It appears that all signs point to Meta releasing the LlaMA-3 405B parameter model within the next 24 hours. The evidence mainly consists of two points: first, a download page for model files appeared in Google's index (though the content is still empty); second, scores for the new model appeared in Azure Cloud's model evaluation project.
A few hours ago, magnet links for the model files appeared on social media, with the complete model file being approximately 800GB.
If the aforementioned "leaks" are true (and most seem reliable), it will indeed be exciting for many.
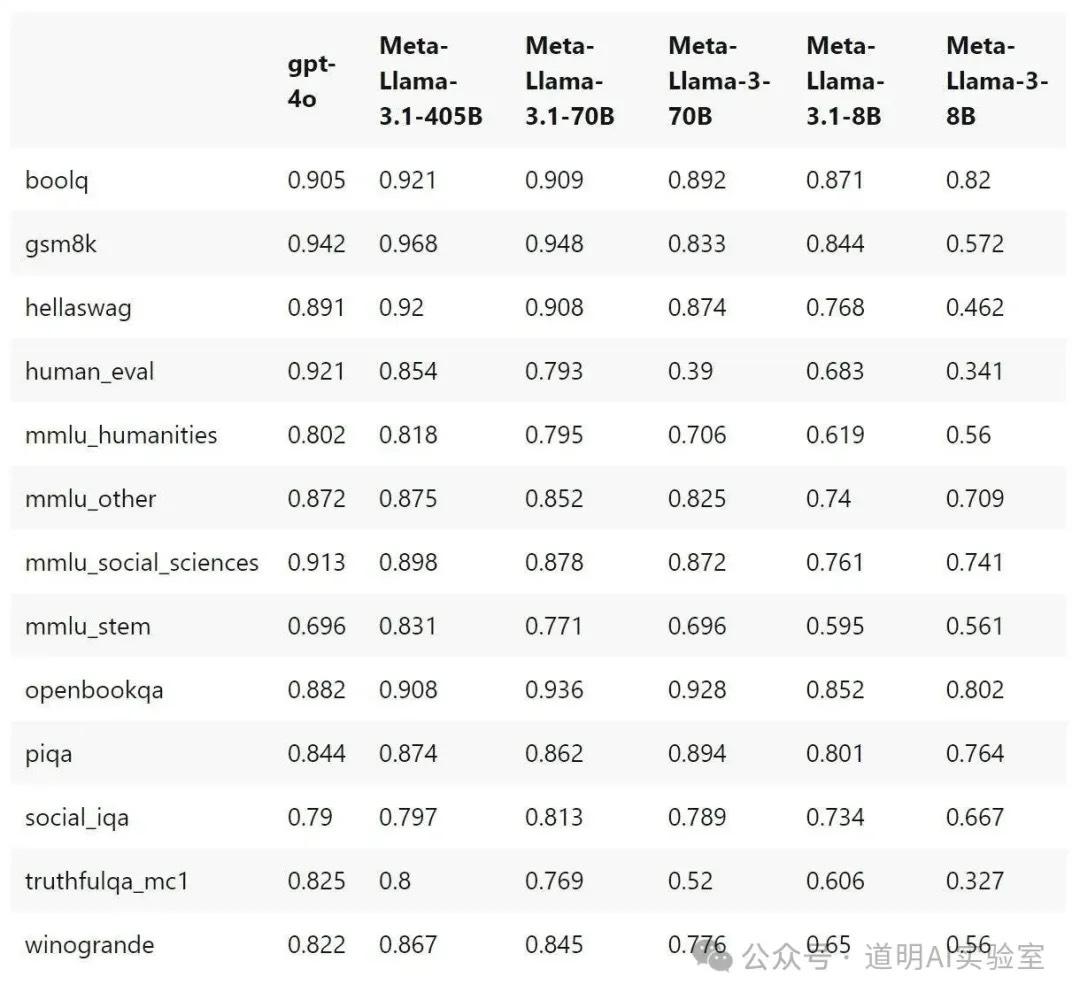
Meta will release LlaMA-3.1, which includes not only the 405B but also new 70B and 8B versions. The 405B model outperforms GPT-4o on the vast majority of benchmarks (though it still lags behind GPT-4o in human evaluation). If Meta indeed open-sources this model (open weights only), the landscape of AI models will change significantly.
The LlaMA-3.1 70B and 8B models have also made significant progress compared to LlaMA-3, especially in mathematics and code generation. Since the 405B model is quite large and has very high hardware requirements, the 70B and 8B models with improved performance will likely see more use cases.
While I haven't had time to verify the authenticity of the files in the magnet link, the total file size of about 800GB seems consistent. Corresponding INT8 or FP8 weight files would be over 300GB. The INT4 version might be able to run directly on an Apple Mac Studio (M2 Ultra with 192GB RAM), with an initial estimated inference speed of 2-5 tokens/s. As someone noted in a previous article's comments: it's just barely runnable.
However, for the majority of developers who do not have four or even eight H100/A100 GPUs, a top-spec Mac Studio (max CPU, 192GB RAM, any SSD size) costs around 40,000-50,000 RMB. From this perspective, it offers exceptional cost-performance.
Of course, better inference requires cluster setups. I've previously written two articles on this: one about using llama.cpp's RPC method to form a cluster via Thunderbolt interfaces (three M1 Mac Minis equal one 22B model), and another on why I'm more optimistic about heterogeneous computing. With such a large model, there's plenty of room for architectural experimentation and optimization. It will be fun; I expect to spend the entire next week "soaked" in this.
Meta mentioned during the LlaMA-3 launch that the 405B would be a multimodal model, but current leaked model cards suggest this release is still text-only, with added multilingual support. If, as expected, a full multimodal model is released this fall with open weights, that would truly be a "major event."
The pressure is now on OpenAI. Rumors about OpenAI releasing a new model are becoming more frequent and credible. Although more people are growing tired of OpenAI's "cunning" tactics (stealing other companies' thunder) and the long wait between announcement and user rollout, this high-intensity competition is always good for developers and for the practical implementation of AI.
I don't want to say much more about the judgment that model applications will inevitably accelerate. Production deployment and stock investment considerations have increasingly become two different dimensions.