
腾讯的AILab新发了一篇论文,本来准备昨天评论的,但因为觉得这个话题粗看起来会有点“敏感”,就放下了,今天一早重新翻了一下论文,还是认为有东西可讲,临时起意,还是更新一篇,而把本来准备讨论的话题延后。
做个小预告,下一个准备讨论的话题是关于“wearable ai”的。
首先,论文题目是《Scaling Synthetic Data Creation with 1,000,000,000 Personas》。大概意思就是如何利用10亿“角色特征”大规模的生产“生成数据”。
部分数据开源,项目地址
https://github.com/tencent-ailab/persona-hub
看题目,就大概能够联想到我认为有些“敏感”的点:因为这所谓的10亿角色其实是用真实存在的“web data”抽象出来的。纯技术和研究视角,这是一个非常棒的想法,而且就是大厂该去做的事情。但是从数据安全的视角,首先原始数据来源其实比较含糊,处理过程也缺乏细节。
即使项目团队也反复提到了很多伦理道德方面的风险,所以,在他们开源的项目和生成数据里,只是包含20万个persona(角色)。
言归正传,相信对于腾讯这样与“敏感”信息打了二十几年交道的公司,不至于犯低级错误,所以,下面的分析纯粹聚焦于技术和应用前景层面。
1、这个项目是什么?
如上是论文里的一张示意图,一句话概括:通过“角色扮演”,让大模型自己生成可用于训练和精调模型的数据,覆盖不同领域,包括:数学问题,推理问题,精调指令(instruction),知识,游戏NPC,以及函数调用(工具)等等。
2、Persona到底是什么?
Persona就是某种角色扮演,只是这种角色扮演是从真实的“web data”中提取出来的代表某种人的角色特性的数据,在这个项目里的表现形式就是类似于“谁谁谁,干什么的工作的,”,简单讲,就是提示词。如果我们对大模型提示词稍微了解一些,会知道经常会问大模型“假设你是一个谁谁谁,请帮我……”,所谓“Persona”,表现就是“提示词”。
3、为什么要用“Persona”提示词?
论文里画了一张示意图的,但是在我们已经拥有了Claude3.5的时代,二维平面图像已经太普通了,所以,我让模型帮我生成了一段示意动画。

解释一下:
我们一直说大模型是个“压缩器”,那么压缩的是什么?知识!(LLM是个压缩器,写在OpenAI直播展示活动之前),也就是说模型训练的过程就是把浩瀚的知识压缩到神经网络的那么多参数里;
大模型的生成过程就是解压缩,把只有模型看得懂的压缩过的那么多参数权重还原成人看得懂的“知识”(这就是为什么会有“能生成意味着能理解”的说法);
但是模型是无比庞大的,如何让它有效准确的“解压缩”?这就靠提示词和attention机制;
通过Persona的提示词,激活模型里跟某知识区域关联度更大的信息,从而“解压缩”出更“准确”的知识,这就是这篇论文的目标。
4、效果如何?

上图是Claude3.5的总结,很到位,数据也是准确的。结论就是使用生成的数学问题“合成数据”精调Qwen2-7B模型后,在数学上的评分达到了64.9%,是超过gpt-4-turbo的早期版本的。
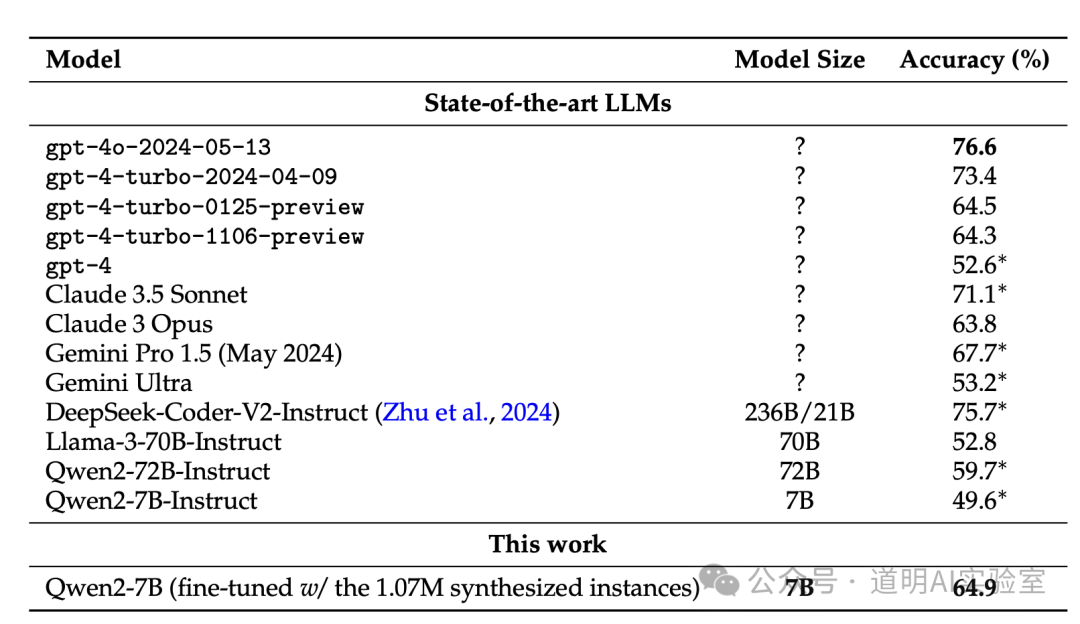
5、结论:用在哪里?
上面的评测已经给出了一个很好的例子,就是用在模型精调上,当然,这样的数据量,能够使用的场景会广阔的多。
写在最后:一个趋势已经很确定了,当模型发展到今天的水平时,“生成数据”对模型的作用越来越大,甚至于我认为“生成数据”的质量是超过绝大多数真实数据的,正如这篇论文里展示的一样。我们可以通过系统性的方法大规模集中的生成特定的“生成数据”,然后用于强化模型的能力。有人认为这是“涌现”,有人质疑,但是没人会否认,模型对于每个人的作用越来越大。
可是要让模型出现一部分人相信的“涌现”,就是需要极海量的数据,哪怕是使用“生成数据”,耗费的算力资源也是惊人的,看看这篇论文涉及到的“10亿”这样的数量级,就已经非常惊人了,这就是大公司的游戏。
最近经常有人会问我一个问题:算力在模型训练的需求多少?推理需求多少?其实,算力就只能用在训练和推理上吗?还有,在看得到的几年内,既然还要堆数据,还是缺最大集群的算力,那么,去算数的意义,真那么大吗?