployment and security. In the AI era, isn't the point that an enterprise can spend two cents to do what used to cost three or four? Moreover, the major cloud providers sitting on cloud hardware infrastructure also have reserves in the software service segments mentioned above.
There is a series of other Conflicts. While coopetition has always been the main theme of the tech industry, the pendulum is swinging rapidly toward the "competition" side because the expansion boundary of "software" is larger than "hardware"—theoretically, it is "boundless."
Keyword Two: Scaling Law.
Yes, there is currently at least one mainstream view: if models cannot demonstrate greater progress in 2025, optimism about AI may suffer a major setback. The biggest technical doubt behind this is: is the Scaling Law still effective?
In fact, from an algorithmic perspective, it has always been an alternating iteration of "greedy methods" and "optimization algorithms," driven by the cycles of hardware progress and data accumulation. Every few years or even every decade, hardware accumulates massive progress and lower costs, and data accumulates in large quantities, making the "greedy method" a viable option. After the "greedy method" exhausts the potential of hardware and data in a short time, optimization algorithms like "backtracking" become mainstream. The alternating progress of hardware and software basically stems from this.
Therefore, in a "broad" sense, the Scaling Law has always driven progress in information science. The idea that the "Scaling Law has failed" is essentially a false proposition.
However, because we are waiting for larger-scale computing clusters (such as the 100,000-card Blackwell cluster) and more data, it is a basic fact that GPT-type models based on the Transformer architecture cannot scale temporarily. This is not a failure of the Scaling Law, but rather that the foundational conditions need time to be prepared.
In this process, choosing algorithm optimization and strengthening post-training becomes more appropriate.
During this period, there will be two points of short-term pain:
- Data needs time to accumulate (or be generated), and computing clusters need time to be built. These require massive capital and energy investment. For model developers, the outcome of the investment is optimistic, but for investors, visibility is dropping rapidly.
- Because models are being optimized in other areas, ordinary users will not be able to intuitively perceive the improvement in capabilities brought by model upgrades. Thus, terms like "ability to think," "better math," and "stronger programming" become increasingly abstract to more people.
This probably explains why I have insisted since the beginning of last year that "AI's opportunity lies in ToB, not ToC": we may be able to deploy billions or even tens of billions of Agents, but we cannot expect this generation of AI to have billions of "human daily active users" like social networks.
After the two keywords, there should be several predictions about opportunities. However, before the predictions, I want to talk about the issue of risk.
Although the allure of AGI is so great that no amount of capital investment is too much, and although technically, investing in larger clusters of computing power and data along the transformer architecture remains the most certain path to AGI, as the technical pendulum swings toward algorithm optimization, the short-term pain points mentioned above will become a non-negligible risk event in 2025:
Model progress is no longer explicit; pre-training costs are too high (not just for hardware, but more importantly for energy and data preparation time); and the choice of cheaper inference hardware (such as edge devices) during large-scale deployment will cause the market to re-evaluate the investment logic that has lasted for two years. In fact, NVIDIA's stock performance over the past six months has already illustrated this issue, but for compliance reasons, I will not expand on it here.
One last sentence about risk: this risk is not a low-probability event, it will not happen late, and of course, it will not last too long.
Having warned about the risks, let's move to the third part, which may be the part many are most concerned about: predictions.
In the past period, I have written five articles on four challenges. In my view, these are both challenges and part of the predictions regarding opportunities:
- AI Challenge 2025 (1): AI Programmers, inspired by bolt.new
- AI Challenge 2025 (2): AI Search, Android itself might disrupt Google Search
- AI Challenge 2025 (3): Education, a topic spanning 20 years
- AI Challenge 2025 (4a): Data Sovereignty and Control, do we need a new "Wubi Input Method"?
- AI Challenge 2025 (4b): Is the "Data Wall" really the main reason hindering model progress?
Indeed, discussing point by point, they are roughly as follows:
- Currently, the most suitable application areas for models are education, frontier scientific research, and biomedicine.
- Why do I always believe that generative AI can change almost all industries? My greatest confidence comes from the programming capabilities of models. Since almost all industries are now inseparable from software, the industry transformation brought by AI programmers will surely exceed the digital wave. Fundamentally speaking, the so-called AI Agent is actually an AI programmer.
- The two major factors restricting model development are energy and data. Regarding energy, if both ESG and efficiency are considered, small nuclear power plants are indeed the best medium-term solution. In contrast, whether for model training or implementation, the "lack of data" is less intuitive than the "lack of energy" but more "painful." From data collection and generation to storage, retrieval, processing, and security, the world of "human-machine coexistence" is a world of data, far larger than the world of "Big Data."
- If there is anything else to expect from the models themselves in 2025, Spatial Intelligence probably ranks first. it is not only the foundation for autonomous driving and humanoid robots but may also be one of the key keys to "human-like intelligence."
- On the edge side, the AI-fication of both phones and PCs needs to expand scenarios. I have always looked forward more to PCs and phones becoming the processing core of AI hardware rather than being the AI "device" themselves; wearable AI represents a change in underlying logic.
- 2025 may very likely become the inaugural year of "Intelligent Computing": the total computing demand for inference will exceed that for training. Models that can be used in various production and living environments will no longer be scarce. Considerations of total cost of ownership (TCO, energy consumption, battery life, portability, etc.) will bring about a demand for diverse hardware forms. Self-developed chips and edge computing power have already emerged, and this high prosperity will continue.
- The biggest trend was written in an article I wrote some time ago: Hardware--, Software++, Intelligence##. Again, as the cycle's pendulum swings toward software and algorithms: the technical level becomes increasingly interesting because we can build everything from a blank canvas, while investment becomes increasingly elusive because who can clearly define boundless competition?