Although long-awaited, and despite the past week's leaks pointing to the imminent release of the "Strawberry model" (OpenAI's rumored internal codename), OpenAI has once again dropped a "bomb" that exceeded everyone's expectations—and for the first time, it's not "future-ware."
Yes, the thinking O1 model has arrived:
To summarize in one sentence: we finally have a "commander," "planner," and "thinker" for large models. To add one more: the road to AGI is becoming increasingly clear.
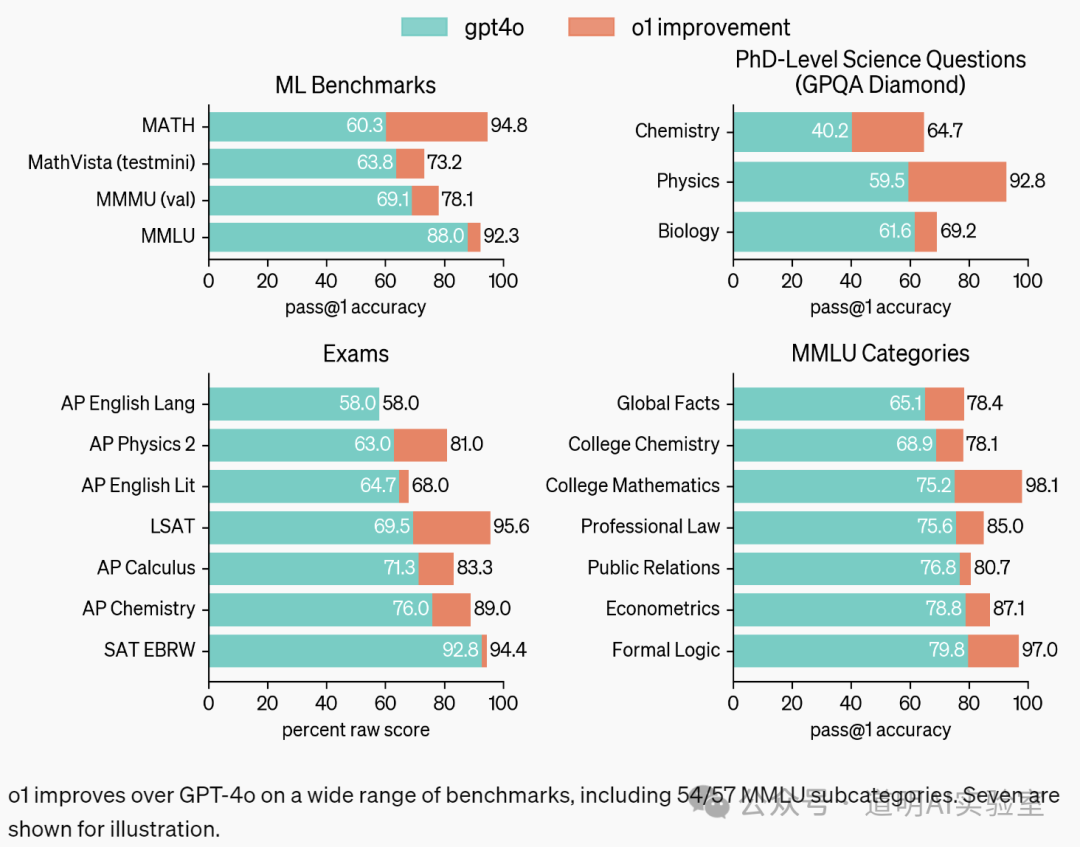
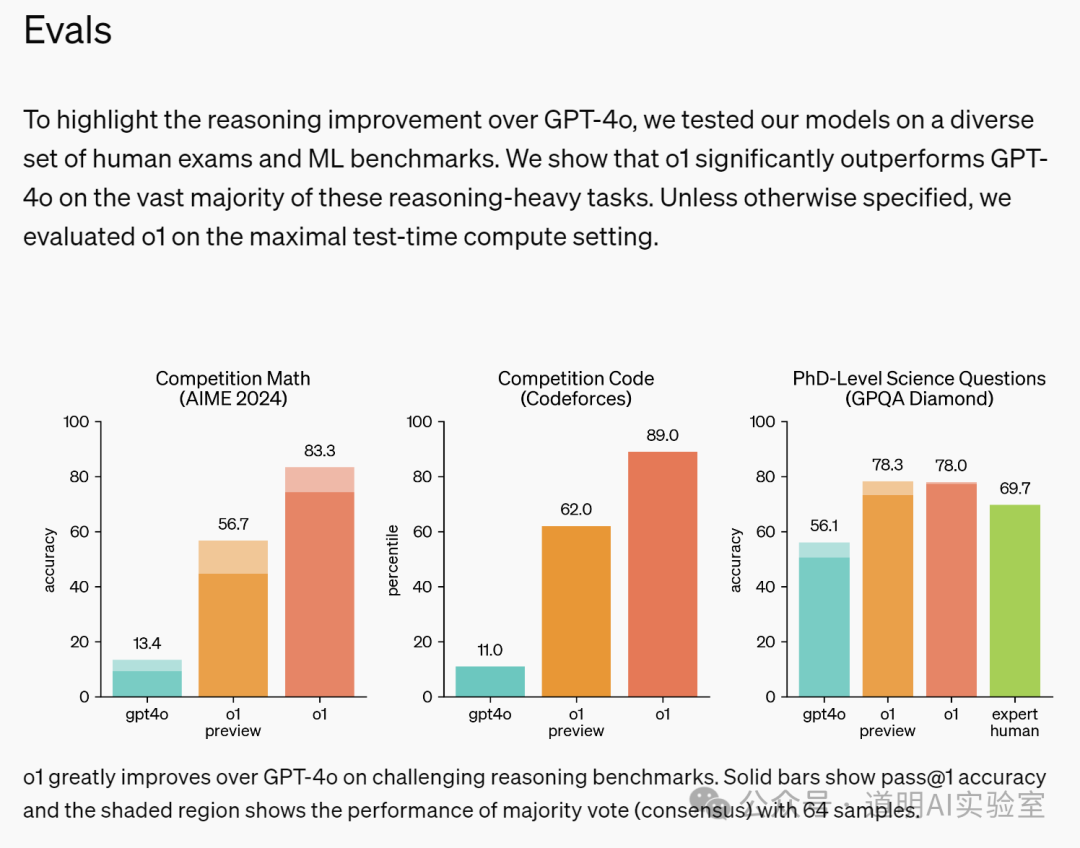
Compared to GPT-4o, O1 incorporates a "deep thinking" phase, resulting in a qualitative leap in performance in areas that represent high intelligence, such as competitive programming and coding, relative to GPT-4o.
This is "explosive," though the immediate target audience is niche (to be discussed later).
First, here are two preliminary observations:
- This model is not future-ware; it is available immediately with no waitlist. All users can access it, though it is currently the "preview" version.
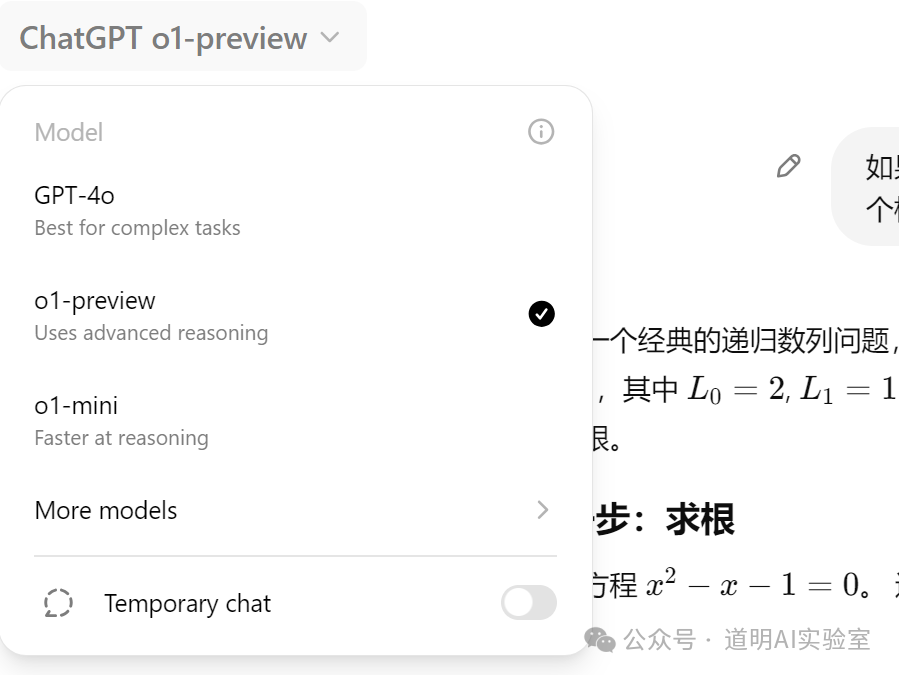
- Because of the "thinking" process, the outputs are very different from before, with higher accuracy and more detail. I just tried it out in the field of programming; it can achieve accurate planning for a large project. Regarding specific code—using the official output as an example—the new model is clearly more readable, professional, complete, and accurate.

This is an entirely different model; it is essentially the GPT-5 that isn't called GPT-5. The reason is simple: starting with GPT-4, the direction of model training changed. The most significant shift was that while GPT-3 to GPT-4 required retraining from scratch, subsequent models did not. The pre-training part became a reliable "knowledge compressor," and the goal of new models is to extract information and form answers more effectively and accurately.
The role of this new model is the "Commander"—the piece that everyone agreed has been "missing" since the advent of large models.
As for the market, people are more concerned about: How much compute does it consume? How many applications will it bring?
First, on compute: OpenAI did not disclose it directly but provided a very interesting chart on the "scaling law" between compute and model capability. This means: 1. Scaling laws remain valid; 2. Moving from the current preview version to the full version to be released in the future may require a roughly 50-fold increase in compute (the logarithmic axis provided is likely base-2). Based on current inference performance, the preview speed is similar to GPT-4o.
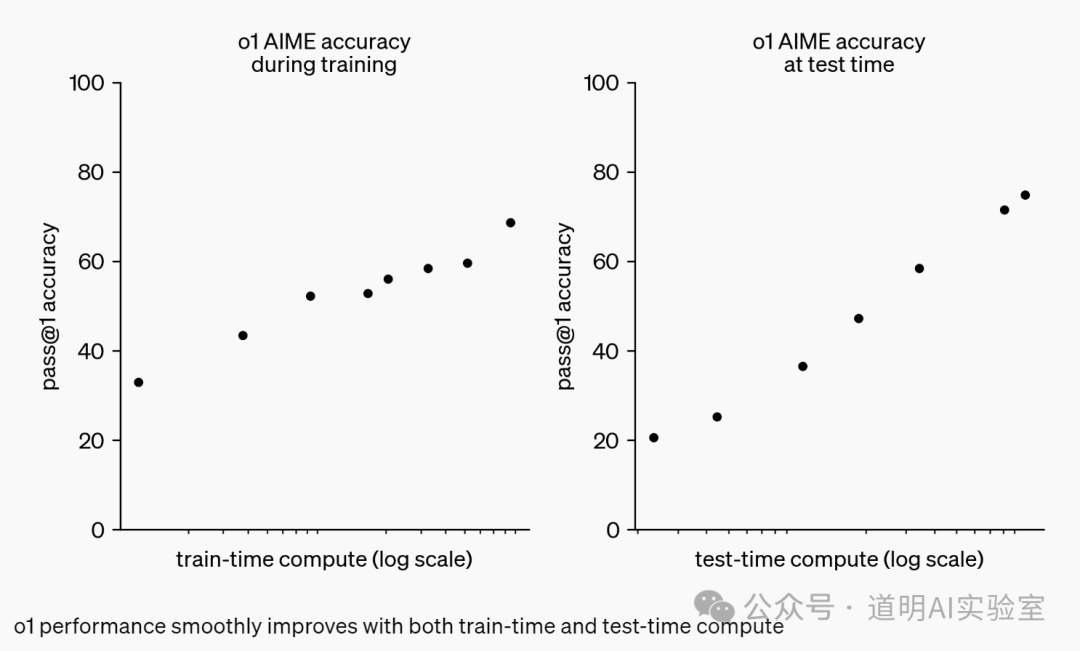
Second, on application implementation: I have always believed that models with "strong thinking capabilities," as OpenAI itself describes, are targeted at scientific research, programming, mathematics, and related fields. This is actually a narrow audience, though I cannot delve deeper into this topic here.
Supplementary notes:
For many deep users of AI models, the arrival of O1 is the final puzzle piece. In the fusion of multiple models, we finally have the "commander" role. After a long period of "chaos," OpenAI seems to have clarified the model's positioning: a human "assistant" or butler. This safe "red line" is of great significance for the future.
There is a barrier to entry for this model. Compute is one factor, but the most important is the ability to "generate data."
It comes back to the increasingly clear view: for some time now, large models have shifted from "hardware" toward "software." It's just that the connotation of "software" here is much broader and more difficult than before.