I finally found some time to start testing exolabs' cluster inference solution as planned. This is why I'm more optimistic about heterogeneous computing power.
Project Address: https://github.com/exo-explore/exo
Initially, I planned to test Llama-3.1-405B, but currently, the MLX-supported 405B weight files in the community are not yet available for download. I am still in the process of downloading the local model for weight file conversion, which will likely take at least another day (I reserved today's network bandwidth for downloading other models).
So, in this test, I used three Mac Studios (M2 Ultra, 192GB RAM) to run Llama-3.1-8B, Llama-3.1-70B, and the Mistral-Large model. Actually, the INT4 quantized versions of these models can run on a single machine, but I wanted to test whether using a cluster could improve inference performance.
In a previous article (Three M1 Mac Minis equal a 22B model), I introduced how to set up a Mac cluster via Thunderbolt 4 ports. This time, I replaced the Mac Minis with Mac Studios. The connection method is the same, similar to the diagram below, using three machines.

For the inference framework, I directly used exolabs mentioned at the beginning, rather than llama.cpp. The exolabs framework calls Apple's open-source inference framework MLX at its core. It's a new project recently released by Alex (yes, the person whose post about running 405B on two MacBook Pros went viral; we've been communicating quite a bit lately, but I only had time to run tests today) and his team.
Installation is very convenient. On M-series chip Apple computers, it’s just three simple commands:
git clone https://github.com/exo-explore/exocd exopip install .
Once running on each machine, they automatically search for other connectable devices. The aesthetic of the command-line interface feedback is quite nice. The three images below show the inference status with one, two, and three machines, respectively—very concise.
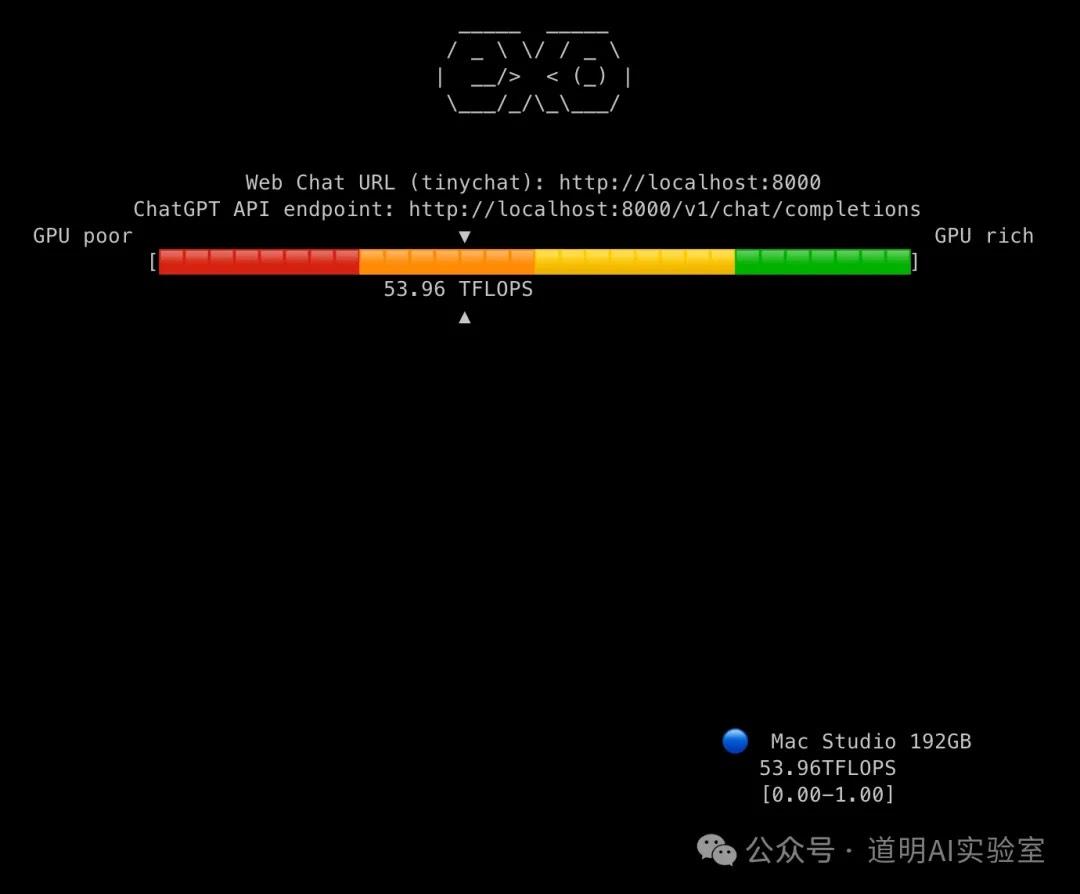
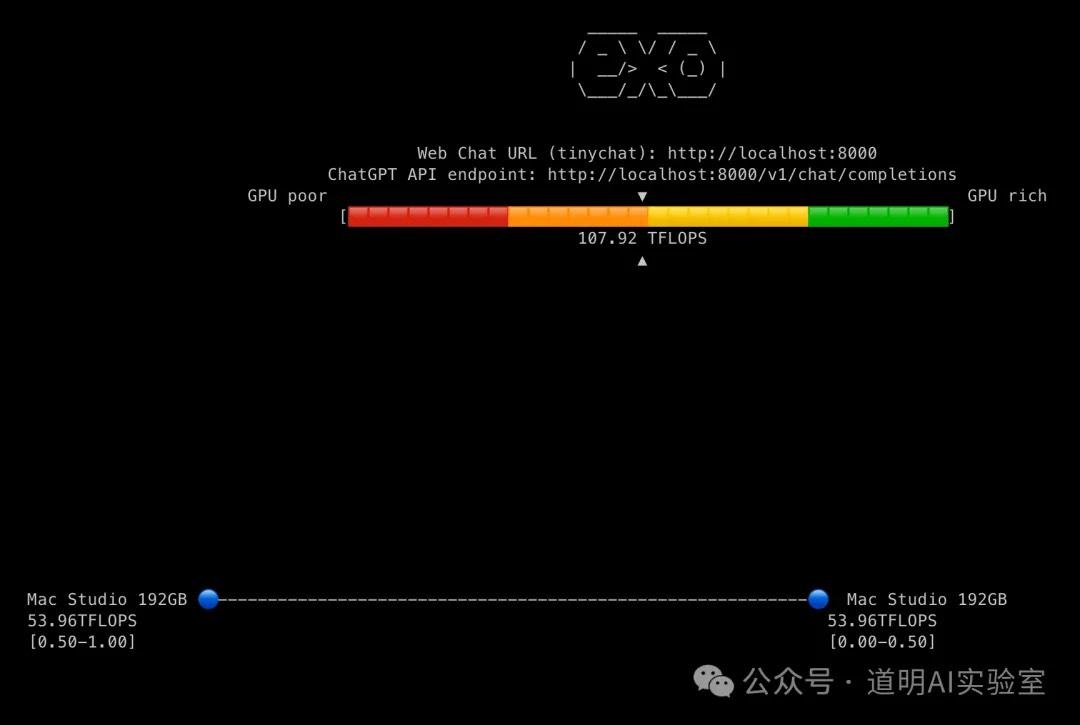

I tested the speeds of running three models (Llama-3.1-8B, Llama-3.1-70B, and Mistral-Large with 123B parameters) in environments with one, two, and three machines.
All three models are INT4 quantized versions, with weight file sizes of 4.5GB, 39.7GB, and 69.1GB respectively.
I then sent the 9 sets of test results to GPT-4o to generate the following graph:
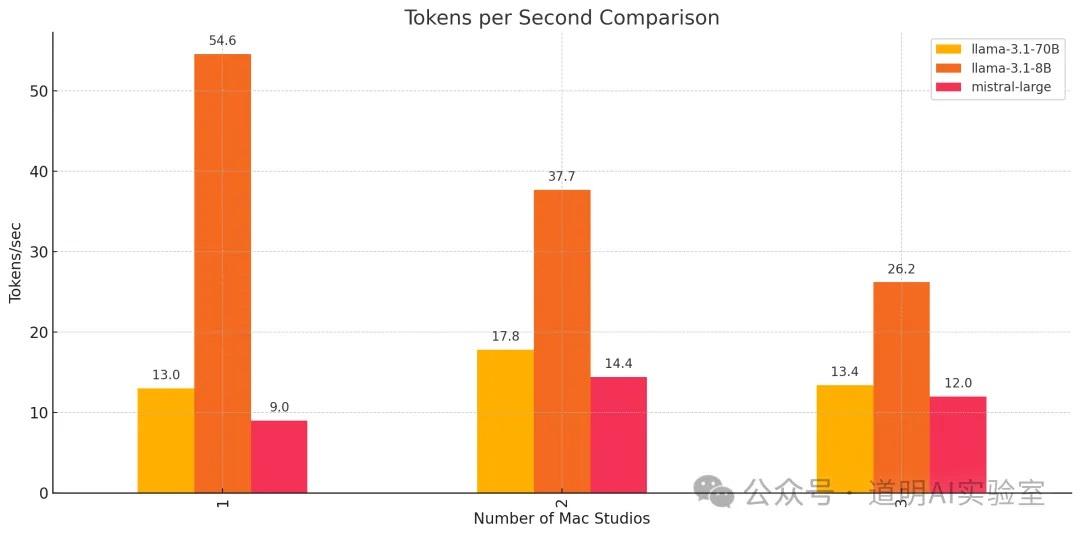
The results are very interesting:
For the 8B model, the best inference performance was on a single machine at 54.6 tokens/s. Every additional machine caused performance to drop by about 30%. Clearly, the network latency significantly exceeds the generation time for a single token.
For both Llama-3.1-70B and Mistral-Large-123B, performance improved with two machines compared to one. The improvement for Mistral-Large was particularly noticeable. However, performance dropped when moving from two machines to three.
I believe that for a 405B model, we would likely see a trend where three machines outperform two, and two outperform one. If this holds true, a multi-machine cluster won't just be able to run the model but will also provide guaranteed performance—perhaps reaching 10 tokens/s?
Throughout the day, I tested many scenarios. In some tests, the 70B and 123B models actually performed best with three machines. I suspect the fluctuations were caused by the network: each machine is also connected via 10G Ethernet, and I didn't specify the interconnect interface during the run. It's possible it sometimes used the 40G Thunderbolt port and other times the slower Ethernet. I'll need to look at the source code and adjust this later.
Regardless, these results remain very enlightening.
I don't think this is just "self-entertainment" or another "mining project" as some might suggest. Building low-energy clusters with Apple devices to create multi-agent environments where small and large models coexist, combined with powerful cloud models like Claude 3.5 or GPT-4o, makes the concept of a "one-person company" highly feasible.
Furthermore, I believe there is still massive room for optimizing inference performance. This has practical significance and a solid foundation; after all, Apple has clearly stated that their cloud model, AFM-Server, runs on their own Apple Silicon chips.