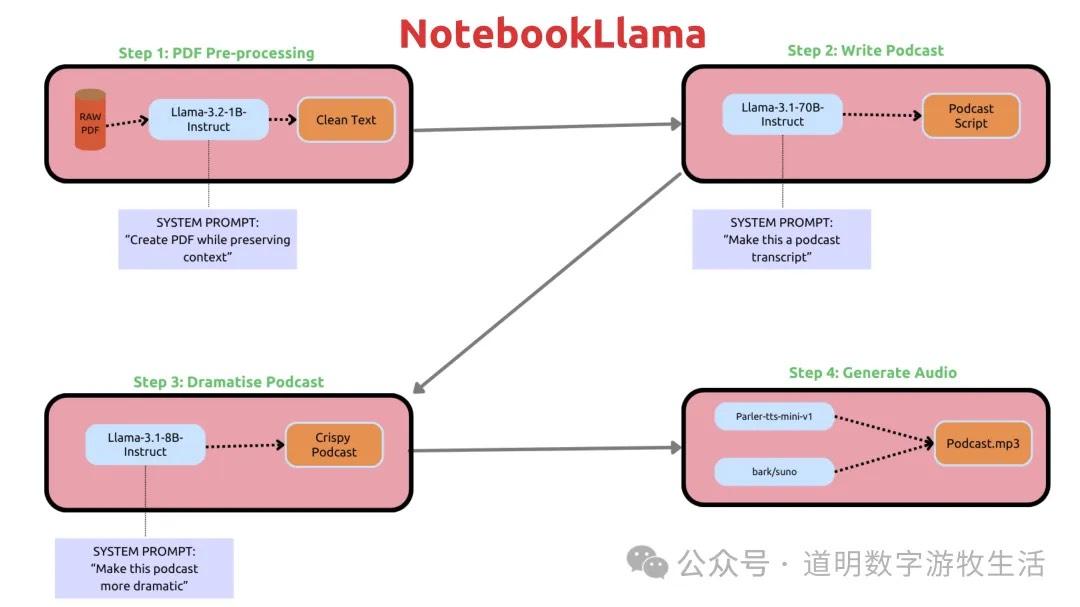
Google的NotebookLM因为能够生成接近真人的半小时Podcast“出圈”后,Meta团队也在Llama Recipes开源代码库下发布了NotebookLlama。
NotebookLlama https://github.com/meta-llama/llama-recipes/tree/main/recipes/quickstart/NotebookLlama
简单来讲,有四步:1、利用LLaMA-3.2-1B-Instruct模型对PDF文档进行预处理;2、使用LLaMA-3.2-70B-Instruct生成Podcast的文字稿;3、利用LlaMA-3.2-8B-Instruct调整文字稿;4、使用parler-tts-mini-v1和suno两个TTS模型生成语音。
效果,当然暂时远不如NotebookLM的,但是至少给了一套完整的全开源,可本地部署的选项。
原版很香,平替也经常有独特的魅力:喜欢即插即用的就直接选择原版,喜欢折腾的就走向平替。终于在智能手机统治了超过十年之后,属于PC时代的多样性快乐又回来了。
诚然,过去半年里,NotebookLM成为我的高频应用:多次帮助我在一周内“啃完”一千页级别的专业书籍,生成各种颗粒度的辅助信息帮助我提升记忆。
可是,我依然认为这类工具离我理想的工作流还有很远的距离。
看到很多人称NotebookLM为“第二大脑”,个人认为这个提法过时了。“第二大脑”更多是帮助整理记忆,作为个人记忆的延申。虽然,现在绝大多数所谓AI工具连这一步都没完成的很好,但是生成式AI的广阔前景还是在创造场景,训练智能,或者,直接“增强大脑”。
当然,从“第二大脑”到“增强大脑”,本身是个递进的关系,工具层面也是如此。虽然还没有任何一个工具真正完美,但各种尝试却给了我们很多的启发。
其中最重要的启发是:我需要自己写一套工具,因为有太多的现成工具可以参考,而生成式AI的出现,也让自己构建工具无论从技术层面还是流程层面都变得愈发可行起来。
是的,写自己的工具是过去一个月里最重要的启发,感谢从2017年的Notion开始的每一个工具。
一、“第二大脑”时代的工具篇
(为控制篇幅,每个工具我只会很简短的评价,基于自己的使用感)。
“第二大脑”是什么?我自己的感受和理解是:随着过去十年里信息量、终端设备和APP的极速爆炸,大脑来不及处理和信息碎片的散落在各个角落成为最大的两个痛点。我们需要一套工具和流程来完成信息聚合处理,个人化的“第二大脑”就是这个作用。
1、最形象的示例来自于Obsidian:信息归集、整理、关联。
Obsidian是我过去五年里使用最多的工具,也成为我团队的标配工具。它不是开源,却胜似开源:
- 以Markdown为主要的文件格式,最方便文字、图像、视频甚至代码的多媒体内容整合编辑及显示;
- 强大的link和backlink功能,不仅文档间可以关联,文档内的内容都可以相互链接,关联,符合大脑思考习惯;
- 核心程序不是开源的,但是丰富的社区保证了大量的插件功能:可以执行程序,自动化文档整理,也可以加入生成式AI;
- 团队协作,可以通过代码仓管理,方便地实现团队成员间的协同工作和知识共享;
- 最强大的插件Excalidraw,这可能是我认为最符合未来生成式AI工具的形式,卖个关子,有兴趣的可以自己搜索“obsidian excalidraw”;
是的,Obsidian有很多缺点,在AI时代略显过时的编辑器,效率并不很高的文件处理系统,导致当知识库不断增长后会越来越难用。过去五年里,我找过几十种工具,试图替代Obsidian,但每一次都还是回到了这里。
2、Notion。这是如今名气最大的工具。我有幸在2017年就开始使用它,并在ChatGPT刚出来时的线下交流中多次安利。
- Notion是目前用户量最大的基于Markdown格式的工具,甚至,我成为Markdown的拥趸也都拜Notion所赐;
- Notion是第一个引入大量模板的工具,例如日程管理、读书计划、项目管理。虽然工具不是开源的,但模板是,用户群策群力并共享,每个人总能找到自己想要的,这回到了互联网的最初形态;
- Notion是第一个集成GPT用于写作、摘要、修改等功能的工具;
- 毕竟是商业化工具,界面很漂亮;
- Notion的缺点同样明显:相比Obsidian,编辑器过于死板,缺乏足够插件支持导致功能偏少,同时,虽然提供了收费的团队版,但是如果每个团队成员每月付10美金只是为了信息共享,对我而言,偏贵了。
所以,当我把自己和团队的工作都迁移到Obsidian上,并且开始集成生成式AI功能后,Notion被我放弃了。
3、匆匆而过的Logseq、Heptabase、Clickup、Appflowy……。在寻找Obsidian替代品的过程中,我尝试了几乎可以找到的所有类似工具,都有一个亮点,却都远不如Obsidian强大。
4、Miro、Figjam、Diagram……。程序员出身的原因,我一直是流程图和脑图的忠实粉丝,从二十多年前的Visio开始。当富媒体画板的概念逐渐出来后,我用了Miro,Figjam,可是不开源的问题使得我看到了他们的天花板:扩展性和代码动态执行能力。
5、TlDraw。如果你跟我一样,喜欢无限画板的概念,你会喜欢上Excalidraw。如果你还跟我一样,喜欢无边无际的自由与扩展性,TlDraw会有潜力成为“最爱”。
- 所有的一切起始于一张“空白画布”,然后你可以写作,画脑图,贴截图,贴视频,跟人一边开会一边分享,还能多人协作修改,还可以集成所有的生成式AI功能;
- 核心程序很简单,就是画板,后面的所有应用都是“头脑风暴”出来的;
- 优点是简单无极限,缺点是简单,所以需要大量的工作去完成内容持久化;
6、Affine、Anytype。他们又像又不像。多少借鉴了上面讨论的所有工具的优点,虽然很多在Roadmap里,却也提供了无限的想象空间。 这两个工具有最大的优点:因为几乎是在ChatGPT出来后推出或者改写的,设计架构很好。因为代码是开源的,而且很简洁,文档也比较完善,非常适合用来改造。
7、我的进度:我正在基于TLDraw、Affine、AnyType的代码进行整合,做自己的工具。难的不是代码,而是我必须不断花时间想清楚,自己到底要干什么。
二、我们需要什么?
我至今都对ChatGPT的“横空出世”评价偏中性:它本该只是我们通向“人造智能”道路上的工具,可是它抬高了所有人对它的错误预期及后来对于幻觉等这些天然缺陷的失望;但是它确实在短时间里吸引了足够多的资本和人才进入到这个领域。
然而,ChatGPT最大的问题是造成了大量用户一方面不知道自己要什么,一方面又对其实很好的功能产生了“钝化”。
1、我们需要智能搜索吗?ChatGPT一面世,大家就认为它会取代搜索,然后是对“幻觉”失望。其实,我们需要它完成两部分功能:对已有知识的归纳总结并输出,以及对基于此基础上对最新信息的主动搜索和整理输出。搜索是目前获取有效信息来源的最重要方式,信息的自主处理则是“增强大脑”最重要的功能。ChatGPT“悄悄”推出搜索功能,变局正式开始了。
2、我们需要它会写代码吗?某种程度上,偷懒是科技进步的重要源动力之一。一个人张张嘴,就可以自己写代码生成工具完成任务的“智能体”,几乎没人不爱。
3、我们需要它写文档、做PPT吗?也许现在暂时还是需要的。可是我一直坚持这样的观点:文档和PPT都是给人看的。AI时代,我们可能根本不需要这东西;
4、我们需要它会画图,会生成动画吗?作为生产力工具,极度需要。作为一个摄影师,我至今还持有这样的观点:所有相机厂商都应该认真思考的问题——数码摄影艺术将在五年内消失。
5、我们需要它跟我们对话吗?需要,无论是从提高效率层面看,还是从越来越孤独的人性看;
所以,无论ChatGPT、Claude,还是Gemini,NotebookLM,单一都满足不了我们的想法。可是生成式AI提供了这种巨大可能:我们只有一个界面,人回归本性,通过语言、表情、肢体语言甚至书写绘画来交流。键盘、鼠标等设备很有可能会消失。书写和绘画呢?它们已经植根于文化之中。正如音乐一直在,但载体已经从磁带到了流媒体。
理想的工具依然还在风中飞扬。但Claude的Artifacts,ChatGPT的Canvas,Google的NotebookLM不就是首先给到我们一张白纸(画布,canvas),然后在上面不断通过模型调用添加素材吗?
从0到N,而不是到1再到N。因为“1到N”是标准化的复制,“0到N”才是人的天性:每个人都不一样,每一个“大脑”都与众不同。
三、我们缺什么?
1、更好的交互,硬件和软件的。对于多模态模型而言,上下文限制非常大。即使Gemini 1.5 Pro目前可以做到2M上下文,处理高清视频仍显吃力。我们需要等待硬件的大幅升级(端侧),模型处理能力的提升,算法的大幅优化。
2、数据存储系统,或者说文件系统。生成式AI带火了向量数据库。如何让模型可以个性化的理解、存储、调用、生成信息,单一依靠数据库或模型都很难。AI文件系统是一个巨大的机会。
3、“增强”。生成式的出现,给了我们一次重构自己的机会:这个工作流可不可以由模型完成?如果模型可以完成了,那么这个工作流为什么还要存在?我们在哪里?一切从头开始构建的方式也逐渐缓解了我日益加重的内耗。
未完:一不小心又写了四千多字。每次文章的取舍都试图在“对齐颗粒度”,可是在那张不断延申的网状结构里,每一次对齐却都是一次巨大的遗憾。