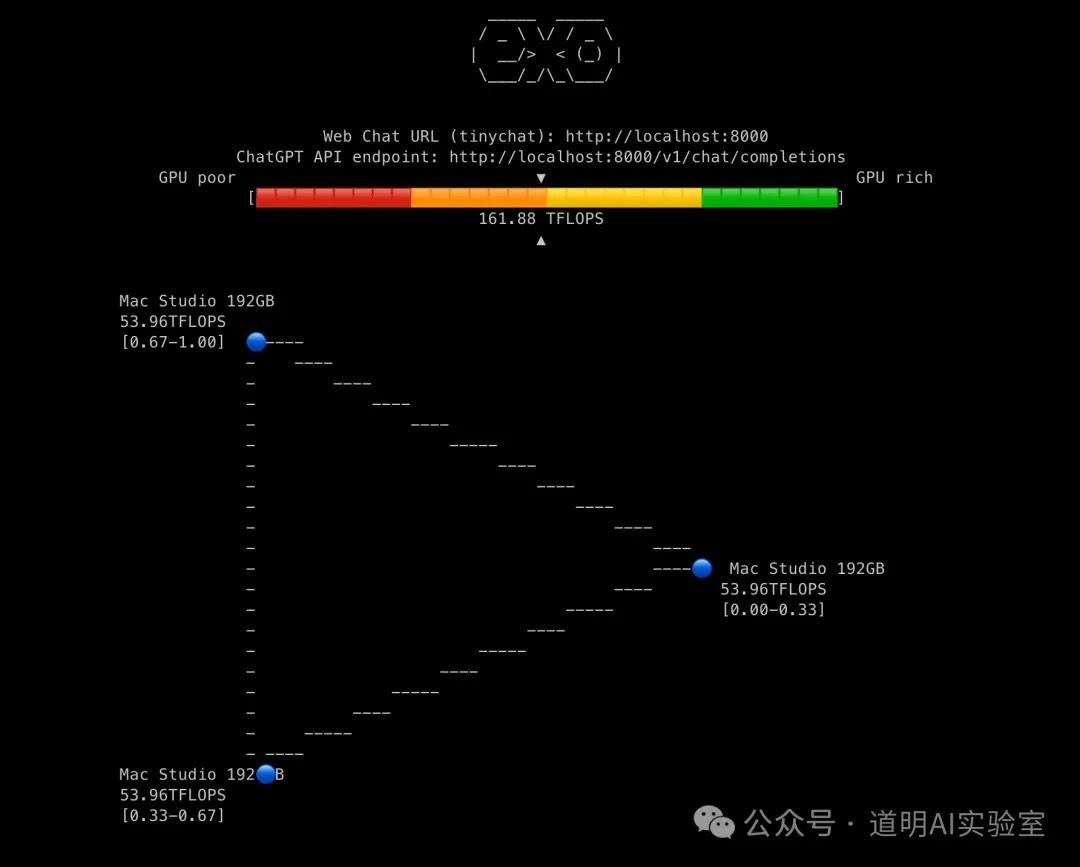
前后折腾了一天多,终于在昨天晚上搞定了Mac Studio集群本地推理LlaMa-3.1-405B模型。
具体的方法在三台Mac Studio跑模型文章里介绍过了,就不再赘述了,简述一下心路历程:
- 在我开始的时候HuggingFace的MLX_Community下还没有405B-Q4的模型可下载,所以只能选择本地模式;
- 首先下载完整的405B模型权重文件(FP16接近1T,以平均8-10MB/S的超高速,花费了超过半天的时间,非常非常快了,对吧);
- 利用MLX的Convert将模型量化到4bit版本;
- 然后将模型文件部署到各个节点(为了节省时间,我花了几个小时调整了网络,终于让网络速度触达了SSD的写上限:240-250MB/S);
- 然后改exolabs的代码,可以加载我量化后的模型文件;
- 然后,是一系列测试,不过我两个节点的测试一直是失败的,最后稳定在三节点可以。
稳定加载后,初步尝试,推理速度4tokens/S,其实不算慢,但是总还是觉得有些问题,然后又是一通网络调整,终于:

对,没看错,7.3tokens/S。
虽然跟我测算的理论值10tokens/S还有些差距,但是已经很满意了。
跑起来后是这样的(无变速):
结果对不对先不管,至少这个速度可以达到可用级别了。
然后,我忍不住要去跟之前说过的利用四块H100跑模型的结果去比较了(在H100上快速部署了llama3.1-405B模型)。这个环境是四块H100(PCI-E),偷懒直接使用了Ollama的推理,效果是这样的:
至于推理速度:
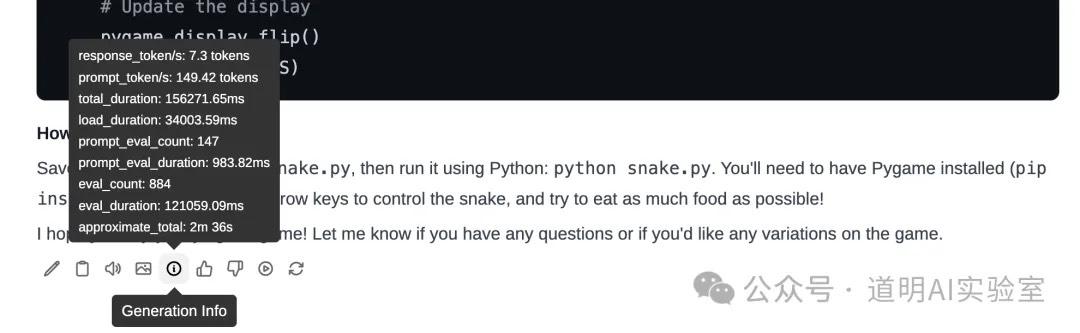
居然也是7.3tokens/S。
但是实事求是讲,实际视频里的感受,一定是H100的速度要更快一点,这里,我认为是ollama与exolabs的UI底层(tinygrad)计算方法的偏差,但是这个速度差距并不很显著。
- H100的环境应该还有很大的优化空间(又是ollama拖累);
- Mac Studio应该在目前代码基础上优化空间不那么大了,但是修改底层代码应该是可以的。
终于,在这个夏天,期待的模型发了,想要的环境部署好了,该做的测试也告一段落了,下一阶段要干“正事”了。