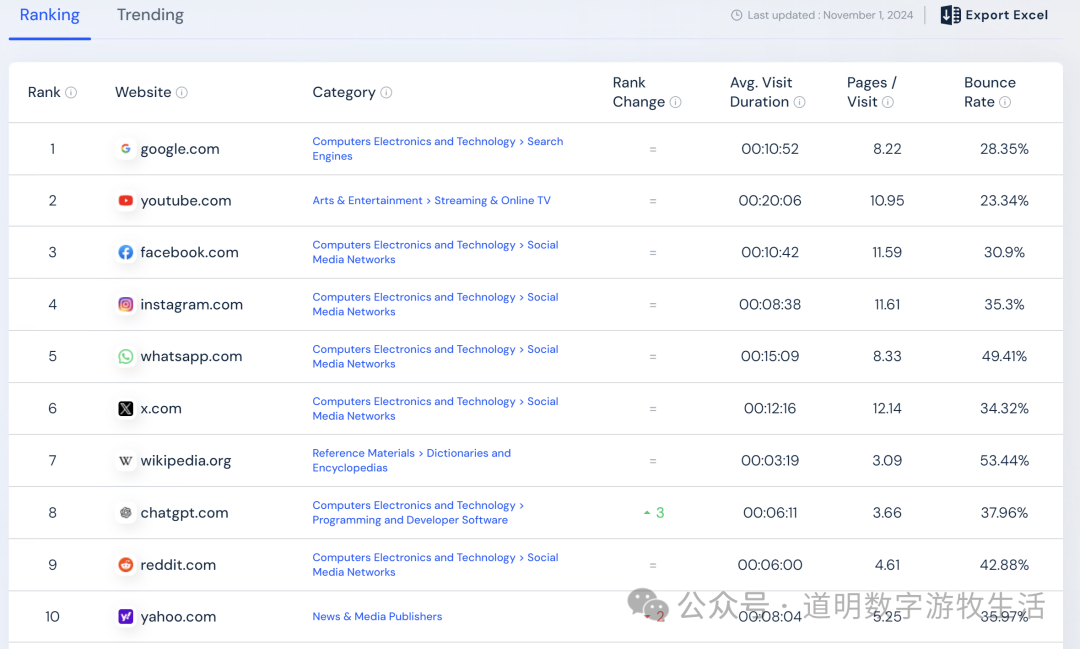
在我停下来系统性的去思考2025的AI要面临的挑战时,“搜索”可能是最难写的一个话题,过去一个月,我甚至写了好几篇想去展望“AI搜索”的广阔未来和颠覆性改变。
可是,我发现,当顺着这个结论去考虑的话,也会出现到某个点就“戛然而止”的感觉,于是,我尝试换一个方向,从二十年前,我们大项目里的一个全文搜索子项目开始,试图寻找搜索真正存在的意义。
是的,搜索引擎最早的名词应该叫做“全文检索”,类似于去所谓论文库里根据时间、范围、关键词查询并返回命中的论文结果的过程。
所以,搜索从开始的需求就是从知识库里获取信息。只不过这个知识库可能是一个内容网站,也可能是我们已经再熟悉不过的搜索引擎。
一个好的搜索引擎,自然就需要有足够完整的数据、更精确的搜索算法、更快的搜索性能,这三点在当前依然成立。
数据来源主要是三方面:提供服务的内容网站本身,电信运营商,网络爬虫。理论上,电信运营商应该拥有最完整的网络数据,但是因为利益冲突、组织架构与基因等问题,历史也证明了他们不具备成为可依赖的搜索引擎的条件;内容网站本身做站内检索还可以,但缺数据问题使得无法做大。
基于爬虫的最成功的自然就是一家独大的Google。当然,谁都知道,支持Google搜索成功最重要的是商业模式带来的广告收入。在这样的良性循环下:可以用更多的研发投入去提高搜索算法,可以有更好的基础设施投入和规模效应去提升搜索性能,降低搜索成本,提高ROI。当竞争者无法形成良性循环时,Google的垄断性就变得越来越强,产品“越做越好”,竞争者越来越难。
同样谁都知道的秘诀就是:流量。
也正是“流量”决定了即使到现在,ChatGPT已超过两亿的月活,按照similarweb统计跻身于全球第八大网站。承担了近两年“打败Goole的希望”的角色,依然没有对Google的流量产生明显的影响。
我一直使用并且非常看好的Perplexity(Perplexity重新定义搜索,ChatGPT也来抢滩登陆!)虽然活跃度也在快速增长,但是似乎离“挑战Google”的目标依然相距甚远。
问题在哪里?
1、数据源。以Perplexity为例,最早推出AI搜索功能时,底层必然要用到大量的搜索引擎服务,无论是Google,还是开源生态下的DuckDuckGo;当然,现在肯定有大量的基于自有爬虫的数据,但是问题就直接来了:首先,爬虫经济性和覆盖度在很长时间内一定做不过Google;第二,面临巨大的道德风险和法律风险。各家内容网站和媒体就会发起对“非法爬虫”的诉讼,对这些内容网站和媒体而言,已经形成了跟Google的某种共生关系(他们要依靠传统搜索带来的流量,Google也可以在内容爬取时尽可能照顾到他们的商业利益,例如reddit)。AI搜索在目前看来等于断了这些内容网站和媒体的流量。
2、商业模式。如今OpenAI正在尝试一种新的模式,内容合作,例如跟Reddit的内容合作,Perplexity也在努力推动跟第三方的合作。可也依然解决不了这样的问题:利用AI搜索成本更高,为了合法合规开展的内容合作也进一步提高了成本,但是如果不能加载广告,那么在哪里变现?
其实,每个新模式刚出来的时候,商业模式都是不太清晰的,问题只是在于,似乎到目前为止AI搜索能够提供的商业模式设想都存在bug。所以,从需求上看,一定很大,用户需要更好的智能化的搜索,但是从商业上讲,却都找不到。所以Google也只是低调的加入了AI Overview的功能,告诉市场:AI搜索技术上根本不难。
难的只是数据,和习惯。
为了说明这一点,我让Claude生成了一张用户使用AI搜索时的工作流程图。
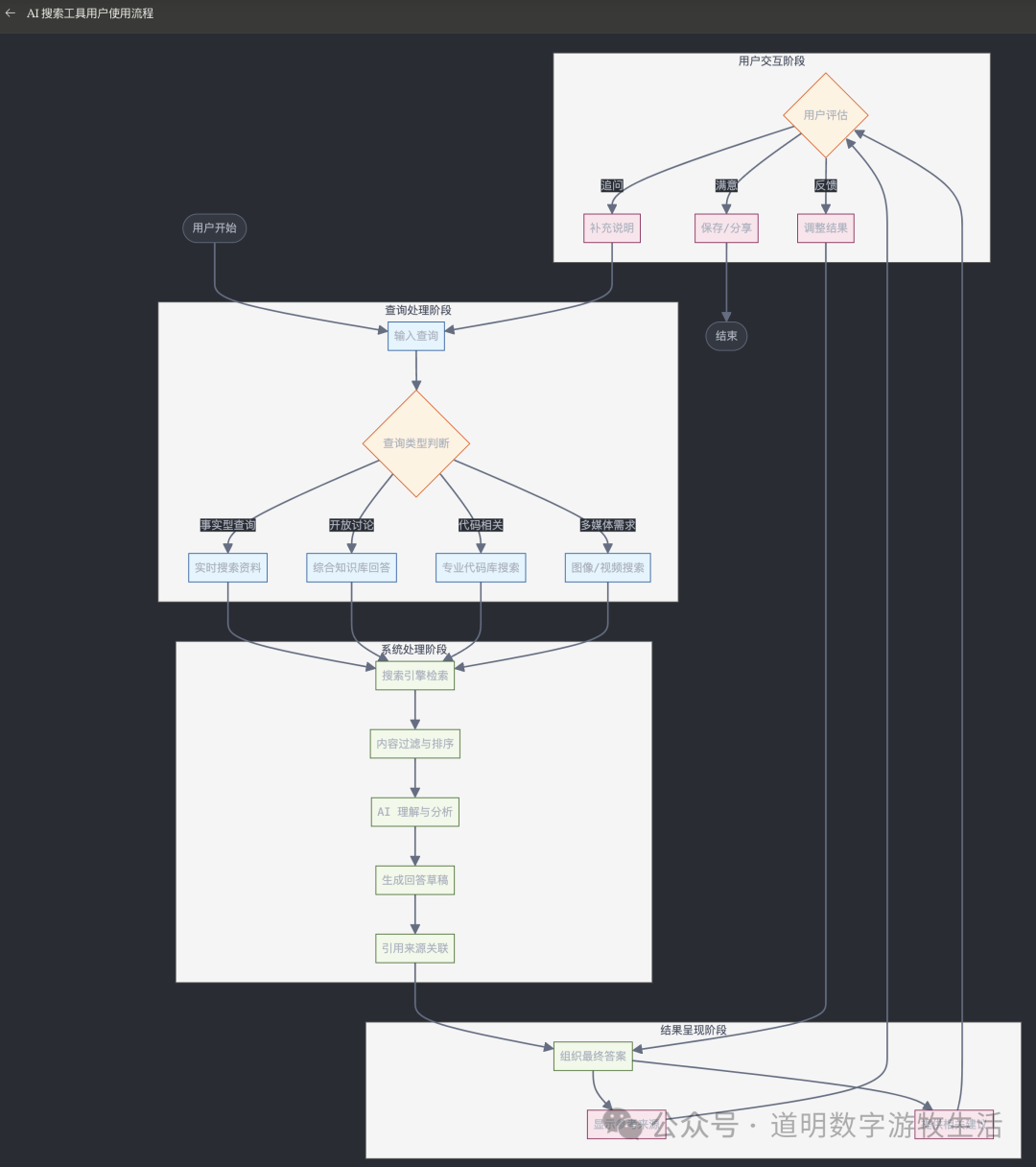
这张图比我预想得更完整,更准确。也更能揭示问题的关键:
1、数据。如何检索到更有价值的数据;
2、幻觉问题。这个流程下几乎也可以让用户对返回结果有更多的信心,因为生成式AI最大的“幻觉问题”被尽可能的克服了;
3、在这样的流程下,对模型能力的要求显著下降了,系统处理部分的任务都是目前模型基本上已经解决的很好的部分;
4、模型最大的帮助在两点:帮助表达不够准确的用户生成更好的prompt;对结果进行汇总,生产。
所以,AI搜索本质上是从“检索工具”成为了“生产工具”,决定质量好坏的最主要因素成为了数据,而不是模型(模型当然有差距,但是现在的前沿模型在这些工作上的差距都不大)。
更好的数据才会有更好的结果,问题又转回来了。
谁有最好的数据?目前还是Google。那无解了吗?
跟几个好内容商合作,能爬的就多爬点,围绕AI搜索加入更多的模型功能。这就是现在ChatGPT、Perplexity等在做的。
也许随着时间的流逝,会有越来越多的人像我这样将更多的搜索需求迁移到Perplexity或者ChatGPT,但是,时间并不站在他们这一边。Google太大了,做什么产品都慢,但是如果挑战者给予足够的时间,那Google最终都能做出来,用户体验可能还更好。
然而,如果从“生产工具”的维度去看,搜索来的互联网数据可能只是生产过程的一部分,更多的部分也许来自于用户自己的数据,或者说,所谓的代理模拟用户行为去主动访问的数据。
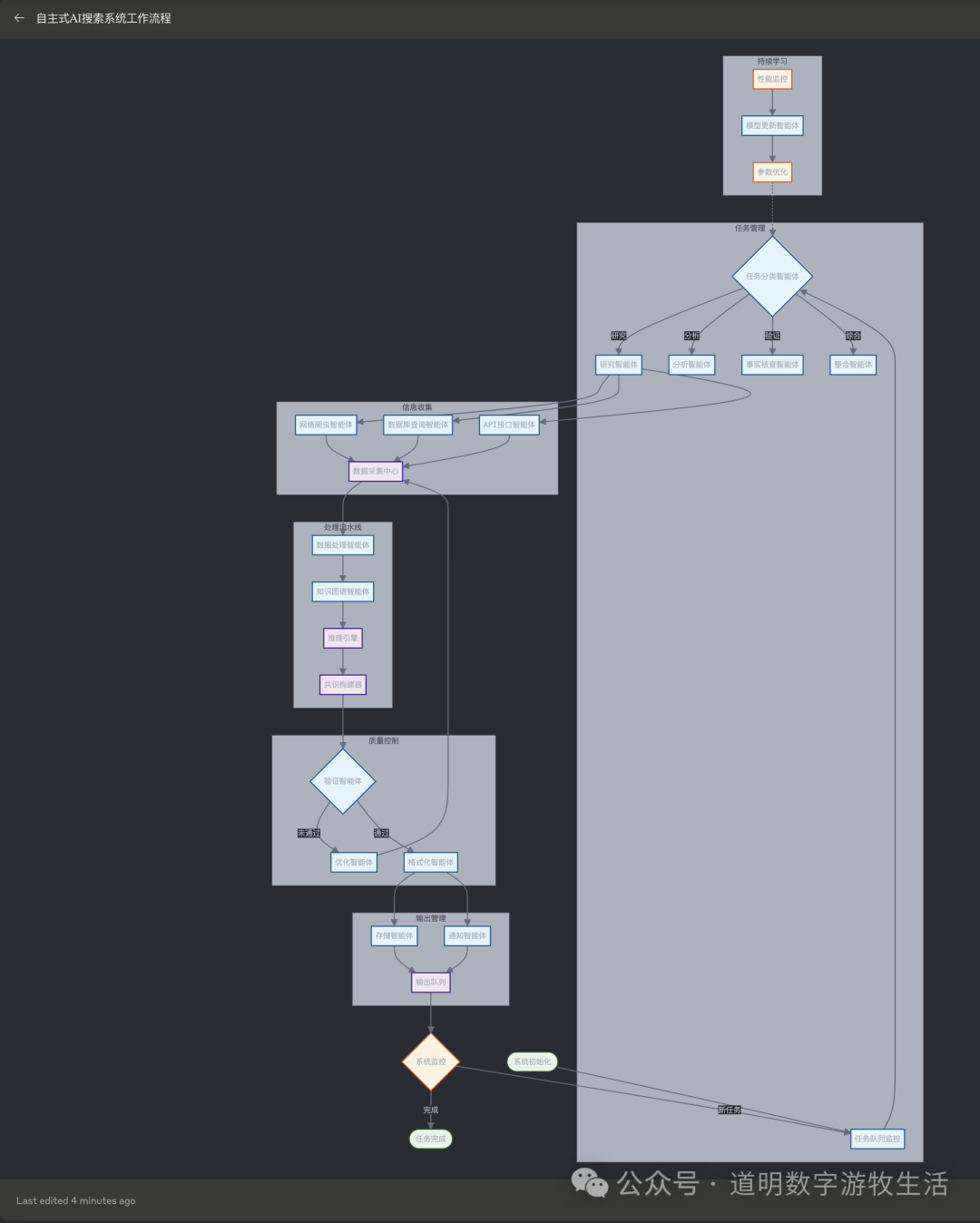
甚至于,如上,在依然由Claude生成的流程图中,最终给予AI搜索反馈的都可以是AI代理,而不一定是人。
这当然又对模型的“智能化水平”提出了更高的要求。
但是,假设模型能力达到了(我总相信这在未来两三年里一定会逐步达到),那么也许就有两种典型的场景:
1、一种,来自于手机或者其他设备比如PC,本地已经有了我们用户日常的行为偏好数据,即苹果AI所说的“context”,有了我们日常获取信息来源的网站列表和APP列表(包括用户名和密码或者登录token,这些在本地保存,正如我们日常手工打开APP或者访问网站自动登录一样)。有目标针对性地检索特定源头,再结合本地数据,完成“搜索到生产”的全过程。它可以帮我们完成很多有场景的任务,简单而言,如果即将有一个外出日程,那么不仅仅是订票,根据天气情况给出物品清单,交通规划,建议食宿,游玩计划,等等。是代理,更是AI搜索。这种场景,我有充分的信心明年就会实现,只是我们需要的是一个可以信赖的载体(虽然手机也并不安全,但可能是所有不安全的方式里最安全的之一了)。
2、另一种,就是面向日常工作生产的场景下。大量本地垂直领域的数据,或者说知识库。AI搜索依然在分析本地知识库数据后有针对性地检索特定来源的数据,然后再结合本地数据完成工作任务。这是RAG吗?也许是,但更可能不是(关于RAG的问题其实蛮复杂的,简单来说,从人的视角看出去似乎需要RAG,但是从模型的视角看出去则是不需要,当然这可以以后单独讨论)。看起来,无论是ChatGPT还是Perplexity都在往这个方向努力了:每次搜索其实访问的来源网站是相对固定的,目前搜索和用户上传数据功能不可以同时在一个对话里,但是技术上这很容易实现,然后,或许就是支持用户批量上传数据(例如ChatGPT的跟Onedrive、Google Drive等网盘账号关联),再然后,就是实现上面所说的任务。
在我看来,我会认为场景1(软硬结合的C端)更现实一点,场景2(B端)当然有很强的业务需求,但是场景2的关键在于本地数据或者知识库的整理,但凡能做好这一点,多数都有能力本地部署更好的开源模型及代理了。
那么,场景1,不就是苹果不断推销的Apple Intelligence吗?也许苹果自己的模型还不够好,但是集成ChatGPT后,应该有更多的机会去实现场景1。
同样,这些,Google也正在快速的围绕Genimi对安卓系统进行改造。无论从模型还是数据上看,当然Google更强,但是三星也正在“猪队友”的道路上狂奔(不是三星拖后腿,而是我认为AI时代,软硬件合体的C位只能有一个,可是三星不会甘心只做一个主机厂商的)。
言归正传,我们假设Google不会被拖累,在场景1里,也许搜索无处不在,却都不再是我们习惯的打开搜索框输入关键词然后返回列表的那种了。
到最后发现,也许颠覆Google搜索的恰恰是自己的安卓+Gemini,还有苹果。
从搜索加载广告收费转变为用户服务收费,这是一个非常通顺的逻辑,两家的财报也不断增强着这样的逻辑。
可是,这依然是一个时间快慢的问题,如果ChatGPT的功能推进的足够快,快到让用户愿意为了功能而再次“放弃私有数据”,那它就可能成为那个颠覆者。
可是,如果ChatGPT不够快呢?
现在想想,怪不得每次OpenAI都会故意挑在Google发产品之前“抢发模型”。它想要,快。