看起来,各种信息都指向了24小时内,Meta就会发布LlaMA-3的405B参数规模的模型。证据主要是两点:一是在Goole的索引里出现了模型文件的下载页面,虽然内容还是为空;二是在Azure云的模型评估项目里,出现了新模型的评分。
几小时前,社交媒体上还出现了模型文件的磁力链接,完整的模型文件约800GB。
如果上述的“信息泄漏”都是真实的(看起来绝大部分可靠),确实会让许多人兴奋。
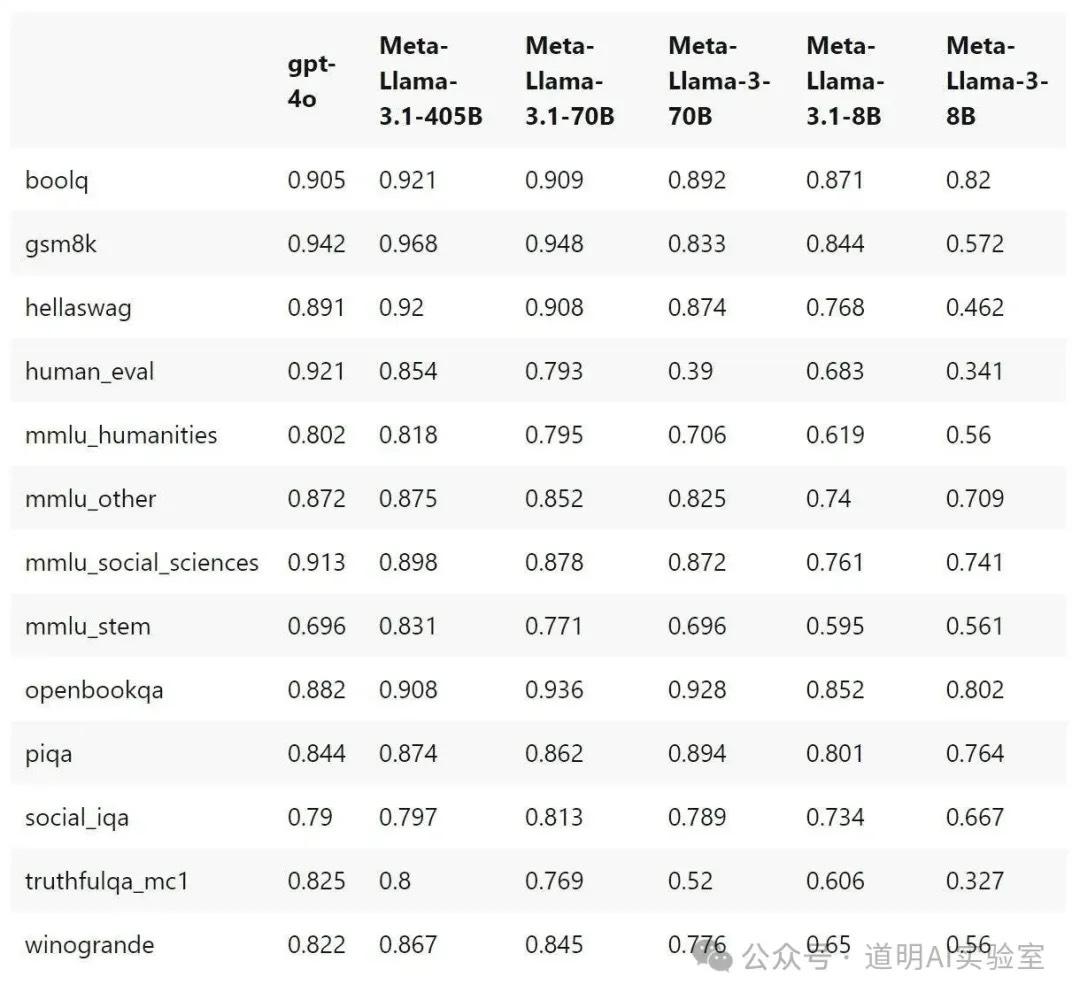
Meta会发布LlaMA-3.1,所以不仅仅是405B,也会有新的70B和8B。405B模型在绝大多数评分上超越了GPT-4o(人类评价上依然不如GPT-4o),如果Meta确实把这个模型都开源(仅开放权重)了,那么模型的格局真的大变了;
LlaMA-3.1的70B和8B模型相比LlaMA-3也有了长足的进步,尤其是数学和代码生成方面;405B模型毕竟太大了,对硬件的要求其实非常高,所以更好的数学和代码生成表现的70B及8B模型使用场景更多;
虽然磁力链接里的文件真实性我还来不及验证,但是总文件大小约800GB这个数字基本上差不多,对应的INT8或者FP8模型权重文件300多GB,INT4版本有可能可以直接在Apple Mac Studio(M2 Ultra 192GB内存版本)上直接运行,推理速度初步推测在2-5tokens/s以内,就跟之前文章评论里有人写的一样:只是可以跑;
但是对于绝大多数没有4块甚至8块以上H100/A100的开发者而言,一台Mac Studio顶配(CPU最高配,内存192GB,SSD存储随意),4-5w人民币,从这个角度看,有绝高的性价比;
当然,更好的推理方式需要靠集群推理了,这个我之前写过两篇,一篇是基于llama.cpp的rpc方式,通过雷电接口组集群:三台M1的Mac Mini,等于一个22B模型;一篇是为什么我更看好算力异构。在这样大的模型面前,有很多可以实验的架构和优化空间,一定会很好玩,目测下周一整周的时间都会“泡”在这个上面了;
Meta在发布LlaMA-3时介绍过,405B是多模态模型,但是从目前泄露出来的模型卡文件看,这次发布的还是纯文本模型,只是支持多语言了。当然,如果如预期一样,秋天真能推出完整多模态模型,同时还开放权重,那就真是一件“大事”了;
压力来到OpenAI这边,但是关于OpenAI即将发布新模型的传言也越来越多,越来越真,虽然越来越多人不喜欢OpenAI这种“鸡贼”(抢其他公司风头)的做法和从发布到推送给用户的漫长等待时间,但是,OpenAI这种高强度的竞争性,对开发者而言,总是好事,对AI落地而言,也是;
不想再说太多关于模型应用一定会越来越快的判断了,生产落地和股票投资考量,已经越来越是两个维度了。