
Time flies, and the first half of 2024 has already come to an end. We have seen many things arrive, except for the long-delayed GPT-5 (Next) and the once-again postponed GPT-4o Voice model rollout.
However, even if we no longer have high expectations for OpenAI, there are still a ton of companies, models, and open-source projects that make us feel the happiness of being incredibly "busy" every day, while also experiencing the constant "external drain" of never being able to relax.
In fact, at this moment, we can be certain that various models for rapidly transforming production, life, and society are ready: the multimodal understanding of large language models, powerful programming capabilities, and data comprehension; the real-time interaction capabilities of voice models; the increasingly realistic capabilities of image and video generation; and the lower barriers and higher production efficiency of workflow tools.
All of these together have almost completed all the "Lego bricks" needed in the pure software field. The rest is just a process of application adaptation, but the time required for this process has shortened to a staggering degree compared to just over a year ago.
Therefore, looking at some open-source projects, especially those from "star" startups, always brings more excitement than concern. The building blocks are improving at an unbelievable speed, and they happen to be exactly what we need.
1. ControlFlow from Prefect
ControlFlow
https://www.prefect.io/blog/introducing-prefect-3-0
During the peak of remote work for well-known reasons, workflow-oriented technical solutions for "multi-person collaboration and multi-task orchestration" were very popular. Mature projects like Airflow existed but were extremely complex. Prefect, as a solution with a very low barrier to entry, immediately gained significant developer attention. Its update frequency has been remarkably fast, staying at the forefront of technical trends for three or four years. From the first generation of Prefect to the second generation, Orion, and then the Marvin solution released after the LLM craze last year, they have now officially launched the third generation:
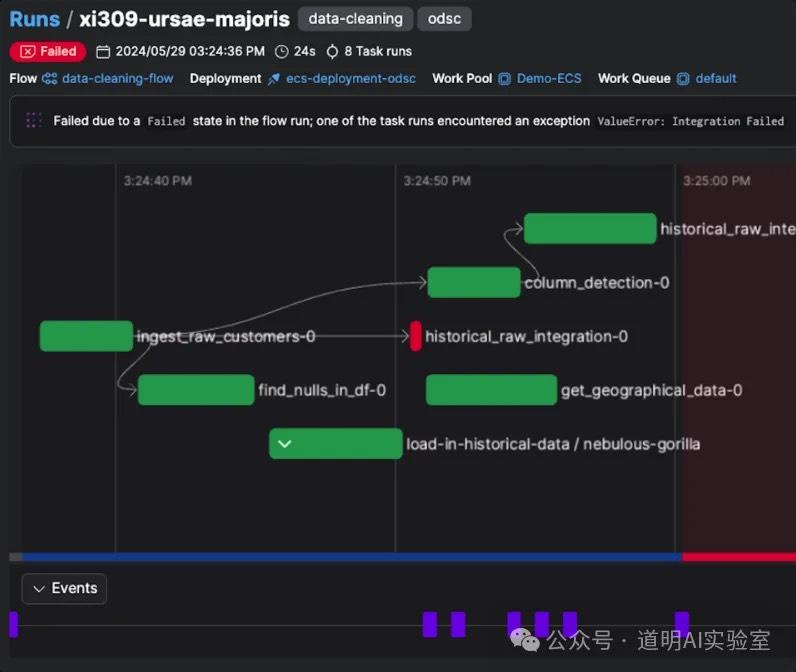
The screenshot above might be a bit abstract. Using Claude 3.5 to summarize and output the key points looks like the image below.
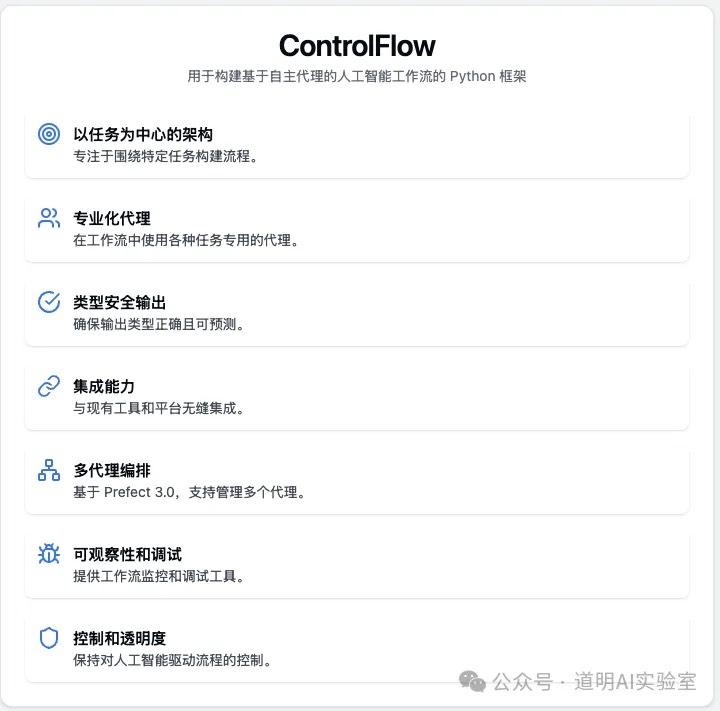
To summarize: when model capabilities reach a certain standard, changing the way we produce requires process re-engineering. After over a year of exploration, people have found that embedding models into traditional data-oriented workflows is a more effective path, saving hundreds of times the project development and deployment time. What's needed is not developing new workflow tools for models, but rather integrating models into mature workflow tools for rapid re-engineering. This is Prefect 3.0, ControlFlow.
2. llama agents from llamaindex
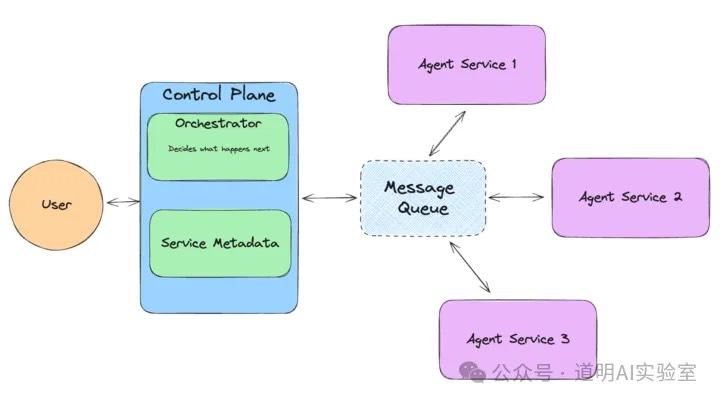
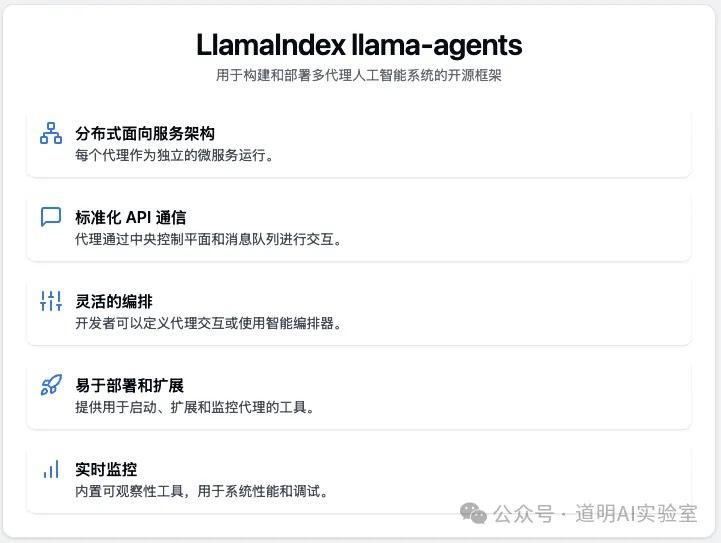
The Prefect ControlFlow mentioned above is a typical solution for integrating AI models into the previous generation of data-oriented workflow tools. Meanwhile, LlamaIndex, as one of the two giants in the hottest field of Retrieval-Augmented Generation (RAG) (the other being LangChain), has timely launched Llama Agents. This is launched at a time when LangChain is facing scrutiny from programmers, focusing on how to better establish agent orchestration workflows. The goal is actually the same as ControlFlow, but the application domains differ. ControlFlow might be better suited for workflow orchestration of structured data, while Llama Agents' strength likely lies in knowledge base search and generation capabilities.
I actually hope to see a fusion. However, the wait for that should be very short.
3. NuExtract, Content Extraction Model
NuExtract
https://www.numind.ai/blog/nuextract-a-foundation-model-for-structured-extraction
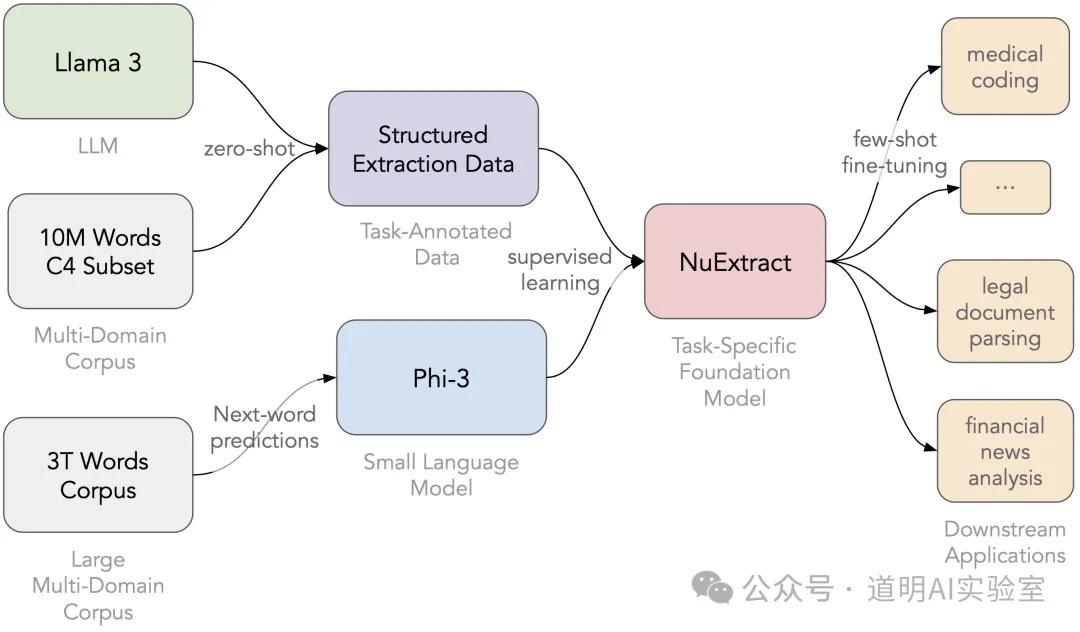

NuExtract can essentially be considered a crawler model. It is a model at its core, with various sizes of weight files released on Hugging Face. Its function is to extract structured text information from text (especially web pages).
For example:
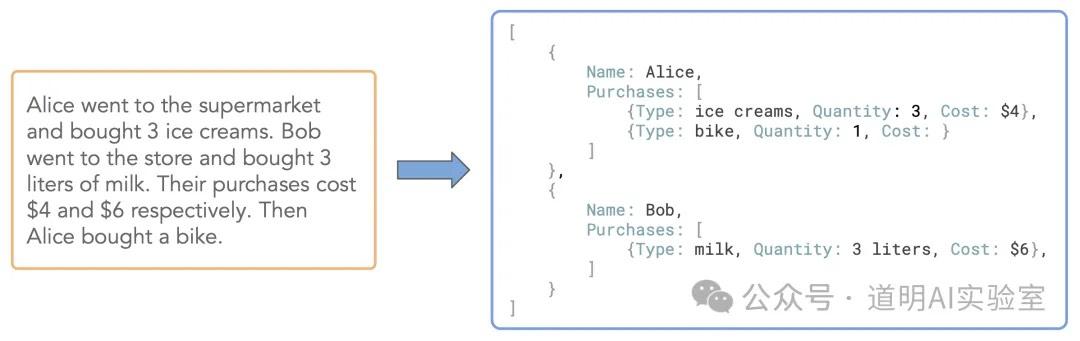
It converts unstructured text information into structured output. According to evaluations by the developer NuMind, its performance is close to GPT-4o. This is indeed the best-performing model of this type I have seen in a while.
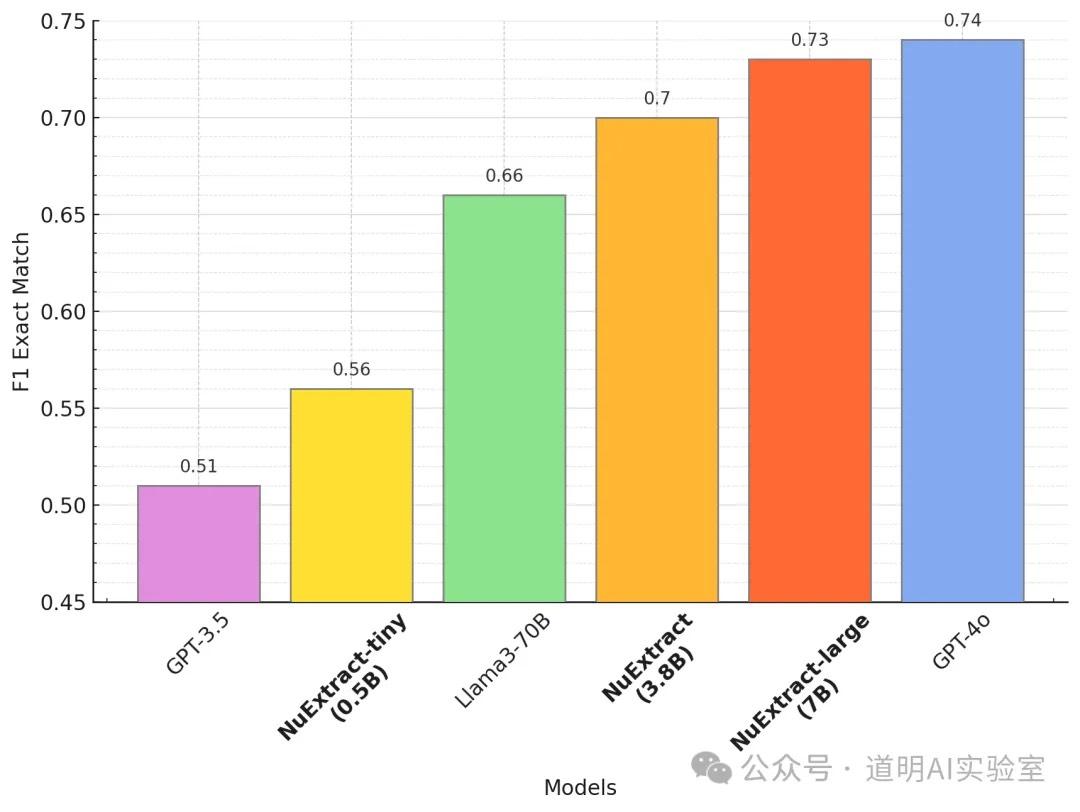
So, what is the biggest use for this model? It is rapid data acquisition and structuring, which can then be called by ControlFlow or Llama Agents as part of an agent.
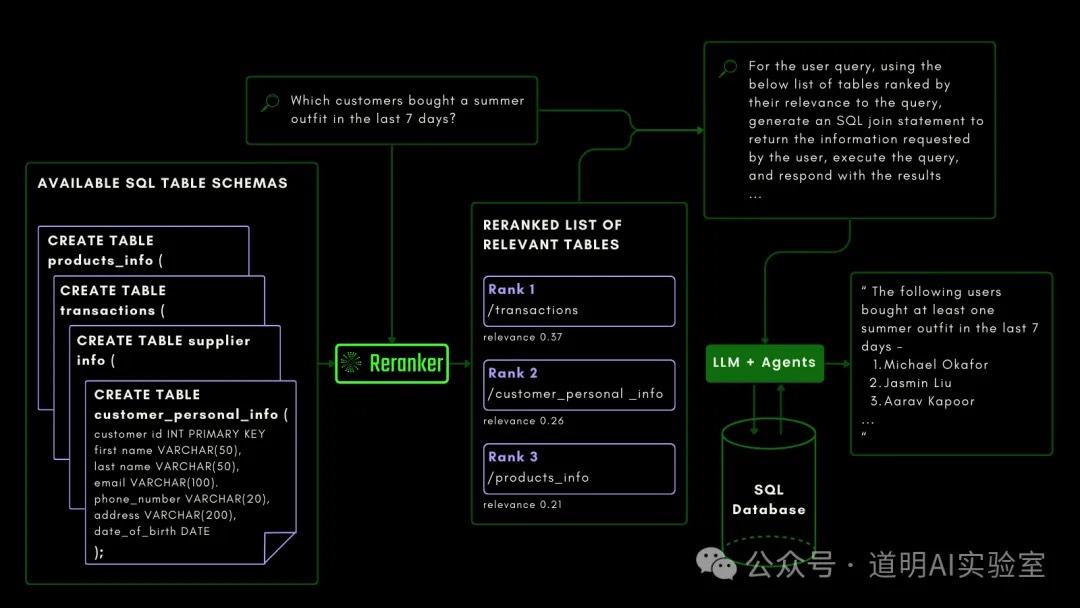
4. Jina Reranker V2, Ultra-Fast RAG Agent Model
Jina Reranker V2
https://jina.ai/news/jina-reranker-v2-for-agentic-rag-ultra-fast-multilingual-function-calling-and-code-search/

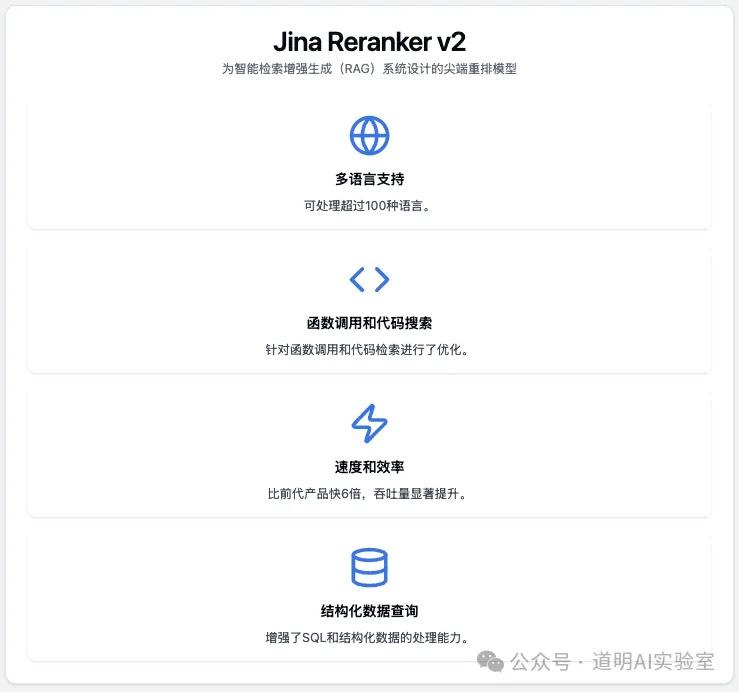
Jina might have the strongest corporate background among the projects introduced here. Before LLMs emerged, they already had a series of AI solutions based on document processing and search. Recently, they even released an AI crawler, Jina Reader. This is an AI startup founded in Germany in 2020, and every set of their solutions has a large following of developers.
Similar to NuExtract, Reranker is also a model whose weight files can be downloaded from Hugging Face. The base-multilingual model has only 278 million parameters, and the model file size is just over 500 MB, with extremely low hardware requirements. It supports multiple languages, function calling, code search, and can even write SQL to query data.
Summary
Recently, my main energy has been focused on infrastructure transformation. So, while I am very excited about these models, I don't have time to test them yet. However, I can strongly feel that they are all moving in the right direction: combining models with traditional workflows. The most important part here is business data processing and the process re-engineering work carried out for this purpose.
If the previous era was called the "Big Data Era," its core was ETL—Extract, Transform, Load (or sometimes ELT). The biggest workload in that era was data processing.
In this "LLM Era," as agents become increasingly viable and the bulk of the workload is gradually handed over to models, the resulting changes will be significant, and perhaps even staggering.