其实,自从进入十一月以来,就在准备关于2025年的前瞻。
不同于2024年几乎无脑押注的情况不同,对于2025年的预测,无论是哪一个点,其实都会有很多争议的。
一点点展开,我想结构不会是跟以前一样的平行的,而是层次性的。当我回看自己在过去两个月里写下的各种要点时,首先想到的是两个关键词。
Conflict of Interest(利益冲突),以及,Scaling Law(规模法则)。
第一个词可能会引起很多疑惑,第二个词则似乎最近讨论的有点多,争议也有点多。
所以,先解释第一个关键词:Conflict of Interest。
在ChatGPT发布的时候,或者说在“大力出奇迹”的预训练阶段,市场找到了一个产业链的机会:英伟达供应GPU,模型开发商例如OpenAI等提供模型服务(无论是应用还是API),微软因为“前瞻性”的入股OpenAI,近水楼台先得月的推出了Copilot等一系列服务,然后芯片代工,HBM内存、光通信、服务器,一系列产业链公司纷纷受益。这其实是贯穿2023整年的故事,部分公司在2024年高景气持续。
尽管越来越多的人质疑英伟达吃掉了超过90%的“AI带来的收入”,但是到目前为止,谁也不能否认“受益于AI”的公司依然是数量众多的,这是产业链的普惠。
背后最重要的原因,在于第一阶段的AI投入绝大多数都是硬件投入,能够清晰的找到产业链,并且普惠到整个产业链。
而到了2024年,或者更准确点讲是2024年的下半年开始,当关于AI的关注重心逐渐从硬件转向软件,从算力转向模型落地时,冲突开始浮出水面(其实海平面下的冰山早就存在了)。
- 我们看到了大型云厂商一边抢英伟达GPU,一边扶持AMD,更重要的是,都在加大力度搞自研芯片(所以为什么我们从年中开始就认为博通会持续受益);反过来,英伟达也在不断显示出搞云服务的“野心”;
- OpenAI不断在发布新功能,尽管ChatGPT已经是全球用户量排名前八的超级APP,但是依然需要不断去拓展类似于搜索(SearchGPT)、办公(Canvas的目标)等功能,而这,本来应该是微软希望GPT模型给自家产品“赋能”的领域;反过来,微软则在不断加强自家模型(例如开源的Phi)、独立产品(Copilot,Github Copilot,虽然都用到GPT最新模型,但是哪家模型好换哪家也不是什么难事)的研发,希望不断“巩固生产力工具”的领地;市场是很聪明的,2024年至今,在除去英伟达和特斯拉的剩余五家巨头公司中,微软股价表现是最差的,2023年的动能并没有能够持续;
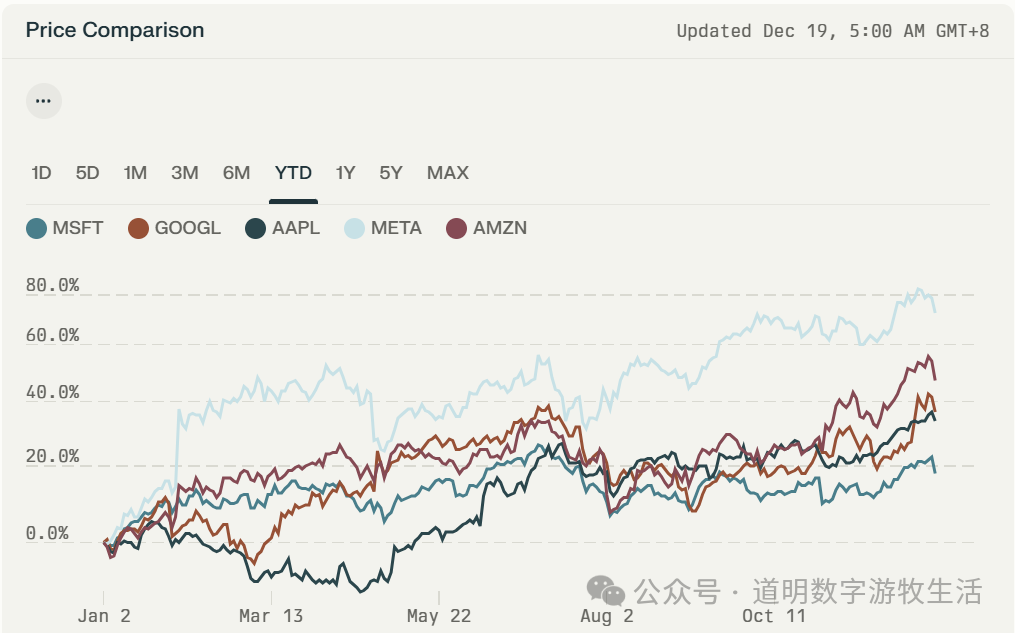
这未必代表市场充分定价了Conflict of Interest,但是微软产品某种程度上的“拉垮”也必定受此影响;
- 云厂商与SaaS公司。熟悉我的人都知道,在整个2024年,我都是更看好云厂商与SaaS公司的表现,我也总结过,AI落地,国内看硬件,海外看软件。三季度开始,SaaS公司纷纷交出了“亮眼”的财报,企业的AI转型是个长期趋势,云和SaaS都会长期受益,从趋势上看,这才开始。但是从技术演变和行业格局变化看:AI模型提供了很好的打通软件栈的机会,同时如果软件业的最重要关键驱动力是“AI as a Service”,那么成本就会是企业最重要的考量。在这样的环境下,竞争加剧和头部集中几乎成为必然:Salesforce转型成AgentForce,何必局限于CRM;Snowflake与Databricks从数据中台进一步向前台渗透也不是难事;Cloudflare的Worker理论上当然可以做除了系统部署、安全之外更多的事情。AI时代,不就是企业可以花两分钱做到三分甚至四分以上的事情吗?何况,坐拥云硬件基础设施的几大云商,在上面提到的软件服务的细分领域,其实也都有储备;
还有一系列的Conflicts,虽然竞合关系一直是科技行业的主旋律,但是钟摆正在迅速摆向“竞争一端”,因为相比于“硬件”,“软件”的可扩张边界更大,甚至理论上,是“无边界”的。
关键词二:Scaling Law。
是的,目前至少有一种主流观点是:如果2025年,模型不能展现出更大的进步,那么对于AI的乐观情绪可能会遭遇巨大挫折。背后来自技术方面最大的疑问就是:Scaling Law是否依然有效?
其实,从算法层面看,一直是“贪心法”与“优化算法”的交替迭代,背后是硬件进步和数据积累的周期使然:每隔三五年甚至十年,硬件都会积累巨大的进步和更低的成本,数据也会大量积累,“贪心法”就成为有效选项;而在“贪心法”短时间挖尽硬件和数据潜力后,类似于“回溯法”之类的优化算法就成为主流。硬件与软件的交替进步也基本源于这样的原因。
所以,从“广义”而言,一直是Scaling Law在主导着信息科学领域的进步,“Scaling Law失效”根本上就是一个伪命题。
但是因为要等待更大规模的算力集群(例如十万张卡的Blackwell集群),要等待更多的数据,基于Transformer架构的GPT类模型暂时无法Scaling也是基本事实,但这不是Scaling Law失效,而是基础条件需要时间才能准备好。
在这个过程中,通过算法优化,通过加强后训练,就成为更合适的选择。
而在这个过程中,会有两个短期阵痛的点:
- 数据需要时间积累(或者生成),算力集群需要时间搭建,这些都需要巨大的资金和能源投入,对于模型研发者而言,投入的结果是乐观的,但是对于出资者而言,能见度却快速下降;
- 因为模型都在其他方面进行优化,普通用户将无法直观感知到模型升级带来的能力提升,所以,所谓的“会思考”、“数学更好”、“程序能力更强”,对于越来越多的人而言,也变得越来越抽象;
这大概也解释了,为什么我从去年一开始就坚持“AI的机会在ToB,而不在ToC”:我们可能可以部署几十亿甚至几百亿的Agent,但是我们却不能指望这一代的AI会如社交网络一样,拥有几十亿的“人类日活”。
两个关键词后,对应的应该是关于机会的若干预测,但是,在预测之前,还是想说一下风险的问题。
虽然AGI的吸引力大到投入再多资本都在所不惜,虽然从技术层面而言,沿着transformer架构,投入更大的集群算力和数据,依然是通向AGI确定性最强的道路。但是在技术钟摆开始摆向算法优化时,上面所说的短期阵痛点会成为2025年一个概率不会太小的风险事件:
模型的进步不再显性,预训练过高的成本(并不只是购买硬件,更重要的是能源、数据的准备时间),模型大规模部署时选择更廉价的推理硬件(例如端侧)等,都会让市场重新评估持续了两年的投资逻辑。其实,过去半年以来英伟达的股价表现已经很说明问题了,不过出于合规考量,本篇不再展开了。
关于风险的最后一句话,这个风险并非小概率事件,发生的时间也不会太晚,当然,持续的时间也不会太久。
提示完风险,进入第三部分,也可能是很多人最关心的部分:预测。
在过去一段时间,我曾经写了五篇四个挑战,这些,在我看来,既是挑战,更是关于机会的预测的一部分:
- AI挑战2025之一:AI程序员,由bolt.new想到的
- AI挑战2025之二:AI搜索,颠覆Google搜索的也许是安卓自己
- AI挑战2025之三:教育,一个贯穿了20年的话题
- AI挑战2025之四(上):数据自主可控,我们需要新的“五笔输入法”吗?
- AI挑战2025之四(下):“数据墙”真的是阻碍模型进步的主要原因吗?
是的,如果一点一点的讨论,大概是:
- 目前模型比较合适的应用领域大概就是教育、前沿科学研究和生物医药;
- 为什么我始终认为生成式AI可以改变几乎所有的行业?最大的底气就是来自于模型的程序能力,既然现在几乎所有行业都离不开软件了,那么AI程序员能够带来的行业变革也一定超过数字化浪潮:从根本上讲,所谓的AI Agent,其实就是AI程序员;
- 制约模型发展的两大因素,一是能源,二是数据。能源方面,如果同时考虑ESG与效率,小型核电站确实是中期最佳解决方案;相比之下,无论是模型训练还是模型落地,“缺数据”虽然不如“缺能源”那么直观,却更“痛”:从数据采集与生成,到数据存储,到数据检索,到数据处理,到数据安全,“人机共存”的世界,就是数据的世界,远远大于“大数据”的世界;
- 如果说2025年对模型本身还有什么期待的话,空间智能大概可以排在首位;它既是无人驾驶和人型机器人的基础,也可能是“类人智能”的关键钥匙之一;
- 端侧,无论手机还是PC的AI化,都需要拓展场景,我可能一直都更为期待PC和手机成为AI硬件的处理核心,而不是AI“XX”本身;可穿戴AI,底层逻辑的变化;
- 2025年或许真的非常有可能成为“智能计算”的元年:推理的总算力需求将超过训练,可以用于各种生产生活环境的模型不再稀缺,对综合成本(TCO、能耗、续航、便携性,等等等等)的考量带来硬件形态多样性的需求,自研芯片、端侧算力已经展露头角,这种高景气还将持续;
- 最大最大的趋势,写在我前段时间的一篇文章里:硬件--,软件++,智能##。还是那句话,当周期的钟摆向软件和算法摆动时:技术层面变得越来越有趣,因为我们可以从一张空白画布(canvas)开始构建一切,而投资上变得越来越难以捉摸,因为无边界的竞争,谁又能说地清楚呢?