When I stop to systematically think about the challenges AI will face in 2025, "Search" might be the most difficult topic to write about. Over the past month, I have even written several pieces attempting to envision the vast future and disruptive changes of "AI Search."
However, I found that when following this conclusion, I would hit a point where things just "came to a sudden halt." Thus, I tried a different direction, starting from a full-text search sub-project in a large project twenty years ago, trying to find the true meaning of search's existence.
Indeed, the earliest term for a search engine was "full-text retrieval," similar to the process of querying a so-called paper database based on time, scope, and keywords to return matching paper results.
Therefore, the demand for search from the beginning has been to obtain information from a knowledge base. This knowledge base might be a content website or a search engine we are already very familiar with.
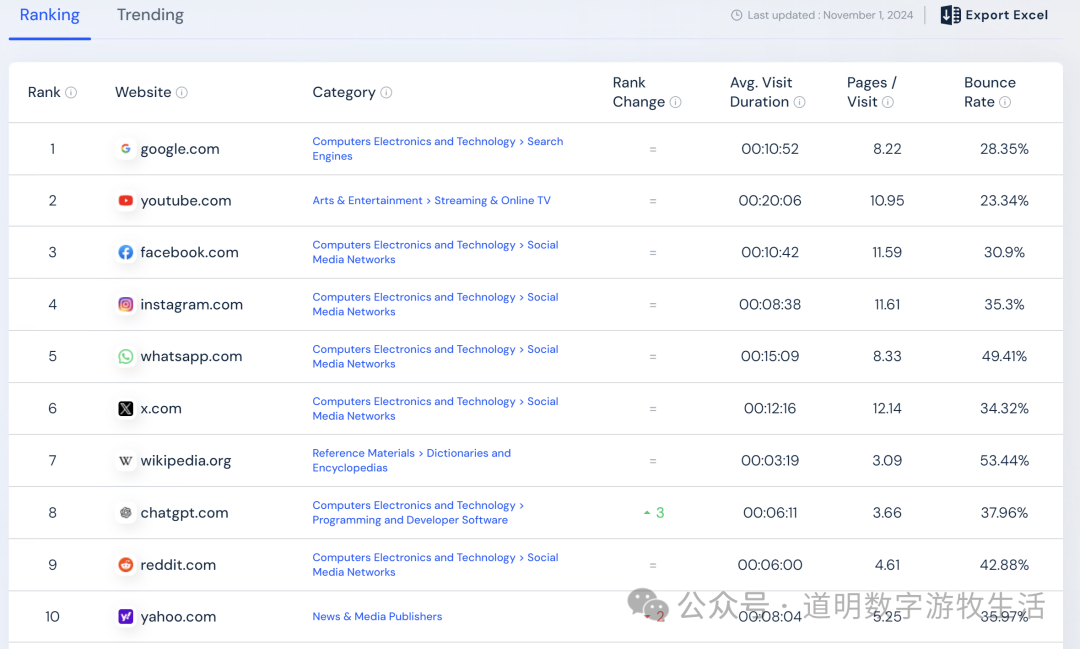
A good search engine naturally requires sufficiently complete data, more accurate search algorithms, and faster search performance. These three points remain true today.
Data sources mainly come from three aspects: the content websites providing the service themselves, telecommunications operators, and web crawlers. In theory, telecommunications operators should possess the most complete network data, but due to conflicts of interest, organizational structures, and genetic issues, history has proven they do not have the conditions to become reliable search engines. Content websites themselves can perform site-wide searches well, but the lack of data prevents them from scaling up.
Crawler-based success naturally belongs to the dominant Google. Of course, everyone knows that the most important factor behind Google Search's success is the advertising revenue brought by its business model. In such a virtuous cycle: more R&D investment can be used to improve search algorithms, and there can be better infrastructure investment and scale effects to improve search performance, reduce search costs, and increase ROI. When competitors cannot form a virtuous cycle, Google's monopoly becomes stronger, the product gets "better and better," and it becomes increasingly difficult for competitors.
Another secret everyone knows is: Traffic.
It is precisely "traffic" that determines that even now, with ChatGPT's monthly active users exceeding 200 million and ranking as the world's eighth-largest website according to Similarweb statistics—having played the role of the "hope to defeat Google" for the past two years—it still has not had a significant impact on Google's traffic.
I have always used and am very optimistic about Perplexity (Perplexity redefines search, and ChatGPT is also jumping in!), which, while its activity is growing rapidly, still seems a far cry from the goal of "challenging Google."
Where is the problem?
Data Sources. Taking Perplexity as an example, when it first launched AI search functions, it inevitably had to use a large number of search engine services at the bottom layer, whether from Google or DuckDuckGo in the open-source ecosystem. Of course, there is now a large amount of data based on their own crawlers, but problems arise immediately: First, the economics and coverage of crawlers will certainly not beat Google for a long time; second, they face huge moral and legal risks. Content websites and media outlets will initiate lawsuits against "illegal crawlers." For these content websites and media, a symbiotic relationship has already formed with Google (they rely on traffic brought by traditional search, and Google can accommodate their commercial interests as much as possible during content crawling, such as Reddit). AI search, as it currently appears, effectively cuts off the traffic to these content websites and media.
Business Model. OpenAI is currently trying a new model—content cooperation, such as with Reddit. Perplexity is also working hard to promote cooperation with third parties. Yet, this still doesn't solve the problem: using AI search is more expensive, and content cooperation carried out for legal and regulatory compliance further increases costs. If advertising cannot be loaded, where is the monetization?
In fact, when every new model first emerges, the business model is not very clear. The problem is simply that, so far, the business model concepts AI search can provide seem to have bugs. Therefore, from a demand perspective, it is definitely huge—users need better, more intelligent search—but from a business perspective, none can be found. Thus, Google has only quietly added the AI Overview function, telling the market: AI search is not technically difficult at all.
What is difficult is the data, and the habits.
To illustrate this, I had Claude generate a workflow chart for users when using AI search.
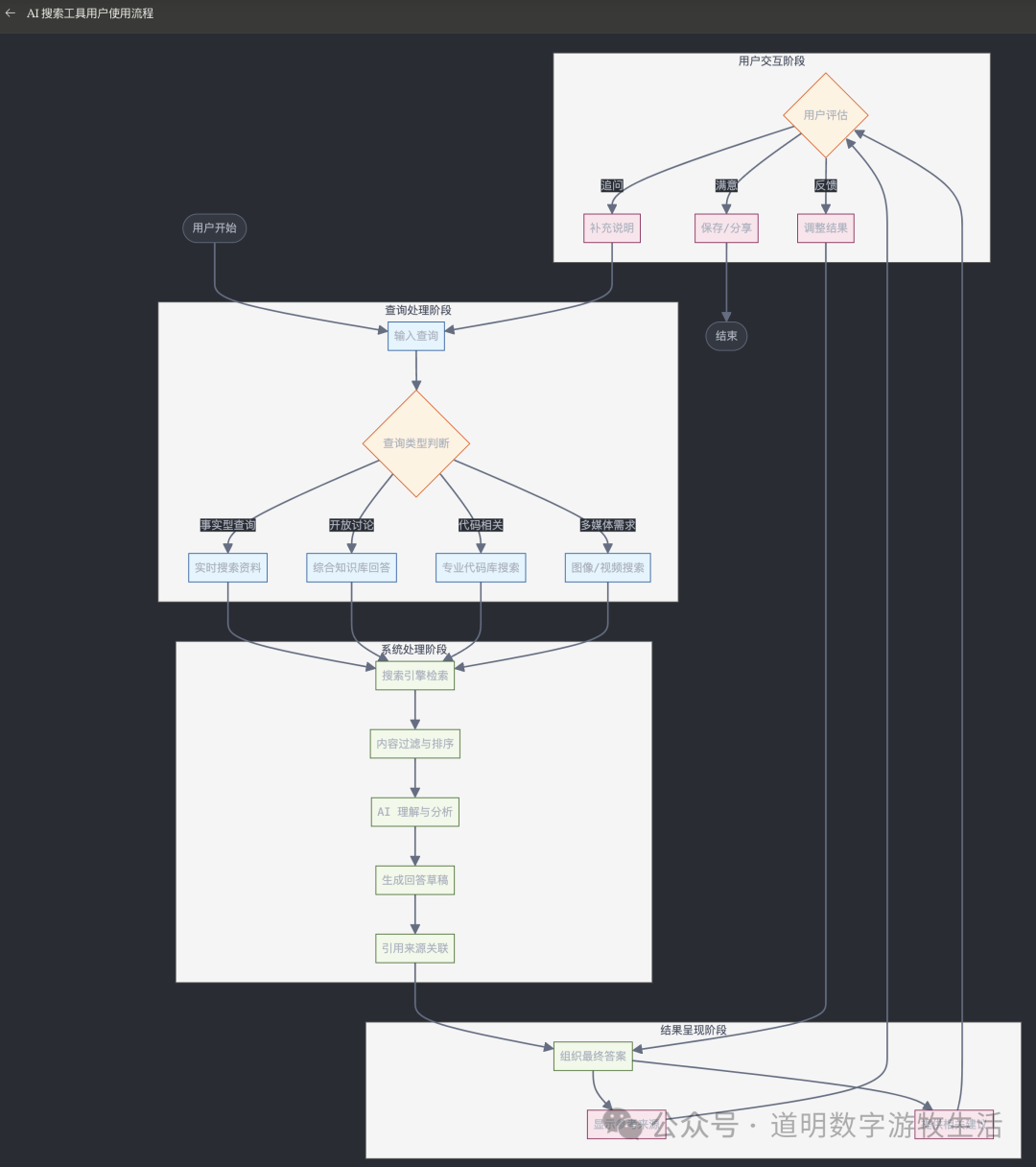
This chart is more complete and accurate than I expected. It also reveals the key issues:
Data. How to retrieve more valuable data;
Hallucination Issues. Under this process, users can have more confidence in the returned results because the biggest "hallucination problem" of generative AI is overcome as much as possible;
Under this workflow, the requirements for model capabilities have dropped significantly. The tasks in the system processing part are mostly parts that current models have basically solved very well;
The model's greatest help is in two points: helping users who are not accurate enough in expression generate better prompts, and summarizing and producing results.
Therefore, AI search has essentially evolved from a "retrieval tool" into a "production tool." The main factor determining quality has become the data, not the model (there are gaps between models, but the gap among current frontier models in these tasks is not large).
Better data leads to better results; the problem comes full circle.
Who has the best data? Currently, it's still Google. Is it unsolvable then?
Cooperating with a few good content providers, crawling as much as possible, and adding more model features around AI search—this is what ChatGPT and Perplexity are doing now.
Perhaps with the passage of time, more and more people like me will migrate more of their search needs to Perplexity or ChatGPT, but time is not on their side. Google is too big and slow to release products, but if challengers give it enough time, Google will eventually build it, and the user experience might even be better.
However, if viewed from the dimension of a "production tool," internet data obtained from search may only be part of the production process. A larger portion might come from the user's own data, or rather, data actively accessed by so-called agents simulating user behavior.
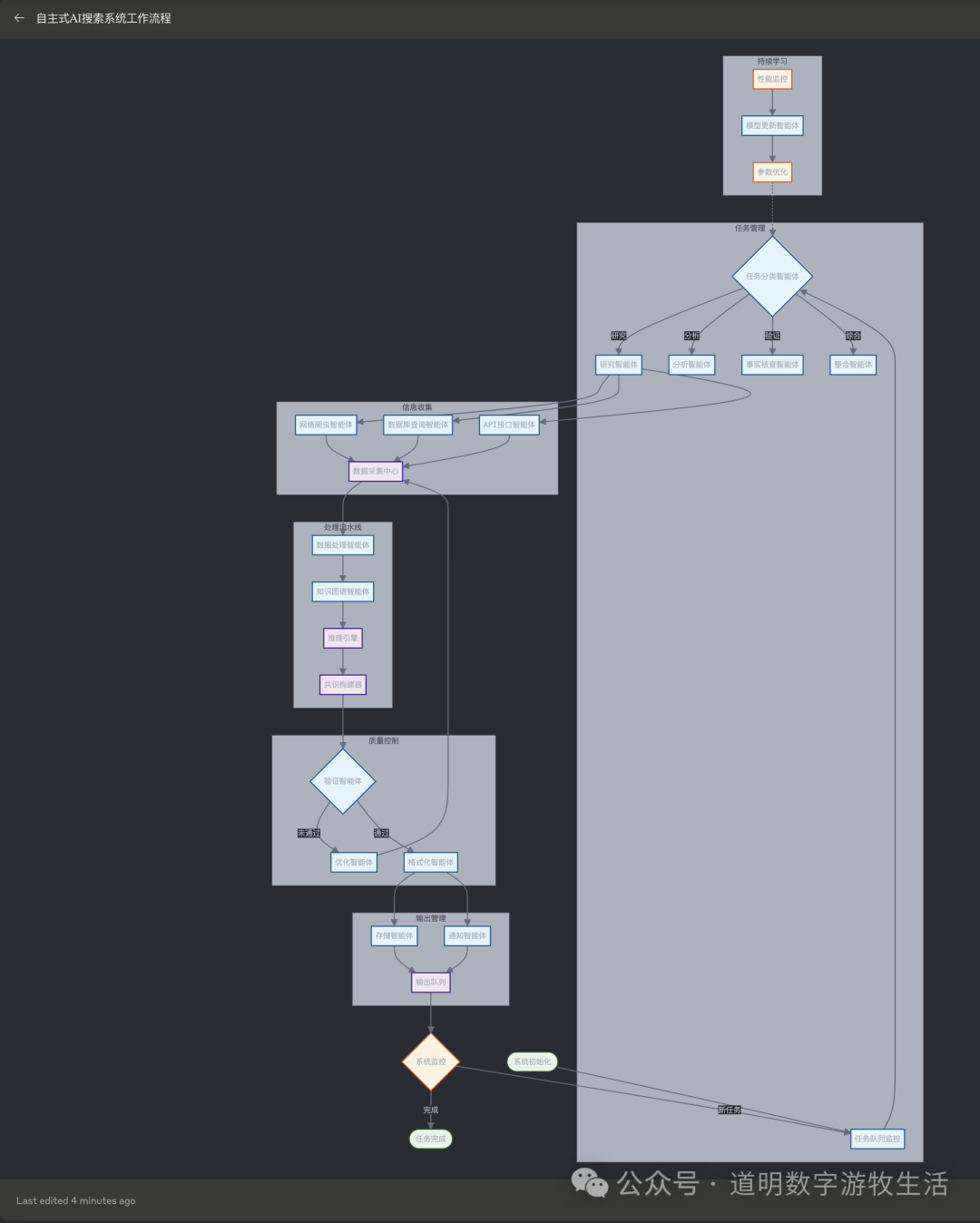
Even, as shown in the flow chart also generated by Claude, the final feedback given to AI search could be from an AI agent, not necessarily a human.
This naturally places higher demands on the model's "intelligence level."
But, assuming model capabilities reach that point (I believe they will gradually do so in the next two to three years), there might be two typical scenarios:
One comes from mobile phones or other devices like PCs, where local data on user behavioral preferences—what Apple AI calls "context"—already exists. This includes lists of websites and apps we daily use for information (including usernames, passwords, or login tokens, saved locally, just as we manually open an app or visit a website to log in automatically). It performs targeted retrieval from specific sources and combines it with local data to complete the entire process from "search to production." It can help us complete many scenario-based tasks; simply put, if there is an upcoming travel itinerary, it wouldn't just be about booking tickets, but providing item lists based on weather, transportation planning, suggestions for food and lodging, sightseeing plans, and so on. It is an agent, but even more so, AI search. I have full confidence this scenario will be realized next year; we just need a trustworthy carrier (while mobile phones aren't perfectly secure, they might be one of the safest among unsafe options).
The other is for daily work and production scenarios. This involves large amounts of local vertical-domain data, or knowledge bases. AI search still retrieves data from specific sources after analyzing local knowledge base data and then combines it with local data to complete work tasks. Is this RAG? Maybe, but more likely not (the RAG issue is quite complex; simply put, from a human perspective it seems necessary, but from the model's perspective it is not, which can be discussed separately later). It seems both ChatGPT and Perplexity are working in this direction: each search actually visits relatively fixed source websites. Currently, search and user data upload functions cannot coexist in one dialogue, but technically this is easy to implement. Then, perhaps, it will support batch user data uploads (like ChatGPT's association with OneDrive, Google Drive, and other cloud storage accounts), and finally, achieve the tasks mentioned above.
In my view, Scenario 1 (software-hardware integration for consumers) is more realistic. Scenario 2 (B2B) certainly has strong business needs, but the key to Scenario 2 lies in the organization of local data or knowledge bases. Anyone capable of doing this well likely has the ability to deploy better open-source models and agents locally.
So, isn't Scenario 1 exactly the Apple Intelligence that Apple keeps marketing? Apple's own model might not be good enough yet, but after integrating ChatGPT, there should be more opportunities to realize Scenario 1.
Similarly, Google is also rapidly transforming the Android system around Gemini. Whether from the perspective of models or data, Google is naturally stronger, but Samsung is also racing down the path of being a "clumsy teammate" (not that Samsung is dragging its feet, but I believe in the AI era, there can only be one center stage for software-hardware integration, and Samsung will not be content just being a hardware manufacturer).
Returning to the point, assuming Google isn't held back, in Scenario 1, search might be everywhere, yet no longer in the form we are used to—opening a search box, entering keywords, and getting a list back.
In the end, it might be Google's own Android + Gemini, along with Apple, that disrupts Google Search.
Switching from charging for search-loaded ads to charging for user services is a very smooth logic, and the financial reports of both companies are constantly reinforcing this logic.
However, this remains a matter of speed. If ChatGPT's features advance quickly enough for users to be willing to "give up private data" again for functionality, it could become the disruptor.
But what if ChatGPT isn't fast enough?
Thinking about it now, no wonder OpenAI deliberately chooses to "pre-emptively release models" every time before Google launches a product. It wants to be fast.