
时间过的很快,2024年的上半年就结束了。我们等来了很多东西,除了迟迟没有推出的GPT-5(Next)和再次跳票的GPT-4o Voice模型推送。
不过,即使我们对OpenAI不再有期待,也依然有一堆公司,一堆模型和一堆开源项目,让我们既感受到每天都无比“忙碌”的幸福,也体味无时无刻不能松懈的“外耗”。
其实,在这个时刻,我们可以确定的是,用于快速改变生产生活和社会的各种模型已经准备好:大语言模型的多模态理解力,强悍的编程能力,对数据的理解力;语音模型的实时交互能力;图形视频逐渐开始的以假乱真能力;流程工具越来越低的门槛和越来越高的产品化效率。
所有这些在一起,几乎完成了在纯软件领域所需的一切“乐高积木”,剩下的只是应用适配的过程,但这个过程需要的时间,相比一年多之前,缩短的程度也是惊人的。
所以,看一些开源项目,尤其是“明星”初创企业的开源项目,总还是兴奋多过忧虑,因为积木在以难以置信的速度变好,而且,恰好还是自己要的。
1. 来自 Prefect 的 ControlFlow
ControlFlow
https://www.prefect.io/blog/introducing-prefect-3-0
在因为众所周知原因远程办公盛行时期,“多人协作、多任务合奏”的面向工作流的技术方案非常流行,成熟的项目如 airflow,但是非常复杂。Prefect 作为使用门槛极低的解决方案一下子获得很多开发者的关注,更新频率也特别快,三四年时间里一直在技术趋势的前沿,从第一代的 prefect,到第二代的 orin,在去年大模型风靡后,还出了一套解决方案 marvin,如今正式推出了第三代:
上面的页面截图可能比较抽象,使用 Claude 3.5 总结并输出要点,就是如下图一样。
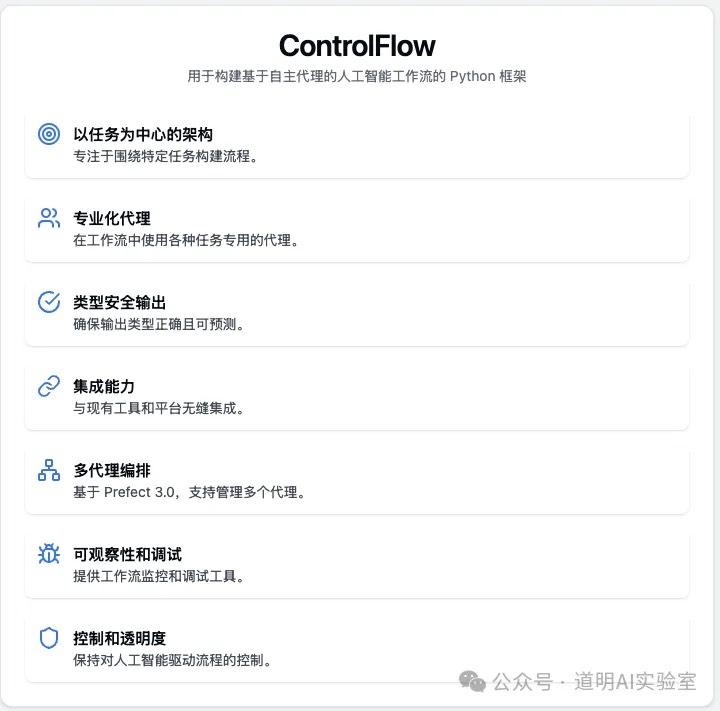
当然,要我总结:当大模型能力达标后,要改变生产方式,就必须进行流程再造,经过一点多的摸索后,大家发现将模型潜入传统的面向数据流程,成百倍的节省项目开发和部署时间,是更有效的路径。所以需要的不是面向模型开发新的流程工具,而是将成熟的流程工具加入模型快速再造。这就是 Prefect 3.0,ControlFlow。
2. 来自 llamaindex 的 llama agents
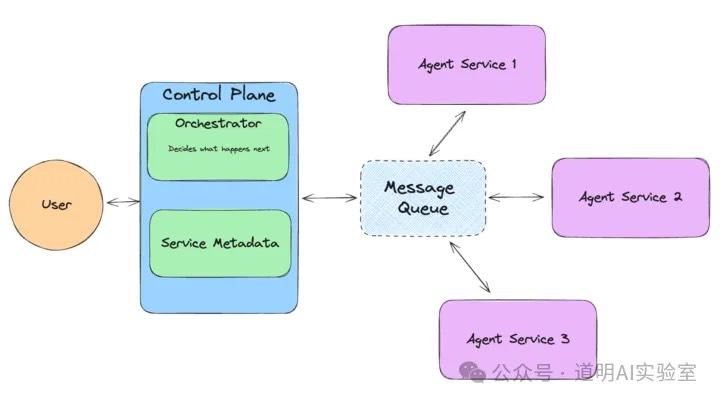
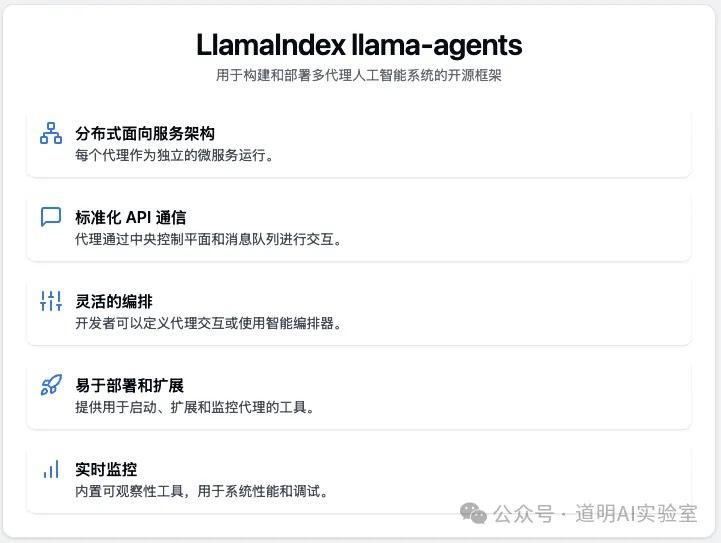
上面的 Prefect ControlFlow 是典型的上一代面向数据的流程工具集成 AI 模型的方案,而 llamaIndex 作为知识获取增强生成(RAG)这个最火领域的两强之一(另一个是 langchain),在 langchain 饱受程序员质疑的当下,适时推出了 llama agents,面向的就是如何更好的建立代理编排流程。目标跟 ControlFlow 其实是一样的,但是在使用领域上还是会有些区别,ControlFlow 可能更适合作为结构化数据的流程编排,而 llama agents 的强项可能还是在知识库搜索和生成能力上。
我其实更希望看到的是融合。不过,这个等待时间应该会很短。
3. NuExtract,内容抽取模型
NuExtract
https://www.numind.ai/blog/nuextract-a-foundation-model-for-structured-extraction
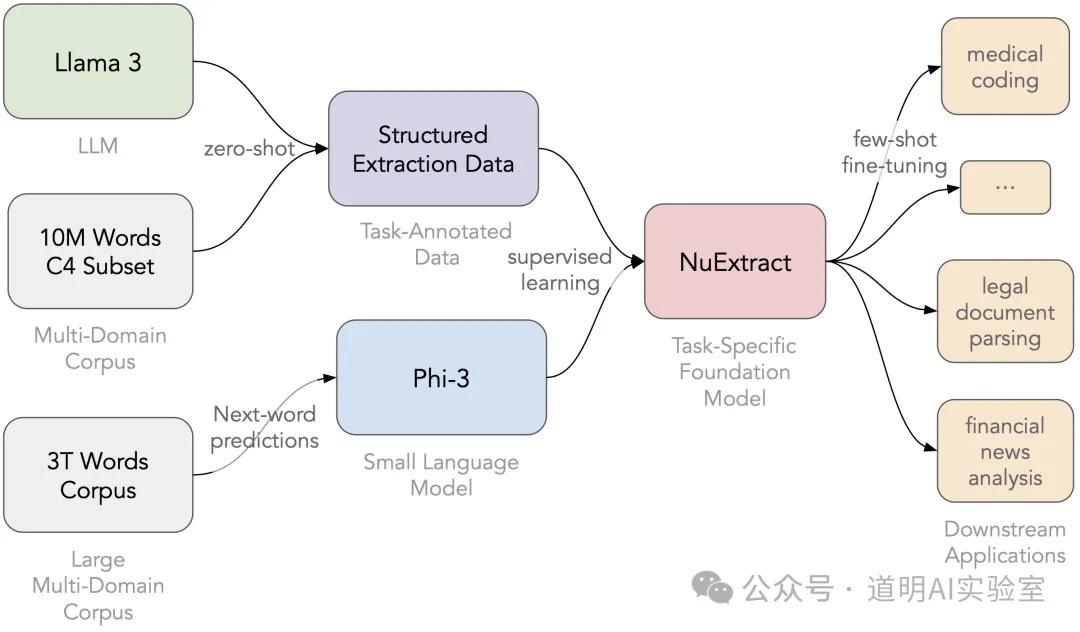

NuExtract 其实可以认为是爬虫模型,底层是一个模型,在 huggingface 上有发布不同大小的模型权重文件,功能就是从文本(尤其是网页)里提取结构化的文本信息。
例如以下:
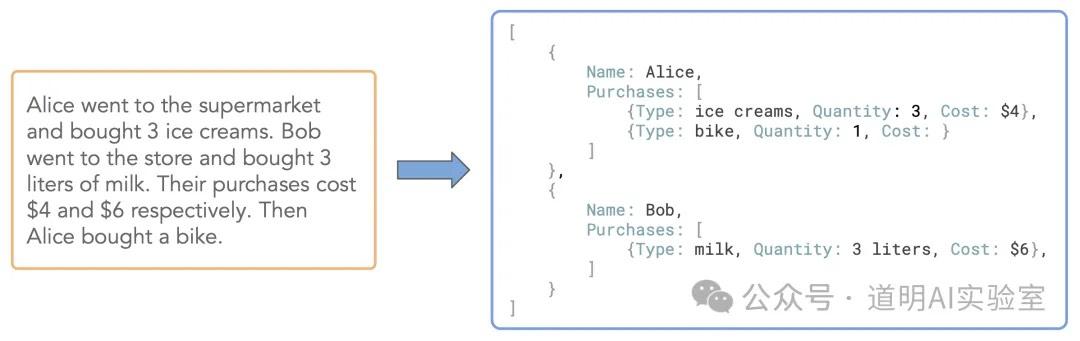
即将非结构化的文本信息,进行结构化的输出,按照模型开发方 numind 的评测,效果接近 gpt-4o。这确实是我这段时间以来看到的表现最好的这类模型。
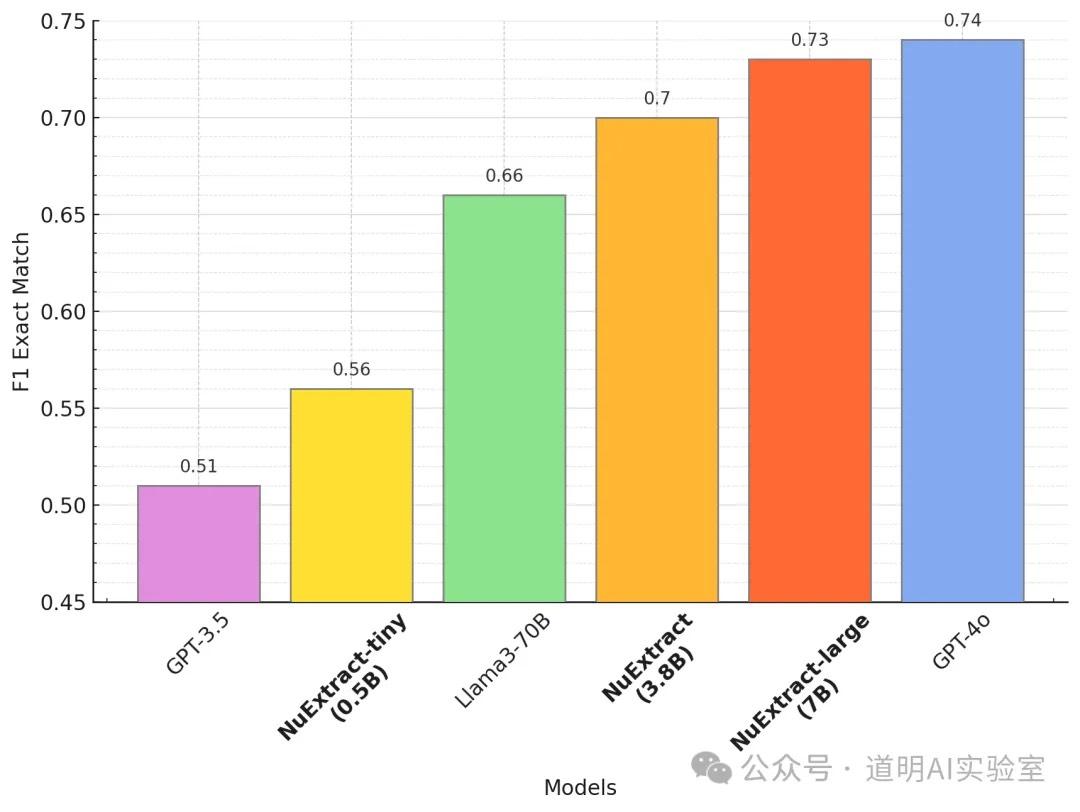
那么这个模型最大的用途在哪里?就是快速的数据获取和结构化,然后作为 agent 的一部分被上述的 ControlFlow 或者 llama agents 调用。
4. Jina Reranker V2,超级快速的 RAG 代理模型
Jina Reranker V2
https://jina.ai/news/jina-reranker-v2-for-agentic-rag-ultra-fast-multilingual-function-calling-and-code-search/

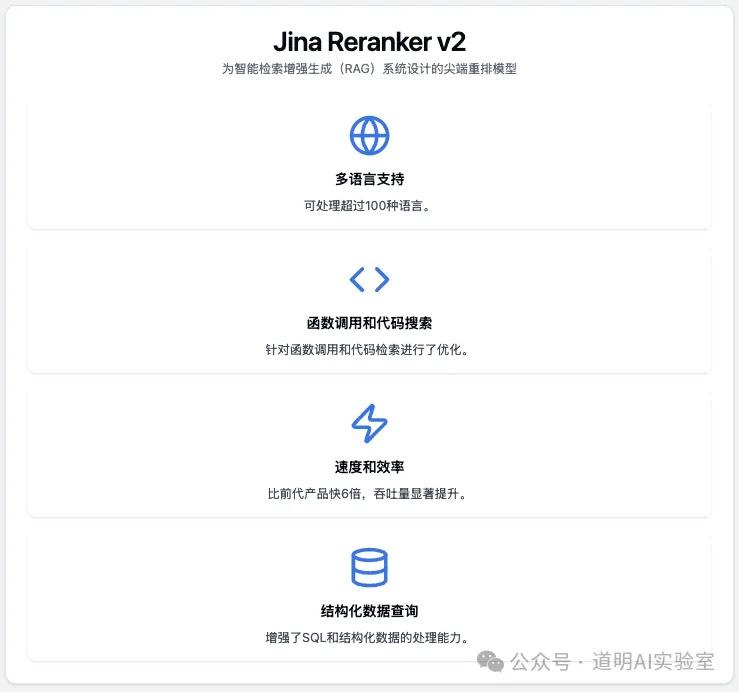
Jina 可能是介绍的这几个项目里,公司背景最强的一家,在大模型出来之前,就有一系列基于文档处理、搜索的 AI 解决方案,最近一段时间,更是发布了 AI 爬虫,Jina Reader。这是一家 2020 年在德国成立的 AI 初创公司,每一套解决方案都有很多的开发者“拥趸”。
与 NuExtract 类似的是,Reranker 也是模型,权重文件可以在 huggingface 上下载,base-multilingual 模型只有 2.78 亿参数规模,模型文件大小才 500 多兆,对硬件的要求极低。可以支持多语言,可以调用函数,搜索代码,还可以写 SQL 查询数据。
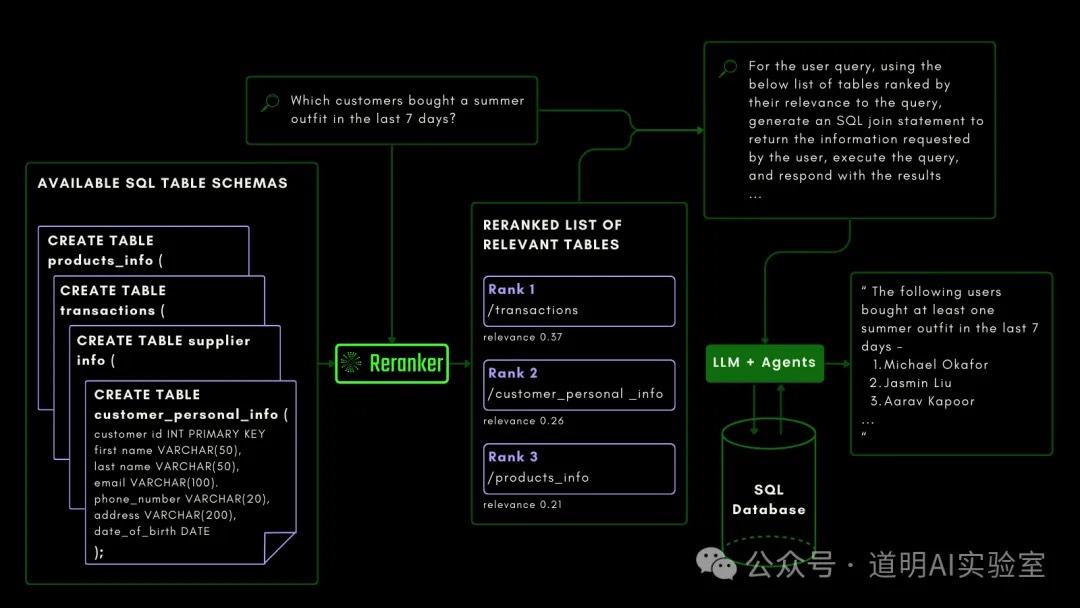
总结
最近一段时间的主要精力首先放在了基础平台改造上,所以虽然对这些模型非常心动,但是暂时拿不出时间来实测,可是,我能强烈的感觉到,它们都走在正确的方向上:将模型与传统工作流结合,这里面最重要的是业务数据处理和为此展开的流程再造工作。
如果把上一个时代称为“大数据时代”,那么核心是 ETL,Extract 抓取,Transform 转换,Load 读取,或者也有流程是 ELT。这个时代最大的工作量就是数据处理。
那么这个“大模型时代”,当 agent 代理人逐渐可用时,最大工作量的一块逐渐交给模型来处理后,带来的改变,会很大,甚至有可能是惊人的。